机器学习-浅谈神经网络和Keras的应用
- 概述
神经网络是深度学习的基础,它在人工智能中有着非常广泛的应用,它既可以应用于咱们前面的章节所说的Linear Regression, classification等问题,它还广泛的应用于image recognition,NLP 等等应用中,当然啦,这一节咱们主要讲述神经网络的最基础的结构以及应用,在后面我会逐渐的讲解基于咱们的这个最简单的神经网络结构的一些其他方面的优化和提升,例如有RNN,CNN等等。这一节主要讲解一下咱们的神经网络的结构,以及如何用TensorFlow和Keras构建一个神经网络,以及常用的一些存储,加载网络模型的一些方式。
- 神经网络
神经网络咱们已经听过很多次了,可是它具体长什么样,它的结构是什么样子呢?只要大家看懂了下面的图,大家就能理解最基本的神经网络的结构了,我会结合着下面的图来解释DNN的一些基本概念
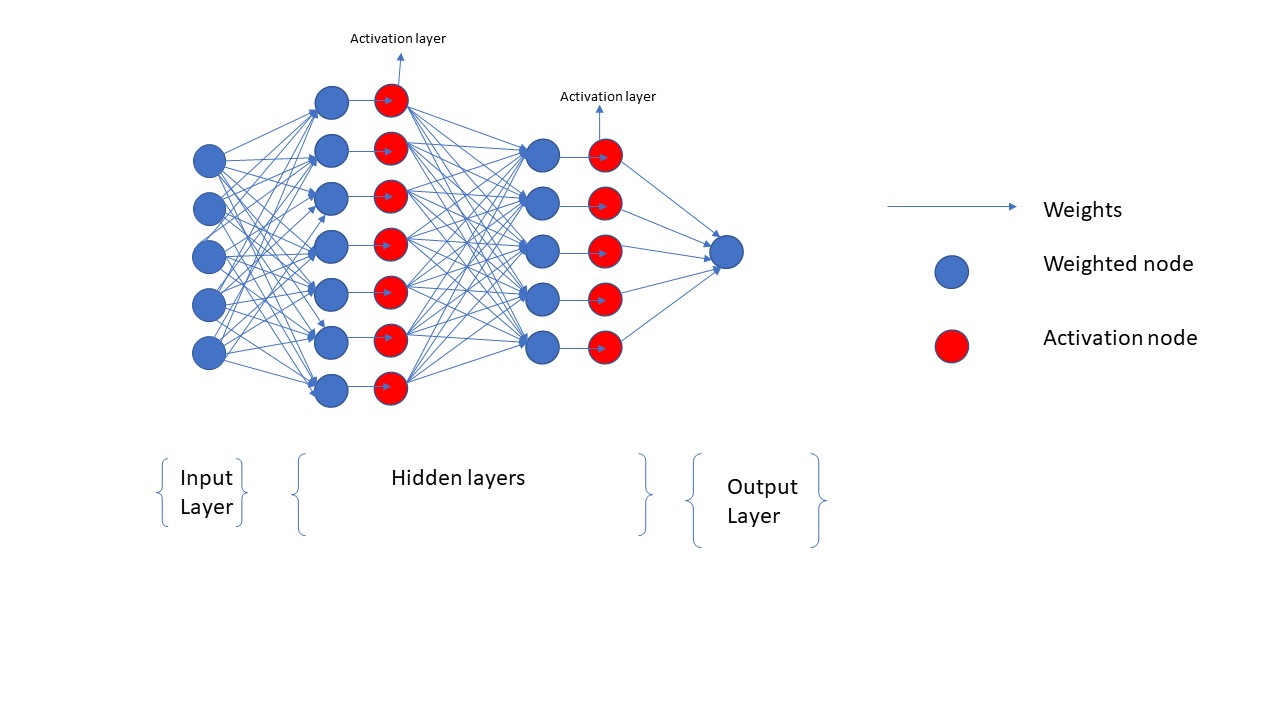
上面的DNN的图片是我自己画的,它是一个最基本的DNN的结构;一个神经网络其实主要包括三个部分,分别是Input layer, hidden layers 和 output layer。input layer就是相当于咱们的数据输入,input layer中每一个node都是一个feature,如果咱们的dataset有5个feature,那么咱们的input layer就有5个node;最后一个output layer相当于咱们的target,output layer的node也有可能是多个的不一定只有一个node哦,例如如果咱们的target是class, 假设一共有10中classes的可能,那么这里的target就是一个one-hot encoding的数据,每一个target都有10个元素,那么这时候咱们output layer的node就是10个了。Hidden layers则是咱们用户定义的layer了,要根据具体的问题具体的分析,如果咱们的问题很复杂,则hidden layer就越多,咱们运算的速度也就越慢,反之亦然;如果细心的朋友肯定会注意到咱的DNN图片还有另外一种红色的layer,那就是activation layer,这是什么呢??这是因为在咱们的DNN如果没有activation layer,那么咱们可以想象的出,咱们的模型无论是多么的复杂,咱最终的模型都是线性的,这时候咱们的模型只适合于linear regression的情况;对于想classification的问题,咱们必须要加一些非线性的函数来让咱们的DNN模型最终能够用于non-linear的情况,activation layer就是这些非线性的函数,这里主要用到的有sigmoid, softmax和relu。所以在linear的情况时候,咱们是不需要activation layer的,在non-linear的问题中,咱们则必须要要用activation layer。另外,DNN图片中中的weight咱们都是用箭头表示的,咱们在训练一个DNN的时候,其实也就是的不多的训练这些weight,通过gradient descent的方式最终找出最合理的weights,这些weights的初始值有很多种方式来设定,既可以都设置成零,也可以按照一定的规则设置成随机数,在tf.keras中有很多种方式来设置初始值的。上面就是一个最简单的DNN的结构,以及这个结构的一些基本的概念,至于咱们是如何来训练这个模型的,通过什么方式来求这个DNN的gradient descent的,这中间其实涉及到了DNN 的back propagation的,具体细节我会在后面的章节细讲的。这里大家主要理解一个forward propagation的DNN的结构和过程,以及他的应用就行了。下面我就讲述一下如何用TensorFlow和Keras来应用实现上面的DNN。
- TensorFlow应用之实现DNN
这里咱们讲述一下如何用TensorFlow来定义咱们的DNN,并且训练DNN模型。其实在TensorFlow中,训练DNN的过程跟我前面随笔中写的linear regression的流程是一模一样的,从数据准备一种的最后的模型的evaluation都是一样的,只是在模型的定义中有一点点细微的区别,我在这里把整个流程的代码都贴出来,然后分析一下他跟其他模型训练的一些不同点
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn import metrics
import math
"Step1: Data preparation"
#data loading
cali_housing_price_origin = pd.read_csv("https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv")
generator = np.random.Generator(np.random.PCG64())
cali_housing_price_permutation = cali_housing_price_origin.reindex(generator.permutation(cali_housing_price_origin.index))
#preprocess features
def preprocess_data(data_frame):
feature_names = ["longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]
data_frame=data_frame.copy()
features = data_frame[feature_names]
features["rooms_per_person"]=features["total_rooms"]/features["population"]
return features
#preprocess targets
def preprocess_targets(data_frame):
target = pd.DataFrame()
target["median_house_value"] = data_frame["median_house_value"]/1000.0
return target
features = preprocess_data(cali_housing_price_permutation)
target = preprocess_targets(cali_housing_price_permutation)
#trainning
features_trainning = features.head(12000)
target_trainning = target.head(12000)
#validation
features_validation = features.tail(5000)
target_validation = target.tail(5000) "Step2: Building a neuro network"
#construct feature columns
def construct_feature_columns(features):
return [tf.feature_column.numeric_column(my_feature) for my_feature in features]
#construct input function
def input_func(features,target,shuffle,epoches,batch_size):
features = {key:np.array([value]).T for key,value in dict(features).items()}
ds = tf.data.Dataset.from_tensor_slices((features,target))
ds = ds.batch(batch_size).repeat(epoches)
if shuffle:
ds = ds.shuffle(10000)
feature,lable = tf.compat.v1.data.make_one_shot_iterator(ds).get_next()
return feature,lable
#model define and trainning process definition
def train_DNN_model(feature_trainning,target_trainning,feature_validation,target_validation, steps):
my_optimizer = tf.optimizers.SGD(learning_rate = 0.001, clipnorm = 5)
DNN_regressor = tf.estimator.DNNRegressor(feature_columns = construct_feature_columns(feature_trainning),
optimizer = my_optimizer,
hidden_units = [10,10])
input_func_trainning = lambda: input_func(feature_trainning, target_trainning, shuffle=True, epoches=None, batch_size=100)
DNN_regressor.train(input_fn = input_func_trainning,
steps = steps)
return DNN_regressor "Step 3: making predictions"
DNN_regressor = train_DNN_model(features_trainning, target_trainning, features_validation, target_validation, 2000) #datasource for predictions
#predicting trainning dataset
input_fn_trainning = lambda: input_func(features = features_trainning, target=target_trainning, shuffle=False, epoches=1, batch_size=1)
predictions_trainning = DNN_regressor.predict(input_fn = input_fn_trainning)
#extract and format the dataset
predictions_trainning = np.array([item["predictions"][0] for item in predictions_trainning])
#MSE
mse = metrics.mean_squared_error(target_trainning, predictions_trainning)
咱们可以看出来,它的整个流程还是一样,只在一个地方后其他的模型训练过程不一样,那就是选择TensorFlow的estimator中的模型不一样而已,例如上面的是一个线性的DNN,咱们选择的就是下面的DNNRegression
DNN_regressor = tf.estimator.DNNRegressor(feature_columns = construct_feature_columns(feature_trainning),
optimizer = my_optimizer,
hidden_units = [10,10])
注意上面定义模型的参数,它多了一个hidden_units参数,这就是用户自定义的hidden layers的部分,如果咱们的结果不理想,咱们可以适当的增加hidden_units的数量。上面的是一个线性的DNN的模型定义,那么如果咱们的是non-linear的模型,例如classification,咱们如何定义呢?请看下面的代码
DNN_classifier = tf.estimator.DNNClassifier(hidden_units = [100,100],
feature_columns = configure_column_features(),
optimizer = my_optimizer,
n_classes = 10,
activation_fn=tf.nn.relu)
如果咱们的模型是non-linear的classification problem,那么咱们就选择estimator中的DNNClassifier模型,这里咱们可以看出它也增加了很多参数,n_classes是说明咱们的数据一共有多少个classes,默认值是2;activation_fn是选择的relu; 这些值都是用户根据实际情况自定义的,我这里的只是一个最简单的演示。其实他还有很多很多参数可以定义,大家自己去看文档根据实际的情况来定义。
- 神经网络之Keras应用
上面咱们介绍了用TensorFlow的estimator来定义和训练神经网络,但是在实际中有一个更加强大的框架来专门处理深度学习的问题,那就是无敌的Keras。Keras自己是一个独立的框架,专门用来处理深度学习的相关问题,咱们可以直接下载并且导入它的组件进行应用;但是呢,无敌的TensorFlow早就为了方便大家而提前将Keras导入到了TensorFlow的tf.keras这个模块中了,所以大家也不需要单独的来导入了,直接就用TensorFlow中的tf.keras模块就能实现几乎所有的Keras的功能。首先,咱们也是来看一下用Keras最简单的方式搭建一个DNN并且训练这个神经网络。
第一步:网络结构搭建
#import keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np ##1.build a sequential network
model = keras.Sequential()
#add a full-connected and dense layer
model.add(layers.Dense(64,activation ='relu',input_shape=(32,)))
#add an another layer with l2 regularizer
model.add(layers.Dense(50,
activation = 'sigmoid',
kernel_regularizer = keras.regularizers.l2(0.01),
bias_regularizer = keras.regularizers.l2(0.02),
bias_initializer = keras.initializers.Ones(),
kernel_initializer = 'glorot_uniform'
)
)
#add another layer with l2 and l1 regularizer
model.add(layers.Dense(40, activation = 'relu', kernel_regularizer = keras.regularizers.l2(0.01), bias_regularizer = keras.regularizers.l1(0.01)))
#add another layer with l1,l2 regularizer and bias/kernel initializer
model.add(layers.Dense(10,activation = 'softmax'))
"""
首先咱们初始化咱们神经网络的layers, 咱们的网络有多少的layers,咱们就初始化多少个Dense layer实例。然后将这些layers按照顺序的一次加入到咱们的model对象中。这里每一个Dense layer咱们都可以用户自定义很多的参数,我在上面的例子中也展示了很多种例子,例如有:activation, regularizer, initializer等等很多,如果大家去看他的文档,大家会看到更多的参数,但是在实际中,咱们主要就是设置上面的例子中展示的一些参数。但是这里有一个小细节大家一定要注意,否很容易出现runtime error,而且非常难找到原因,那就是bias_initializer和kernel_initializer的选择,这里并不是随便选择一个initializer就行的,首先kernel_initializer是一个matrix,所以它所选择的initializer必须得是返回matrix的,例如上面例子中的glorot_uniform等等,而bias_initializer则是一个一维的vector!!!记住bias是vector而不是matrix,所以它所选择的initializer则必须得是返回一维的vector的的initializer,而不能是glorot_uniform, othogonal等initializer。这里的细节很容易让人忽略,而一旦出错却很难找到原因的。另外一点,input layer是不需要定义的,Keras是自动的会把咱们的input layer加进去的,但是output layer是需要咱们手动定义并且加上去的。所以上面的模型结构是一个input layer, 三个hidden layers和一个output layer。咱们也可以通过model.summary()的方法来检查咱们的模型结构,如下所示
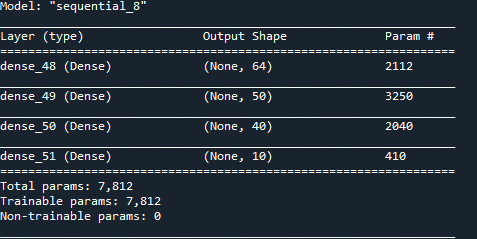
上面就是model.summary()返回的结果,它默认也没有显示input layer。
第二步:配置上面定义的模型结构
model.compile(
optimizer = keras.optimizers.Adam(0.01),
loss = 'mse',
metrics = ['mae'])
这一步主要是给上面定义的网络模型配置一些基本的信息,例如optimizer, loss function和metrics这些模型必要的一些信息。这里跟咱们之前讲的其他的一些基本模型都是一样的,这里就不在赘述了,如果不知道就看我前面的博客。
第三部: 数据准备
这部分内容呢既可以放在咱们的第一步,也可以放在咱们的网络模型都定义好了之后,这里我就随机产生几个数据当做咱们的数据模型,方便咱们后面内容的演示
data = np.random.random((1000,32))
labels = np.random.random((1000,10))
val_data = np.random.random((100,32))
val_labels = np.random.random((100,10)) dataset = tf.data.Dataset.from_tensor_slices((data,labels))
dataset = dataset.batch(32)
val_dataset = tf.data.Dataset.from_tensor_slices((val_data,val_labels))
val_dataset = val_dataset.batch(32)
第四步:模型训练
#trainning a model from dataset
model.fit(dataset,epochs = 10, validation_data=val_dataset)
这里训练数据的时候,咱们的数据既可以是numpy array也可以是dataset,因为我个人习惯的问题,我倾向于是有dataset的数据来训练,所以我上面的例子也是用的dataset。上面epochs的参数是说明咱们的模型训练的时候,咱们一共重复咱们的数据集多少次。
第五步:predict 和 evaluation
#prediction
model.predict(data) #evaluation
model.evaluate(dataset)
- Keras Functional APIs (save & load model)
上面只是展示了如何用Keras搭建并且训练一个最简单的神经网络,那么实际中咱们遇到的会遇到一些其他的需求,例如当咱们的模型训练后,咱们如何保存这个模型呢?如何保存咱们训练得来的weights呢?如何加载咱们存储在本地的模型呢?如何加载咱们的weights呢?这些都是咱们肯定会遇到的问题。那么这些功能性的API都是如何应用呢?咱们这里就一个个的给大家介绍一下。
第一:存储/加载 整个模型
#save a entire model
model.save("C:/Users/tangx/OneDrive/Desktop/path_to_my_model.h5")
#load a entire model
model = keras.models.load_model("C:/Users/tangx/OneDrive/Desktop/path_to_my_model.h5")
上面第一步就是将咱们训练的模型(包括模型的结构和weights, bias等所有的信息)都存储在本地的指定的位置。第二句代码就是加载整个咱们的本地的模型,当然了,这个加载后的模型也是包括了所有的信息,包括了模型结构,weights和bias所有的信息。
第二:存储/加载 咱们的weights和bias
在有些情况下,咱们只想加载咱们训练出来的weights(包括了bias啊),那么这种情况下,咱们如何存储呢?看下面的代码
#only save weights
model.save_weights("C:/Users/tangx/OneDrive/Desktop/model_wights")
上面是Keras提供的将咱们model的weights(包括bias)存储在本地的方式,注意哦, 这里只是存储了weights哦,并没有这个model的结构哦,那么咱们如何完整的加载这个模型呢?光有weights而没有网络结构的话可是没有用的哦。那么接下来看一下如何通过加载weights来加载整个模型信息呢,首先咱们得知道这个weights所对应的网络结构,然后重新定义并且初始化一个相对应的神经网络,相当于获取的一个“空模型“, 然后用下面的代码将weights填充到这个“空模型”中
#restore the model's state, which requires a model with same architecture
model.load_weights("C:/Users/tangx/OneDrive/Desktop/model_wights")
这之后,相当于给咱们的model填充了模型内容,从而咱们的model就可以进行正常的操作了,例如predict,evaluate等等。
第三: 存储/加载 网络结构和配置(serialize a model)
从上面的内容咱们可以知道,如果咱们只存储了weights的话,咱们在下次加载整个模型的时候,咱们还得自己重新定义并且实例化一个网络结构和配置,然后咱们才能加载咱们的weights,从而让这个模型可用。可以实际中咱们也可以单独的只存储/加载这个模型的结构和配置。那么咱们如何做呢?看下面代码演示
#save and recreate a model's configuration without any weights(serilizes a model to json format)
json_string = model.to_json() #recreate a model archetechture and configuration from json string without any weights
fresh_model = keras.models.model_from_json(json_string)
上面第一句代码呢就是将咱们的模型架构和配置信息转成json的数据结构存储起来,记住啊,这里只存储了网络架构和配置信息,并不包括训练得来的weights,这里的过程也称作model serialization。第二句代码就是从咱们序列化json数据格式中,加载咱们的网络结构和网络配置信息。从而咱们也可以直接将这个fresh_model用来load_weights, 从而成为一个完成的模型。
机器学习-浅谈神经网络和Keras的应用的更多相关文章
- 浅谈神经网络中的bias
1.什么是bias? 偏置单元(bias unit),在有些资料里也称为偏置项(bias term)或者截距项(intercept term),它其实就是函数的截距,与线性方程 y=wx+b 中的 b ...
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
- 《Machine Learning in Action》—— 浅谈线性回归的那些事
<Machine Learning in Action>-- 浅谈线性回归的那些事 手撕机器学习算法系列文章已经肝了不少,自我感觉质量都挺不错的.目前已经更新了支持向量机SVM.决策树.K ...
- 浅谈Feature Scaling
浅谈Feature Scaling 定义:Feature scaling is a method used to standardize the range of independent variab ...
- Python机器学习笔记:深入理解Keras中序贯模型和函数模型
先从sklearn说起吧,如果学习了sklearn的话,那么学习Keras相对来说比较容易.为什么这样说呢? 我们首先比较一下sklearn的机器学习大致使用流程和Keras的大致使用流程: skl ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 转:浅谈深度学习(Deep Learning)的基本思想和方法
浅谈深度学习(Deep Learning)的基本思想和方法 参考:http://blog.csdn.net/xianlingmao/article/details/8478562 深度学习(Deep ...
- 浅谈 Attention 机制的理解
什么是注意力机制? 注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制.例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目 ...
- 浅谈PageRank
浅谈PageRank 2017-04-25 18:00:09 guoziqing506 阅读数 17873更多https://blog.csdn.net/guoziqing506/article/de ...
随机推荐
- CITRIX VPX配置四层负载
网络拓扑如下: Step1:开启四层负载特性 在Configuration->Traffic Management->Load Balancing上右键弹出菜单点击enable,如下图: ...
- 利用脚本运行APP
1.电脑安装Xcode(iOS)/Androidsdk(Android),连接手机,并在手机上安装相应代理,下图为iOS的Xcode代理样式: 2.打开Appium,点击搜索图标,添加并设置该手机信息 ...
- 对EntityViewInfo的理解
1,EntityViewInfo常常用作bos中接口参数,来做查询用,其中包含了FilterInfo(过滤).Selector(指定属性)以及Sorter(排序) SelectorItemColl ...
- linux 双Redis + keepalived 主从复制+宕机自主切换
主要核心思想,如果master 和 salve 全部存活的情况,VIP就漂移到 master.读写都从master操作,如果master宕机,VIP就会漂移到salve,并将之前的salve切换为ma ...
- 对接百度地图API 实现地址转经纬度
<?php class BaiduLBS { public static $_ak = '你的KEY值'; # Util::request 是我封装的一个请求URL类,自己可以写一个 可以提交 ...
- 19.python中os模块的常见用法
常见函数列表 os.sep:取代操作系统特定的路径分隔符 os.name:指示你正在使用的工作平台.比如对于Windows,它是'nt', 而对于Linux/Unix用户,它是'posix'. os. ...
- PPP协议 PAP认证
- Java面向对象之异常【一】
目录 Java面向对象之异常[一] 异常的继承体系 Error Exception 异常是否受检 unchecked exceptions(不受检异常) checked exceptions(受检异常 ...
- 【转】Spring面试问题集锦
Q. 对于依赖倒置原则(Dependency Inversion Principle,DIP),依赖注入(Dependency Injection,DI)和控制反转(Inversion of Cont ...
- GeneXus 16 如何实现自动化测试和发布
CI/CD(持续集成/持续发布)是一种软件开发策略,以使公司能够尽可能快速.高效地给客户发布新功能.为了能够实现CI/CD,就需要通过PipeLine对整个软件过程进行一系列的节点管理,必须将每个阶段 ...