Mysql sql语句技巧与优化
一、常见sql技巧
1、正则表达式的使用
2、巧用RAND()提取随机行
mysql数据库中有一个随机函数rand()是获取一个0-1之间的数,利用这个函数和order by一起能够吧数据随机排序,
、 mysql>select * from stu order by rand();
下面是通过limit随机抽取了3条数据样本。
mysql>select * from stu order by rand() limit 3;
3、利用GROUP BY 的WITH ROLLUP子句统计
使用group by的with rollup子句可以检索出更多的聚合信息。
mysql>select cname,pname,count(pname) from demo group by cname,pname;
同样使用with rollup关键字后,统计出更多的信息。注意:with rollup不可以和order by同时使用。
mysql>select cname,pname,count(pname) from demo group by cname,pname with rollup;
4、用BIT GROUP FUNCTIONS 做统计
在使用group by语句时可以同时使用bit_anf、bit_or函数来完成统计工作,这两个函数的主要作用是做数值之间的逻辑位运算。
mysql>select id,bit_or(kind) from order_rab group by id; //二进制位运算
对order_rab表中id分组时对kind做位与和或计算。
mysql>select id,bit_and(kind) from order_rab group by id; //二进制余运算,只有11才为1
5、使用外健要注意的问题
创建外健如下:
mysql>create table temp(id int,name char(20),foreign key(id) references outTable(id) on delete cascade on update cascade));
注意:innodb类型的表支持外健,myisam类型的表,虽然创建可以成功,但不起作用,主要原因是不支持外健。
6、mysql中help的使用
a、?%可以获得所有mysql>里的命令,
b、?create
c、?opt%,因为记不住全称。
二、mysql的优化
1、优化sql语句的一般步骤
通过show status命令了解各种sql的执行频率。
格式:mysql>show [session|global] status;
session:(默认)表示当前链接
globla:表示自数据库启用至今
如:mysql>show status;
mysql>show global status;
mysql>show status like "Com_%";
mysql>show global status like "Com_%";
参数说明:
Com_select 执行select操作的次数,一次查询值累计加1
Com_update 执行update操作的次数
Com_insert 执行insert操作的次数
Com_delete 执行delete操作的次数
只针对Innodb引擎的:
InnoDB_rows_read执行select操作的次数
InnoDB_rows_update执行update操作的次数
InnoDB_rows_insert执行insert操作的次数
InnoDB_rows_delete执行delete操作的次数
其他:
connections链接mysql的数量
Uptime服务器已经工作的秒数
Slow_queries慢查询的次数
2、定位执行效率较低的sql语句:
a、explain select * from table where id = 1000;
b、desc select * from table where id = 1000;


c、优化的顺序:
1)查看慢查询日志,日志里查询超过10秒的说明产寻幽问题
2)通过desc定位这条语句哪里有问题。
3)通过方案对问题点进行优化,如加索引
2、索引问题
索引实数据库优化中最常见的也是最重要的手段之一,通过索引通常可以帮助用户姐绝大多数的sql性能问题。
1)索引的存储和分类:
MyISAM存储引擎的表的数据和索引是自动分开存储的,各自是独一的一个文件;InnoBDB存储引擎的表的数据和索引是存储在同一个表空间里面,但可以由多个文件组成。
mysql目前不支持函数索引,但是能对列的前面某一部分进行进行索引,例如name字段,可以去name的前2个字符进行索引,这个特性可以大大缩小文件的大小,用户在设计表结构的时候也可以对文本列根据此特性进行灵活设计。
mysql>create index ind_company2_name on company2(name(4));//company表名,ind_company2_name索引名
2)mysql如何使用索引
索引用于快速找出在某个列中有一特定值的行。对相关列使用索引是提高SELECT操作性能的最佳途径。
a、使用索引
(1)对于创建的多行索引,只要查询的条件中用到最左边的列,索引一般就会被使用。如下创建一个复合索引。
mysql>create index ind_sales2_com_mon onsales2(company_id,moneys);
然后按company_id进行查询,发现使用到了复合索引。
mysql>explain select * from sales2 where company_id=2006\G;
使用下面的查询就没有使用复合索引。
mysql>explain select * from sales2 where moneys=1\G;
(2)使用like的查询,后面如果是常量并且只有%号不在第一个字符,索引才可能被使用,如下:
mysql>explan select * from company2 where name like "%3"\G;

3)存在索引但不使用索引
(1)如果mysql估计使用索引比全表扫描更慢,则不使用索引。例如如果列key_prat1均匀分布在1-100之间,查询时使用索引就不是很好
mysql>select * from table_name where ley_part1>1 and key_part<90;
(2)如果使用MEMORY/HEAP表并且where条件中不使用“=”进行索引列,那么不会用到索引。Heap表只有在“=”的条件下使用索引。
(3)用or分割的条件,如果or前的条件中的列有索引,二后面的列没有索引,那么涉及的索引都不会用到。
(4)如果不是索引列的第一部分,如下例子:可见虽然在money上面建有复合索引,但是由于money不是索引的第一列,那么在查询中,这个索引也不会被mysql采用。
mysql>explan select * from sales2 where moneys=1\G;

(5)如果like是一%开始,可见虽然在name上家有索引,但是由于条件中的like的值的“%”在第一位了,那么mysql也不会采用这个索引。
(6)如果列类型是字符串,但在查询时把第一个数值型常量赋值给了一个字符类型的列名name,那么虽然在name列上有索引,但是也没有用到。
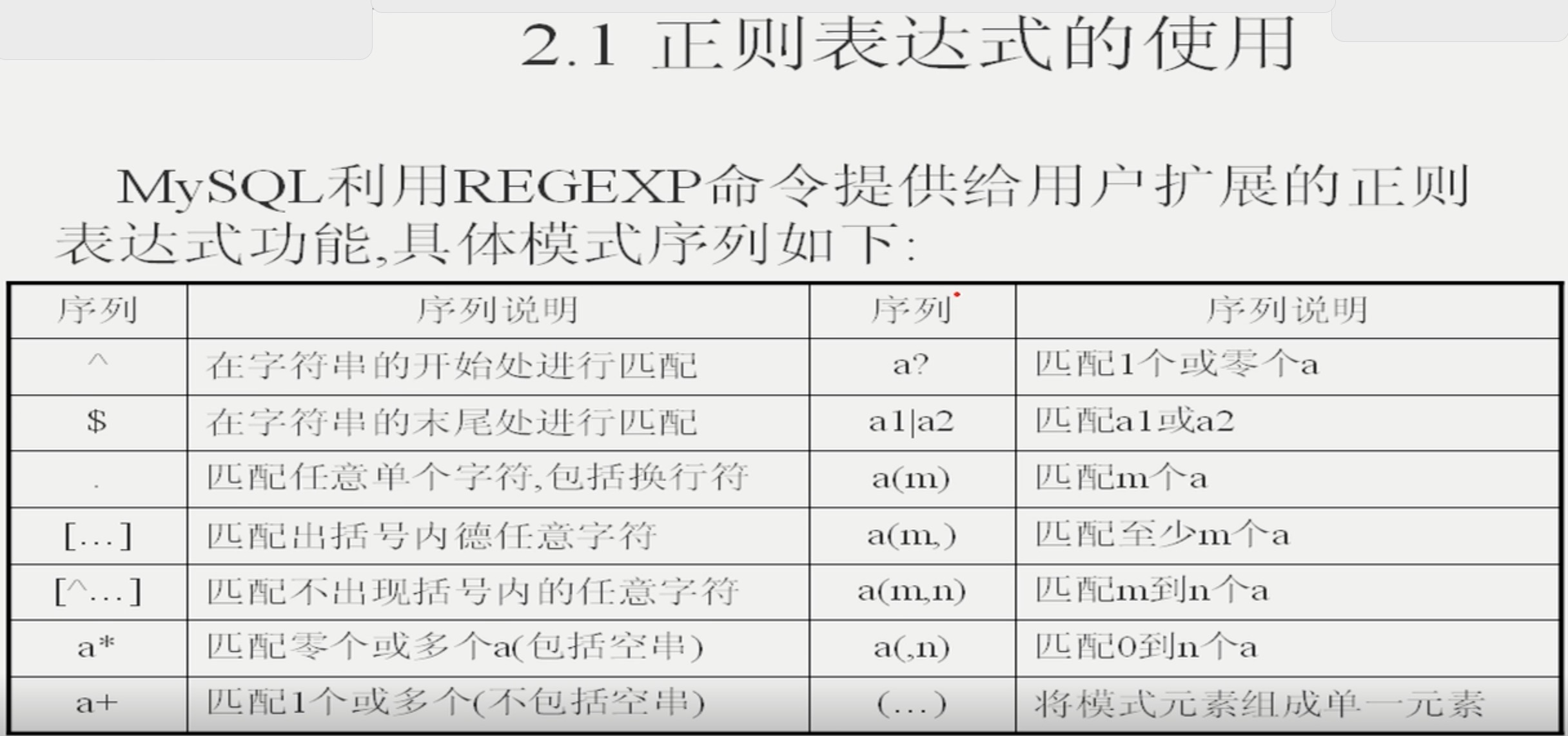
mysql>explain select * from company2 where name=294\G;
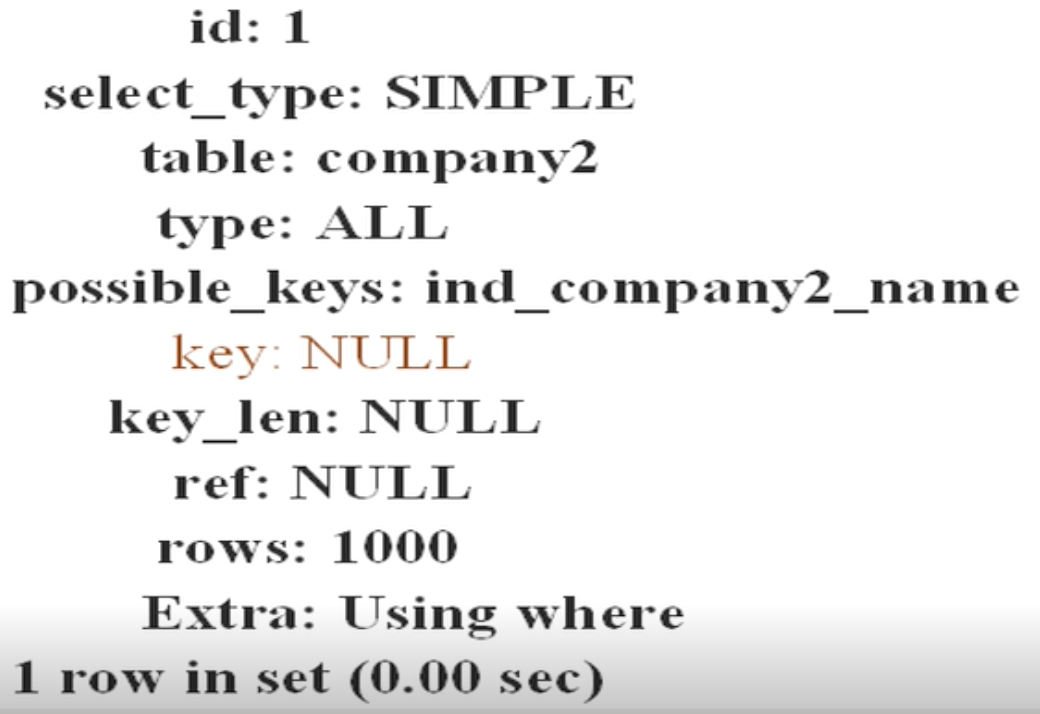
4)查看索引的使用情况
如果索引正在工作,Handler_read_key的值将很高,这个值代了一个行别索引值读的次数。
Handler_read_next的高则意味着查询运行低效,并且应该建立索引补救。
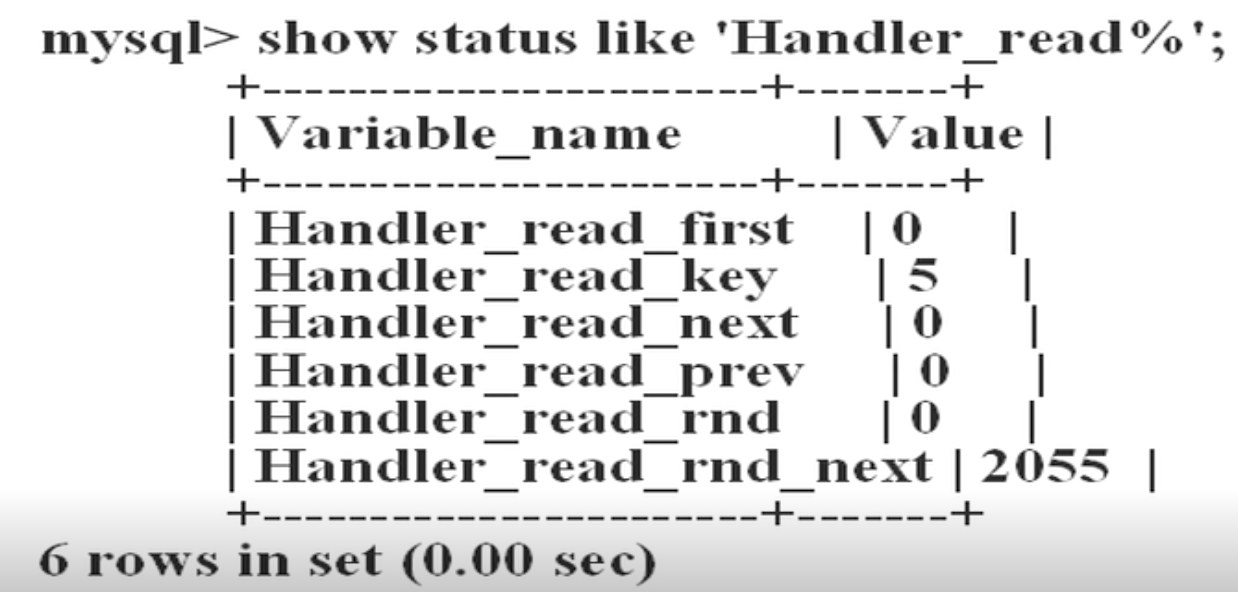
3、两个简单的优化方法
对于多数开发人员来说,可能希望掌握一些简单实用的优化方法,对于更堵更复杂的优化,更倾向于交给作业dba来做。
1)定期分析表和检查表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tal_name[,tbl_name]....
本语句用于分析和储存表的关键字分布,分析的结果将可以得到准确的统计信息,使得sql能够生成正确的行计划。
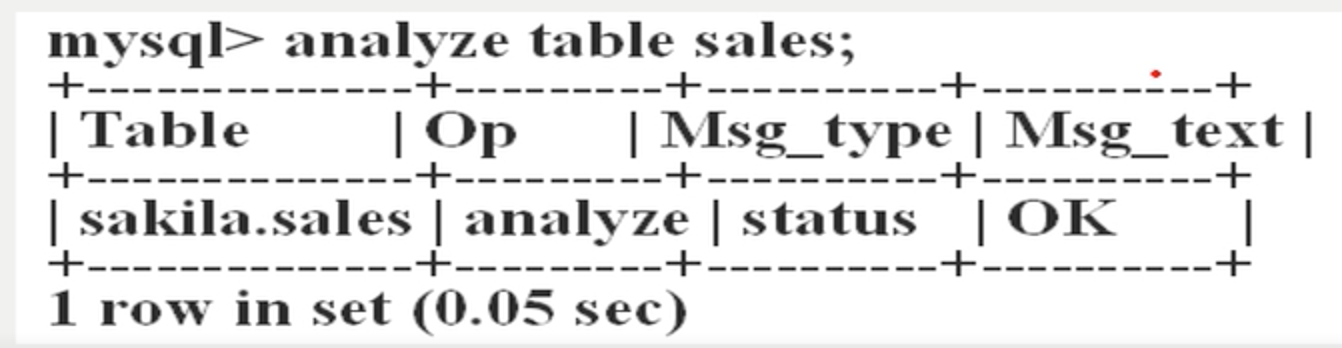

2)定期优化表

4、常用sql的优化
1)大批量插入数据。
当用load命令导入数据库的时候,适当设置可以提高导入速度。
对于myisam存储引擎的表,可以通过以下方式快速的导入大量的数据。
ALTER TABLE tbl_name DISABLE KEYS
loading the data
ALTER TABLE tbl_name ENABLE KEYS
DISABLE KEYS和ENABLE KEYS用来打开或关闭mysiam表非唯一索引的更新,可以提高速度。注意:对innodb表无效。

2)关闭唯一性校验可以提高导入效率。
再倒入数据前限制性set unique_checks=0,关闭唯一性校验,再倒入结束后执行set unique_checks=1,恢复唯一性校验可以提高到付效率。



3)优化insert语句
及两使用多个值表的insert语句,这样可以大大算短客户与数据库的连接、关闭等损耗。
可以使用insert delayed(马上执行)语句得到更高的效率将索引文件和数据文件分别存放不同的磁盘上。
可以增加bulk_buffer_size变量值的方法来提高速度,但是只对myisam表使用。
当一个文件装载一个表时,使用LOAD DATA INFILE。这个通常比使用很多insert语句要快20呗。
4)优化group bu语句
如果查询包含group by但用户想要避免排序结果的损耗,则可以使用order by null来禁止排序:
如下没有使用order by null 来禁止排序。

5)优化order by语句
在某些情况中,mysql可以使用一个索引来满足order by 子句,而不需要额外的排序。where条件和order by使用相同的索引,并且order by的顺序和索引顺序相同,并且order by的字段都是升序或者降序。

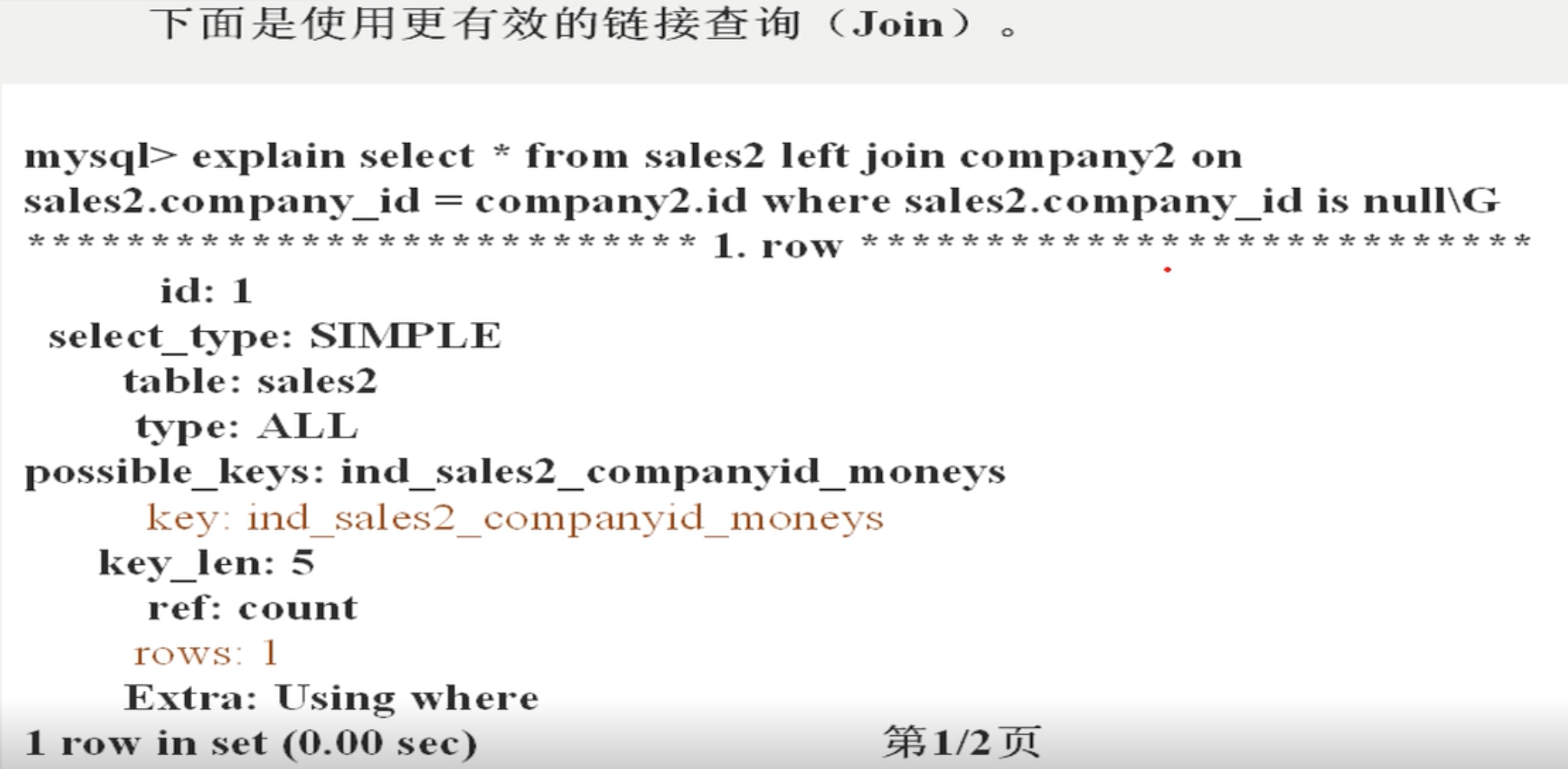
6)优化嵌套查询
下面是采用嵌套查询的效果(可以使用更有效的链接查询(join)替代)
explain select * from sales2 where company_id not in (select id from complany2)\G

Mysql sql语句技巧与优化的更多相关文章
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
- 《MySQL慢查询优化》之SQL语句及索引优化
1.慢查询优化方式 服务器硬件升级优化 Mysql服务器软件优化 数据库表结构优化 SQL语句及索引优化 本文重点关注于SQL语句及索引优化,关于其他优化方式以及索引原理等,请关注本人<MySQ ...
- MySQL SQL查询优化技巧详解
MySQL SQL查询优化技巧详解 本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 ...
- mysql sql语句大全(转载)
1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- 创建 ...
- MySQL客户端工具的使用与MySQL SQL语句
MySQL客户端工具的使用 1.MySQL程序的组成 客户端 mysql:CLI交互式客户端程序 mycli:CLI交互式客户端程序;使用sql语句时会有提示信息 mysql_secure_insta ...
- SQL语句技巧_索引的优化_慢查询日志开启_root密码的破解
1.正则表达式的使用 regexp例:select name,email from t where email regexp '@163[.,]com$'使用like方式查询selct name,em ...
- MYSQL SQL语句优化
1.EXPLAIN 做MySQL优化,我们要善用EXPLAIN查看SQL执行计划. 下面来个简单的示例,标注(1.2.3.4.5)我们要重点关注的数据: type列,连接类型.一个好的SQL语句至少要 ...
- 自制小工具大大加速MySQL SQL语句优化(附源码)
引言 优化SQL,是DBA常见的工作之一.如何高效.快速地优化一条语句,是每个DBA经常要面对的一个问题.在日常的优化工作中,我发现有很多操作是在优化过程中必不可少的步骤.然而这些步骤重复性的执行,又 ...
- MySQL - SQL语句优化方法
1.使用 show status 了解各种 SQL 的执行频率 mysql> show status like 'Com%'; 该命令可以查询 sql 命令的执行次数. 2.定位执行效率较低的 ...
随机推荐
- 求素数p的原根
定义: 设m>1,gcd(a,m)=1,使得成立的最小正整数d为a对模m的阶,记为δm(a) 如果δm(a)=φ(m),则称a是模m的原根 定理:设m>1,gcd(a,m)=1,那么正整数 ...
- 【巨杉数据库SequoiaDB】助力金融科技升级,巨杉数据库闪耀金融展
11月4日,以“科技助创新 开放促改革 发展惠民生”为主题的2019中国国际金融展和深圳国际金融博览会在深圳会展中心盛大开幕. 中国人民银行党委委员.副行长范一飞,深圳市人民政府副市长.党组成员艾学峰 ...
- PHP返回json数据为null
文件编码非utf-8,导致json_encode()返回false:最后前台ajax接收不到数据
- SSM项目集成Lucene+IKAnalyzer在Junit单元测试中执行异常
个人博客 地址:http://www.wenhaofan.com/article/20181108132519 问题描述 在项目运行以及main方法中能够正常运行,但是使用junit单元测试时却报如下 ...
- 题解 CF1064A 【Make a triangle!】
题目传送门 反正数学方法我是不会 那只能模拟了一只连模拟题解都看不懂的哀怨 我的思路大体如下 1.定义3个变量a,b,c并输入 int a,b,c; cin>>a>>b> ...
- spring中实现基于注解实现动态的接口限流防刷
本文将介绍在spring项目中自定义注解,借助redis实现接口的限流 自定义注解类 import java.lang.annotation.ElementType; import java.lang ...
- 163.扩展User模型-一对一方式扩展
一对一外键 如果你对用户验证方法authenticate没有更多的要求,就是使用username和password就可以完成用户的登录验证工作,但是想要在原来的模型的基础上添加新的字段,那么就可以使用 ...
- kali 所有版本
首先打开kali官方网站 第一步 第二步 找到 第三步点击标黄色的地方 http://cdimage.kali.org/ 第四步将网址中的cdimage替换为old http://old.kali.o ...
- mybatis-plus QueryWrapper自定义查询条件
mybatis-plus QueryWrapper自定义查询条件 mybatis-plus框架功能很强大,把很多功能都集成了,比如自动生成代码结构,mybatis crud封装,分页,动态数据源等等, ...
- windows下tesseract-ocr的安装及使用
For CentOS 7 run the following as root: yum-config-manager --add-repo https://download.opensuse.org/ ...