吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np
import matplotlib.pyplot as plt from sklearn.svm import LinearSVC
from sklearn.datasets import load_digits
from sklearn.model_selection import validation_curve #模型选择验证曲线validation_curve模型
def test_validation_curve():
'''
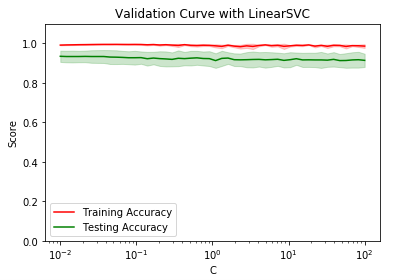
测试 validation_curve 的用法 。验证对于 LinearSVC 分类器 , C 参数对于预测准确率的影响
'''
### 加载数据
digits = load_digits()
X,y=digits.data,digits.target
#### 获取验证曲线 ######
param_name="C"
param_range = np.logspace(-2, 2)
train_scores, test_scores = validation_curve(LinearSVC(), X, y, param_name=param_name,param_range=param_range,cv=10, scoring="accuracy")
###### 对每个 C ,获取 10 折交叉上的预测得分上的均值和方差 #####
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
####### 绘图 ######
fig=plt.figure()
ax=fig.add_subplot(1,1,1) ax.semilogx(param_range, train_scores_mean, label="Training Accuracy", color="r")
ax.fill_between(param_range, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2, color="r")
ax.semilogx(param_range, test_scores_mean, label="Testing Accuracy", color="g")
ax.fill_between(param_range, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2, color="g") ax.set_title("Validation Curve with LinearSVC")
ax.set_xlabel("C")
ax.set_ylabel("Score")
ax.set_ylim(0,1.1)
ax.legend(loc='best')
plt.show() #调用test_validation_curve()
test_validation_curve()
吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型的更多相关文章
- 吴裕雄 python 机器学习——数据预处理包裹式特征选取模型
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_select ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 吴裕雄 python 机器学习——数据预处理二元化Binarizer模型
from sklearn.preprocessing import Binarizer #数据预处理二元化Binarizer模型 def test_Binarizer(): X=[[1,2,3,4,5 ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
随机推荐
- 编码 - 调整 gitbash 文本字符集
概述 gitbash 设置 文本字符集 背景 最近被 编码 的事情搞得乱七八糟 有点没头绪, 所以碰到 编码相关 的东西, 都想看上一看 环境 os win10.1903 git 2.20.1 1. ...
- [NOI2014] 魔法森林 - Link Cut Tree
[NOI2014] 魔法森林 Description 给定一张图,每条边 \(i\) 的权为 \((a_i,b_i)\), 求一条 \(1 \sim n\) 路径,最小化 \(\max_{i\in P ...
- IIS支持json、geojson文件
最近在搞asp.net + openlayers. 其中openlayer有个数据源支持 .geojson 数据,但是怎么测试都不能成功.同样的数据拿到php下就能成功显示. 搓. 在网上漫无目的的搜 ...
- Linux package installation: deb and rpm
一般来说著名的 Linux 系统基本上分两大类: RedHat 系列:Redhat.Centos.Fedora 等 Debian 系列:Debian.Ubuntu 等 Dpkg (Debian系): ...
- linux异常 - unzip: 未找到命令
问题描述 unzip: Command Not Found 或 zip: Command Not Found 或unzip: 未找到命令 解决方法 如果是Ubuntu的的系统可以用下面的命令安装:su ...
- UES
Spring-core-4.3.16 ObjectUtils.java public static boolean isEmpty(Object obj) { if (obj == null) { r ...
- mysql数据库函数之left()、right()、substring()、substring_index()
在实际的项目开发中有时会有对数据库某字段截取部分的需求,这种场景有时直接通过数据库操作来实现比通过代码实现要更方便快捷些,mysql有很多字符串函数可以用来处理这些需求,如Mysql字符串截取总结:l ...
- Vue的iview组件框架select远程搜索,选中后不刷新的问题
1.场景:弹框内有一个下拉组件(支持搜索),当选择完数据后弹框关闭,再次打开后,下拉框内的数据是刚才选中的数据.原因:分析后觉得是搜索内容没有清空,导致下拉的数据只有一个 2.解决方案 a .解决:调 ...
- umi ui 构建时出现 spawn sh ENOENT 报错的解决方法
在使用umi可视化界面构建项目的时候,如果出现spawn sh ENOENT错误,一般都是由于环境变量里没有设置git的环境变量导致的.在环境变量的path里加上"C:\Program Fi ...
- spring(三):BeanFactory