Hadoop学习笔记(三):分布式文件系统的写和读流程
写流程:怎么将文件切割成块,上传到服务器
读流程:怎么从不同的服务器来读取数据块
写流程
图一

图二
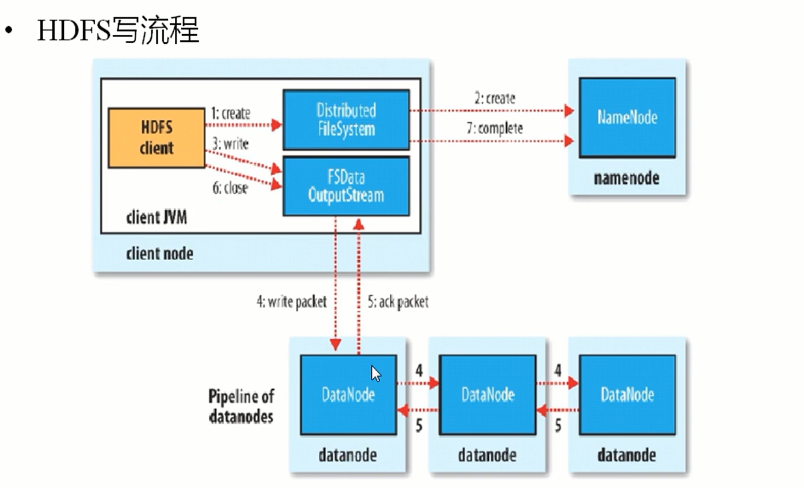
写的过程中:NameNode会给块分配存储块的位置,每次想要存储文件的时候都会在NameNode创建一个path,之后HDFSClient读取和写入数据都是先访问这个NameNode中的path去找从何处去下载文件或者上传文件到哪里,具体的NameNode怎么去分配块的存储位置根据的是图一的原则。
文件写流程的实例辅助理解:
假如我们有一个文件test.txt,想要把它放到Hadoop上,执行如下命令:
引用
# hadoop fs -put /usr/bigdata/dataset/input/20130706/test.txt /opt/bigdata/hadoop/dataset/input/20130706 //或执行下面的命令
# hadoop fs -copyFromLocal /usr/bigdata/dataset/input/20130706/test.txt /opt/bigdata/hadoop/dataset/input/20130706
整个写流程如下:
第一步,客户端调用DistributedFileSystem的create()方法,开始创建新文件:DistributedFileSystem创建DFSOutputStream,产生一个RPC调用,让NameNode在文件系统的命名空间中创建这一新文件;
第二步,NameNode接收到用户的写文件的RPC请求后,谁偶先要执行各种检查,如客户是否有相关的创佳权限和该文件是否已存在等,检查都通过后才会创建一个新文件,并将操作记录到编辑日志,然后DistributedFileSystem会将DFSOutputStream对象包装在FSDataOutStream实例中,返回客户端;否则文件创建失败并且给客户端抛IOException。
第三步,客户端开始写文件:DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。data queue会向NameNode节点请求适合存储数据副本的DataNode节点的列表,然后这些DataNode之前生成一个Pipeline数据流管道,我们假设副本集参数被设置为3,那么这个数据流管道中就有三个DataNode节点。
第四步,首先DFSOutputStream会将packets向Pipeline数据流管道中的第一个DataNode节点写数据,第一个DataNode接收packets然后把packets写向Pipeline中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向Pipeline中的第三个DataNode节点。
第五步,DFSOutputStream内部同样维护另外一个内部的写数据确认队列——ack queue。当Pipeline中的第三个DataNode节点将packets成功保存后,该节点回向第二个DataNode返回一个确认数据写成功的信息,第二个DataNode接收到该确认信息后在当前节点数据写成功后也会向Pipeline中第一个DataNode节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将packets从ack queue中将数据删除。
在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢?如果这种情况发生,那么就会执行一些操作:
首先,Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失,为存储在另一正常dataname的当前数据指定一个新的标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块;
接着,在正常的DataNode节点上的以保存好的block的ID版本会升级——这样发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,失效节点也会被从Pipeline中删除;
最后,剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。
如果Pipeline中的多个节点在写数据是发生失败,那么只要写成功的block的数量达到dfs.replication.min(默认为1),那么就任务是写成功的,然后NameNode后通过一步的方式将block复制到其他节点,最后事数据副本达到dfs.replication参数配置的个数。
第六步,,完成写操作后,客户端调用close()关闭写操作,刷新数据;
第七步,,在数据刷新完后NameNode后关闭写操作流。到此,整个写操作完成。
读流程
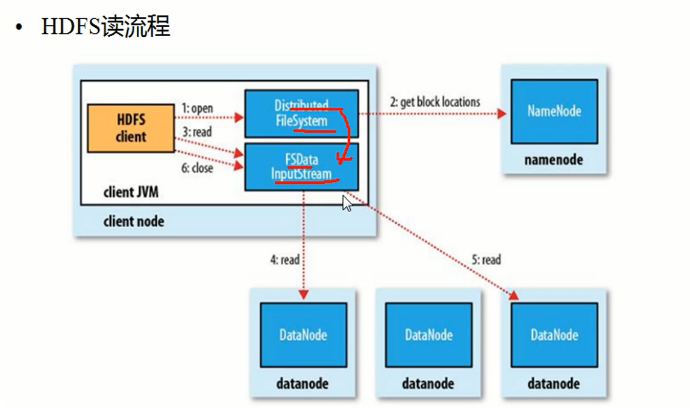
文件读流程的实例辅助理解:
Client调用FileSystem.open()方法:
1 FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有block拷贝的DN地址)。
2 选取举栗客户端最近的DN建立连接,读取block,返回FSDataInputStream。
Client调用输入流的read()方法:
1 当读到block结尾时,FSDataInputStream关闭与当前DN的连接,并未读取下一个block寻找最近DN。
2 读取完一个block都会进行checksum验证,如果读取DN时出现错误,客户端会通知NN,然后再从下一个拥有该block拷贝的DN继续读。
3 如果block列表读完后,文件还未结束,FileSystem会继续从NN获取下一批block列表。
关闭FSDataInputStream

参考链接:https://blog.csdn.net/zhang123456456/article/details/77882866,https://www.cnblogs.com/laowangc/p/8949850.html;
Hadoop学习笔记(三):分布式文件系统的写和读流程的更多相关文章
- Hadoop学习笔记【分布式文件系统学习笔记】
分布式文件系统介绍 分布式文件系统:Hadoop Distributed File System,简称HDFS. 一.HDFS简介 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(c ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- 大数据学习笔记2 - 分布式文件系统HDFS(待续)
分布式文件系统结构 分布式文件系统是一种通过网络实现文件在多台主机上进行分布式存储的文件系统,采用C/S模式实现文件系统数据访问,目前广泛应用的分布式文件系统主要包括GFS和HDFS,后者是前者的开源 ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Hadoop学习笔记三
一.设置HDFS不进行权限检查 默认的HDFS上的文件类似于Linux中的文件,是有权限的.例如test用户创建的文件,root用户如果没有写权限,则不能进行删除. 有2种办法进行修改,修改文件的权限 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- Hadoop概念学习系列之分布式文件系统(三十)
===============> 数据量越来越多,在一个操作系统管辖的范围存下不了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就 ...
- Hadoop学习笔记(1):概念和整体架构
Hadoop简介和历史 Hadoop架构体系 Master和Slave节点 数据分析面临的问题和Hadoop思想 由于工作原因,必须学习和深入一下Hadoop,特此记录笔记. 什么是hadoop? A ...
随机推荐
- Spring核心知识
目录 Spring 概述 依赖注入 Spring beans Spring注解 Spring数据访问 Spring面向切面编程(AOP) Spring MVC Spring 概述 1. 什么是spri ...
- 利用python装饰器为字符串添加,HTML标签
# 为字符串添加HTML标签 import time def zhuang(fun): def zhaung_1(*args, **kargs): # time.sleep(1) html_str = ...
- C++ 中字符串查找、字符串截取、字符串替换
参照:C++基础-string截取.替换.查找子串函数 1.字符串查找 s.find(s1) //查找s中第一次出现s1的位置,并返回(包括0) s.rfind(s1) //查找s中最后次出现s1的位 ...
- 屏蔽tips
在屏蔽的地方打上记号,这样解屏蔽时就容易找到屏蔽的地方了
- Spring Boot项目指定启动后执行的操作
Spring Boot项目指定启动后执行的操作: (1)实现CommandLineRunner 接口 (2)重写run方法 (3)声明执行顺序@Order(1),数值越小,优先级越高 (4)如果需要注 ...
- centos6 源码编译安装nginx 1.6 教程 nginx安装脚本
操作系统centos 6.9 安装nginx需要pcre zlib openssl的库,下文都是在官网直接下载用作编译安装 该nginx安装教程,有安装maxmind IP 库 该教材有修改最大打开文 ...
- spring cloud config 连接GitHub访问 报错 Cannot clone or checkout repository
原因是建立仓库的时候将仓库私有化了,将仓库公有 或者 设置账号密码即可!
- ColorPix——到目前为止最好用的屏幕取色器
分享一个颜色取色器网页.PPT.EXCEL配色不再烦恼 简单易用 大家做商业.企业报告的时候是不是经常遇到要调色的困扰呢?PPT.EXCEL等颜色选取会对报告有质的影响!!要更专业要更有美感!给大家分 ...
- 计算几何-HPI
This article is made by Jason-Cow.Welcome to reprint.But please post the article's address. 在线笛卡尔坐 ...
- sqli-libs(46-53关)
Less_46 补充知识:MySQL知识 SQL语句中,asc是指定列按升序排列,desc则是指定列 按降序排列: Select * from users order by 1 desc; 使用降序进 ...