一句话介绍python线程、进程和协程
一、进程:
Python的os模块封装了常见的系统调用,其中就包括fork。而fork是linux常用的产生子进程的方法,简言之是一个调用,两个返回。
在python中,以下的两个模块用于进程的使用。详细就不展开。
multiprocessing:跨平台版本的多进程模块。
Pool:进程池
Queue、Pipes:进程通信
二、线程:
严格意义上,python的多线程属于伪多线程,因为受限于GIL,python的多线程每次只能执行一个,按流水线方式执行所有任务。
threading:高级创建线程模块
threading.Lock(): lock.acquire()获取 lock.release()释放
三、ThreadLocal
定义全局变量,每个thread对他都有读写操作,但是该全局变量的属性值是每个thread的局部变量,不同thread中的局部变量不能互相修改。
计算密集型 vs. IO密集型
受限于GIL,python的多线程属于伪线程,即是每个cpu一次只能执行一个线程。
计算密集型:多进程
IO密集型:多线程,比如爬虫,时间多花费在io操作上
四、分布式进程
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。
服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
# taskmanager.py import random, time, Queue
from multiprocessing.managers import BaseManager # 发送任务的队列:
task_queue = Queue.Queue()
# 接收结果的队列:
result_queue = Queue.Queue() # 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass # 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口5000, 设置验证码'abc':
manager = QueueManager(address=('', 5000), authkey='abc')
# 启动Queue:
manager.start()
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown()
本机上启动或另一台机子上启动:
# taskworker.py import time, sys, Queue
from multiprocessing.managers import BaseManager # 创建类似的QueueManager:
class QueueManager(BaseManager):
pass # 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue') # 连接到服务器,也就是运行taskmanager.py的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与taskmanager.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey='abc')
# 从网络连接:
m.connect()
# 获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')
工作如图:
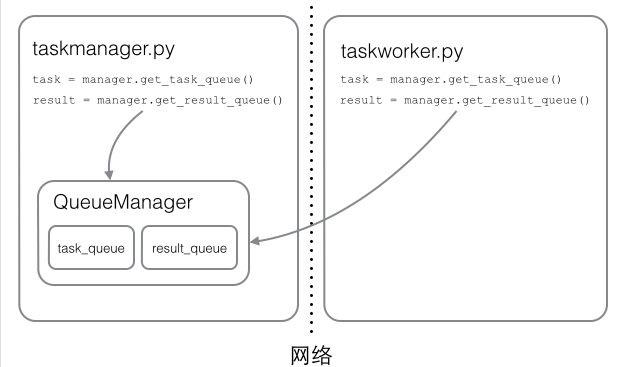
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件。
四、协程
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
第一最大的优势就是协程极高的执行效率。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
import time def consumer():
r = ''
while True:
n = yield r ##
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK' def produce(c):
c.next() ##执行一次生成
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n) ##传给consumer,转进consumer的yield里面
print('[PRODUCER] Consumer return: %s' % r)
c.close() if __name__=='__main__':
c = consumer() ##生成器
produce(c)
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
首先调用c.next()启动生成器;
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
consumer通过yield拿到消息,处理,又通过yield把结果传回;
produce拿到consumer处理的结果,继续生产下一条消息;
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
一句话介绍python线程、进程和协程的更多相关文章
- Python 线程&进程与协程
Python 的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承.Py ...
- 多任务-python实现-进程,协程,线程总结(2.1.16)
@ 目录 1.类比 2.总结 关于作者 1.类比 一个生产玩具的工厂: 一个生产线成为一个进程,一个生产线有多个工人,所以工人为线程 单进程-多线程:一条生产线,多个工人 多进程-多线程:多条生产线, ...
- Python 37 进程池与线程池 、 协程
一:进程池与线程池 提交任务的两种方式: 1.同步调用:提交完一个任务之后,就在原地等待,等任务完完整整地运行完毕拿到结果后,再执行下一行代码,会导致任务是串行执行 2.异步调用:提交完一个任务之后, ...
- Python之线程、进程和协程
python之线程.进程和协程 目录: 引言 一.线程 1.1 普通的多线程 1.2 自定义线程类 1.3 线程锁 1.3.1 未使用锁 1.3.2 普通锁Lock和RLock 1.3.3 信号量(S ...
- Python菜鸟之路:Python基础-线程、进程、协程
上节内容,简单的介绍了线程和进程,并且介绍了Python中的GIL机制.本节详细介绍线程.进程以及协程的概念及实现. 线程 基本使用 方法1: 创建一个threading.Thread对象,在它的初始 ...
- python学习笔记11 ----线程、进程、协程
进程.线程.协程的概念 进程和线程是操作系统中两个很重要的概念,对于一般的程序,可能有若干个进程,每一个进程有若干个同时执行的线程.进程是资源管理的最小单位,线程是程序执行的最小单位(线程可共享同一进 ...
- python 线程,进程与协程
引言 线程 创建普通多线程 线程锁 互斥锁 信号量 事件 条件锁 定时器 全局解释器锁 队列 Queue:先进先出队列 LifoQueue:后进先出队列 PriorityQueue:优先级队列 deq ...
- python成长之路 :线程、进程和协程
python线程 进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源的管理和分 ...
- Python之路【第七篇】:线程、进程和协程
Python之路[第七篇]:线程.进程和协程 Python线程 Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元. 1 2 3 4 5 6 7 8 9 10 11 12 1 ...
随机推荐
- vue-cli3使用yarn run build打包找不到路径
vue-cli3使用yarn run build打包项目部署到服务器上面,运行空白 解决办法非常方便,直接创建vue.config.js 在vue.config.js中添加即可 再打包项目即成功
- 用shell编写小九九乘法表程序
1.使用for循环 运行结果: 2.方法二:for循环 运行结果: 备注: 1. echo -n 的意思是不自动换行,因为在linux shell中 echo到最后一个字符时会自动换行的,所以echo ...
- 在python3中的编码
在python3中的编码 #_author:Administrator#date:2019/10/29import sysprint(sys.getdefaultencoding())#utf-8 打 ...
- ThinkPHP 读取数据
在ThinkPHP中读取数据的方式很多,通常分为读取数据.读取数据集和读取字段值. 步进电机和伺服电机 数据查询方法支持的连贯操作方法有: 连贯操作 作用 支持的参数类型 where 用于查询或者更新 ...
- csp-s模拟测试10.1(b)X 国的军队,排列组合, 回文题解
题面:https://www.cnblogs.com/Juve/articles/11615883.html X 国的军队: 好像有O(T*N)的直接贪心做法 其实多带一个log的二分也可以过 先对所 ...
- C++内存字节对齐规则
为什么要进行内存对齐以及对齐规则 C/C++—— 内存字节对齐规则 C++内存字节对齐规则
- JavaScrip中的循环语句
循环语句 循环语句,也是流程控制语句中不可或缺的一种结构.在 JavaScrip中实现循环的方式有好几个一个来看 1.为什么需要循环 在具体介绍 Javascript中的循环之前,首先我们来明确一个问 ...
- CDN与智能DNS原理和应用
1.cdn概念,DNS概念 CDN:Centent Delivery Network(内容分发网络) 使用户可以就近取得所需内容,提高用户访问网站相应速度 CDN=更智能的镜像+缓存+流量导流: DN ...
- hibernate查询timestamp条件
参考https://blog.csdn.net/zuozuoshenghen/article/details/50540661 Mysql中Timestamp字段的格式为yyyy-MM-dd HH-m ...
- hadoop settings
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys expor ...