meet-in-the-middle 基础算法(优化dfs)
$meet-in-the-middle$(又称折半搜索、双向搜索)对于$n<=40$的搜索类型题目,一般都可以采用该算法进行优化,很稳很暴力。
$meet-in-the-middle$算法的主要思想是将搜索区域化为两个集合,分别由搜索树的两端向中间扩展,直到搜索树产生交集,此时即可得到我们的合法情况。
通常适用于求经过$n$步变化,从A集合变到B集合需要的方案数问题。
对于普通dfs来说,其一大弊端是随着搜索层数的不断增加,搜索的复杂度也会极速增长,
而$meet-in-the-middle$算法能够将搜索层数降至原来的一半,对整体效率而言无疑是不小的提升。
如图所示:
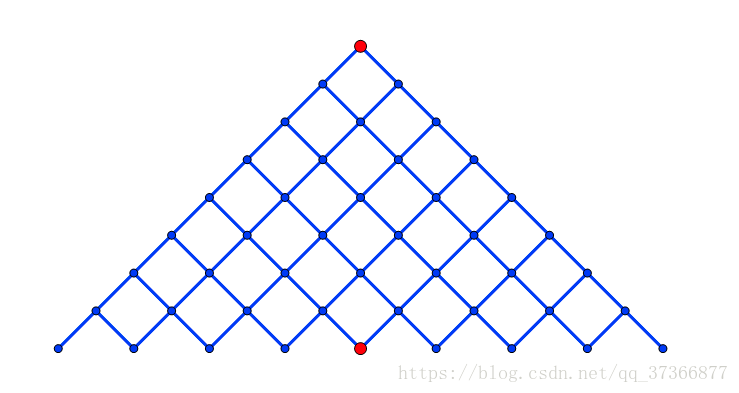

可以明显看出$meet-in-the-middle$对于dfs优化之显著。
那么考虑$meet-in-the-middle$的算法流程:
1、从状态$L$出发,经过$x$步状态扩展,记录到达状态$i$的步数,通常这里会与状压、二分等内容结合。
2、从状态$R$出发,经过$y$步状态扩展,若同样到达状态$i$并且步数不为0,则累加答案。
通常我们需要保证$x+y=n$,也就是需要满足状态总数不变,只是深度减少,一般情况下取$x=y=(n>>1)$最优
但具体情况应视题而定,可能搜索深度不均匀时,效率反而会更高。
下面来看一道例题:
[BZOJ 2679] Balanced Cow Subsets
简要题意:有多少个非空子集,能划分成和相等的两份。$(n<=20)$
分析:显然的$meet-in-the-middle$定义,考虑如何转化
将题设转化成方程的形式$a1x1+a2x2+a3x3+...+anxn=0$,其中$x=0,1,-1$(表示不选,选入集合$l$,选入集合$r$),那么移项可得一种两侧各有一种集合的形式,根据题目要求,我们需要求出可以构建出该方程的集合方案数,可以采用状压的思想,记录所选取的数的和以及选取集合的状态即可。
#include<bits/stdc++.h>
#include<tr1/unordered_map>
#define re register
using namespace std;
int n,a[],cntl,cntr,ans=-;
bool vis[<<];
inline int read(){
re int a=,b=; re char ch=getchar();
while(ch<''||ch>'')
b=(ch=='-')?-:,ch=getchar();
while(ch>=''&&ch<='')
a=(a<<)+(a<<)+(ch^),ch=getchar();
return a*b;
}
struct node{
int sta,val; node(){}
node(int x,int y){sta=x,val=y;}
bool operator < (const node &b) const {
return val<b.val;
}
bool operator > (const node &b) const {
return val>b.val;
}
}l[<<],r[<<];
inline void dfs1(re int x,re int tot,re int sta){
if(x>(n>>)){
l[++cntl]=node(sta,tot);
return ;
}
dfs1(x+,tot,sta);
dfs1(x+,tot+a[x],sta|(<<(x-)));
dfs1(x+,tot-a[x],sta|(<<(x-)));
}
inline void dfs2(re int x,re int tot,re int sta){
if(x>n){
r[++cntr]=node(sta,tot);
return ;
}
dfs2(x+,tot,sta);
dfs2(x+,tot+a[x],sta|(<<(x-)));
dfs2(x+,tot-a[x],sta|(<<(x-)));
}
signed main(){
n=read();
for(re int i=;i<=n;++i) a[i]=read();
dfs1(,,); dfs2((n>>)+,,);
sort(l+,l+cntl+,less<node>());
sort(r+,r+cntr+,greater<node>());
for(re int i=,j=,pos;i<=cntl&&j<=cntr;++i){
while(j<=cntr&&l[i].val+r[j].val>) ++j;
for(pos=j;l[i].val==-r[pos].val;++pos){
re int sta=(l[i].sta|r[pos].sta);
if(!vis[sta]) vis[sta]=,++ans;
}
}
printf("%d\n",ans);
}
Code
同种类的题目还有许多,例如 [POJ 1186] 方程的解数, [BZOJ 4800] 冰球世界锦标赛 等。
综上可见$meet-in-the-middle$算法的应用之广。
至此,通过分析转化搜索模型,达到了降低搜索复杂度,优化程序效率的目的。
meet-in-the-middle 基础算法(优化dfs)的更多相关文章
- 【BZOJ4800】[Ceoi2015]Ice Hockey World Championship Meet in the Middle
[BZOJ4800][Ceoi2015]Ice Hockey World Championship Description 有n个物品,m块钱,给定每个物品的价格,求买物品的方案数. Input 第一 ...
- Meet in the middle算法总结 (附模板及SPOJ ABCDEF、BZOJ4800、POJ 1186、BZOJ 2679 题解)
目录 Meet in the Middle 总结 1.算法模型 1.1 Meet in the Middle算法的适用范围 1.2Meet in the Middle的基本思想 1.3Meet in ...
- 0基础算法基础学算法 第八弹 递归进阶,dfs第一讲
最近很有一段时间没有更新了,主要是因为我要去参加一个重要的考试----小升初!作为一个武汉的兢兢业业的小学生当然要去试一试我们那里最好的几个学校的考试了,总之因为很多的原因放了好久的鸽子,不过从今天开 ...
- 折半搜索(meet in the middle)
折半搜索(meet in the middle) 我们经常会遇见一些暴力枚举的题目,但是由于时间复杂度太过庞大不得不放弃. 由于子树分支是指数性增长,所以我们考虑将其折半优化; 前言 这个 ...
- Meet in the middle
搜索是\(OI\)中一个十分基础也十分重要的部分,近年来搜索题目越来越少,逐渐淡出人们的视野.但一些对搜索的优化,例如\(A\)*,迭代加深依旧会不时出现.本文讨论另一种搜索--折半搜索\((meet ...
- 浅谈Meet in the middle——MITM
目测观看人数 \(0+0+0=0\) \(\mathrm{Meet\;in\;the\;middle}\)(简称 \(\rm MITM\)),顾名思义就是在中间相遇. 可以理解为就是起点跑搜索树基本一 ...
- ACM基础算法入门及题目列表
对于刚进入大学的计算机类同学来说,算法与程序设计竞赛算是不错的选择,因为我们每天都在解决问题,锻炼着解决问题的能力. 这里以TZOJ题目为例,如果为其他平台题目我会标注出来,同时我的主页也欢迎大家去访 ...
- DAY 4 基础算法
基础算法 本来今天是要讲枚举暴力还有什么的,没想到老师就说句那种题目就猪国杀,还说只是难打,不是难.... STL(一)set 感觉今天讲了好多,set,单调栈,单调队列,单调栈和单调队列保证了序列的 ...
- 【算法】342- JavaScript常用基础算法
一个算法只是一个把确定的数据结构的输入转化为一个确定的数据结构的输出的function.算法内在的逻辑决定了如何转换. 基础算法 一.排序 1.冒泡排序 //冒泡排序function bubbleSo ...
- SQL Server 聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值 ...
随机推荐
- crontab中反引号和$()无效的解决
问题描述 1.增加了一条crontab,删除本月中2天以前的日志 10 02 * * * /bin/find /data/logs/php/$(date +%Y%m)/ -mtime +2 | x ...
- 【树剖】CF916E Jamie and Tree
好吧这其实应该不是树剖... 因为只要求子树就够了,dfs就好了 大概就是记录一个全局根root 多画几幅图会发现修改时x,y以root为根时的lca为以1为根时的lca(x,y),lca(root, ...
- art-template官方文档
http://aui.github.io/art-template/zh-cn/docs/
- windows环境下,svn未备份情况下重新恢复
公司有个同事在未打招呼的情况下把公司服务器进行重新装系统,崩溃啊.SVN之前未备份,还好SVN的库(Repositories)还在,如下图: 恢复办法如下: 由于之前安装的就是VisualSVN-Se ...
- js 面向对象几种数据模式
一.单例模式: 把描述同一事物的属性和方法放在同一内存空间下,实现了分组的作用,防止同一属性或者方法冲突.我们把这种分组编写代码的模式叫做单例模式即普通的对象. 单例模式是项目开发中最常用的一种开发模 ...
- Android之shape属性简介和使用
1.shape标签简介 shape的形状,默认为矩形,可以设置为矩形(rectangle).椭圆形(oval).线性形状(line).环形(ring) ! 设置形状: <shape xmln ...
- iOS程序两中启动图方式和一些坑LaunchImage 和 Assets.xcassets(Images.xcassets)
一.通过LaunchScreen.storyboard 作启动图 1>在LaunchScreen.storyboard中拖拽一个imageView放上启动图片 注意:记得勾选右边的 User a ...
- JspServlet
初始化servlet时,选用的配置类: config.getInitParameter("engineOptionsClass")?(System.getSecurityManag ...
- Cooki and Session
目录 Cookie Cookie的由来 什么是Cookie Cookie的原理 查看Cookie Django中操作Cookie 获取Cookie 设置Cookie 删除Cookie Session ...
- JAXL连接Openfire发送房间消息
使用composer形式安装的JAXL <?php require_once "vendor/autoload.php"; $client = new JAXL(array( ...