如何在 Apache Flink 中使用 Python API?
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink PMC,阿里巴巴高级技术专家 孙金城 分享。重点为大家介绍 Flink Python API 的现状及未来规划,主要内容包括:Apache Flink Python API 的前世今生和未来发展;Apache Flink Python API 架构及开发环境搭建;Apache Flink Python API 核心算子介绍及应用。
一.Apache Flink Python API 的前世今生和未来发展
1.Flink 为什么选择支持 Python
Apache Flink 是流批统一的开源大数据计算引擎,在 Flink 1.9.0 版本开启了新的 ML 接口和全新的Python API架构。那么为什么 Flink 要增加对 Python 的支持,下文将进行详细分析。
- 最流行的开发语言
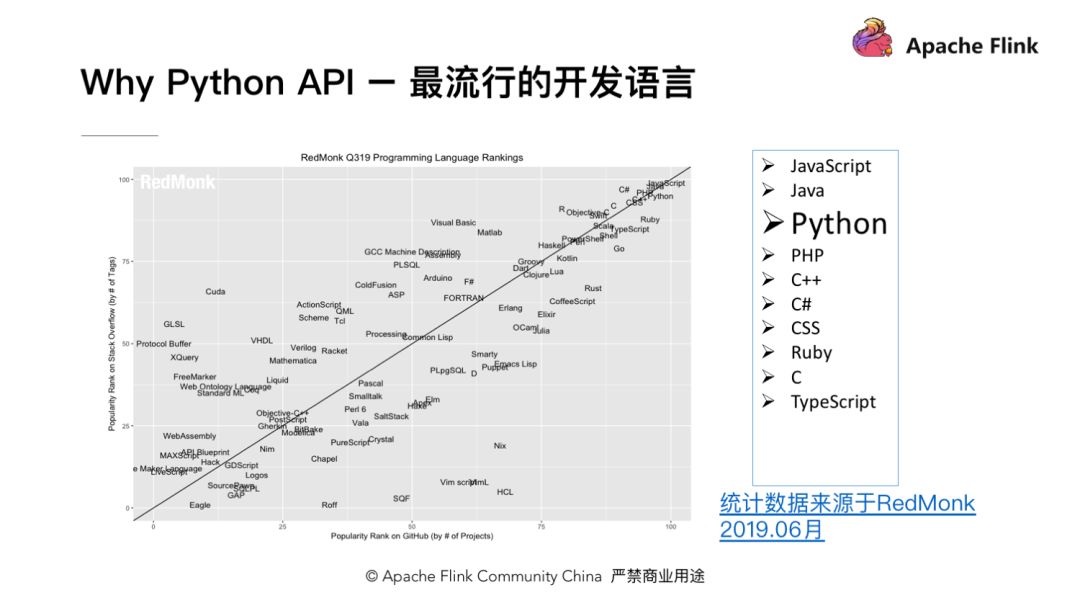
Python 本身是非常优秀的开发语言,据 RedMonk 数据统计,除 Java 和 JavaScript 之外,受欢迎度排名第三。
RedMonk 是著名的以开发人员为中心的行业分析公司,其更详细的分析信息,大家在拿到我的PPT之后,可以点击链接进行详细查阅。好了,那么Python的火热,与我们今天向大家分享的流批统一的大数据计算引擎,Apache Flink有什么关系呢?带着这个问题,我们大家想想目前与大数据相关的著名的开源组件有哪些呢?比如说最早期的批处理框架Hadoop?流计算平台Storm,最近异常火热的Spark?异或其他领域数仓的Hive,KV存储的HBase?这些都是非常著名的开源项目,那么这些项目都无一例外的进行了Python API的支持。
- 众多开源项目支持
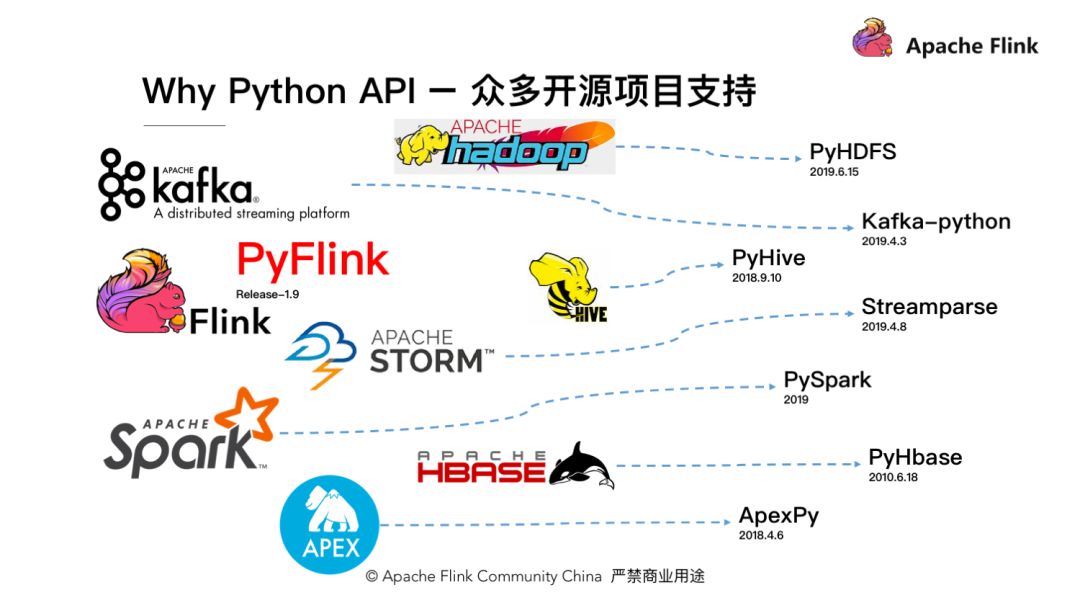
Python 的生态已相对完善,基于此,Apache Flink 在 1.9 版本中也投入了大量的精力,去推出了一个全新的 Pyflink。除大数据外,人工智能与Python也有十分密切的关系。
- ML青睐的语言
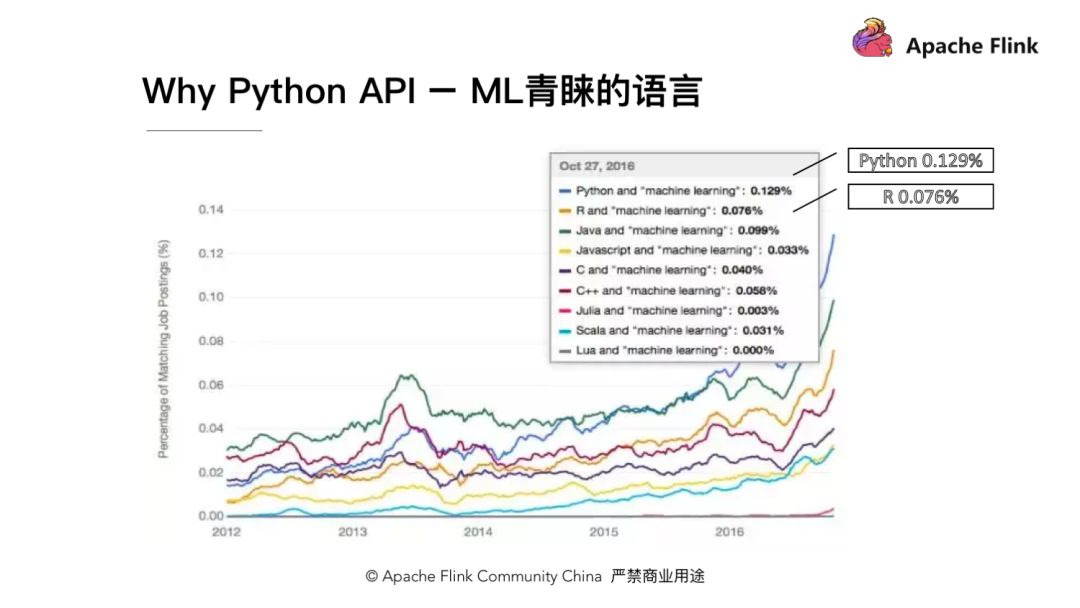
从上图统计数据可以发现,Python API 本身已经占机器学习岗位需求语言的 0.129%。相对于 R 语言,Python 语言似乎更受青睐。Python 作为解释型语言,语法的设计哲学是”用一种方法并且只有一种方法来做一件事”。其简洁和易用性使其成为了世界上最受欢迎的语言,在大数据计算领域都有着很好的生态建设,同时Python在机器学习 在机器学习方面也有很好的前景,所以我们在近期发布的Apache Flink 1.9 以全新的架构推出新的 Python API
Flink 是一款流批统一的计算引擎,社区非常重视和关注 Flink 用户,除 Java 语言或者 Scala 语言,社区希望提供多种入口,多种途径,让更多的用户更方便的使用 Flink,并收获 Flink 在大数据算力上带来的价值。因此 Flink 1.9 开始,Flink 社区以一个全新的技术体系来推出 Python API,并且已经支持了大部分常用的一些算子,比如如 JOIN,AGG,WINDOW 等。
2.Python API – RoadMap

在 Flink 1.9 中虽然 Python 可以使用 Java 的 User-defined Function,但是还缺乏 Python native 的 User-defined function 的定义,所以我们计划在 Flink 1.10 中进行支持 Python User-defined function 的支持。并技术增加对数据分析工具类库 Pandas 的支持,在 Flink 1.11 增加对 DataStream API 和 ML API 的支持。
二.Python API架构及开发环境搭建
1.Python Table API架构
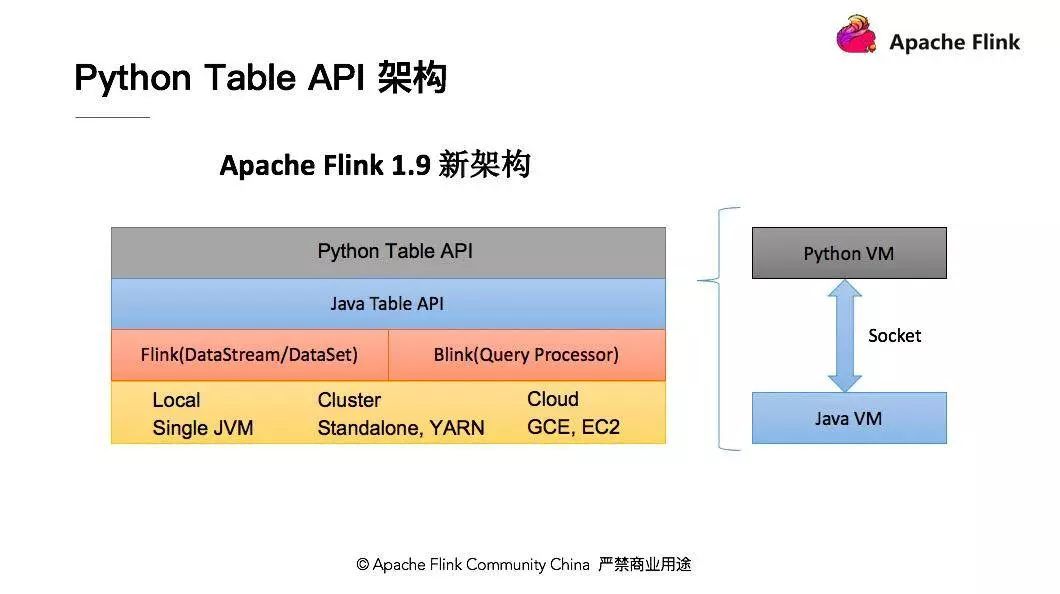
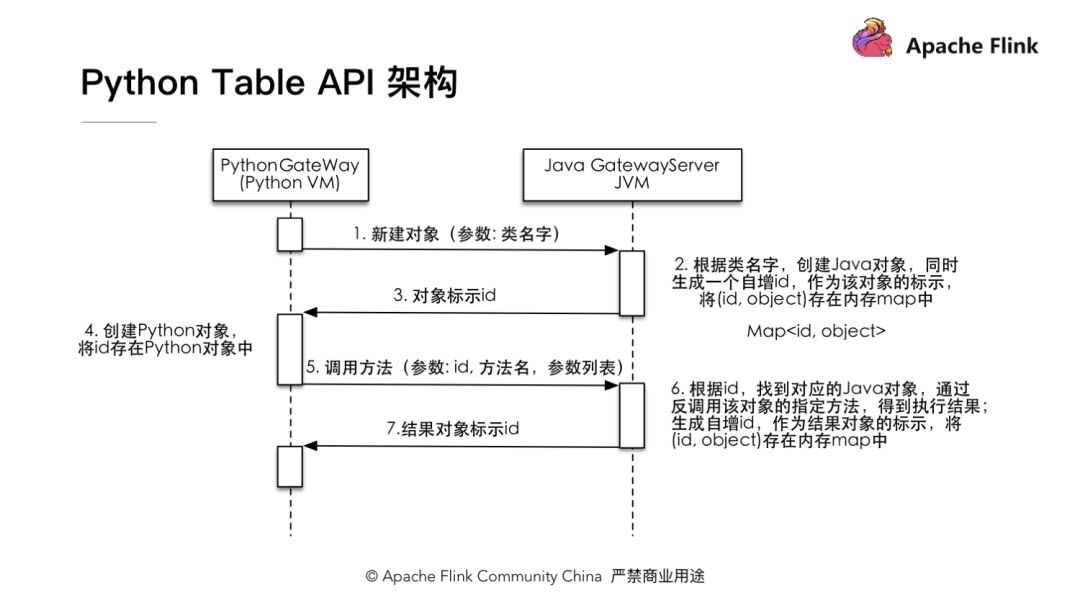
新的 Python API 架构分为用户 API 部分,PythonVM 和 Java VM 的通讯部分,和最终将作业提交到 Flink 集群进行运行的部分。那么 PythonVM 和 JavaVM 是怎样通讯的呢?我们在Python 端会会有一个 Python 的 Gateway 用于保持和 Java 通讯的链接,在 Java 部分有一个 GateWayServer 用于接收 Python 部分的调用请求。
关于 Python API 的架构部分,在 1.9 之前,Flink 的 DataSet 和 DataStream 已经有了对 Python API 的支持,但是拥有 DataSet API 和 DataStream API 两套不同的 API。对于 Flink 这样一个流批统一的流式计算引擎来讲,统一的架构至关重要。并且对于已有的 Python DataSet API 和 DataStream API 而言,采用了JPython 的技术体系架构,而 JPython 本身对目前 Python 的 3.X 系列无法很好的支持,所以 Flink 1.9 发布后,决定将原有的 Python API 体系架构废弃,以全新的技术架构出现。这套全新的 Python API 基于 Table API 之上。
Table API 和 Python API 之间的通讯采用了一种简单的办法,利用 Python VM 和 Java VM 进行通信。在 Python API 的书写或者调用过程中,以某种方式来与 Java API 进行通讯。操作 Python API 就像操作 Java 的 Table API一样。新架构中可以确保以下内容:
- 不需要另外创建一套新的算子,可以轻松与 Java 的 Table API 的功能保持一致;
- 得益于现有的 Java Table API 优化模型,Python 写出来的API,可以利用 Java API 优化模型进行优化,可以确保 Python 的 API 写出来的 Job 也能够具备极致性能。

如图,当 Python 发起对Java的对象请求时候,在 Java 段创建对象并保存在一个存储结构中,并分配一个 ID 给 Python 端,Python 端在拿到 Java 对象的 ID 后就可以对这个对象进行操作,也就是说 Python 端可以操作任何 Java 端的对象,这也就是为什么新的架构可以保证Python Table API 和 Java Table API功能一致,并且能过服用现有的优化模型。

在新的架构和通讯模型下,Python API 调用 Java API 只需要在持有 Java 对象的 ID,将调用方法的名字和参数传递给 Java VM,就能完成对 Java Table API 的调用,所以在这样的架构中开发 Python Table API 与开发 Java Table API 的方式完全一致,接下来我为大家详细介绍如何开发一个简单的 Python API 作业。
2.Python Table API – Job开发
通常来讲一个 Python Table Job 一般会分成四个部分,首先要根据目前的现状,要决定这个Job 是以批的方式运行,还是流的方式运行。当然后续版本用户可以不考虑,但当前 1.9 版本还是需要考虑。
在决定第一步以怎样的方式执行 Job 后,我们需要了解数据从哪里来,如何定义 Source、结构数据类型等信息。然后需要写计算逻辑,然后就是对数据进行计算操作,但最终计算的结果需要持久化到某个系统。最后定义 Sink,与 Source 类似,我们需要定义 Sink Schema,以及每一个字段类型。
下面将详细分享如何用 Python API 写每一步?首先,我们创建一个执行环境,对于执行环境本身来讲,首先需要一个 ExecutionEnvironment,根本上我们需要一个 TableEnvironment。那么在 TableEnvironment 中,有一个参数 Table Config,Table Config 中会有一些在执行过程中的配置参数,可以传递到 RunTime 层。除此之外,还提供了一些个性化的配置项,可以在实际业务开发中进行使用。

在拿到 Environment 后,需要对数据源表进行定义,以 CSV 格式文件为例,用"逗号"分隔,用 Field 来表明这个文件中有哪些字段。那么会看到,目前里面用逗号分隔,并且只有一个字段叫 word,类型是 String。

在定义并描述完数据源数据结构转换成 Table 数据结构后,也就是说转换到 Table API 层面之后是怎样的数据结构和数据类型?下面将通过 with_schema 添加字段及字段类型。这里只有一个字段,数据类型也是 String,最终注册成一个表,注册到 catlog 中,就可以供后面的查询计算使用了。

创建结果表,当计算完成后需要将这些结果存储到持久化系统中,以 WordCount 为例,首先存储表会有一个 word 以及它的计数两个字段,一个是 String 类型的 word,另一个是 Bigint 的计数,然后把它注册成 Sink。

编写注册完 Table Sink 后,再来看如何编写逻辑。其实用 Python API 写 WordCount 和 Table API 一样非常简单。因为相对于 DataSream 而言 Python API 写一个 WordCount 只需要一行。比如 group by,先扫描Source表,然后 group by 一个 Word,再进行 Select word 并加上聚合统计Count ,最终将最数据结果插入到结果表里面中。
3.Python Table API – 环境搭建

那么WordCount 怎样才能真正的运行起来?首先需要搭建开发环境,不同的机器上可能安装的软件版本不一样,这里列出来了一些版本的需求和要求,其中括号中是示例机器上的版本。

第二步,构建一个 Java 的二进制发布包,以从源代码进行构建,那么这一页面就是从原代码获取我们的主干代码,并且拉取 1.9 的分支。当然大家可以用 Mater,但是 Master 不够稳定,还是建议大家在自己学习的过程中,最好是用 1.9 的分支去做。接下来进行实战演练环节,首先验证 PPT 的正确性。首先编译代码,示例如下:
//下载源代码git clone https://github.com/apache/flink.git// 拉取1.9分支cd flink; git fetch origin release-1.9git checkout -b release-1.9 origin/release-1.9//构建二进制发布包mvn clean install -DskipTests -Dfast

编译完成后,需要在相应目录下找到发布包:
cd flink-dist/target/flink-1.9.0-bin/flink-1.9.0tar -zcvf flink-1.9.0.tar.gz flink-1.9.0
在构建完 Java 的 API 之后进行检验,我们要构建一个 Python 的发布包。

因为大多数 Python 的用户我们都知道我们需要 pip install 方式,将需要的依赖库进行与本地的 Python 环境进行集成或者安装。
那么 Flink 也是一样,PyFlink 也需要打包一个 Pypip 能够识别的资源进行安装,在实际的使用中,也可以按这种命令去拷贝,在自己的环境中尝试。
cd flink-Python;Python setup.py sdist
这个过程只是将 Java 包囊括进来,再把自己 PyFlink 本身模块的一些 Java 的包和 Python 包打包成一起,它会在 dist 目录下,有一个 apache-flink-1.9.dev0.tar.gz。
cd dist/
在 dist 目录的 apache-flink-1.9.dev0.tar.gz 就是我们可以用于 pip install 的 PyFlink 包。在1.9版本,除了 Flink Table,还有 Flink Table Blink。Flink 同时会支持两个 plan,如果大家可以尝试,我们可以自由的切换是 Flink 原有的 Planner,还是 Blink 的 Planner,大家可以去尝试。完成打包后,就可以尝试把包安装到我们的实际环境当中。

接下来是一个非常简单的命令,首先检查命令的正确性,在执行之前,我们用 pip 检查一下 list,我们要看在已有的包里有没有,现在尝试把刚才打包的包再安装。在实际的使用过程中,如果升级版,也要有这个过程,要把新的包要进行安装。
pip install dist/*.tar.gzpip list|grep flink

安装完成后,就可以用刚才写的 WordCount 例子来验证环境是否正确。验证一下刚才的正确性,怎么验证?为了大家方便,可以直接克隆 enjoyment.code 仓库。
git clone https://github.com/sunjincheng121/enjoyment.code.gitcd enjoyment.code; Python word_count.py
接下来体验并尝试。在这个目录下,我们刚才开发的 WordCount 例子。直接用 Python 或检验环境是否 OK。这个时候 Flink Python API 会启动一个 Mini 的 Cluster,会将刚才 WordCount Job 进行执行,提交到一个 Mini Cluster 进行执行。现在 Run 的过程中其实已经在集群上进行执行了。其实在这个代码里面是读了一个 Source 文件,把结果写到 CSV 文件,在当前目录,是有一个 Sink CSV 的。具体的操作步骤可以查看Flink中文社区视频Apache Flink Python API 现状及规划

IDE 的配置在正常的开发过程中,其实我们大部分还是在本地进行开发的,这里推荐大家还是用 Pychram 来开发 Python 相关的逻辑或者 Job。
同时由于有很大量的截图存在,也把这些内容整理到了博客当中,大家可以扫描二维码去关注和查看那么一些详细的注意事项,博客详细地址:https://enjoyment.cool。这里有一个很关键的地方,大家要注意,就是可能你的环境中有多种 Python 的环境,这时候选择的环境一定是刚才 pip install 环境。具体操作详见Apache Flink Python API 现状及规划。
4.Python Table API – 作业提交

还有哪些方式来提交 Job 呢?这是一个 CLI 的方式,也就是说真正的提交到一个现有的集群。首先启动一个集群。构建的目录一般在 target 目录下,如果要启动一个集群,直接启动就可以。这里要说一点的是,其中一个集群外部有个 Web Port,它的端口的地址都是在 flink-conf.yaml 配置的。按照 PPT 中命令,可以去查看日志,看是否启动成功,然后从外部的网站访问。如果集群正常启动,接下来看如何提交 Job 。

Flink 通过 run 提交作业,示例代码如下:
./bin/flink run -py ~/training/0806/enjoyment.code/myPyFlink/enjoyment/word_count_cli.py
用命令行方式去执行,除了用 PY 参数,还可以指定 Python 的 module,以及其他一些依赖的资源文件、JAR等。

在 1.9 版本中还为大家提供一种更便利的方式,就是以 Python Shell 交互式的方式来写 Python API 拿到结果。有两种方式可执行,第一种方式是 Local,第二种方式 Remote,其实这两种没有本质的差异。首先来看 Local ,命令如下:
bin/pyflink-shell.sh local
启动一个mini Cluster ,当输出后,会出来一个 Python 的 Flink CLI 同时会有一些示例程序,供大家来体验,按照上面的案例就能够达到正确的输出和提交,既可以写 Streaming,也可以写 Batch。详细步骤大家参考视频操作即可。
到目前为止,大家应该已经对 Flink 1.9 上 Python API 架构有了大概了解,同时也了解到如何搭建 Python API 环境。并且以一个简单的 WordCount 示例,体验如何在 IDE 里面去执行程序,如何以 Flink run 和交互式的方式去提交 Job。同时也体验了现有一些交互上的一种方式来使用 Flink Python API。那么介绍完了整个 Flink 的一些环境搭建和一个简单的示例后。接下来详细介绍一下在1.9里面所有的核心算子。
三.Flink Python API 核心算子介绍及应用
1.Python Table API 算子
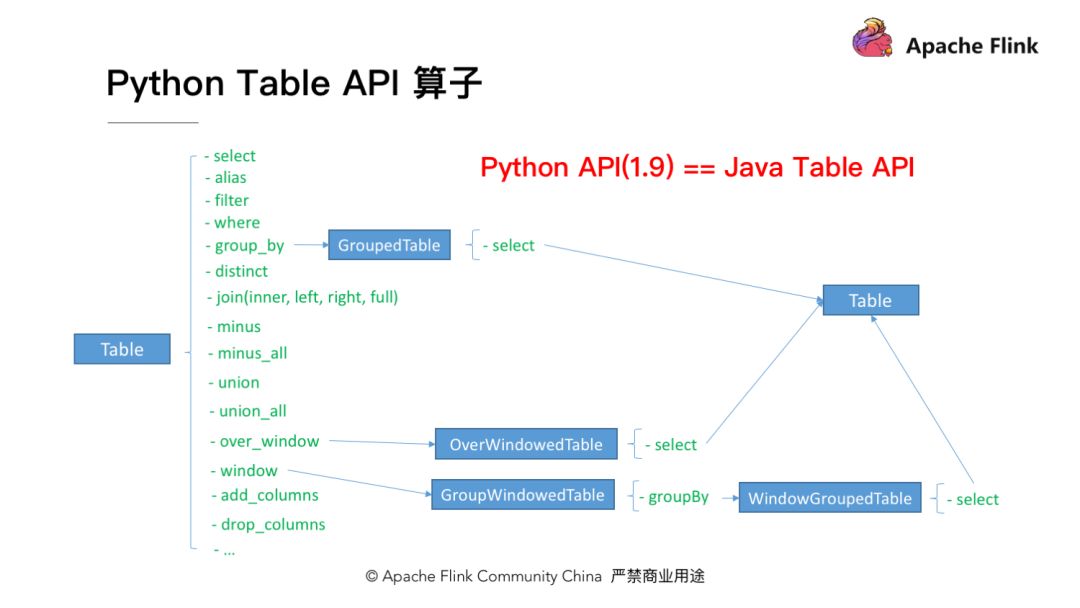
上面分享创建一个 Job 的过程,第一要选择执行的方式是Streaming还是Batch;第二个要定义使用的表,Source、Schema、数据类型;第三是开发逻辑,同时在写 WordCount 时,使用 Count 的函数。最后,在 Python API 里面内置了很多聚合函数,可以使用count,sum, max,min等等。
所以在目前 Flink 1.9 版本中,已经能够满足大多数常规需求。除了刚才讲到的 count。Flink Table API 算子 1.9 中也已经支持。关于 Flink Table API 算子,不论是 Python Table API 还是 Java 的Table API,都有以下几种类型的操作。第一单流上的操作,比如说做一些SELECT、Filter,同时还可以在流上做一些聚合,包括开窗函数的 windows 窗口聚合以及列的一些操作,比如最下面的 add_columns 和 drop_columns。
除了单流,还有双流的操作,比如说双流 JOIN、双流 minus、union ,这些算子在Python Table API 里面都提供了很好的支持。Python Table API 在 Flink 1.9 中,从功能的角度看几乎完全等同于Java Table API,下面以实际代码来看上述算子是怎么编写的以及怎么去开发Python算子。
2.Python Table API 算子-Watermark定义

细心的同学可能会注意到,我们尚未提到流的一个特质性 -> 时序。流的特性是来的顺序是可能乱序,而这种乱序又是流上客观存在的一种状态。在 Flink 中一般采用 Watermark 机制来解决这种乱序的问题。
在 Python API 中如何定义 Watermark?假设有一个 JSON 数据,a 字段 String,time 字段 datetime。这个时候定义 Watermark 就要在增加 Schema 时增加 rowtime 列。rowtime 必须是 timestamps 类型。
Watermark 有多种定义方式,上图中 watermarks_periodic_bounded 即会周期性的去发 Watermark,6万单位是毫秒。如果数据是乱序的,能够处理一分钟之内的乱序,所以这个值调的越大,数据乱序接受程度越高,但是有一点数据的延迟也会越高。关于 Watermark 原理大家可以查看我的blog: http://1t.click/7dM。
3.Python Table API – Java UDF

最后,跟大家分享一下 Java UDF在 Flink 1.9 版本中的应用, 虽然在1.9中不支持 Python 的 UDF ,但 Flink 为大家提供了可以在 Python 中使用 Java UDF。在 Flink 1.9 中,对 Table 模块进行了优化和重构,目前开发 Java UDF 只需要引入 Flink common 依赖就可以进行 Python API 开发。

接下来以一个具体的示例给大家介绍利用 Java UDF 开发 Python API UDF,假设我们开发一个求字符串长度的 UDF,在 Python 中需要用 Java 中的 register_java_function,function 的名字是包全路径。然后在使用时,就可以用注册的名字完成UDF的调用,详细可以查阅我的Blog: http://1t.click/HQF。

那怎样来执行?可以用 Flink run 命令去执行,同时需要将UDF的JAR包携带上去。
Java UDF 只支持 Scalar Function?其实不然,在 Java UDF中既支持 Scalar Function,也支持 Table Function和Aggregate Function。如下所示:

4.Python Table API 常用链接

上面所讲到的一些东西,有一些长链的文档和链接,也放在PPT上方便大家查阅,同时最下面我也有个人博客。希望对大家有帮助。
四.总结
简单的总结一下,本篇首先是介绍了Apache Flink Python API 历史发展的过程,介绍了Apache Flink Python API架构变更的原因以及当前架构模型;任何对未来 Flink Python API 是的规划与功能特性继续详细介绍,最后期望大家能在QA环节能给一些建议和意见,谢谢!
本文作者:孙金城(金竹)
本文为云栖社区原创内容,未经允许不得转载。
如何在 Apache Flink 中使用 Python API?的更多相关文章
- [译]如何在Web开发中使用Python
[译]如何在Web开发中使用Python 原文:HOWTO Use Python in the Web 摘要 这篇文档展示了Python如何融入到web中.它介绍了几种Python结合web服务器的方 ...
- Apache Flink中的广播状态实用指南
感谢英文原文作者:https://data-artisans.com/blog/a-practical-guide-to-broadcast-state-in-apache-flink 不过,原文最近 ...
- 如何在Ubuntu14.04中创建Python虚拟环境
在Ubuntu14.04中安装Python相对比较容易些,最简单的安装方法就是apt-get安装了,具体的教程可以戳这篇文章:在Ubuntu14.04中如何安装Python3和切换py2和py3环境. ...
- C++多线程中调用python api函数
错误场景:一直等待全局锁. 解决方法: 一.首先定义一个封装类,主要是保证PyGILState_Ensure, PyGILState_Release配对使用,而且这个类是可以嵌套使用的. #inclu ...
- 在apache环境中使用 python stock 请求遇到error: [Errno 13] Permission denied
一个python 项目运行在linux 环境下,使用apache做为web容器. 调用urllib2.urlopen(your url) 或者 xmlrpclib.ServerProxy()请求某个服 ...
- 如何在Apache HttpClient中设置TLS版本
1.简介 Apache HttpClient是一个底层.轻量级的客户端HTTP库,用于与HTTP服务器进行通信. 在本教程中,我们将学习如何在使用HttpClient时配置支持的传输层安全(TLS)版 ...
- 如何在batch脚本中嵌入python代码
老板叫我帮他测一个命令在windows下消耗的时间,因为没有装windows那个啥工具包,没有timeit那个命令,于是想自己写一个,原理很简单: REM timeit.bat echo %TIME% ...
- 如何在Mvc 6 中创建 Web Api以及如何脱离IIS实现自我托管
微软推出的Asp.net vNext(asp.net 5.0)的其中的一个目标就是统一mvc 和web api 的框架.接下来我就演示一下一下几个内容 1,怎么在Asp.net mvc 6 中创建简单 ...
- 如何在Windows系统中设置Python程序定时运行
文章出处:http://blog.csdn.net/wwy11/article/details/51100432 首先,我们肯定是要用到Windows下的[计划任务]功能 之后点击右侧的[创建基本任务 ...
随机推荐
- hexo换了电脑,怎么办?
个人博客:https://mmmmmm.me 源码:https://github.com/dataiyangu/dataiyangu.github.io 背景: 今天公司的苹果电脑硬件升级,之前看过h ...
- 4.1_springboot2.2任务之异步、定时、邮件任务
1.异步任务 在Java应用中,绝大多数情况下都是通过同步的方式来实现交互处理的:但是在处理与第三方系统交互的时候,容易造成响应迟缓的情况,之前大部分都是使用多线程来完成此类任务,其实,在Spri ...
- Redis连不上的一些细节配置
远程链接redis连不上,在确保防火墙设置正确的情况下 把redis.conf中的 bind 127.0.0.1注释 另外把protected-mode yes 改为protected-mode no
- 论文阅读笔记---ShuffleNet V1
01 ShuffleNet V1要解决什么问题 为算力有限的嵌入式场景下专门设计一个高效的神经网络架构. 02 亮点 使用了两个新的操作:pointwise group convolution和cha ...
- Visual Studio Git代码管理环境部署
Visual Studio 2010 部署Git代码管理环境. 第一:首先做Git的安装和环境部署 1.下载并安装Git软件,在windows环境下的Git叫做“msysGit”,官网地址为https ...
- CF528E Triangles3000
题意:给你一个不存在三线共交点的一次函数组a[i]x+b[i]y+c[i]=0. 问等概率选取三条直线,围成三角形的面积的期望. n<=3000. 标程: #include<bits/st ...
- Java Collection - 遍历map的几种方式
作者:zhaoguhong(赵孤鸿) 出处:http://www.cnblogs.com/zhaoguhong/ 本文版权归作者和博客园共有,转载请注明出处 ---------------- 总结 如 ...
- 启动web项目,监听器、过滤器、拦截器启动顺序
启动顺序:监听器 > 过滤器 > 拦截器 记忆技巧:接到命令,监听电报,过滤敌情,拦截行动.
- C++如何判断某一文件是否存在
函数名: access 功 能: 确定文件的访问权限 用 法: int access(const char *filename, int amode); 程序例: #include <stdio ...
- 三模数NTT模板
求两个多项式的卷积对任意数p取模 两个好记的FNT模数: 5*2^25+1 7*2^26+1 原根都为3 //Achen #include<algorithm> #include<i ...