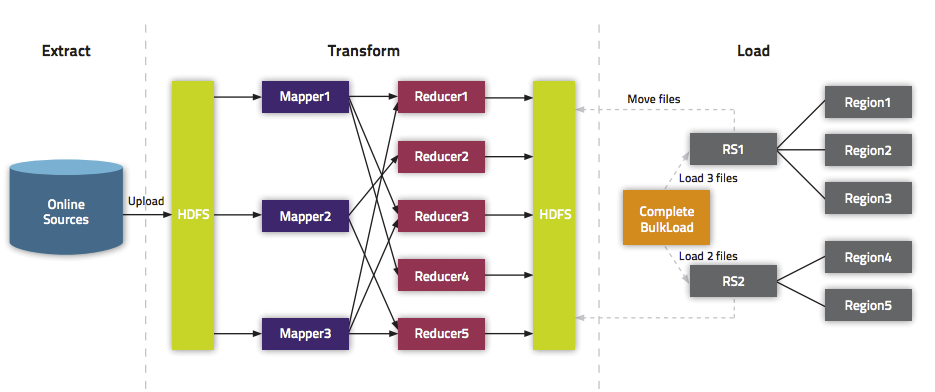
通过BlukLoad的方式快速导入海量数据
http://www.cnblogs.com/MOBIN/p/5559575.html
摘要


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public class GenerateHFile extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put>{ protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] items = line.split("\t"); String ROWKEY = items[1] + items[2] + items[3]; ImmutableBytesWritable rowkey = new ImmutableBytesWritable(ROWKEY.getBytes()); Put put = new Put(ROWKEY.getBytes()); //ROWKEY put.addColumn("INFO".getBytes(), "URL".getBytes(), items[0].getBytes()); put.addColumn("INFO".getBytes(), "SP".getBytes(), items[1].getBytes()); //出发点 put.addColumn("INFO".getBytes(), "EP".getBytes(), items[2].getBytes()); //目的地 put.addColumn("INFO".getBytes(), "ST".getBytes(), items[3].getBytes()); //出发时间 put.addColumn("INFO".getBytes(), "PRICE".getBytes(), Bytes.toBytes(Integer.valueOf(items[4]))); //价格 put.addColumn("INFO".getBytes(), "TRAFFIC".getBytes(), items[5].getBytes());//交通方式 put.addColumn("INFO".getBytes(), "HOTEL".getBytes(), items[6].getBytes()); //酒店 context.write(rowkey, put); }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public class GenerateHFileMain { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { final String INPUT_PATH= "hdfs://master:9000/INFO/Input"; final String OUTPUT_PATH= "hdfs://master:9000/HFILE/Output"; Configuration conf = HBaseConfiguration.create(); HTable table = new HTable(conf,"TRAVEL"); Job job=Job.getInstance(conf); job.getConfiguration().set("mapred.jar", "/home/hadoop/TravelProject/out/artifacts/Travel/Travel.jar"); //预先将程序打包再将jar分发到集群上 job.setJarByClass(GenerateHFileMain.class); job.setMapperClass(GenerateHFile.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); job.setOutputFormatClass(HFileOutputFormat2.class); HFileOutputFormat2.configureIncrementalLoad(job,table,table.getRegionLocator()); FileInputFormat.addInputPath(job,new Path(INPUT_PATH)); FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true)?0:1); }} |
|
1
2
3
4
5
6
7
8
|
public class LoadIncrementalHFileToHBase { public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(configuration); LoadIncrementalHFiles loder = new LoadIncrementalHFiles(configuration); loder.doBulkLoad(new Path("hdfs://master:9000/HFILE/OutPut"),new HTable(conf,"TRAVEL")); }} |
通过BlukLoad的方式快速导入海量数据的更多相关文章
- 通过BulkLoad的方式快速导入海量数据
摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使节点宕机),但是这些方式不是慢就 ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式)
mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式) 首先将要导入的数据文件top5000W.txt放入到数据库数据目录/var/local/mysql/data/${d ...
- MySQL 快速导入大量数据 资料收集
一.LOAD DATA INFILE http://dev.mysql.com/doc/refman/5.5/en/load-data.html 二. 当数据量较大时,如上百万甚至上千万记录时,向My ...
- 在Ubuntu上使用离线方式快速安装K8S v1.11.1
在Ubuntu上使用离线方式快速安装K8S v1.11.1 0.安装包文件下载 https://pan.baidu.com/s/1nmC94Uh-lIl0slLFeA1-qw v1.11.1 文件大小 ...
- 8、组件注册-@Import-给容器中快速导入一个组件
8.组件注册-@Import-给容器中快速导入一个组件 8.1 给容器中注册组建的方式 包扫描+组建标注注解(@Controller.@Service.@Repository.@Component)[ ...
- Mysql百万数据量级数据快速导入Redis
前言 随着系统的运行,数据量变得越来越大,单纯的将数据存储在mysql中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能 ...
- 【Spring注解驱动开发】使用@Import注解给容器中快速导入一个组件
写在前面 我们可以将一些bean组件交由Spring管理,并且Spring支持单实例bean和多实例bean.我们自己写的类,可以通过包扫描+标注注解(@Controller.@Servcie.@Re ...
随机推荐
- WannaCry结束了? 安专家注册域名掐断病毒传播
腾讯科技讯,(韩依民) 5 月 13 日,席卷全球的勒索病毒 WannaCry(也被称作 WanaCrypt 或 WCry),在今日晚间被互联网安全人员找到阻止其传播的方法. 据北京云纵信息技术有限公 ...
- 第十四篇:PL/SQL Developer Oracle配置和必知基础
1.一般在本地使用PL/SQL 第三方工具操作Oracle数据库,首先你的机器上得有oracle的客户端client,下一个就行了,很小2.首先找到你下载的oracle的客户端的包,找到tnsname ...
- PagedListCore的使用
关于在Core2.0中PagedListCore实现分页 一.引言 开发中在对大量数据展示的时候,出于对性能的考虑,我们往往是使用分页功能(用户需要那一页我们就返回给他那一页,而不是一次性加载所有的数 ...
- 使用CEfSharp之旅(1) 加载网络页面
原文:使用CEfSharp之旅(1) 加载网络页面 版权声明:本文为博主原创文章,未经博主允许不得转载.可点击关注博主 ,不明白的进群191065815 我的群里问 https://blog.csdn ...
- [记]Windows 系统下设置Nodejs NPM全局路径
Windows下的Nodejs npm路径是appdata,担心安装的node_modules越来越多,导致C盘满,所以参考别人的博文,将node_modules安装的默认目录修改一下. 参考Wind ...
- 廖雪峰Java11多线程编程-3高级concurrent包-2ReadWriteLock
ReentrantLock保证单一线程执行 ReentrantLock保证了只有一个线程可以执行临界区代码: 临界区代码:任何时候只有1个线程可以执行的代码块. 临界区指的是一个访问共用资源(例如:共 ...
- ssm框架,出现xxx不能加载,或者bean不能加载时的解决方案之一
有可能是你在项目的mapper.xml文件中添加了本项目没有的实体类, 你把日志中找不到的最后一个实体类全项目搜索下,改成本项目可以引用的即可
- CobaltStrike与Metasploit实战联动
前言 CobalStrike 与 Metasploit 均是渗透利器,各有所长.前者更适合做稳控平台,后者则更擅长内网各类探测搜集与漏洞利用.两者更需要灵活的联动,各自相互依托,从而提升渗透的效率. ...
- 深入理解JVM(一)类加载器部分、类变量、常量、jvm参数
类加载概述 在java代码中,类型的加载.连接与初始化过程都是在程序运行期间完成的 类型:class.interface(object本身).类型可在运行期间生成,如动态代理.一种runting概念 ...
- 第二周——1.项目中MySQL版本问题
1.版本升级 经组长推荐,本地安装的是mysql-8.0.11,而主项目用的还是版本5.6, 因此需要升级版本. 首先,更新驱动:下载mysql-connector-java-8.0.11,将E:\P ...