Mysql优化-字段设计
摘抄并用于自查笔记
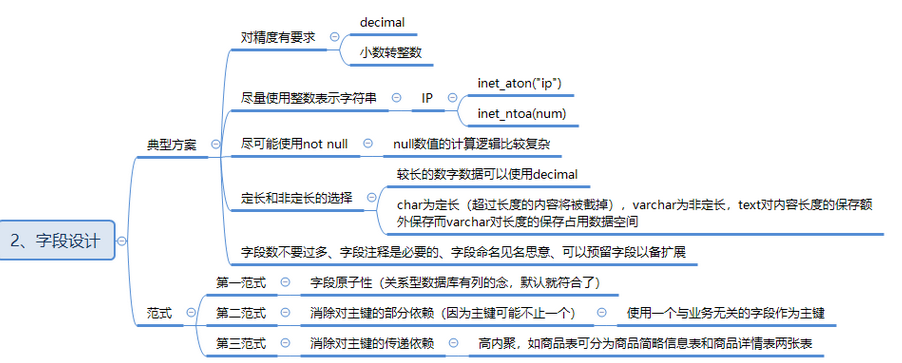
1. 对精度有要求decimal
float 类型用于表示单精度浮点数值,而double类型用于表示双精度浮点数值,float 和 double 都是浮点型,而 decimal 是定点型。
MySQL浮点型和定点型可以用类型名称后加 (M,D) 来表示,M表示该值的总共长度,D表示小数后面的长度,M和D又称为精度和标度,如 float(7,4) 可显示为 -999.9999,MySQL保存值时进行四舍五入,如果插入 999.00009,则结果为 999.0001。float 的精度大概在7为左右,超过了就是1000000...... double的精度在15位左右.......
浮点数通常用来保存一些数量特别大,大到不用那么精确的数据,如果要更精确的,可以用decimal。
decimal(M,D) M表示总长度,不能超过65,D表示小数部分,最长不能超过38。
float 和 double 在不指定精度时,默认会按照实际的精度来显示,而 decimal 在不指定精度时,默认整数为10,小数为0。
decimal 和 numeric 值作为字符串存储,而不是二进制浮点数,以便保存那些值的小数精度。
缺点: decimal 类型字段插入超过定义的数字会省略后面几位的数字(四舍五入)
优点:1)数值以字符串的形式保存,存储了一个准确的数字表达法,不存储值的近似值。这种方法很好的处理 float 和 double 类型都会发生的错误,因为他们都是以二进制存储的,所以有一定的误差。一个字符用于值的每一位、小数点
2)decimal 有更多的位数保存数值
float:浮点型,含字节数为4,32bit,7个有效位
double:双精度实型,含字节数为8,64bit,15个有效位
decimal:数字型,128bit,不存在精度损失,常用于银行账目计算,28个有效位。
2. 尽量用整数代替字符串
数据库处理数字比字符串快,在正常情况下查询数字比查询字符快很多。
对数字建立索引也比字符快
对数字比大小时,如果拿到程序端比较还要转型,在数据端比较也很麻烦
...
3. 尽量使用 not null
在mysql数据库中,“NULL” 和 “空值(空字符串)”是不一样的。NULL是一种比较特殊的数据类型,这也可以解释为什么字段设置为NOT NULL,却可以插入空值。空值是不占用空间的,而NULL需要占用空间。
在平常我们设计数据库时,如果是索引字段,一定要定义为 NOT NULL 。因为 NULL 值会影响优化器对索引的选择,索引效率会下降很多。虽然表中允许 NULL 列,但其他字段也尽量定义为 NOT NULL 。 mysql 在进行比较的时候,NULL 会参与字段比较。因为 NULL 是一种比较特殊的数据类型。数据库在处理的时候需要进行特殊的处理。如此的话,就会增加数据库处理记录的复杂性。当表中有比较多的空字段时,在同等条件下,数据库处理的性能会降低许多。
在往数据表插入数据时,如果一直不能保证该字段一定有值,可以借鉴以下解决方法:
1)通过设置默认的形式,定义时使用DEFAULT " 或 DEFAULT 0,来避免空字段的产生。
2)若一张表中,允许为空的列比较多,接近全部列数的三分之一,而且这些列在大部分情况下都可有可无,可以考虑另外建立一张附表,以保存这些列。
4. 定长和非定长的选择
对于长度基本固定的列,如果该列恰好更新又特别频繁,适合char。
varchar虽然存储变长字符串,但不可太小也不可太大。UTF8最多能存储21844个汉字,或者65532个英文。
varbinary(M) 保存的是二进制字符串,它保存的是字节而不是字符,所以没有字符集的概念,M长度0-255(字节)。只用于排序或比较时大小写敏感的类型,不包括密码存储。
text 类型与 VARCHAR 都类似,存储可变长度,最大限制2^16,但是它20Byte以后的内容是在数据页以外的空间存储(row_format=dynamic),对他的使用需要多一次寻址,没有默认值。一般用于存放容量平均都很大、操作没有其他字段那样频繁的值。(网上部分说要避免使用 text 和blob,如果纯用varchar可能会导致行溢出,效果差不多,但因为每行占用字节数过多,会导致 buffer_pool 能缓存的数据行、页下降。另外 text 和 blob 上面一般不会去建索引,而是利用 sphinx 之类的第三方全文搜索引擎,如果确实要创建(前缀)索引,那就会影响性能)
在 mysql 中,若一张表里面不存在 varchar、text 、blob 字段的话,那么这张表也叫静态表,即该表的 row_format 是 fixed , 就是说每条记录所占用的字节一样。其优点是读取快,缺点是浪费额外一部分空间。
若一张表里面存在 varchar、text、blob 字段的话,那么这张表也叫动态表,即该表的 row_format 是 dynamic,就是说每条记录所占用的字节是动态的。其优点是节省空间,缺点是增加读取的时间开销。
所以,做搜索查询量大的表一般都是以空间来换取时间,设计成静态表。
5. timestamp 和 datetime 选择
datetime 和 timestamp 类型所占的存储空间不同,前者8字节,后者4字节,这样造成的后果是两者能表示的时间范围不同。前者范围是 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59,后者范围是 1970-01-01 8:00:01 ~ 2038-01-19 11:14:07. 所以 timestamp 支持的范围比 datetime 要小。
timestamp 可以在 insert/update 时,自动更新时间字段(如 f_set_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP),但一个表只能有一个这样的定义。
timestamp 显示与时区有关,内部总是以 UTC 毫秒来存的。
优先使用 timestamp ,datetime 也没问题
where 条件里不要对时间列上使用时间函数。
6. 所有表显示指定主键,不要强制使用外键
主键尽量采用自增方式,InnoDB 表实际是一棵索引组织表,顺序存储可以提高存储效率,充分利用磁盘空间。还有对一些复杂查询可能需要自连接来优化时需要用到。(如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当写满一页就会自动开辟一个新的页,如果使用非自增主键,由于每次插入主键的值近似随机,因此每次的新记录都要被插到现有索引页的中间某个位置,此时,MySQL不得不为了将新记录插到合适位置而移动数据,升职目标页面可能已经被回写到磁盘而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE(这个用来删除空洞,利用未使用的空间,并整理数据文件的碎片)来重新 建表并优化填充页面)
当删除数据时,mysql 并不会回收被已删除数据占据的存储空间,以及索引位。而是空在那里,等待新的数据来弥补这个空缺。所以如果一时半会没有数据
如果没有主键或者唯一索引,update/delete 是通过所有字段来定位操作的行,相当于每行就是一次全表扫描。
即使2个表的字段有明确的外键参考关系,也不使用 FOREIGN KEY,因为新纪录会去主键表做校验,影响性能。
7. 字段不要过多,取名见名思义,加注释,预留字段供扩展
单表字段数上限30个左右,再多的话考虑垂直分表,一时冷热数据分离,二是大字段分离,三是常在一起查询条件和返回的不分离。
表字段控制少而精,可以提高IO效率,内存缓存更多有效数据,从而提高响应速度和并发能力,后续 alter table 速度也更快。
8. 数据库三大范式
范式是关系数据库关系模式规范化的标准,从规范化的宽松到严格,分为不同的范式,通常使用的有第一范式、第二范式、第三范式及BC范式。范式是建立在函数依赖基础上的。
第一范式
1NF是对属性的原子性,要求属性具有原子性,不可再分解;
如学生(学号、姓名、性别、出生年月日),如果认为最后一列还可以再分成(出生年、出生月、出生日),他就不是第一范式了。(这个分解应该根据具体业务来确定,使用这个字段的情况,是查看年月日,还是分开查看年、月、日)
第二范式
2NF是对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖(两个事务);
如:表:学号、课程号、姓名、学分;
这个表明显说明了两个事务:学生信息,课程信息;由于非主键字段必须依赖主键,这里学分依赖课程号,姓名依赖学号,所以不符合第二范式;
可能会存在问题:
1. 数据冗余,每条记录都含有相同信息;
2. 删除异常,删除所有学生成绩,就把课程信息全部删除了;
3. 插入异常,学生未选课,无法记录进数据库;
4. 更新异常,调整课程学分,所有行都调整。
正确做法:
学生:Student(学号,姓名);
课程:Course(课程号,学分);
选课关系:StudentCourse(学号、课程号、成绩)。
第三范式
3NF是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖。
如:表:学号,姓名,年龄,学院名称,学院电话
因为存在依赖传递:学号 --> 学生 --> 所在学院 --> 学院电话
可能会存在问题:
1. 数据冗余,有重复值;
2. 更新异常,有重复的冗余信息,修改时需要同时修改多条记录,否则会出现不一致的情况,
正确做法:
学生:学号、姓名、年龄、所在学院;
学院:学院、电话
反范式化
一般来说,数据库只需满足第三范式(3NF)就行了。
没有冗余的数据库设计可以做到,但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余,达到以空间换时间的目的。
例如:有一张存放商品的基本表,“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个字段,可以提高查询统计的速度,这就是以空间换时间的做法。
范式化设计和反范式化设计的优缺点
1. 范式化优点:
可以尽量的减少数据冗余,数据表更新快体积小
范式化的更新操作比反范式化更快
范式化的表通常比反范式化更小
2. 范式化缺点:
对于查询需要对多个表进行关联,导致性能降低
更难进行索引优化
3. 反范式化优点
可以减少表的关联
可以更好的进行索引优化
4. 反范式化缺点
存在数据冗余及数据维护异常
对数据的修改需要更多的成本
Mysql优化-字段设计的更多相关文章
- mysql优化-数据库设计基本原则
mysql优化-数据库设计基本原则 一.数据库设计三范式 第一范式:字段具有原子性 原子性是指数据库的所有字段都不可被再次划分,如下表就不满足原子性,起点与终点 字段就可被拆分为起点与终点两个字段. ...
- MySQL 优化、设计规则浅谈
当数据量大,数据库相应慢时都会针对数据库进行优化.这时都是要针对具体情况,具体业务需求进行优化的. 但是有些步骤和规则应该适合各种情况的.这里综合网上找的资料简单分析一下. 第一优化你的sql和索引: ...
- MySQL的字段设计
1.尽量使用数字,因为文本占空间,不利于查询(针对有限种类文本)
- 第 9 章 MySQL数据库Schema设计的性能优化
前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就已经产生了的,后期的优化很多时候所能够带来的改善都只 ...
- Mysql优化之索引和字段
Mysql优化是一个老生常谈的问题, 优化的方向也优化很多:从架构层;从设计层;从存储层;从SQL语句层; 今天讲解一下从索引和字段: 字段优化: ① 尽量使用TINYINT.SMALLINT.ME ...
- mysql系列十一、mysql优化笔记:表设计、sql优化、配置优化
可以从这些方面进行优化: 数据库(表)设计合理 SQL语句优化 数据库配置优化 系统层.硬件层优化 数据库设计 关系数据库三范式 1NF:字段不可分; 2NF:有主键,非主键字段依赖主键; 3NF:非 ...
- MySQL性能调优与架构设计——第9章 MySQL数据库Schema设计的性能优化
第9章 MySQL数据库Schema设计的性能优化 前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就 ...
- mysql数据库架构设计与优化
mysql数据库架构设计与优化 2019-04-23 20:51:20 无畏D尘埃 阅读数 179 收藏 更多 分类专栏: MySQL 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA ...
- MySQL数据库优化、设计与高级应用
MySQL数据库优化主要涉及两个方面,一方面是对SQL语句优化,另一方面是对数据库服务器和数据库配置的优化. 数据库优化 SQL语句优化 为了更好的看到SQL语句执行效率的差异,建议创建几个结构复杂的 ...
随机推荐
- Linux环境变量永久设置方法(zsh)
1.之前一直使用:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./home/46005/cuda-9.0/lib64/来设置cuda库路径变量 -----临时的,当 ...
- Centos 能ping通域名和公网ip但是网站不能够打开,服务器拒绝了请求。打开80端口解决。
博客搬迁,给你带来的不便,敬请谅解! http://www.suanliutudousi.com/2017/10/29/centos-%E8%83%BDping%E9%80%9A%E5%9F%9F%E ...
- 高级UI晋升之常用View(三)下篇
更多Android高级架构进阶视频学习请点击:https://space.bilibili.com/474380680本篇文章将从WebView来介绍常用View: 一.WebView介绍 Andro ...
- 55-Ubuntu-软件安装
1.通过apt安装/卸载软件 apt是advanced packaging tool, 是Linux下的一款安装包管理工具. 可以在终端中方便的安装/卸载/更新软件包. (1)安装软件 sudo ap ...
- [Err] 1701 - Cannot truncate a table referenced in a foreign key constraint
1.SET FOREIGN_KEY_CHECKS=0; 2.DELETE FROM ACT_RE_DEPLOYMENT where 1=1; 或者 truncate table ACT_RE_DEPL ...
- SQLite 小调研
一. 概况: SQLite 是 D. Richard Hipp 于 2000 年采用 C 语言编写的一个轻量级.跨平台的关系型数据库,支持大部分 SQL92 标准(比如视图.事务.触发器.blob 数 ...
- Foxmail公司邮箱配置
1.打开Foxmail点击新建输入账户密码,点击创建: 2.勾选IMAP服务器的ssl,修改SMTP服务器端口为587 点击应用,账号创建完成.可以拉取和发送邮件了:
- Redis缓存数据库简单介绍
\ 1.什么是redis redis是一种基于内存的高性能键值型数据库(key-value),属于NoSQL,和 Memcached 类似: 从内存读取速度为110000次/s,写入内存速度为8100 ...
- PagedLOD模型对象选择关键技术点
DatabaseCacheReadCallback这个类继承ReadCallback,在相交的测试中,场景可能有PagedLOD,而计算相交过程中,PagedLOD不是精度最高的节点,这样计算的就不准 ...
- Java 获取当前路径的方法总结
Java 获取当前路径的方法总结 1.利用System.getProperty()函数获取当前路径: System.out.println(System.getProperty("user. ...