【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客
import requests
import time
from bs4 import BeautifulSoup def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return def get_infos(html):
'''
提取数据
'''
html = BeautifulSoup(html)
# 排名#
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span') # 打印信息
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
data = {
'排名': r,
'歌名-歌手': n,
'播放时间': t
}
print(data) def main():
'''
主接口
'''
urls = ['https://www.kugou.com/yy/rank/home/{}-23784.html?from=rank'
.format(str(i)) for i in range(1, 6)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1) if __name__ == '__main__':
main()
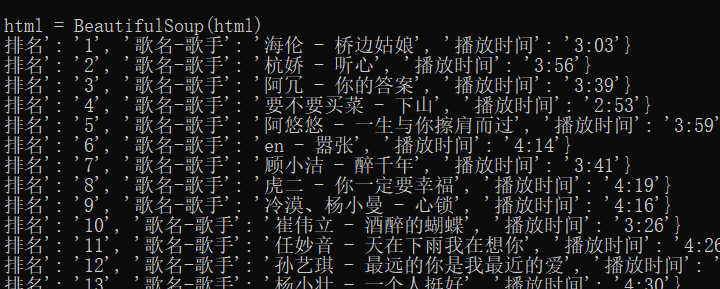
结果:
【Python】【爬虫】爬取酷狗音乐网络红歌榜的更多相关文章
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- Python实例---爬去酷狗音乐
项目一:获取酷狗TOP 100 http://www.kugou.com/yy/rank/home/1-8888.html 排名 文件&&歌手 时长 效果: 附源码: import t ...
- python爬虫---爬取网易云音乐
代码: import requests from lxml import etree text = requests.get("https://music.163.com/discover/ ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
随机推荐
- VSCode部署JAVA项目出现The type java.lang.Object cannot be resolved
如题,出现的原因是这样的:我将mac系统上的eclipse项目复制到了ubuntu环境下,通过vscode的远程功能连接ubuntu. 然后项目上就出现了各种报错,显示The type java.la ...
- 按钮控制彩灯实验 CSU - 1770 树状数组 差分变单点修改
#include<iostream> #include<algorithm> #include<cstring> using namespace std; ; in ...
- PAT 基础编程题目集 6-10 阶乘计算升级版 (20 分)
本题要求实现一个打印非负整数阶乘的函数. 函数接口定义: void Print_Factorial ( const int N ); 其中N是用户传入的参数,其值不超过1000.如果N是非负整数,则该 ...
- C语言 三目运算
C语言 三目运算 功能:为真后可根据条件选择成立两个不同的表达式 如果表达式1值为真选择表达式2 如果表达式1值为假选择表达式3 案例 #define _CRT_SECURE_NO_WARNINGS ...
- nginx 配置 强制访问https
使用nginx的301状态码 server { listen ; if ($scheme = 'http') { return 301 https://$server_name$requ ...
- fastadmin弹窗效果表单
在项目所对应的js文件中的 table.bootstrapTable({ url: $.fn.bootstrapTable.defaults.extend.index_url, pk: 'id', s ...
- windows下安装配置subline+Markdown
安装环境:win10 64bit 1. 安装subline3 subline : http://www.sublimetextcn.com/ 直接下载安装,不用激活(dao版,慎用) 2. 安装Ma ...
- PHP对一维数组去重
一维数组去重 $arr =[1,2,2,3,6]; $arr1 =array_flip($arr); $arr =array_flip($arr1); return $arr; array_flip( ...
- jqgrid中分页和搜索,jqgrid loadonce:true后trigger("reloadGrid")无效
第一次接触jqgrid,发现项目中好多地方都用到. jqgrid是典型的B/S架构(浏览器/服务器模式),服务器端只需提供数据管理,浏览器只需负责数据显示. jqGrid是用ajax实现对 ...
- mybatis(五):源码分析 - 参数映射流程