spark-ML之朴素贝叶斯
训练语料格式
自定义五个类别及其标签:0 运费、1 寄件、2 人工、3 改单、4 催单、5 其他业务类。
从原数据中挑选一部分作为训练语料和测试语料 
建立模型测试并保存
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{HashingTF, IDF, LabeledPoint, Tokenizer}
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.sql.Row
import org.apache.spark.{SparkConf, SparkContext}
object shunfeng {
case class RawDataRecord(label: String, text: String)
def main(args : Array[String]) {
val config = new SparkConf().setAppName("createModel").setMaster("local[4]")
val sc =new SparkContext(config)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
//开启RDD隐式转换,利用.toDF方法自动将RDD转换成DataFrame;
import sqlContext.implicits._
val TrainDf = sc.textFile("E:\\train.txt").map {
x =>
val data = x.split("\t")
RawDataRecord(data(0),data(1))
}.toDF()
val TestDf= sc.textFile("E:\\test.txt").map {
x =>
val data = x.split("\t")
RawDataRecord(data(0),data(1))
}.toDF()
//tokenizer分解器,把句子划分为词语
val TrainTokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
val TrainWords = TrainTokenizer.transform(TrainDf)
val TestTokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
val TestWords = TestTokenizer.transform(TestDf)
//特征抽取,利用TF-IDF
val TrainHashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(5000)
val TrainData = TrainHashingTF.transform(TrainWords)
val TestHashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(5000)
val TestData = TestHashingTF.transform(TestWords)
val TrainIdf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val TrainIdfmodel = TrainIdf.fit(TrainData)
val TrainForm = TrainIdfmodel.transform(TrainData)
val TestIdf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val TestIdfModel = TestIdf.fit(TestData)
val TestForm = TestIdfModel.transform(TestData)
//把数据转换成朴素贝叶斯格式
val TrainDF = TrainForm.select($"label",$"features").map {
case Row(label: String, features: Vector) =>
LabeledPoint(label.toDouble, Vectors.dense(features.toArray))
}
val TestDF = TestForm.select($"label",$"features").map {
case Row(label: String, features: Vector) =>
LabeledPoint(label.toDouble, Vectors.dense(features.toArray))
}
//建立模型
val model =new NaiveBayes().fit(TrainDF)
val predictions = model.transform(TestDF)
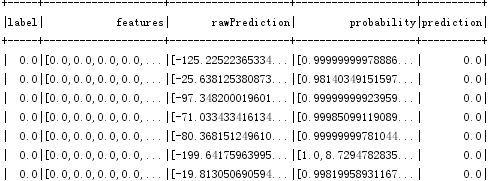
predictions.show()
//评估模型
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println("准确率:"+accuracy)
//保存模型
model.write.overwrite().save("model")
}
}模型评估: 
使用模型预测
import org.ansj.recognition.impl.StopRecognition
import org.ansj.splitWord.analysis.{DicAnalysis, ToAnalysis}
import org.apache.spark.ml.classification.NaiveBayesModel
import org.apache.spark.ml.feature._
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object stest {
case class RawDataRecord(label: String)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("shunfeng")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val frdd = sc.textFile("C:\\Users\\Administrator\\Desktop\\01\\*")
val filter = new StopRecognition()
filter.insertStopNatures("w") //过滤掉标点
val rdd = frdd.filter(_.contains("含中文"))
.filter(!_.contains("▃▂▁机器人丰小满使用指引▁▂▃"))
.map(_.split("含中文")(0))
.map(_.split("\\|")(3))
.filter(_.length>1)
.map{x =>
val temp = ToAnalysis.parse(x.toString)
RawDataRecord(DicAnalysis.parse(x.toString).recognition(filter).toStringWithOutNature(" "))
}.toDF()
val tokenizer = new Tokenizer().setInputCol("label").setOutputCol("words")
val wordsData = tokenizer.transform(rdd)
//setNumFeatures的值越大精度越高,开销也越大
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(5000)
val PreData = hashingTF.transform(wordsData)
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(PreData)
val PreModel = idfModel.transform(PreData)
//加载模型
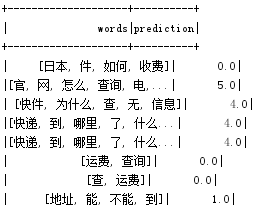
val model =NaiveBayesModel.load("model")
model.transform(PreModel).select("words","prediction").show()
}
}
结果:
spark-ML之朴素贝叶斯的更多相关文章
- 朴素贝叶斯算法源码分析及代码实战【python sklearn/spark ML】
一.简介 贝叶斯定理是关于随机事件A和事件B的条件概率的一个定理.通常在事件A发生的前提下事件B发生的概率,与在事件B发生的前提下事件A发生的概率是不一致的.然而,这两者之间有确定的关系,贝叶斯定理就 ...
- 贝叶斯、朴素贝叶斯及调用spark官网 mllib NavieBayes示例
贝叶斯法则 机器学习的任务:在给定训练数据A时,确定假设空间B中的最佳假设. 最佳假设:一种方法是把它定义为在给定数据A以及B中不同假设的先验概率的有关知识下的最可能假设 贝叶斯理论提供了 ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- Spark朴素贝叶斯(naiveBayes)
朴素贝叶斯(Naïve Bayes) 介绍 Byesian算法是统计学的分类方法,它是一种利用概率统计知识进行分类的算法.在许多场合,朴素贝叶斯分类算法可以与决策树和神经网络分类算法想媲美,该算法能运 ...
- [置顶] 生成学习算法、高斯判别分析、朴素贝叶斯、Laplace平滑——斯坦福ML公开课笔记5
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9285001 该系列笔记1-5pdf下载请猛击这里. 本篇博客为斯坦福ML公开 ...
- [ML学习笔记] 朴素贝叶斯算法(Naive Bayesian)
[ML学习笔记] 朴素贝叶斯算法(Naive Bayesian) 贝叶斯公式 \[P(A\mid B) = \frac{P(B\mid A)P(A)}{P(B)}\] 我们把P(A)称为"先 ...
- spark 机器学习 朴素贝叶斯 实现(二)
已知10月份10-22日网球场地,会员打球情况通过朴素贝叶斯算法,预测23,24号是否适合打网球.结果,日期,天气 温度 风速结果(0否,1是)天气(0晴天,1阴天,2下雨)温度(0热,1舒适,2冷) ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- ML—朴素贝叶斯
华电北风吹 日期:2015/12/12 朴素贝叶斯算法和高斯判别分析一样同属于生成模型.但朴素贝叶斯算法须要特征条件独立性如果,即样本各个特征之间相互独立. 一.朴素贝叶斯模型 朴素贝叶斯算法通过训练 ...
- spark(1.1) mllib 源码分析(三)-朴素贝叶斯
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4042467.html 本文主要以mllib 1.1版本为基础,分析朴素贝叶斯的基本原理与源码 一.基本原 ...
随机推荐
- 【核心核心】4.Spring【IOC】注解方式
1.导入jar包 2.创建对应的类 public interface HelloService { public void sayHello(); } /** * @Component(value=& ...
- JZOJ5918【NOIP2018模拟10.20】Car
题目 最近比较懒,题目描述都直接截图了. 题目大意 给你一棵树,还有树上的几条路径,一条路径上的点到路径上其它任意点的代价为111.然后是一堆询问,问从一个点到另一个点的最小代价. 思路 一开始做这题 ...
- 廖雪峰Java10加密与安全-5签名算法-2DSA签名算法
DSA DSA:Digital Signature Algorithm,使用EIGamal数字签名算法,和RSA数字签名相比,DSA更快. DSA只能配合SHA使用: SHA1withDSA SHA2 ...
- 19-10-24-J-快乐?
向未来的大家发送祝福(不接受的请自动忽略): 祝大家程序员节快乐! 好了. ZJ一下 额. 考场上差点死了. 码1h后,T1还没过大样例. 我×××. 后来发现是自己××了. T2T3丢暴力. 比咕的 ...
- nginx 访问ssl 的 pem 遇到的权限问题
nginx 开启失败,日志记录 访问 ssl 的 pem 文件 fopen:Permission denied 权限问题,查看文件权限,目录权限,正常. google 后得知原来是一个 SELinu ...
- jeecms添加站点
Step1:点击[站点管理],然后点击[添加站点]. Step2:按照下图填写,注意[路径]这一栏!!这里我随便写了个[aaa]. Step3:这个时候在本地部署的tomcat的模板路径:tomcat ...
- 组件:slot插槽
<!DOCTYPE html> <html lang="zh"> <head> <title></title> < ...
- pixhawk 常见问题 持续更新
红灯蓝灯闪,初始化中,请稍等 黄灯双闪,错误,系统拒绝解锁 黄灯闪,遥控器关闭 黄灯快速闪且滴滴响,电池保护激活 蓝灯... 未见过.... 绿灯闪: 已加锁,GPS锁定已获得. 准备解锁. 从加锁状 ...
- JasperReports报表区段14
我们将在本章开始,一个简单的报表模板的结构看.依样画葫芦JasperReports的结构报表模板归类到多个区段.部分是有规定的高度,并且可以包含像直线,矩形,图像或文本字段对象报表的部分. 通过提供的 ...
- Luogu P2678 跳石头(二分)
P2678 跳石头 题意 题目背景 一年一度的"跳石头"比赛又要开始了! 题目描述 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石.组委会已经选择好了两块岩石作为比赛起 ...