Flink中的多source+event watermark测试
这次需要做一个监控项目,全网日志的指标计算,上线的话,计算量应该是百亿/天
单个source对应的sql如下
最原始的sql
select pro,throwable,level,ip,`count`,id,`time`,firstl,lastl
from
(
select pro,throwable,level,ip,
count(*) as `count`,
lastStrInGroupSkipNull(CONCAT_WS('_',KAFKA_TOPIC,CAST(KAFKA_PARTITION AS VARCHAR),CAST(KAFKA_OFFSET as VARCHAR))) as id,
firstLong(l) as firstl,
lastLong(l) as lastl,
TUMBLE_END(SPT, INTERVAL '3' SECOND) as `time`
from input.`ymm-appmetric-dev-self1`
where
pro IS NOT NULL and throwable IS NOT NULL and level IS NOT NULL and level='ERROR' and ip IS NOT NULL
group by pro,throwable,level,ip,TUMBLE(SPT,INTERVAL '3' SECOND)
)
where 1=uniqueWithin100MS(pro,throwable,level,ip,`time`)
---先做技术论证,写了下面一个sql
select pro,throwable,level,ip,`count`,id,`time`,firstl,lastl
from (
select pro,throwable,level,ip,count(*) as `count`,
lastStrInGroupSkipNull(CONCAT_WS('_',KAFKA_TOPIC,CAST(KAFKA_PARTITION AS VARCHAR),CAST(KAFKA_OFFSET as VARCHAR))) as id,
firstLong(l) as firstl,
lastLong(l) as lastl,
TUMBLE_END(SPT, INTERVAL '3' SECOND) as `time`
from (
select pro,throwable,level,ip
from input.`ymm-appmetric-dev-self1`
where pro IS NOT NULL and throwable IS NOT NULL and level IS NOT NULL and level='ERROR' and ip IS NOT NULL
union
select pro,throwable,level,ip
from input.`ymm-appmetric-dev-self2`
where pro IS NOT NULL and throwable IS NOT NULL and level IS NOT NULL and level='ERROR' and ip IS NOT NULL
)
group by pro,throwable,level,ip,TUMBLE(SPT,INTERVAL '3' SECOND)
)
where 1=uniqueWithin100MS(pro,throwable,level,ip,`time`)
然后拉起flink任务,观察是否可顺利启动---果然报错了
Caused by: org.apache.calcite.sql.validate.SqlValidatorException: Column 'SPT' not found in any table
定位一下,看看是什么问题导致的,看了下之前写的sql,猜测是因为UNION的时候,没有在每个表里带上SPT时间属性字段以及其它字段,补上后sql如下
select pro,throwable,level,ip,`count`,id,`time`,firstl,lastl
from (
select pro,throwable,level,ip,count(*) as `count`,
lastStrInGroupSkipNull(CONCAT_WS('_',KAFKA_TOPIC,CAST(KAFKA_PARTITION AS VARCHAR),CAST(KAFKA_OFFSET as VARCHAR))) as id,
firstLong(l) as firstl,
lastLong(l) as lastl,
TUMBLE_END(SPT, INTERVAL '3' SECOND) as `time`
from (
select pro,throwable,level,ip,l,KAFKA_TOPIC,KAFKA_PARTITION,KAFKA_OFFSET,SPT
from input.`ymm-appmetric-dev-self1`
where pro IS NOT NULL and throwable IS NOT NULL and level IS NOT NULL and level='ERROR' and ip IS NOT NULL
union
select pro,throwable,level,ip,l,KAFKA_TOPIC,KAFKA_PARTITION,KAFKA_OFFSET,SPT
from input.`ymm-appmetric-dev-self2`
where pro IS NOT NULL and throwable IS NOT NULL and level IS NOT NULL and level='ERROR' and ip IS NOT NULL
)
group by pro,throwable,level,ip,TUMBLE(SPT,INTERVAL '3' SECOND)
)
where 1=uniqueWithin100MS(pro,throwable,level,ip,`time`)
再重启看看,这次应该差不多了吧---sql可以顺利编译,但是还是有错

奇怪了,之前并没有这样的错误,赞,我们来看看问题在哪!
我们打开类的层次图如下
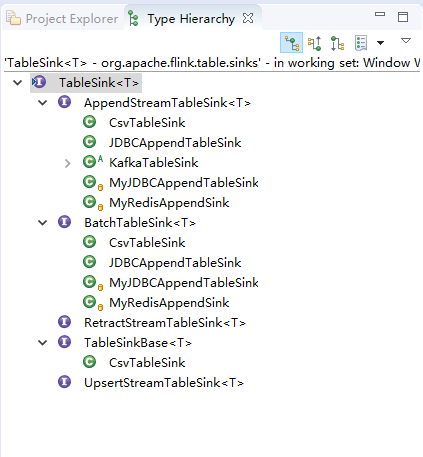
借这个机会加强对这些类的理解!
---经过我的调试,发现问题出现在union上,不加这个Union,啥事没有;加了就报错,下面我们再回到调用栈看看
一个人调试了一个下午,-_-||,最终发现知道修改一个地方就行
union -> union all
厉害了,给大佬低头!
----好,既然解决了,我们继续来debug原理层!
测试了一下,发现多source跟单source相比,单source的watermark很好理解,但是多source就稍微复杂些,下面我们来研究下原理!
首先,观察一下现有的图,如下所示:

下面再来研究一下线程,jstack一把
我们来分析上面的线程,看看有没有收获!挑几个重点线程讲解
"VM Periodic Task Thread" os_prio=0 tid=0x00007f366825e800 nid=0x63d waiting on condition
百度可以知道
该线程是JVM周期性任务调度的线程,它由WatcherThread创建,是一个单例对象。该线程在JVM内使用得比较频繁,比如:定期的内存监控、JVM运行状况监控。
下面几个是GC线程
"Gang worker#0 (Parallel GC Threads)" os_prio=0 tid=0x00007f3668031800 nid=0x626 runnable
"Gang worker#1 (Parallel GC Threads)" os_prio=0 tid=0x00007f3668033800 nid=0x627 runnable
"Gang worker#2 (Parallel GC Threads)" os_prio=0 tid=0x00007f3668035800 nid=0x628 runnable
"Gang worker#3 (Parallel GC Threads)" os_prio=0 tid=0x00007f3668037800 nid=0x629 runnable
"Gang worker#4 (Parallel GC Threads)" os_prio=0 tid=0x00007f3668039800 nid=0x62a runnable
"Gang worker#5 (Parallel GC Threads)" os_prio=0 tid=0x00007f366803b000 nid=0x62b runnable
"Gang worker#6 (Parallel GC Threads)" os_prio=0 tid=0x00007f366803d000 nid=0x62c runnable
"Gang worker#7 (Parallel GC Threads)" os_prio=0 tid=0x00007f366803f000 nid=0x62d runnable
"Concurrent Mark-Sweep GC Thread" os_prio=0 tid=0x00007f36680b7000 nid=0x630 runnable
"Gang worker#0 (Parallel CMS Threads)" os_prio=0 tid=0x00007f36680b2800 nid=0x62e runnable
"Gang worker#1 (Parallel CMS Threads)" os_prio=0 tid=0x00007f36680b4800 nid=0x62f runnable
---
"main" #1 prio=5 os_prio=0 tid=0x00007f3668019800 nid=0x625 waiting on condition [0x00007f3670010000]
主线程,在flink内部等待所有事情结束
"New I/O worker #1" #24 prio=5 os_prio=0 tid=0x00007f366995f000 nid=0x648 runnable [0x00007f3642cd1000]
内部netty线程
---
"Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #51 prio=5 os_prio=0 tid=0x00007f363d11a800 nid=0x65e in Object.wait() [0x00007f3641ac3000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.streaming.connectors.kafka.internal.Handover.pollNext(Handover.java:74)
- locked <0x00000000e6ee2df0> (a java.lang.Object)
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:133)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:721)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
"Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #50 prio=5 os_prio=0 tid=0x00007f363d120800 nid=0x65d in Object.wait() [0x00007f3641bc4000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.streaming.connectors.kafka.internal.Handover.pollNext(Handover.java:74)
- locked <0x00000000e6ee2e98> (a java.lang.Object)
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:133)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:721)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
有2个线程是用来获取消息,对于这2个线程来说,这2个消息不是直接读取kafka,而是其它线程读取kafka喂给这2个线程
---
"time attribute: (SPT) (1/1)" #53 prio=5 os_prio=0 tid=0x00007f363d8e4000 nid=0x662 in Object.wait() [0x00007f36418c1000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.runtime.io.network.partition.consumer.UnionInputGate.waitAndGetNextInputGate(UnionInputGate.java:205)
- locked <0x00000000e6ee8210> (a java.util.ArrayDeque)
at org.apache.flink.runtime.io.network.partition.consumer.UnionInputGate.getNextBufferOrEvent(UnionInputGate.java:163)
at org.apache.flink.streaming.runtime.io.BarrierTracker.getNextNonBlocked(BarrierTracker.java:94)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:209)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:103)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
这个线程对应了我们sql里的union算子
---
"groupBy: (pro, throwable, level, ip), window: (TumblingGroupWindow('w$, 'SPT, 3000.millis)), select: (pro, throwable, level, ip, COUNT(*) AS count, lastStrInGroupSkipNull($f5) AS id, firstLong(l) AS firstl, lastLong(l) AS lastl, start('w$) AS w$start, end('w$) AS w$end, rowtime('w$) AS w$rowtime, proctime('w$) AS w$proctime) -> where: (=(1, uniqueWithin100MS(pro, throwable, _UTF-16LE'ERROR', ip, w$end))), select: (pro, throwable, level, ip, count, id, w$end AS time, firstl, lastl) -> to: Row -> Sink: Kafka010JsonTableSink(pro, throwable, level, ip, count, id, time, firstl, lastl) (1/1)" #54 prio=5 os_prio=0 tid=0x00007f363fde3800 nid=0x664 in Object.wait() [0x00007f3641127000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.getNextBufferOrEvent(SingleInputGate.java:533)
- locked <0x00000000e6ee2d48> (a java.util.ArrayDeque)
at org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.getNextBufferOrEvent(SingleInputGate.java:502)
at org.apache.flink.streaming.runtime.io.BarrierTracker.getNextNonBlocked(BarrierTracker.java:94)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:209)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:103)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
这个对应了group by算子
---生产者
"kafka-producer-network-thread | producer-1" #55 daemon prio=5 os_prio=0 tid=0x00007f364d0f0800 nid=0x667 runnable [0x00007f3640a26000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e6ef3358> (a sun.nio.ch.Util$3)
- locked <0x00000000e6ef3340> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e6eedbd8> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.kafka.common.network.Selector.select(Selector.java:489)
at org.apache.kafka.common.network.Selector.poll(Selector.java:298)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:349)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:225)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:126)
at java.lang.Thread.run(Thread.java:748)
对应着生产者,直连kafka
---
"Time Trigger for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #57 daemon prio=5 os_prio=0 tid=0x00007f364d264800 nid=0x669 waiting on condition [0x00007f3640624000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000e6ef84c0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
"Time Trigger for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #56 daemon prio=5 os_prio=0 tid=0x00007f363e937800 nid=0x668 waiting on condition [0x00007f3640725000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000e6ee2bc8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
每个流对应着一个水印定时发送线程,因为我这边的输入是2个流
所以有2个水印发送线程
---
"Kafka Partition Discovery for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #61 prio=5 os_prio=0 tid=0x00007f364d25f000 nid=0x66c waiting on condition [0x00007f3640121000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase$2.run(FlinkKafkaConsumerBase.java:701)
at java.lang.Thread.run(Thread.java:748)
"Kafka Partition Discovery for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #59 prio=5 os_prio=0 tid=0x00007f363f4bc800 nid=0x66a waiting on condition [0x00007f3640323000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase$2.run(FlinkKafkaConsumerBase.java:701)
at java.lang.Thread.run(Thread.java:748)
2个自动分区发现线程
---
"Kafka 0.10 Fetcher for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #60 daemon prio=5 os_prio=0 tid=0x00007f364d269800 nid=0x66d runnable [0x00007f363bffe000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e73f0888> (a sun.nio.ch.Util$3)
- locked <0x00000000e73f0870> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e7279b20> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.kafka.common.network.Selector.select(Selector.java:489)
at org.apache.kafka.common.network.Selector.poll(Selector.java:298)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:349)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:226)
- locked <0x00000000e7497ec0> (a org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient)
at org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:1047)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:995)
at org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.run(KafkaConsumerThread.java:257)
"Kafka 0.10 Fetcher for Source: MyKafka010JsonTableSource -> from: (l, KAFKA_TOPIC, KAFKA_PARTITION, KAFKA_OFFSET, pro, throwable, level, ip, SPT) -> Timestamps/Watermarks -> where: (AND(=(level, _UTF-16LE'ERROR'), IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(ip))), select: (pro, throwable, CAST(_UTF-16LE'ERROR') AS level, ip, SPT, CONCAT_WS(_UTF-16LE'_', KAFKA_TOPIC, CAST(KAFKA_PARTITION), CAST(KAFKA_OFFSET)) AS $f5, l) (1/1)" #58 daemon prio=5 os_prio=0 tid=0x00007f363f4be800 nid=0x66b runnable [0x00007f3640222000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e6ef0758> (a sun.nio.ch.Util$3)
- locked <0x00000000e6ef0740> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e6ee0248> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.kafka.common.network.Selector.select(Selector.java:489)
at org.apache.kafka.common.network.Selector.poll(Selector.java:298)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:349)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:226)
- locked <0x00000000e6f03398> (a org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient)
at org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:1047)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:995)
at org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.run(KafkaConsumerThread.java:257)
对应着2个直连kafka的生产者线程
线程debug完了,下面我们来看每个线程做什么事情!这里先简单交代一下消息记录和watermark的背景
对于每个流,有1个消费者线程来读取kafka的消息
然后通过本地内存交换,喂给另外一个线程,就是文中Handover字样的线程,这个线程会把消息往下游发送,同时,有1个水印线程定时探测是否有更大时间戳出现,出现的话,把这个时间戳放在一个水印事件里下广播给下游.
---下面先来debug下Handover线程,看看是如何消息喂给unionInputGate线程的
断点在
stop at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher:154
跑起来!
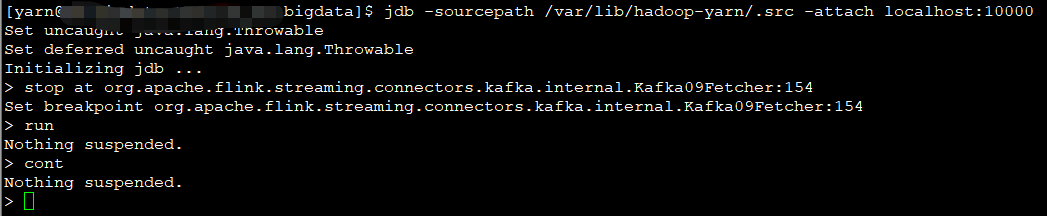
然后,发送一条消息到kafka,断点顺利命中

接下来就是具体看消息的流转过程!
消息处理过程中,会记录下当前事件的时间戳,位置在
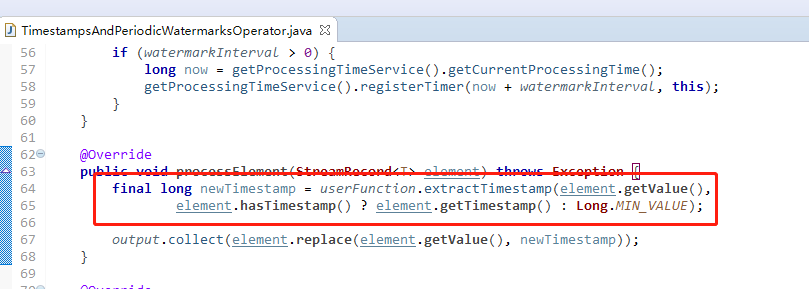
作用是如果时间戳比当前值更大,则更新这个时间戳,后面会有水印线程定时读取这个值决定是否需要发送水印信息
好,继续观察消息的流动,执行到了下面这个地方
[1] org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit (RecordWriter.java:104)
[2] org.apache.flink.streaming.runtime.io.StreamRecordWriter.emit (StreamRecordWriter.java:81)
[3] org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter (RecordWriterOutput.java:107)
[4] org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect (RecordWriterOutput.java:89)
[5] org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect (RecordWriterOutput.java:45)
[6] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[7] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[8] org.apache.flink.streaming.api.operators.TimestampedCollector.collect (TimestampedCollector.java:51)
[9] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:37)
[10] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:28)
[11] DataStreamCalcRule$69.processElement (null)
[12] org.apache.flink.table.runtime.CRowProcessRunner.processElement (CRowProcessRunner.scala:66)
[13] org.apache.flink.table.runtime.CRowProcessRunner.processElement (CRowProcessRunner.scala:35)
[14] org.apache.flink.streaming.api.operators.ProcessOperator.processElement (ProcessOperator.java:66)
[15] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[16] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[17] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[18] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[19] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[20] org.apache.flink.streaming.runtime.operators.TimestampsAndPeriodicWatermarksOperator.processElement (TimestampsAndPeriodicWatermarksOperator.java:67)
[21] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[22] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[23] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[24] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[25] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[26] org.apache.flink.streaming.api.operators.TimestampedCollector.collect (TimestampedCollector.java:51)
[27] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:37)
[28] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:28)
[29] DataStreamSourceConversion$23.processElement (null)
[30] org.apache.flink.table.runtime.CRowOutputProcessRunner.processElement (CRowOutputProcessRunner.scala:67)
[31] org.apache.flink.streaming.api.operators.ProcessOperator.processElement (ProcessOperator.java:66)
[32] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[33] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[34] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[35] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[36] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[37] org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollectWithTimestamp (StreamSourceContexts.java:310)
[38] org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collectWithTimestamp (StreamSourceContexts.java:409)
[39] org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher.emitRecordWithTimestamp (AbstractFetcher.java:398)
[40] org.apache.flink.streaming.connectors.kafka.internal.Kafka010Fetcher.emitRecord (Kafka010Fetcher.java:89)
[41] org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop (Kafka09Fetcher.java:154)
[42] org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run (FlinkKafkaConsumerBase.java:721)
[43] org.apache.flink.streaming.api.operators.StreamSource.run (StreamSource.java:87)
[44] org.apache.flink.streaming.api.operators.StreamSource.run (StreamSource.java:56)
[45] org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run (SourceStreamTask.java:99)
[46] org.apache.flink.streaming.runtime.tasks.StreamTask.invoke (StreamTask.java:306)
[47] org.apache.flink.runtime.taskmanager.Task.run (Task.java:703)
[48] java.lang.Thread.run (Thread.java:748)
看一下这里的即将执行的代码
public void emit(T record) throws IOException, InterruptedException {
for (int targetChannel : channelSelector.selectChannels(record, numChannels)) {
sendToTarget(record, targetChannel);
}
}
这里的print numChannels
numChannels = 1 --->因为我们有一个union操作,union自然是所有源归一!这就对了!
---最后放入消息并提醒消费线程,完整的调用栈如下:
[1] org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.queueChannel (SingleInputGate.java:623)
[2] org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.notifyChannelNonEmpty (SingleInputGate.java:612)
[3] org.apache.flink.runtime.io.network.partition.consumer.InputChannel.notifyChannelNonEmpty (InputChannel.java:121)
[4] org.apache.flink.runtime.io.network.partition.consumer.LocalInputChannel.notifyDataAvailable (LocalInputChannel.java:202)
[5] org.apache.flink.runtime.io.network.partition.PipelinedSubpartitionView.notifyDataAvailable (PipelinedSubpartitionView.java:56)
[6] org.apache.flink.runtime.io.network.partition.PipelinedSubpartition.notifyDataAvailable (PipelinedSubpartition.java:290)
[7] org.apache.flink.runtime.io.network.partition.PipelinedSubpartition.flush (PipelinedSubpartition.java:76)
[8] org.apache.flink.runtime.io.network.partition.ResultPartition.flush (ResultPartition.java:269)
[9] org.apache.flink.runtime.io.network.api.writer.RecordWriter.sendToTarget (RecordWriter.java:149)
[10] org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit (RecordWriter.java:105)
[11] org.apache.flink.streaming.runtime.io.StreamRecordWriter.emit (StreamRecordWriter.java:81)
[12] org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter (RecordWriterOutput.java:107)
[13] org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect (RecordWriterOutput.java:89)
[14] org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect (RecordWriterOutput.java:45)
[15] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[16] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[17] org.apache.flink.streaming.api.operators.TimestampedCollector.collect (TimestampedCollector.java:51)
[18] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:37)
[19] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:28)
[20] DataStreamCalcRule$69.processElement (null)
[21] org.apache.flink.table.runtime.CRowProcessRunner.processElement (CRowProcessRunner.scala:66)
[22] org.apache.flink.table.runtime.CRowProcessRunner.processElement (CRowProcessRunner.scala:35)
[23] org.apache.flink.streaming.api.operators.ProcessOperator.processElement (ProcessOperator.java:66)
[24] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[25] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[26] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[27] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[28] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[29] org.apache.flink.streaming.runtime.operators.TimestampsAndPeriodicWatermarksOperator.processElement (TimestampsAndPeriodicWatermarksOperator.java:67)
[30] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[31] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[32] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[33] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[34] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[35] org.apache.flink.streaming.api.operators.TimestampedCollector.collect (TimestampedCollector.java:51)
[36] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:37)
[37] org.apache.flink.table.runtime.CRowWrappingCollector.collect (CRowWrappingCollector.scala:28)
[38] DataStreamSourceConversion$23.processElement (null)
[39] org.apache.flink.table.runtime.CRowOutputProcessRunner.processElement (CRowOutputProcessRunner.scala:67)
[40] org.apache.flink.streaming.api.operators.ProcessOperator.processElement (ProcessOperator.java:66)
[41] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator (OperatorChain.java:560)
[42] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:535)
[43] org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect (OperatorChain.java:515)
[44] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:679)
[45] org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect (AbstractStreamOperator.java:657)
[46] org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollectWithTimestamp (StreamSourceContexts.java:310)
[47] org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collectWithTimestamp (StreamSourceContexts.java:409)
[48] org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher.emitRecordWithTimestamp (AbstractFetcher.java:398)
[49] org.apache.flink.streaming.connectors.kafka.internal.Kafka010Fetcher.emitRecord (Kafka010Fetcher.java:89)
[50] org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop (Kafka09Fetcher.java:154)
[51] org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run (FlinkKafkaConsumerBase.java:721)
[52] org.apache.flink.streaming.api.operators.StreamSource.run (StreamSource.java:87)
[53] org.apache.flink.streaming.api.operators.StreamSource.run (StreamSource.java:56)
[54] org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run (SourceStreamTask.java:99)
[55] org.apache.flink.streaming.runtime.tasks.StreamTask.invoke (StreamTask.java:306)
[56] org.apache.flink.runtime.taskmanager.Task.run (Task.java:703)
[57] java.lang.Thread.run (Thread.java:748)
---水印的处理应该也是类似的,所以接下来,我们来看Union所在的线程
我们再来复习下上面里提到的这个线程的调用栈
"time attribute: (SPT) (1/1)" #53 prio=5 os_prio=0 tid=0x00007f363d8e4000 nid=0x662 in Object.wait() [0x00007f36418c1000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.runtime.io.network.partition.consumer.UnionInputGate.waitAndGetNextInputGate(UnionInputGate.java:205)
- locked <0x00000000e6ee8210> (a java.util.ArrayDeque)
at org.apache.flink.runtime.io.network.partition.consumer.UnionInputGate.getNextBufferOrEvent(UnionInputGate.java:163)
at org.apache.flink.streaming.runtime.io.BarrierTracker.getNextNonBlocked(BarrierTracker.java:94)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:209)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:103)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
这个线程对应了我们sql里的union算子
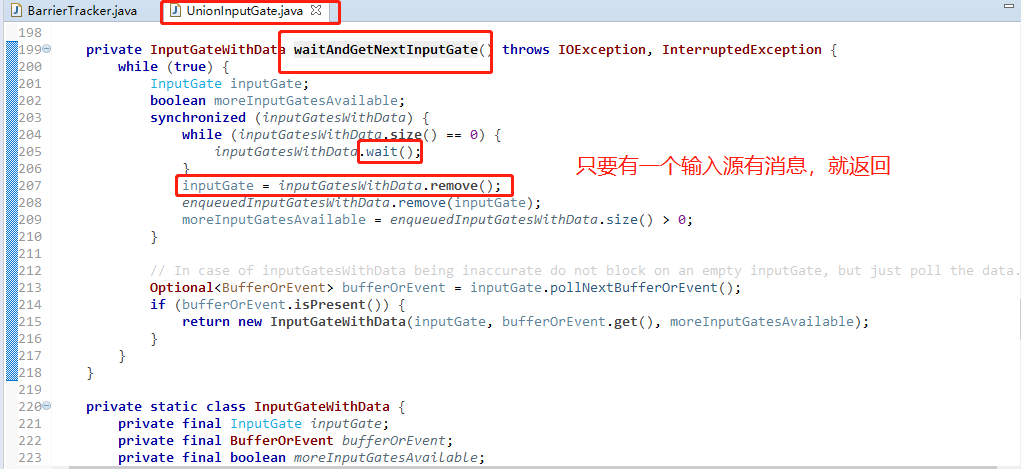
上面这个图,是等待有消息过来就提取消息,任何一个源有消息都会触发消息提取,否则wait
---注意:这里的消息有4种类型,一般我们只需要关注record+watermark即可
具体地点是:

---这里讲一下,关于LatencyMarker,默认2秒钟发送一次,截图如下
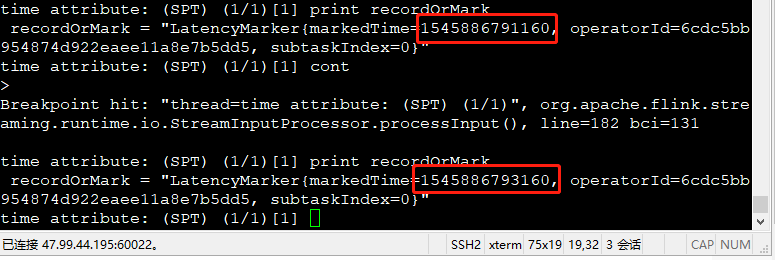
其它的不管是record还是watermark都会往下发送!
下面我们来在union里同时针对record和watermark打断点,猜一猜哪个断点先被触发?
断点位于【针对flink-1.5版本】
Breakpoints set:
breakpoint org.apache.flink.streaming.runtime.io.StreamInputProcessor:184
breakpoint org.apache.flink.streaming.runtime.io.StreamInputProcessor:198
触发的顺序如下:
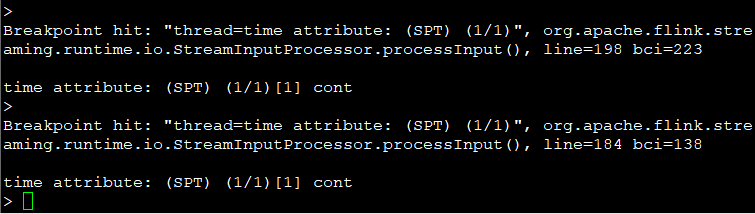
---跟想的是一样的! 下面就去研究下groupby线程
"groupBy: (pro, throwable, level, ip), window: (TumblingGroupWindow('w$, 'SPT, 3000.millis)), select: (pro, throwable, level, ip, COUNT(*) AS count, lastStrInGroupSkipNull($f5) AS id, firstLong(l) AS firstl, lastLong(l) AS lastl, start('w$) AS w$start, end('w$) AS w$end, rowtime('w$) AS w$rowtime, proctime('w$) AS w$proctime) -> where: (=(1, uniqueWithin100MS(pro, throwable, _UTF-16LE'ERROR', ip, w$end))), select: (pro, throwable, level, ip, count, id, w$end AS time, firstl, lastl) -> to: Row -> Sink: Kafka010JsonTableSink(pro, throwable, level, ip, count, id, time, firstl, lastl) (1/1)" #54 prio=5 os_prio=0 tid=0x00007f363fde3800 nid=0x664 in Object.wait() [0x00007f3641127000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.getNextBufferOrEvent(SingleInputGate.java:533)
- locked <0x00000000e6ee2d48> (a java.util.ArrayDeque)
at org.apache.flink.runtime.io.network.partition.consumer.SingleInputGate.getNextBufferOrEvent(SingleInputGate.java:502)
at org.apache.flink.streaming.runtime.io.BarrierTracker.getNextNonBlocked(BarrierTracker.java:94)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:209)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:103)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
这个对应了group by算子
针对group by来说,最重要的环节,这个其实跟union线程一样的,也是在
org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput
这里面来做事件的分发,所以断点都是一样的
---
这里主要强调,在groupby处理watermark时的位置如下:【尤其是针对多个source来说,很容易出问题】
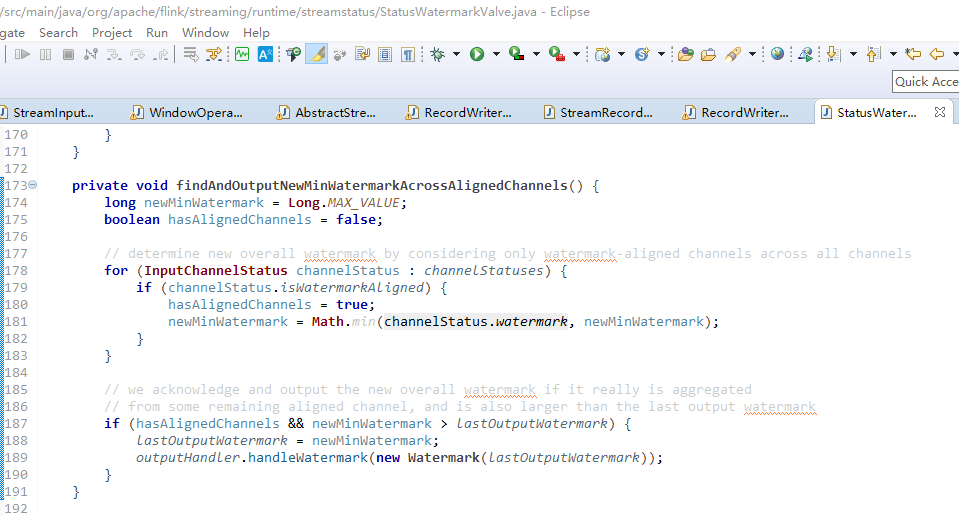
这个时候,我意识到在groupby线程中来观察watermark还早了点,因为在union线程中针对watermark的处理还有一些秘密
所以我们回到union线程来挖这些秘密,把groupby线程用suspend命令挂起来,专门debug union线程即可!
---打个断点【针对flink-1.5】
stop at org.apache.flink.streaming.runtime.io.StreamInputProcessor:184
研究了一把,大致明白原理了,这么说吧,线程模型如下
流1-------
|
|
|
|
|
|---------->union线程的watermark--------->groupby线程的watermark
|
|
|
|
流2-------
其中,流1和流2---每次都发送自己看到的最大时间戳发送个下游(看到小的就什么都不做)
union这里会动态更新流1和流2的各自所看到的最大时间戳,同时取Min(流1的最大时间戳,流2的最大时间戳),跟上一次的值比较
如果>上一次的Min值,则发送给group by.
---我觉得读者看到这里,肯定已经懵逼了,我来解释下思想
强调一下:消息在中间过程中不拦截,直达最后的windowoperator那里做windowLate判断决定是否丢弃!
===========================================================================================
对于流1来说,它每次发送自己已知的最大时间戳给下游,就是说“你好,下游,对我来说小于这个时间戳的就算是延迟消息,你看着办”
对于流2来说,它每次发送自己已知的最大时间戳给下游,就是说“你好,下游,对我来说小于这个时间戳的就算是延迟消息,你看着办”
---对于union来说,这里复杂些
它取值min( 流1的max时间戳,流2的max时间戳)跟上一次的min( 流1的max时间戳,流2的max时间戳)比较,
如果发现递增了,就把当前较大的这个min值发送给下游,说“你好,下游,全局来说,对我来说小于这个时间戳的就算是延迟消息,我只能帮到这里了,已经尽力拖住时间戳了,你看着办”
---对于groupby来说,它收到时间戳,每次保留最大值,然后参考最大值来快速决定每个消息是不是延迟消息(最大值-可容忍的延迟消息)。
所以,在多源情况下,判断全局一个消息是不是延迟消息,实际上由min( 流1的max时间戳,流2的max时间戳)这个值来参与决定
---
我们再跳出来想一想这个事情,我估计读者最懵逼的地方就是union为啥取每个流的最小值,而不是最大值
我们就这么理解吧,如果取最大值,那消费慢的流的数据大部分都成为了late数据被丢弃,union就会被打
所以union为了防止被打,它不想惹众怒,就取了min(每个流),这样所有人都无话可说了
union旁白:我都取了你们每个流的各自的时间戳最大值的全局最小值,还要我怎么样,
最慢的那个流也不会说啥了,因为取的就是它这个流上报的自身最大值。
上面都是从技术角度来阐述这个事情,那么我们再拔高一下,从更高的层次来看这个事情
其实就是让更多的数据没有成为late数据,纳入正常运算范围内,由min( 流1的max时间戳,流2的max时间戳)的递增来推动全局windowoperator的计算输出结果. 相应的,消费最慢的流会拖累最终业务数据的延迟生成.
---读者可以再细细琢磨里面的门道,下面我们来做逻辑测试!验证我们是否真正理解了这个游戏规则!
背景:容忍延迟3000毫秒
下面每行的格式就是:流名称 + 时间戳 ,每次只输出1条
1)流1 + 1545703896000
2)流1 + 1545703896000
3)流2 + 1545703896000
4)流2 + 1545703898999
5)流2 + 1545703899000
6)流1 + 1545703899000
7)流1 + 1545703900000
8)流2 + 1545703902000-1 --->这个不会触发windowOperator的输出,因为流1的最小值还不够
9)流1 + 1545703902000-1 --->这个才会触发windowOperator的输出
正确输出了,记住,一定要2个流
【齐头并进,理实交融】
但是,其实,仅仅研究到这一步,并没有完全结束,欲知后事如何请听下回分解 :)
原文链接:
Flink中的多source+event watermark测试的更多相关文章
- 老板让阿粉学习 flink 中的 Watermark,现在他出教程了
1 前言 在时间 Time 那一篇中,介绍了三种时间概念 Event.Ingestin 和 Process, 其中还简单介绍了乱序 Event Time 事件和它的解决方案 Watermark 水位线 ...
- Flink中的window、watermark和ProcessFunction
一.Flink中的window 1,window简述 window 是一种切割无限数据为有限块进行处理的手段.Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有 ...
- 彻底搞清Flink中的Window
窗口 在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理.当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的 ...
- Flink学习(二)Flink中的时间
摘自Apache Flink官网 最早的streaming 架构是storm的lambda架构 分为三个layer batch layer serving layer speed layer 一.在s ...
- 《从0到1学习Flink》—— Flink 中几种 Time 详解
前言 Flink 在流程序中支持不同的 Time 概念,就比如有 Processing Time.Event Time 和 Ingestion Time. 下面我们一起来看看这几个 Time: Pro ...
- Flink 中极其重要的 Time 与 Window 详细解析(深度好文,建议收藏)
前言 Flink 是流式的.实时的 计算引擎 上面一句话就有两个概念,一个是流式,一个是实时. 流式:就是数据源源不断的流进来,也就是数据没有边界,但是我们计算的时候必须在一个有边界的范围内进行,所以 ...
- Flink中的Time
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- 《从0到1学习Flink》—— 介绍Flink中的Stream Windows
前言 目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语(例如,"windowin ...
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
随机推荐
- Python 实现0-1背包
代码: import numpy as np c=10 #背包容量 w=[2,2,6,5,4] #物品重量 v=[5,3,5,4,6] #物品价值 flag =[0,0,0,0,0] m=np.zer ...
- 伪造ip头
x-forwarded-for: 127.0.0.1x-remote-IP: 127.0.0.1x-remote-ip: 127.0.0.1x-client-ip: 127.0.0.1x-client ...
- PagedListCore的使用
关于在Core2.0中PagedListCore实现分页 一.引言 开发中在对大量数据展示的时候,出于对性能的考虑,我们往往是使用分页功能(用户需要那一页我们就返回给他那一页,而不是一次性加载所有的数 ...
- 6_1.springboot2.x整合JDBC与数据源配置原理解析
1.引言 对于数据访问层,无论是SQL还是NOSQL,Spring Boot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置.引入各种xxxTemplate,x ...
- Django的日常-模型层(1)
目录 Django的日常-模型层(1) 模型层 django测试环境 ORM查询 Django的日常-模型层(1) 模型层 模型层其实就是我们应用名下的models.py文件,我们在里面写入想要创建的 ...
- <Django>第一篇:入门的例子
1.MVT框架 Model(模型):数据库交互相关.在这部分一般需要进行三个操作: (1)面向数据库:模型对象.列表 (2)定义模型类:指定属性及类型,确定表结构(设计表),需要迁移(生成表) (3) ...
- SpringCloud学习笔记《---03 Ribbon---》基础篇
- NuGet 命令行使用EntityFrameWork
初始化 Enable-migrations 迁移 Add-Migration Donator_Add_CreationTime 执行操作 UpDate-database 撤销更改 Update-Dat ...
- JS 标签页切换(复杂)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xht ...
- WPF 免费控件库
https://github.com/Infragistics/InfragisticsThemesForMicrosoftControls 几款WPF免费控件库,不过运行源码时需要下载三个DLL , ...