Hadoop的安装(2)---Hadoop配置
一:安装JDK
hadoop2.x最低jdk版本要求是:jdk1.7(不过推荐用最新的:jdk1.8,因为jdk是兼容旧版本的,而且我们使用的其他软件可能要求的jdk版本较高)
注意:版本选取需要同操作系统一致

(一)创建App文件夹
用于存放Hadoop用户安装的各种应用
(二)将jdk解压自App文件夹中
先进入jdk所在文件夹目录下
tar -zxvf jdk-7u80-linux-x64.tar.gz -C ~/App/
(三)进行测试使用
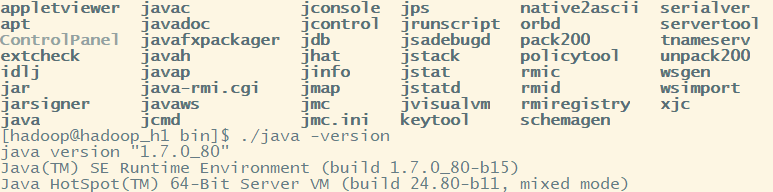
cd ~/App/jdk1..0_80/bin
./java -version
二:将应用bin和sbin目录加入环境变量中
编辑/etc/profile文件
sudo vi /etc/profile
添加下面代码:将java和Hadoop中bin目录加入环境变量
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/hadoop/App/hadoop-2.7.1
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH

使用source /etc/profile保存配置文件
source /etc/profile
三:安装Hadoop
(一)解压Hadoop

tar -zvxf hadoop-2.7.1_64bit.tar.gz -C ~/App/
(二)目录讲解
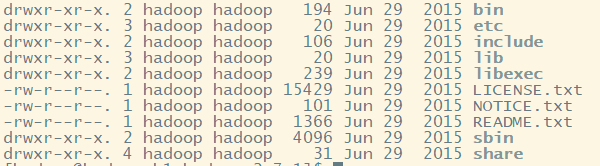
1.bin目录---存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
bin: 存放的是我们用来实现管理脚本和使用的脚本的目录,我们对hadoop文件系统操作的时候用的就是这个目录下的脚本
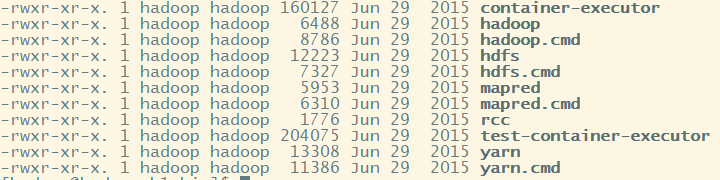
常用的命令脚本(我们忽略.cmd的文件这是windows下的使用的文件):hdfs hadoop yarn 来执行对文件操作
其中hadoop文件用于执行hadoop脚本命令,被hadoop-daemon.sh调用执行,也可以单独执行,一切命令的核心
2.etc目录---Hadoop的配置文件目录,存放Hadoop的配置文件
etc:存放一些hadoop的配置文件
cd ./hadoop/
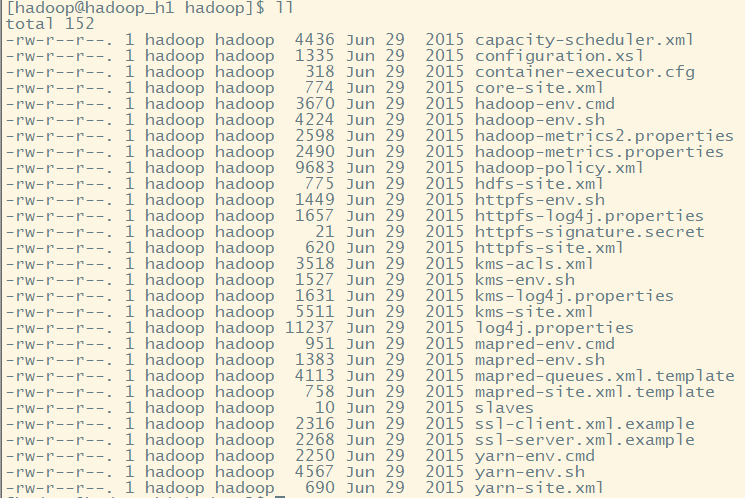
(1)core-site.xml: Hadoop全局配置文件
Hadoop核心全局配置文件,可以其他配置文件中引用该文件中定义的属性,如在hdfs-site.xml及mapred-site.xml中会引用该文件的属性;
该文件的模板文件存在于$HADOOP_HOME/src/core/core-default.xml,可将模板文件复制到conf目录,再进行修改。
(2)hadoop-env.sh Hadoop环境变量配置文件
Hadoop环境变量
(3)hdfs-site.xml HDFS的核心配置文件
HDFS配置文件,该模板的属性继承于core-site.xml;该文件的模板文件存于$HADOOP_HOME/src/hdfs/hdfs-default.xml,可将模板文件复制到conf目录,再进行修改
(4)yarn-site.xml yarn的核心配置文件
yarn的配置文件,该模板的属性继承于core-site.xml;该文件的模板文件存于$HADOOP_HOME/src/mapred/mapredd-default.xml,
可将模板文件复制到conf目录,再进行修改
(5)slaves 用于设置所有的slave的名称或IP,每行存放一个
用于设置所有的slave的名称或IP,每行存放一个。如果是名称,那么设置的slave名称必须在/etc/hosts有IP映射配置
(6)mapred-site.xml MapReduce的核心配置文件,模板文件mapred-site.xml.template
3.include目录
include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
4.lib目录---存放Hadoop的本地库(对数据进行压缩解压缩功能)
lib:该目录下存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中。
5.libexec目录
libexec:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
6.sbin目录---存放启动或停止Hadoop相关服务的脚本
sbin: 存放的是我们管理脚本的所在目录,重要是对hdfs和yarn的各种开启和关闭和单线程开启和守护
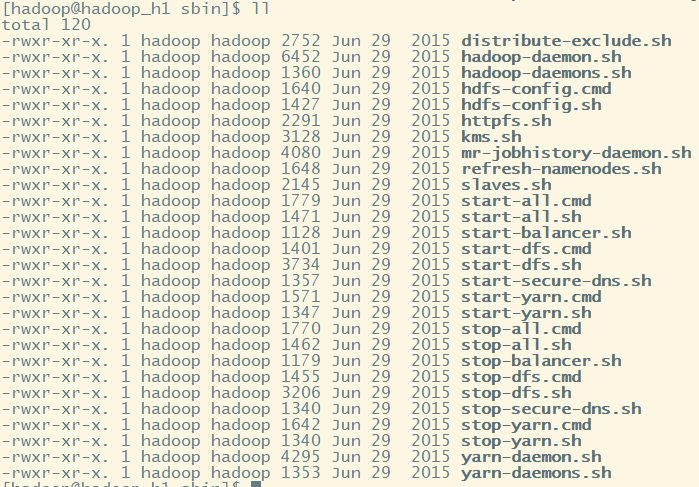
start-dfs.sh
启动NameNode、DataNode以及SecondaryNameNode
start-yarn.sh
启动ResourceManager以及NodeManager
stop-dfs.sh
停止NameNode、DataNode以及SecondaryNameNode
stop-yarn.sh
停止ResourceManager以及NodeManager
start-all.sh
相当于执行 start-dfs.sh 及 start-yarn.sh
stop-all.sh
相当于执行 stop-dfs.sh 及 stop-yarn.sh
hadoop-daemon.sh
通过执行hadoop命令来启动/停止一个守护进程(daemon);
该命令会被bin目录下面所有以start或stop开头的所有命令调用来执行命令;
hadoop-daemons.sh也是通过调用hadoop-daemon.sh来执行命令;
hadoop-daemon.sh本身就是通过调用hadoop命令来执行任务。
7.share目录---存放Hadoop的依赖jar包、文档(可删除)、和官方案例
Hadoop各个模块编译后的jar包所在的目录。开发程序需要从此引入jar包
(三)配置安装Hadoop
1.修改etc/hadoop/下配置文件(linux下不需要修改cmd文件)
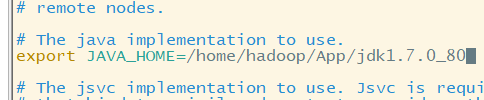
(1)hadoop-env.sh文件修改:修改java_home(写死)
vi hadoop-env.sh

echo $JAVA_HOME获取完整环境变量:/home/hadoop/App/jdk1..0_80
Hadoop启动时,需要读取,*-site.xml文件,都需要修改
(2)修改core-site.xml文件
vi core-site.xml
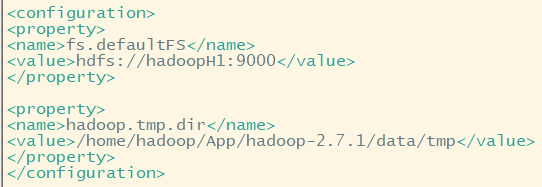
fs.defaultFS:默认采用的文件系统---指定namenode(主节点)的地址
我们需要修改他,因为Hadoop各组件组件是松耦合联系,而文件系统可以是本地文件系统,如linux ext等,也可以是HDFS,....。
所以我们需要指定一个专门的文件系统,为HDFS
value值必须为URI类型:例如HDFS URI: hdfs://主节点名称:端口号/ 其中端口默认9000
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopH1:9000</value>
</property>
hadoop.tmp.dir:Hadoop公共目录,用来指定使用hadoop时产生文件的存放目录(如果可以,应该是磁盘挂载点,方便扩容)
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/App/hadoop-2.7.1/data/tmp/</value> 这里我们指定存放在hadoop根目录下的data文件夹下
</property>
(3)修改hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>1</value> 伪分布指定一个即可
</property>
也可以指定切块大小,默认128M(太小了,效率会降低)
注:因为每个分块,都会占用NameNode的一条记录,如果分块太小,则会产生大量记录,占据NameNode空间,使得实际DataNode集群可存放数据大小降低!!!
dfs.namenode.name.dir:指定hdfs中namenode的存储位置
dfs.datanode.data.dir:指定hdfs中datanode的存储位置
Hadoop hdfs有NameNode和DataNode两种节点(两种不同进程),DataNode进程负责管理我们传送的文件块,存放在linux文件目录下, 同样NameNode也需要文件目录存放数据,我们可以分别指定,
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/App/hadoop-2.7.1/data/name</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/App/hadoop-2.7.1/data/data</value>
</property>

4.修改mapred-site.xml文件
先将mapred-site.xml.template(Hadoop不可读)变为mapred-site.xml文件(Hadoop可读)
mv mapred-site.xml.template mapred-site.xml
mapreduce.framework.name:指定mapreduce程序应该放入哪一个资源调度集群上使用,否则在本地运行,而不是在集群中使用
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

5.修改yarn-site.xml文件
yarn.resourcemanager.hostname:指定Yarn主节点ResourceManager地址
yarn.nodemanager.aux-services:指定nodeManager节点获取数据的方式
yarn.log-aggregation-enable:是否开启工作日志
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopH1</value>
</property>
<!--Yarn打印工作日志-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>

(四)开启Hadoop
1.关闭防火墙(Hadoop一般在内网使用,所以关掉影响不大)
sudo firewall-cmd --state 查看防火墙状态
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动

2.初始化hdfs文件系统
hadoop namenode -format

可以看到,格式化namenode之后,会在我们指定的配置项所指目录中,生成一些文件


其中fsimage是元数据,.md5是校验文件
而整个文件系统命名空间(包括块到文件和文件系统属性的映射)存储在名为 FsImage 的文件中。
FsImage 也作为文件存储在 NameNode 的本地文件系统中。
3.启动Hadoop
进入sbin目录(存放系统启动脚本)
cd ~/App/hadoop-2.7./sbin/
(1)先启动hdfs
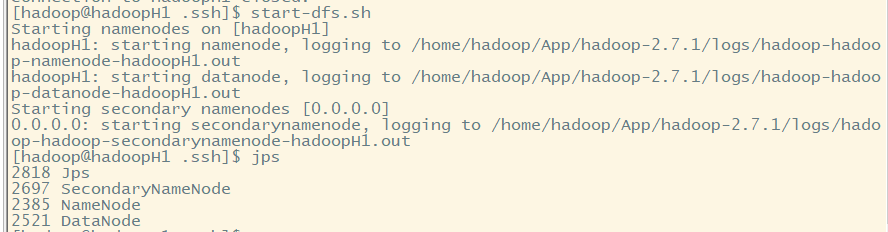
start-dfs.sh
需要选择是否连接主机,并且每启动一次进程,需要输入一次密码!!!
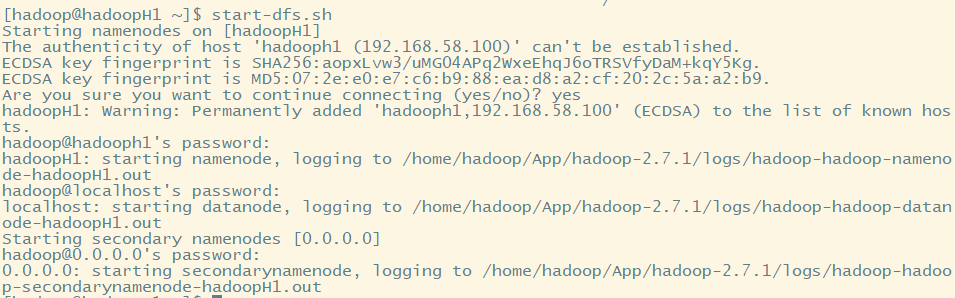
注意:我们在core-site.xml中只配置了NameNode,并没有配置DataNode。但是为什么依旧启动了DataNode??
0.0.0.0广播地址,用于查看集群中有几台机器。
查看进程:jps,用于检查hdfs是否启动成功
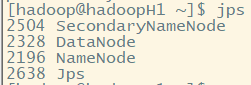
hdfs正常运行,需要上面3种进程
NameNode只有一个,DataNode则有多个,DataNode设置需要在配置文件
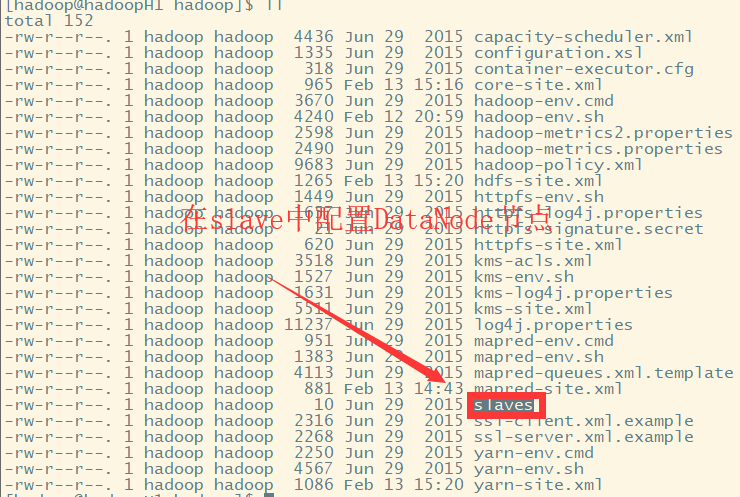
查看slave文件内容:

内容为localhost,故在本机中启动DataNode。我们可以设置多个集群节点,设置主机名即可
(2)启动yarn
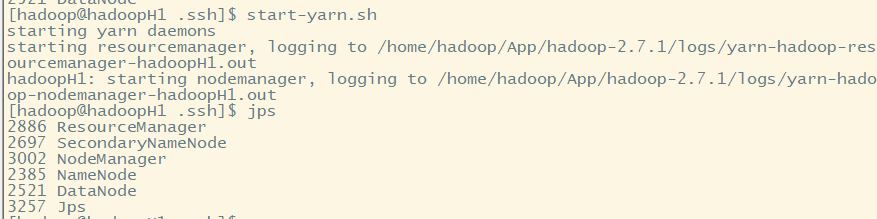
start-yarn.sh
我们本机为主节点,直接开启resourcenamager,不需要输入密码。而nodemanager需要在其他主机中启动,故需要输入密码才可以启动nodemanager进程

故:启动集群,并不需要到每台机器中启动。只需要配置slave文件后。便可在一台机器中启动所有节点。

四:测试Hadoop
(一).测试Hadoop web服务
修改windows主机hosts文件
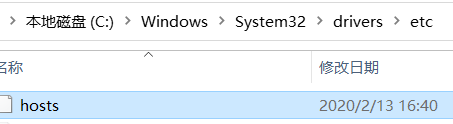
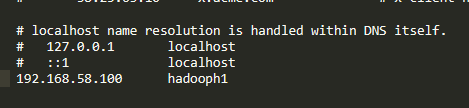
添加映射:
使用网页访问Hadoop:
http://hadooph1:50070 注意:https可能无法访问
(二)测试hdfs
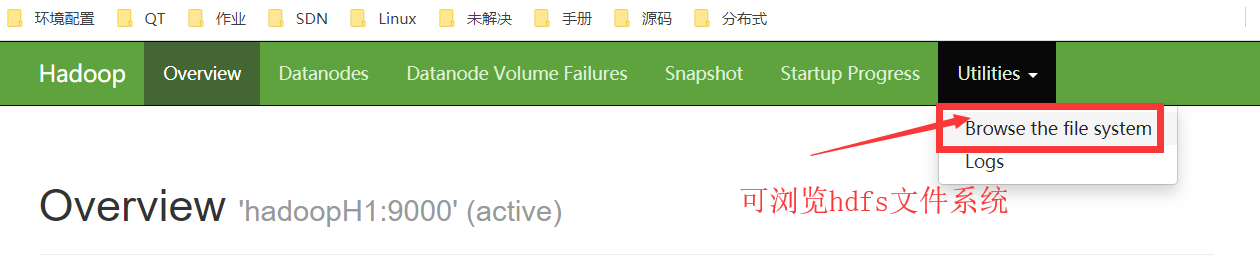
1.上传文件到hdfs文件系统中
hadoop fs -put jdk-7u80-linux-x64.tar.gz hdfs://hadoopH1:9000/ 上传到hdfs文件系统根目录下

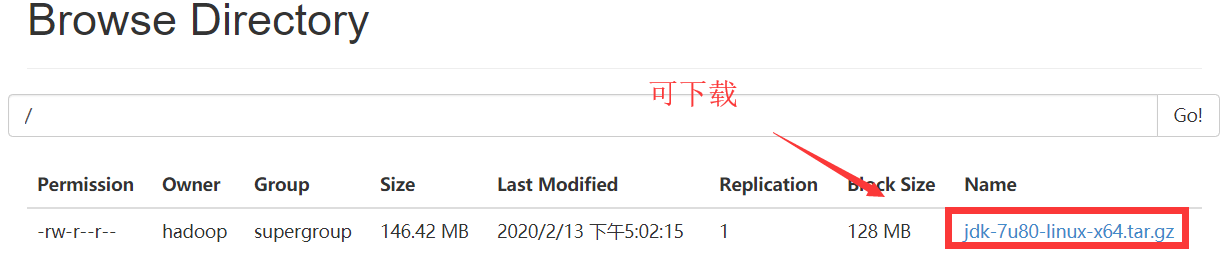
2.查看hdfs文件系统中文件
(1)在web中查看,可进行下载
(2)使用命令行下载文件到当前目录
hadoop fs -get hdfs://hadoopH1:9000/jdk-7u80-linux-x64.tar.gz

3.查看hdfs文件分块信息

其中.meta文件,是校验和文件。
(三)测试mapreduce
1.使用案例程序进行测试。
mapreduce案例程序在/home/hadoop/App/hadoop-2.7./share/hadoop/mapreduce,在share文件夹下
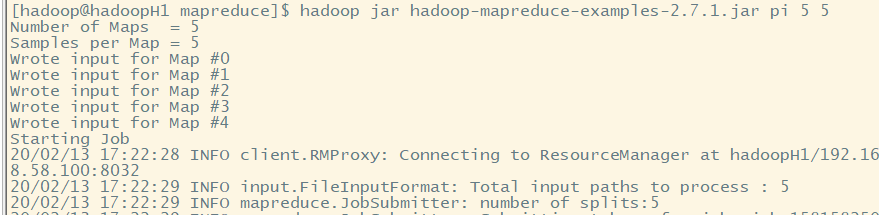
可用于计算圆周率
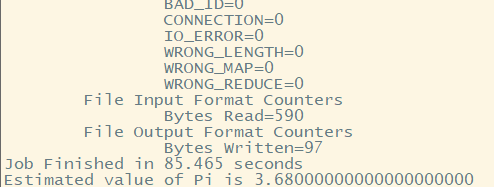
(四)测试mapreduce程序---统计单词出现次数
1.测试数据
vi test.txt
hello world
hello ketty
hello boys
hello mark
hello mark
hello doctor
hello kitty
2.上传文件到hdfs系统中
先在hdfs系统中创建一个目录
hadoop fs -mkdir hdfs://hadoopH1:9000/wordcount
或者
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input 创建二级目录


上传文件到input文件目录中
hadoop fs -put test.txt /wordcount/input

3.调用案例程序统计数据
hadoop jar hadoop-mapreduce-examples-2.7..jar wordcount /wordcount/input /wordcount/output
调用jar案例包,使用wordcount类进行单词字数统计,输入数据在/worddcount/input目录下,输出数据应该放入/wordcout/output目录下
注:指定数据输入目录下的所有文件都会读取!!!
4.查看输出文件目录
hadoop fs -ls /wordcount/output

其中_SUCCESS大小为0,为空文件。part-r-00000存放结果。
5.查看输出结果文件
hadoop fs -cat /wordcount/output/part-r-
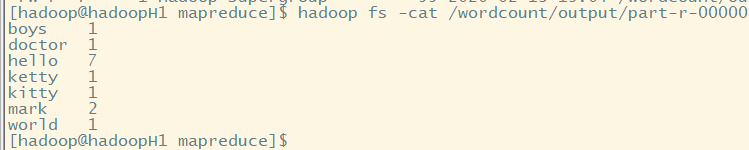
五:Hadoop shell命令
https://blog.csdn.net/hll19950830/article/details/79810540
六:Hadoop集群搭建的无密登陆配置
(一)ssh协议
推文:https://www.jianshu.com/p/33461b619d53
(二)集群密码输入时机
当启动hdfs文件系统时,start-dfs.sh。
其中start-dfs.sh会去调用core-site.xml获取NameNode信息,本地登陆NamdNode节点,调用slaves文件获取DataNode信息,远程登陆DataNode节点(需要输入密码)。
(三)SSH实践
1.生成密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -t:指定生成密钥类型(rsa、dsa、ecdsa等)
-P:指定passphrase,用于确保私钥的安全
-f:指定存放密钥的文件(公钥文件默认和私钥同目录下,不同的是,存放公钥的文件名需要加上后缀.pub)
ssh-keygen -t rsa
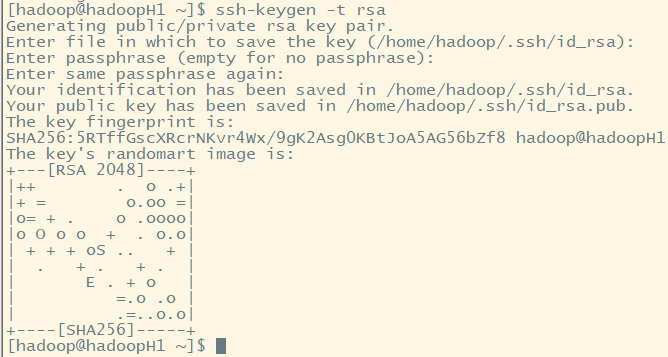
文件存放在用户主目录下.ssh目录下:
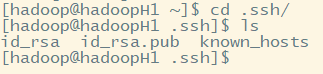
其实id_rsa 为密钥,id_rsa.pub为公钥
2.客户端将公钥发送到服务器端,可使得客户端可以登陆该服务器(无需密码)
scp id_rsa.pub hadoopH1:/home/hadoop/
其中scp为远程拷贝操作,拷贝到远程主机(主机名hadoopH1,拷贝目录/home/hadoop/下),需要输入远程主机的密码

查看远程服务器主目录(存在该公钥):

查看远程服务器.ssh是否存在authorized_keys文件,若不存在则创建,并赋权限600
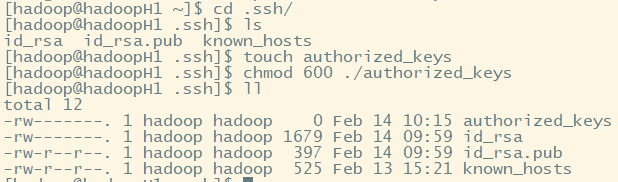
3. 将获取的公钥追加如authorized_keys文件中
cat ../id_rsa.pub >> ./authorized_keys
注:>是写入,>>是追加

是hadoop@hadoopH1的公钥
4.客户端再次登陆服务器。发现并不用输入密码

(四)实践Hadoop无密登陆
1.开启hdfs文件系统,不需要密码登陆
2.启动yarn,不需要密码登录
Hadoop的安装(2)---Hadoop配置的更多相关文章
- Hadoop HDFS安装、环境配置
hadoop安装 进入Xftp将hadoop-2.7.3.tar.gz 复制到自己的虚拟机系统下的放软件的地方,我的是/soft/software 在虚拟机系统装软件文件里,进行解压缩并重命名 进入p ...
- 大数据Hadoop平台安装及Linux操作系统环境配置
配置 Linux 系统基础环境 查看服务器的IP地址 设置服务器的主机名称 hostnamectl set-hostname hadoop hostname可查看 绑定主机名与IP 地址 vim /e ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 安装单机Hadoop系统(完整版)——Mac
在这个阴雨绵绵的下午,没有睡午觉的我带着一双惺忪的眼睛坐在了电脑前,泡上清茶,摸摸已是略显油光的额头(笑cry),,奋斗啊啊啊啊!!%>_<% 1.课程回顾. 1.1 Hadoop系统运行 ...
- Hadoop简单安装配置
Hadoop开始设计以Linux平台为运行目标,所以这里推荐在Linux发行版比如Ubuntu进行安装,目前已经有Hadoop for Windows出来,大家自行搜下文章. Hadoop运行模式分为 ...
- Linux云主机安装JDK,配置hadoop的详细方式
云主机我使用的是青云的,还有好多其他品牌,比如阿里云 unitedstack 等等. 注册完青云后,会有试用券发到账户,可以利用此券试用其服务. 1 首先创建好一个主机,按照提示选择好系统,创建好一个 ...
- Hadoop单机版安装,配置,运行
Hadoop是最近非常流行的东东啦,但是乍一看都觉得是集群的东东,其实在单机版上安装Hadoop也是可以的,并且安装好以后可以很方便的进行程序的调试,调试好程序以后再丢到集群中,放心的算吧,呵呵.. ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- hadoop的安装和配置(二)伪分布模式
博主会用三篇文章为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 伪分布式模式: 这篇为大家带来hadoop的伪分布模式: 从最简单的方面来说,伪分布模式就是在本地模式上修 ...
- hadoop的安装和配置(一)本地模式
博主会用三篇文章来为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 本地模式: 思路走向 |--------------------| | ①:配置Java环境 | | ...
随机推荐
- SVN状态图标不显示的解决办法
第一步:检查设置 右键->TortoiseSVN->setting->Icon Overlays->Status cache->default/Shell.或者 右键-& ...
- SecureCRT的下载、安装( 过程非常详细!!值得查看)
SecureCRT的下载.安装( 过程非常详细!!值得查看) 简单介绍下SecureCRT 一.SecureCRT的下载 二.SecureCRT的安装 简单介绍下SecureCRT SecureCRT ...
- itest(爱测试) 4.5.0 发布,开源BUG 跟踪管理 & 敏捷测试管理软件
itest 简介 test 开源敏捷测试管理,testOps 践行者.可按测试包分配测试用例执行,也可建测试迭代(含任务,测试包,BUG)来组织测试工作,也有测试环境管理,还有很常用的测试度量:对于发 ...
- dotMemory 2019.3.1一直试用
创建一个bat脚本, 里面写上: reg delete HKEY_CURRENT_USER\Software\JetBrains\dotMemory /freg delete HKEY_CURRENT ...
- iMacros 入门教程-基础函数介绍(3)
imacros 的 PAUSE 函数用法 这个函数的作用是暂停程序的运行,也就是断点. 对于有时运行到某一步需要输入内容时,或者需要调试时非常有用 如果你混着 pause 和 wait 一起用,那么当 ...
- tp 框架 文本编辑器 不解析HTML标签
解析 文本编辑器 空格 {$vo.content|htmlspecialchars_decode|stripslashes|html_entity_decode}
- bootstrap234的ie兼容选择
如果你需要兼容IE8甚至是IE7和IE6,那么只能选择Bootstrap2,虽然它自身在IE6的效果也并不完美.如果需要兼容IE678的话用2.如果需要高版本的浏览器,并且移动端优先的话,那么用boo ...
- Chocolaty
原文是用markdown格式写的,稍微改了下发了博客,格式可能会很奇怪.. Chocolaty官网 Chocolaty是一款Windows平台的包管理工具,类似于centos的yum或ubuntu的a ...
- 【29】带你了解计算机视觉(Computer vision)
计算机视觉(Computer vision) 计算机视觉是一个飞速发展的一个领域,这多亏了深度学习. 深度学习与计算机视觉可以帮助汽车,查明周围的行人和汽车,并帮助汽车避开它们. 还使得人脸识别技术变 ...
- openlayers地图显示点
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...