机器学习之路--seaborn
seaborn是基于plt的封装好的库。有很强的作图功能。
1、布局风格设置(图形的style)and 细节设置
用matplotlib作图:

import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
x = np.linspace(0, 14, 100)
for i in range(1, 7):
plt.plot(x, np.sin(x + i * .5) * (7 - i))
plt.show()
输出:

用seaborn的默认系统风格:
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
# def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 7):
plt.plot(x, np.sin(x + i * .5) * (7 - i))
sns.set()
plt.show()
输出:
下面介绍seaborn的五种作图风格:
- darkgrid
- whitegrid
- dark
- white
- ticks
下面介绍常用的一种,其他可用代码自行查看
whitegrid
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt sns.set_style("whitegrid") #设置风格
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2 #创建数据
sns.boxplot(data=data) #制作盒图
plt.show()
输出:
此风格可以清晰看到数据的值与对应关系,也很简约,建议用此图。
指定轴线距离:
#f, ax = plt.subplots()
sns.violinplot(data)
sns.despine(offset=10)
offset的值为轴线距离
将左边的轴隐藏起来:(单个轴显示问题)
sns.despine(left=True)
用两种主题做图:
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2
with sns.axes_style("darkgrid"):
sns.boxplot(data=data)
plt.show()
sns.boxplot(data=data)
plt.show()
with里面的是一种风格,外边是另一种
画图的页面布局:
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt sns.set_context("paper") #除了paper还有别的布局,help查看
plt.figure(figsize=(8, 6)) #大小
sns.set()
x = np.linspace(0, 14, 100)
for i in range(1, 7):
plt.plot(x, np.sin(x + i * .5) * (7 - i))
plt.show()
2、调色板
- 颜色很重要
- color_palette()能传入任何Matplotlib所支持的颜色
- color_palette()不写参数则默认颜色
- set_palette()设置所有图的颜色
6个默认的颜色循环主题: deep, muted, pastel, bright, dark, colorblind
圆形画板****
当你有六个以上的分类要区分时,最简单的方法就是在一个圆形的颜色空间中画出均匀间隔的颜色(这样的色调会保持亮度和饱和度不变)。这是大多数的当他们需要使用比当前默认颜色循环中设置的颜色更多时的默认方案。
最常用的方法是使用hls的颜色空间,这是RGB值的一个简单转换。
import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
sns.palplot(sns.color_palette("hls", 8))
plt.show()
输出:

import seaborn as sns
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
data = np.random.normal(size=(20, 8)) + np.arange(8) / 2
sns.boxplot(data=data,palette=sns.color_palette("hls", 8))
plt.show()
hls_palette()函数来控制颜色的亮度和饱和
- l-亮度 lightness
- s-饱和 saturation
sns.palplot(sns.hls_palette(8, l=.7, s=.9))
使用xkcd命名颜色
连续色板
色彩随数据变换,比如数据越来越重要则颜色越来越深
sns.palplot(sns.color_palette("Blues"))
输出:

如果想要翻转渐变,可以在面板名称中添加一个_r后缀:
sns.palplot(sns.color_palette("BuGn_r"))
色调线性变换(饱和度和亮度)
sns.palplot(sns.cubehelix_palette(8, start=.75, rot=-.150))
light_palette() 和dark_palette()调用定制连续调色板
sns.palplot(sns.light_palette("green"))
上面是由浅变深
下面是由深变暗:
sns.palplot(sns.light_palette("navy", reverse=True))
x, y = np.random.multivariate_normal([0, 0], [[1, -.5], [-.5, 1]], size=300).T
pal = sns.dark_palette("green", as_cmap=True)
sns.kdeplot(x, y, cmap=pal);
输出:

3、单变量分析绘图
%matplotlib inline
import numpy as np
import pandas as pd
from scipy import stats, integrate
import matplotlib.pyplot as plt import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "distributions")))
首先导入库,指定一个高斯分布的图
然后绘制出一个直方图:
x = np.random.normal(size=100)
sns.distplot(x,kde=False)
sns.distplot(x, bins=20, kde=False) #bins指定直方图的宽度
如果要画出一个数据的分布情况,可以:
x = np.random.gamma(6, size=200)
sns.distplot(x, kde=False, fit=stats.gamma)
根据均值和协方差生成数据
mean, cov = [0, 1], [(1, .5), (.5, 1)] #mean为均值,cov协方差
data = np.random.multivariate_normal(mean, cov, 200) #生成200组数据
df = pd.DataFrame(data, columns=["x", "y"]) #数据类型为panda的dataframe
df #输出

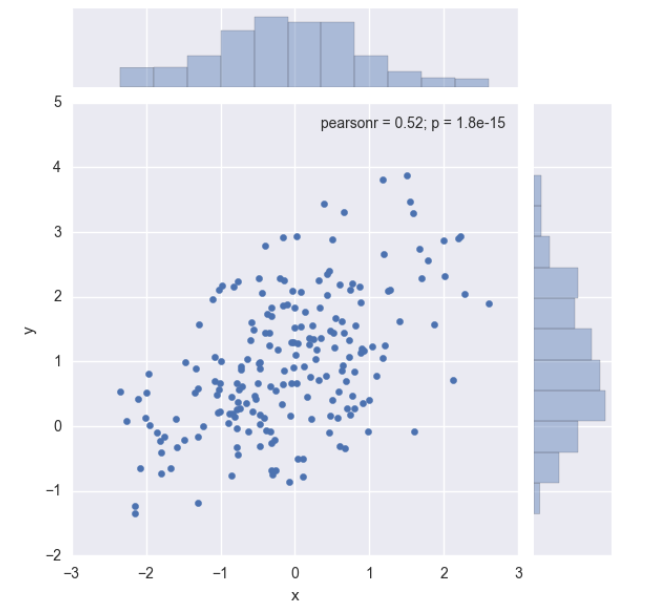
观察两个变量之间的分布情况:(散点图)
sns.jointplot(x="x", y="y", data=df);
输出:
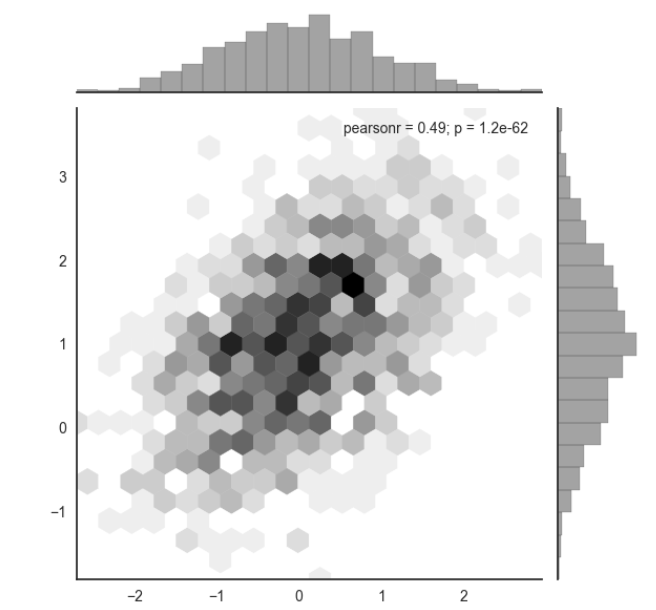
如果数据太多,点太过密集又想看分布情况:
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("white"): #指定绘图风格
sns.jointplot(x=x, y=y, kind="hex", color="k") #kind=hex
4、多变量分析绘图
iris = sns.load_dataset("iris") #传入数据
sns.pairplot(iris)
输出:

一共是四组数据,对角线因为是单个数据所以是单个数据的直方图,散点图都是由两组数据得来的。
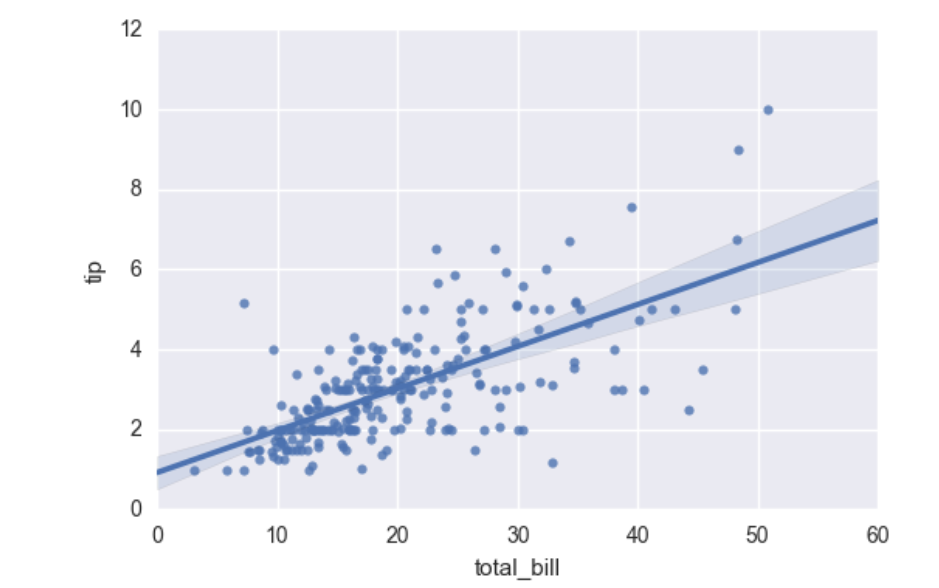
regplot()和lmplot()都可以绘制回归关系,推荐regplot()
sns.regplot(x="total_bill", y="tip", data=tips)
输出:
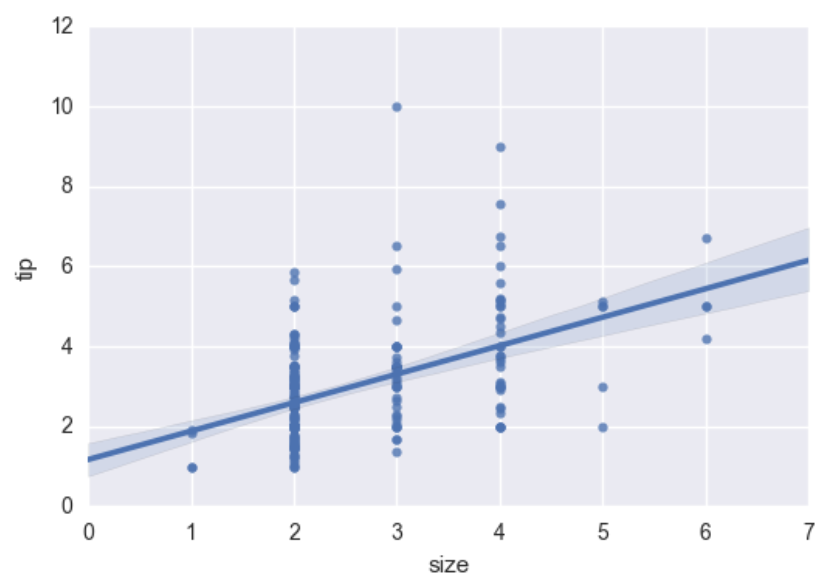
如果值为整数,不适合建立回归模型,如:
sns.regplot(data=tips,x="size",y="tip")
输出:
我们可以给它加上一个小范围的浮动:
sns.regplot(x="size", y="tip", data=tips, x_jitter=.05)
输出:
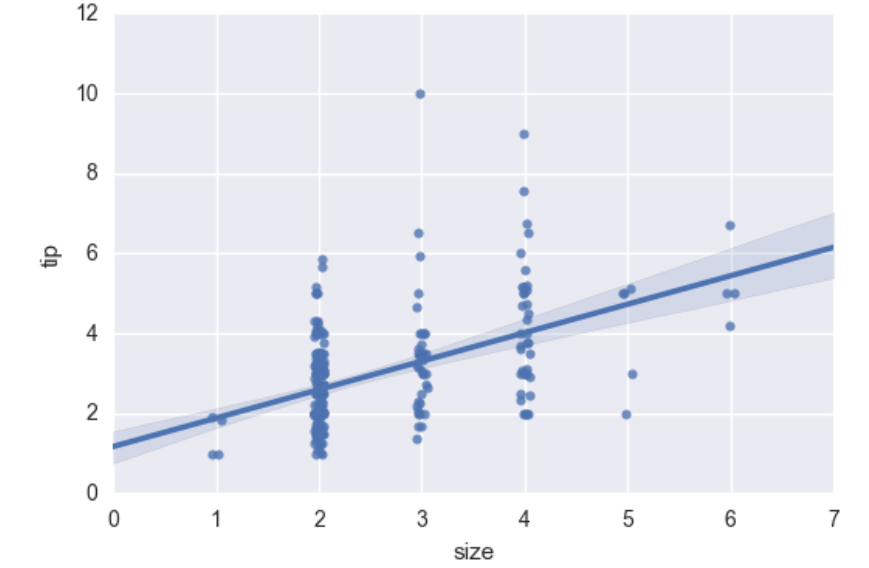
离群点
小提琴图
先导入数据:
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid", color_codes=True) np.random.seed(sum(map(ord, "categorical")))
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")
正常作图:
sns.stripplot(x="day", y="total_bill", data=tips);
输出:
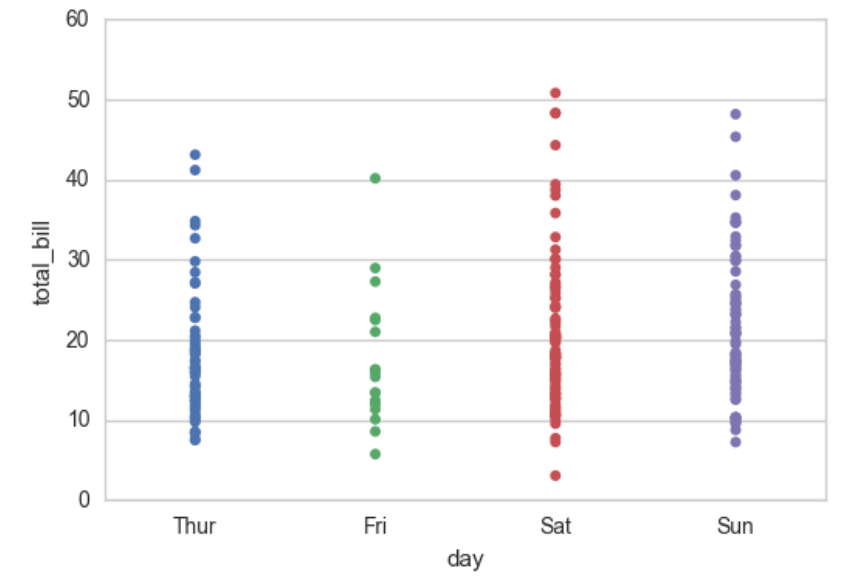
这样会导致数据重叠,影响观察。
可以添加:
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True) #jitter=True
输出:
不太好看,所以我们也可以:
sns.swarmplot(x="day", y="total_bill", data=tips)
这样输出的图是左右均匀的:
还可以在图中加一个分类的特征:
sns.swarmplot(x="day", y="total_bill", hue="sex",data=tips)
输出:
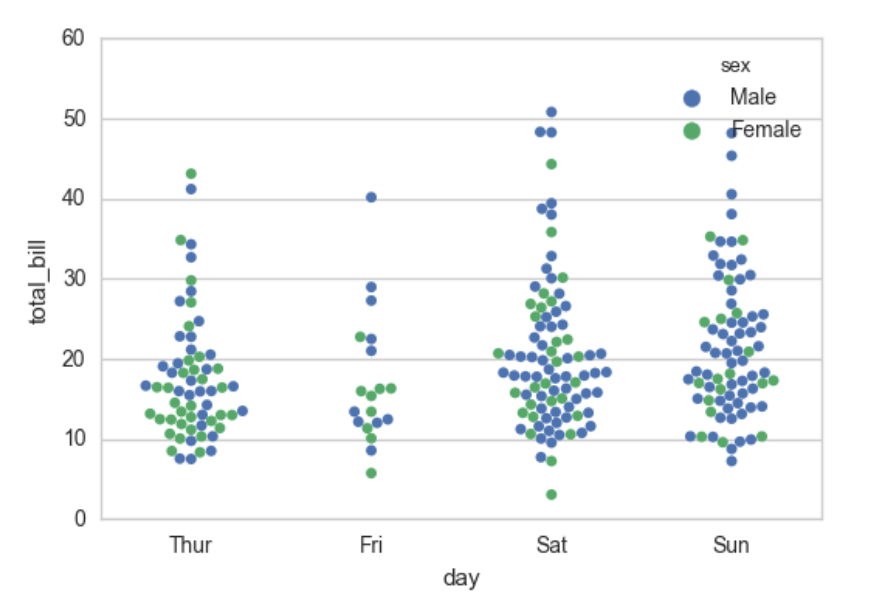
盒图
- IQR即统计学概念四分位距,第一/四分位与第三/四分位之间的距离
- N = 1.5IQR 如果一个值>Q3+N或 < Q1-N,则为离群点
sns.boxplot(x="day", y="total_bill", hue="time", data=tips);
输出:
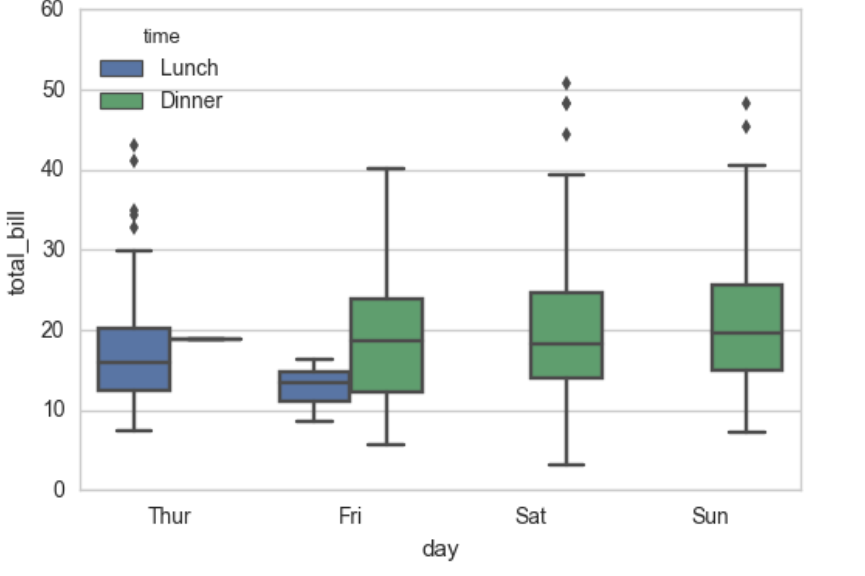
上面的点是离群点
小提琴图:(反映分布情况)
sns.violinplot(x="total_bill", y="day", hue="time", data=tips);
输出:
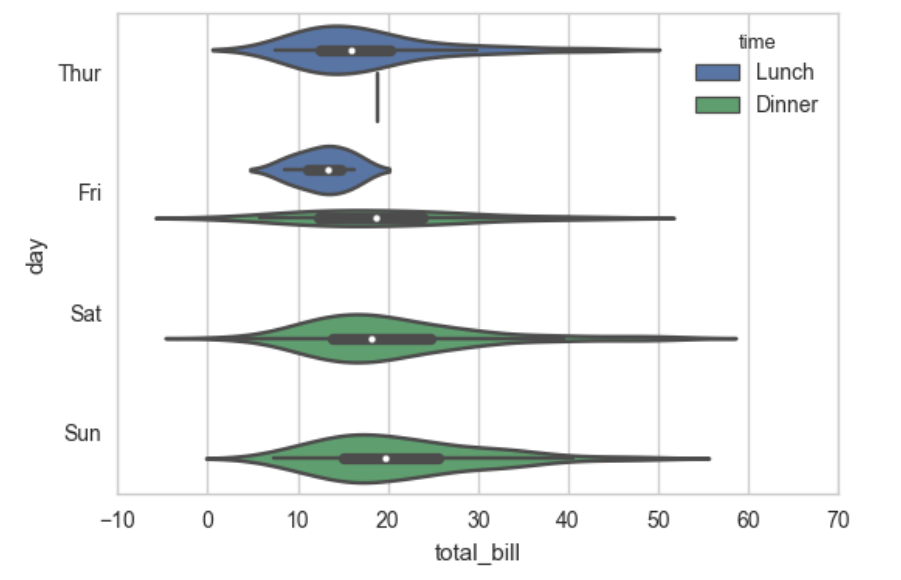
对time分类后不直观也不好看,我们可以:
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True);
让spilt = True,使得直观好看:
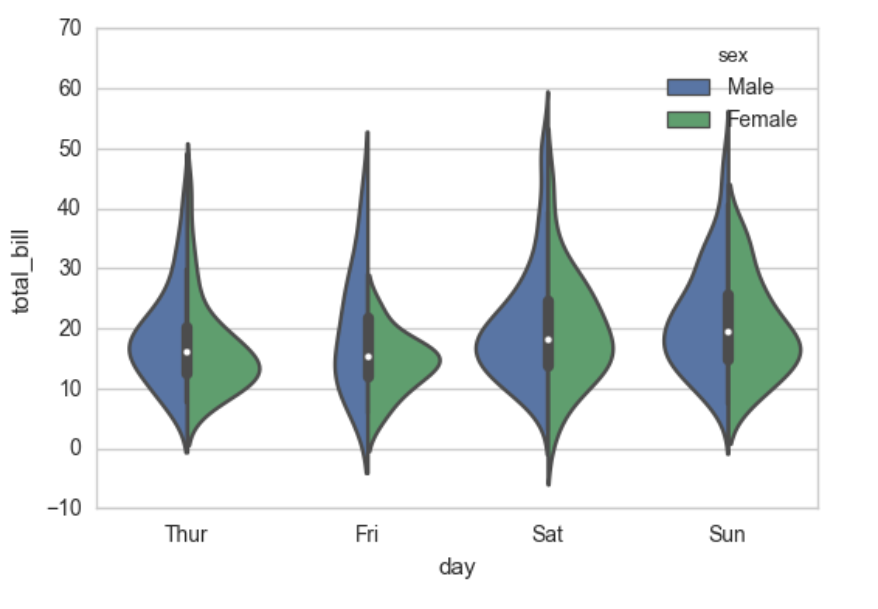
显示值的集中趋势可以用条形图
sns.barplot(x="sex", y="survived", hue="class", data=titanic);
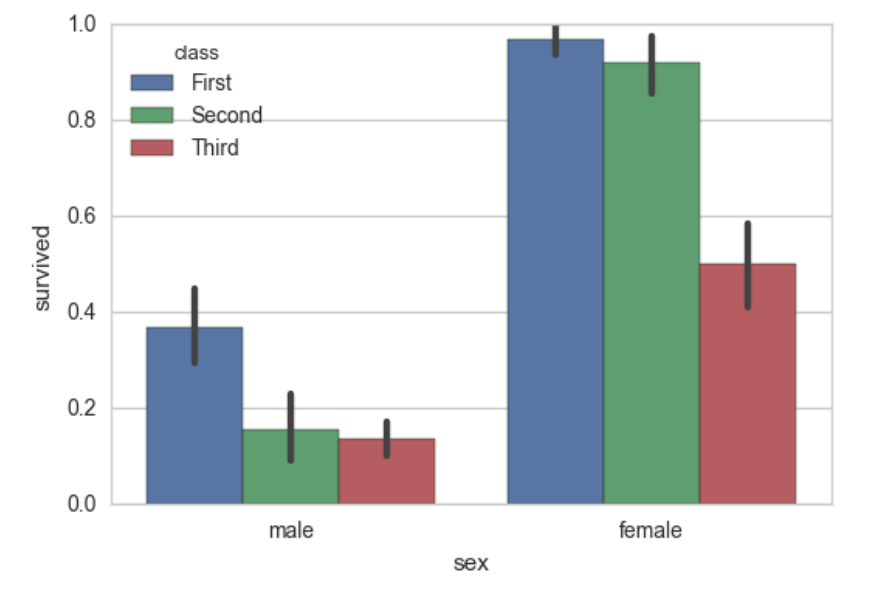
点图可以更好的描述变化差异
sns.pointplot(x="sex", y="survived", hue="class", data=titanic) #hue表示指标

对于点图,还可以将图画的好看一点,设置一些参数
sns.pointplot(x="class", y="survived", hue="sex", data=titanic,
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"]);
输出:

宽型数据
sns.boxplot(data=iris,orient="h")
orient = "h"将图弄成横着的
****多层面板分类图
这个将之前的几种整合到一起,将图的类型作为参数传入
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips)
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips, kind="bar") #kind为图的类型
sns.factorplot(x="day", y="total_bill", hue="smoker",
col="time", data=tips, kind="swarm")
输出:
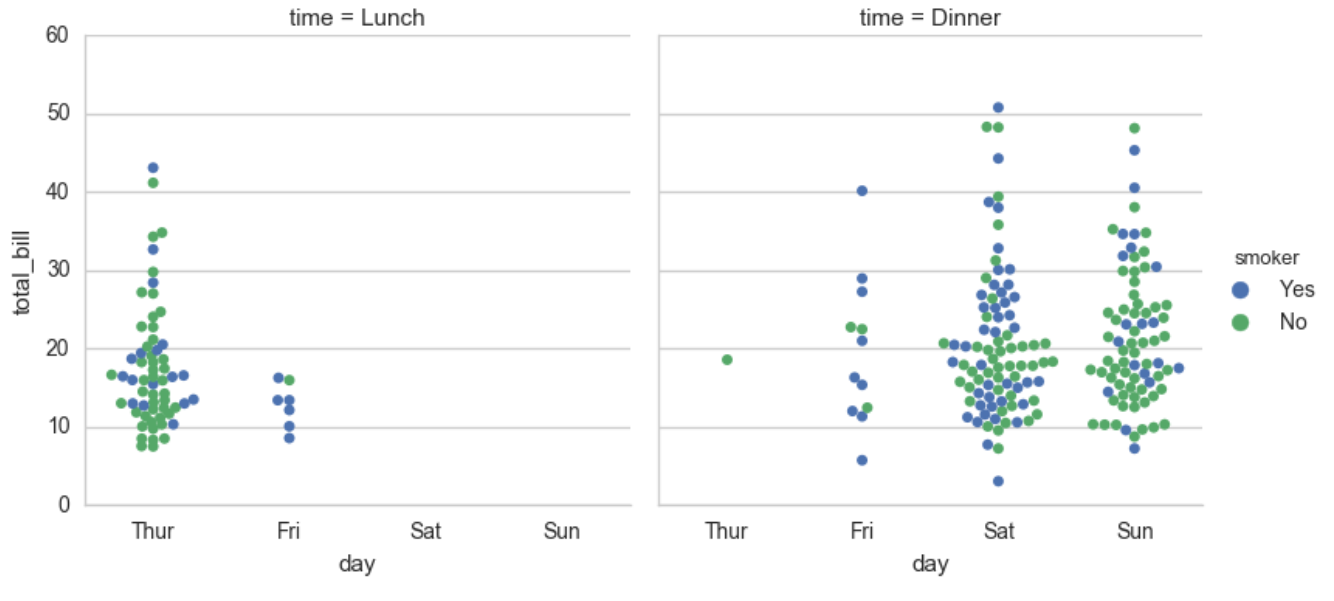
sns.factorplot(x="time", y="total_bill", hue="smoker",
col="day", data=tips, kind="box", size=4, aspect=.5) #指定宽度和大小
关于factorplot
seaborn.factorplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='point', size=4, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs) Parameters:
•x,y,hue 数据集变量 变量名
•date 数据集 数据集名
•row,col 更多分类变量进行平铺显示 变量名
•col_wrap 每行的最高平铺数 整数
•estimator 在每个分类中进行矢量到标量的映射 矢量
•ci 置信区间 浮点数或None
•n_boot 计算置信区间时使用的引导迭代次数 整数
•units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
•order, hue_order 对应排序列表 字符串列表
•row_order, col_order 对应排序列表 字符串列表
•kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点 size 每个面的高度(英寸) 标量 aspect 纵横比 标量 orient 方向 "v"/"h" color 颜色 matplotlib颜色 palette 调色板 seaborn颜色色板或字典 legend hue的信息面板 True/False legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False share{x,y} 共享轴线 True/False
5、facetgrid使用方法及绘制多变量
先导入:
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
import matplotlib as mpl
import matplotlib.pyplot as plt sns.set(style="ticks")
np.random.seed(sum(map(ord, "axis_grids")))
先看看数据:
tips = sns.load_dataset("tips")
tips.head()
将图先实例化出来:
g = sns.FacetGrid(tips, col="time")
g = sns.FacetGrid(tips, col="time")
g.map(plt.hist, "tip") #条形图,tip为x轴
g = sns.FacetGrid(tips, col="sex", hue="smoker") #
g.map(plt.scatter, "total_bill", "tip", alpha=.7) #alpha为透明度
g.add_legend() #加入图例(最右边的)

g = sns.FacetGrid(tips, row="smoker", col="time", margin_titles=True)
g.map(sns.regplot, "size", "total_bill", color=".1", fit_reg=False, x_jitter=.1) #fit_reg 表示回归的直线要不要画出来, x_jitter表示抖动区间

g = sns.FacetGrid(tips, col="day", size=4, aspect=.5) #宽度和大小
g.map(sns.barplot, "sex", "total_bill") #先x后y
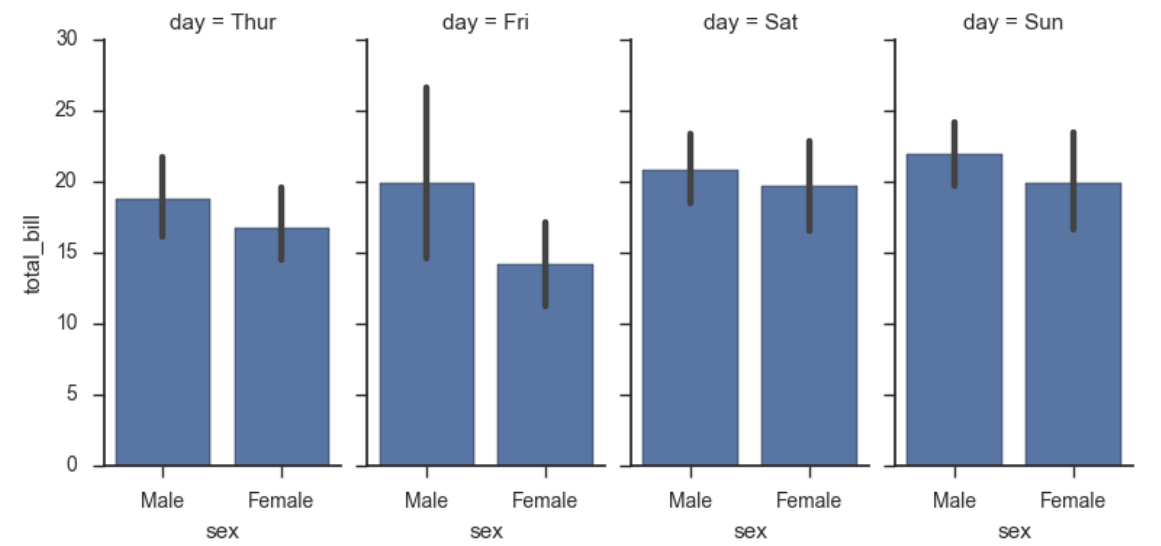
如果想指定图的顺序:
from pandas import Categorical
ordered_days = tips.day.value_counts().index
print (ordered_days) #CategoricalIndex(['Sat', 'Sun', 'Thur', 'Fri']
ordered_days = Categorical(['Thur', 'Fri', 'Sat', 'Sun']) #指定顺序
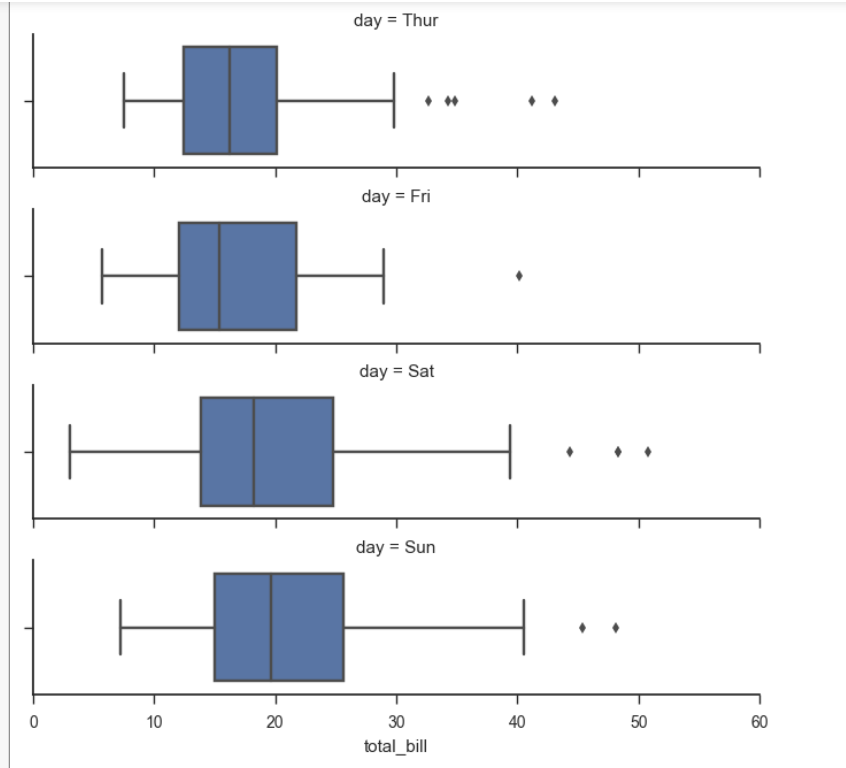
g = sns.FacetGrid(tips, row="day", row_order=ordered_days,
size=1.7, aspect=4,)
g.map(sns.boxplot, "total_bill")
pal = dict(Lunch="seagreen", Dinner="gray")
g = sns.FacetGrid(tips, hue="time", palette=pal, size=5) #palette表示调色板
g.map(plt.scatter, "total_bill", "tip", s=50, alpha=.7, linewidth=.5, edgecolor="white") #s表示点的大小
g.add_legend()
g = sns.FacetGrid(tips, hue="sex", palette="Set1", size=5, hue_kws={"marker": ["^", "v"]}) #点的形状
g.map(plt.scatter, "total_bill", "tip", s=100, linewidth=.5, edgecolor="white")
g.add_legend();
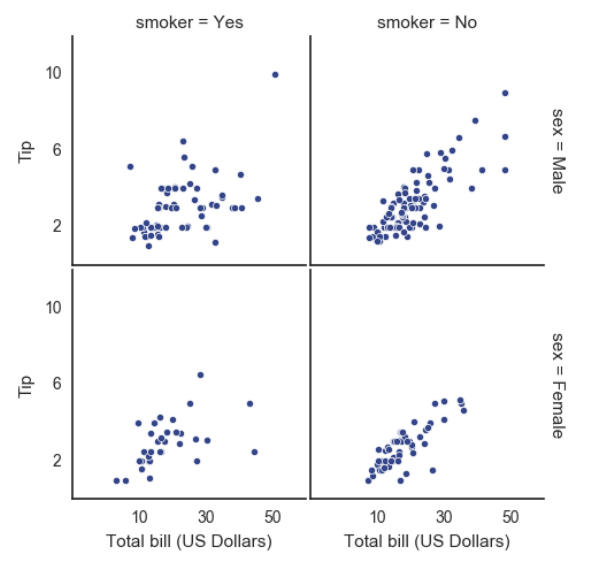
with sns.axes_style("white"):
g = sns.FacetGrid(tips, row="sex", col="smoker", margin_titles=True, size=2.5) #指定风格
g.map(plt.scatter, "total_bill", "tip", color="#334488", edgecolor="white", lw=.5);
g.set_axis_labels("Total bill (US Dollars)", "Tip"); #横轴与纵轴的名称
g.set(xticks=[10, 30, 50], yticks=[2, 6, 10]); #横轴与纵轴要表现的值
g.fig.subplots_adjust(wspace=.02, hspace=.02); #子图之间的距离
iris = sns.load_dataset("iris")
g = sns.PairGrid(iris) #绘制多变量
g.map(plt.scatter);
g = sns.PairGrid(iris)
g.map_diag(plt.hist) #指定对角线图的类型
g.map_offdiag(plt.scatter) #指定非对角线图的类型
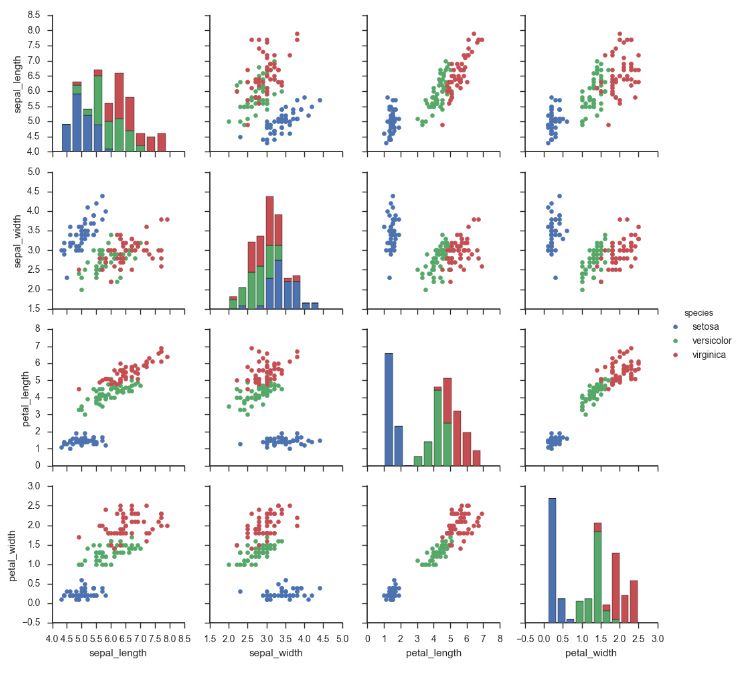
g = sns.PairGrid(iris, hue="species")
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter)
g.add_legend();
如果不想把所有特征都弄出来,可以
g = sns.PairGrid(iris, vars=["sepal_length", "sepal_width"], hue="species") #指定需要的特征
g.map(plt.scatter);
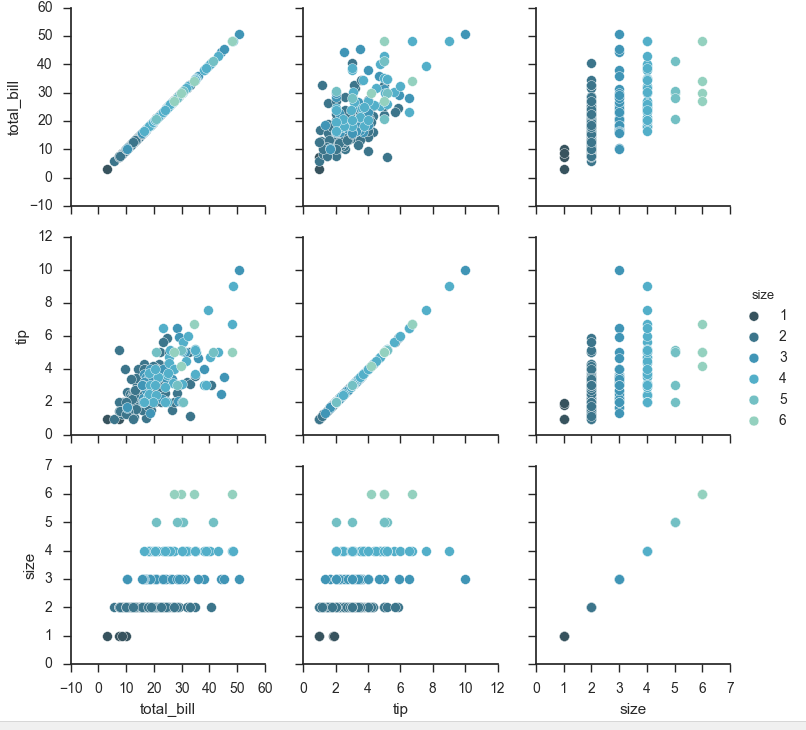
g = sns.PairGrid(tips, hue="size", palette="GnBu_d") #将颜色弄成渐变色
g.map(plt.scatter, s=50, edgecolor="white")
g.add_legend();
6、热度图绘制
先导入库:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np;
np.random.seed(0)
import seaborn as sns;
sns.set()
用random提供随机的数据:
uniform_data = np.random.rand(3, 3)
"""
[[ 0.0187898 0.6176355 0.61209572]
[ 0.616934 0.94374808 0.6818203 ]
[ 0.3595079 0.43703195 0.6976312 ]]
"""
heatmap = sns.heatmap(uniform_data)
输出: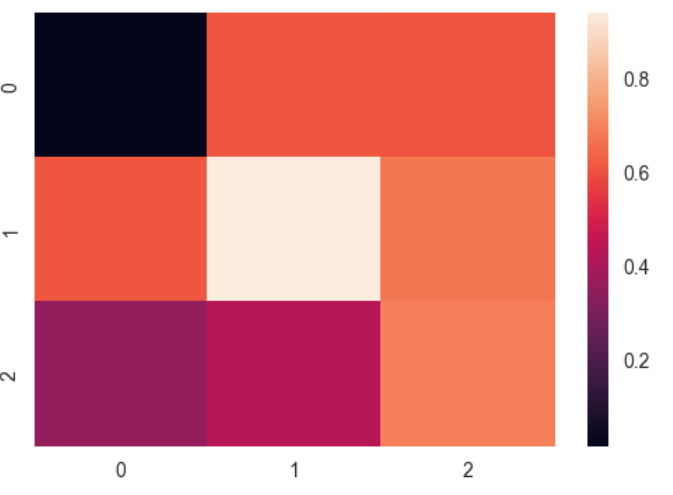
ax = sns.heatmap(uniform_data, vmin=0.2, vmax=0.5) #设置调色板上下限
normal_data = np.random.randn(3, 3) #随机数有负数
print (normal_data)
ax = sns.heatmap(normal_data, center=0) #让调色板的中心为0
flights = sns.load_dataset("flights") #库提供的数据
flights.head()
flights = flights.pivot("month", "year", "passengers")
print (flights)
ax = sns.heatmap(flights)
输出:
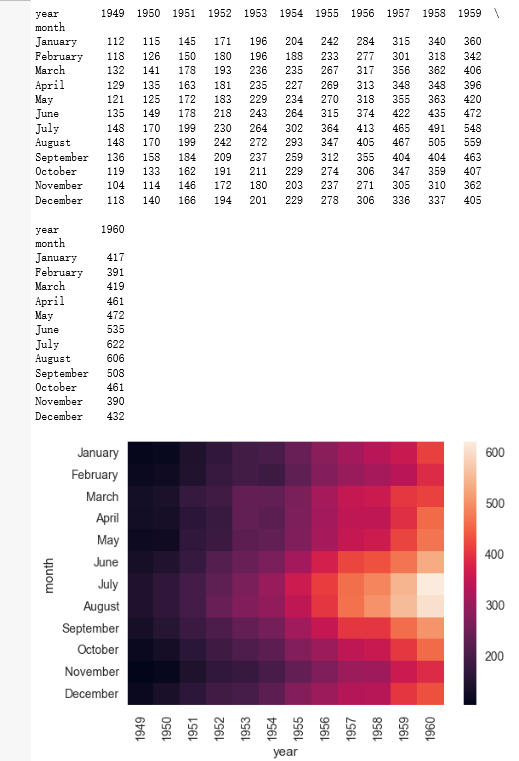
如果要让数字显示出来:
ax = sns.heatmap(flights, annot=True,fmt="d") #annot显示数字 fmt设置数字格式
让图中数据更明显:
ax = sns.heatmap(flights, linewidths=.5) #设置小格宽度
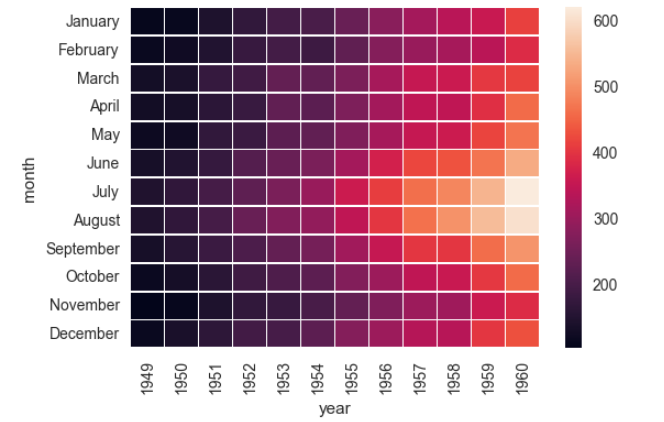
自定义颜色:
ax = sns.heatmap(flights, cmap="YlGnBu")
机器学习之路--seaborn的更多相关文章
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 机器学习之路:python k近邻回归 预测波士顿房价
python3 学习机器学习api 使用两种k近邻回归模型 分别是 平均k近邻回归 和 距离加权k近邻回归 进行预测 git: https://github.com/linyi0604/Machine ...
- 机器学习之路:python线性回归分类器 LogisticRegression SGDClassifier 进行良恶性肿瘤分类预测
使用python3 学习了线性回归的api 分别使用逻辑斯蒂回归 和 随机参数估计回归 对良恶性肿瘤进行预测 我把数据集下载到了本地,可以来我的git下载源代码和数据集:https://gith ...
- 我的机器学习之路--anaconda环境搭载
网上许多教程比较晦涩难懂,本教程按照笔者(新手)自己的视角记录,希望给大家一些帮助 1.安装anaconda 目前比较推荐的机器学习环境为anaconda. Anaconda指的是一个开源的Pytho ...
- 机器学习之路--KNN算法
机器学习实战之kNN算法 机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少: (1)python3.52,64位,这是我用的python ...
- 机器学习之路: 深度学习 tensorflow 神经网络优化算法 学习率的设置
在神经网络中,广泛的使用反向传播和梯度下降算法调整神经网络中参数的取值. 梯度下降和学习率: 假设用 θ 来表示神经网络中的参数, J(θ) 表示在给定参数下训练数据集上损失函数的大小. 那么整个优化 ...
- 机器学习之路: tensorflow 自定义 损失函数
git: https://github.com/linyi0604/MachineLearning/tree/master/07_tensorflow/ import tensorflow as tf ...
- 机器学习之路:tensorflow 深度学习中 分类问题的损失函数 交叉熵
经典的损失函数----交叉熵 1 交叉熵: 分类问题中使用比较广泛的一种损失函数, 它刻画两个概率分布之间的距离 给定两个概率分布p和q, 交叉熵为: H(p, q) = -∑ p(x) log q( ...
- 机器学习之路: tensorflow 一个最简单的神经网络
git: https://github.com/linyi0604/MachineLearning/tree/master/07_tensorflow/ import tensorflow as tf ...
随机推荐
- Android Listview中Button按钮点击事件冲突解决办法
今天做项目时,ListView中含有了Button组件,心里一早就知道肯定会有冲突,因为以前就遇到过,并解决过,可惜当时没有记录下来. 今天在做的时候,继续被这个问题郁闷了一把,后来解决后,赶紧来记录 ...
- H3C RARP
- 数据存储在哪里? Java是值传递还是引用传递?
寄存器 : 最快的存储区,位于处理器中,寄存器会按需求自行分配空间,java不能控制寄存器,所以在程序中感觉不到它的存在 栈(stack) : 位于RAM(内存)中,速度仅次于寄存器,存储对象的引用( ...
- linux用户权限管理, chmod, ln
1 /etc/passwd文件 用户名 密码 UID GID Full Name 主目录 ...
- php 使用正则匹配中文 返回结果
$str = 'eg5455正则匹配中文123三国杀'; $patten='/[\x{4e00}-\x{9fa5}]+/u'; $a = preg_match($patten, $str, $mn); ...
- hdu 1128 Self Numbers
Self Numbers Time Limit: 20000/10000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...
- H3C PPP基本概念
- PHP+MySQL实现对一段时间内每天数据统计优化操作实例
http://www.jb51.net/article/136685.htm 这篇文章主要介绍了PHP+MySQL实现对一段时间内每天数据统计优化操作,结合具体实例形式分析了php针对mysql查询统 ...
- SpringSide 3 中的安全框架
在SpringSide 3的官方文档中,说安全框架使用的是Spring Security 2.0.乍一看,吓了我一跳,以为Acegi这么快就被淘汰了呢.上搜索引擎一搜,发现原来Spring Secur ...
- tp框架使用心得(六)——分页查询
http://baijiahao.baidu.com/s?id=1578482537511010805&wfr=spider&for=pc 在用thinkphp中,对于新手手册中还是有 ...