Pandas库之DataFrame
Pandas库之DataFrame
1 简介
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。
同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位,具体方法在后面细说。
2 创建DataFrame
首先声明一下,以下都是使用的Python 3.6.5版本为例,Python2应该也差不多吧(大概
在所有操作之前当然要先import必要的pandas库,因为pandas常与numpy一起配合使用,所以也一起import吧。
import pandas as pd
import numpy as np如果还没安装直接在cmd里pip安装吧,如果有版本选择问题,参看之前的帖子。
pip install pandas
pip install numpy2.1 直接创建
可以直接使用pandas的DataFrame函数创建,比如接下来我们随机创建一个4*4的DataFrame。
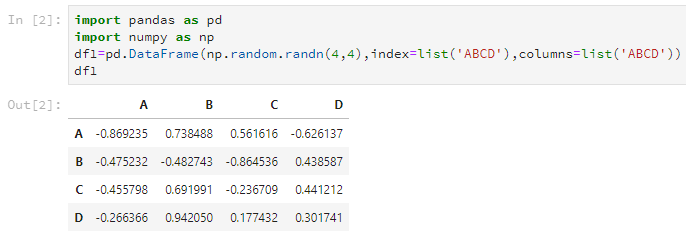
df1=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD'))其中第一个参数是存放在DataFrame里的数据,第二个参数index就是之前说的行名(或者应该叫索引?),第三个参数columns是之前说的列名。
后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配,不然会报错。当然,这两个参数是可选的,你可以选择不设置。
而且发现,这两个list是可以一样的,但是每行每列的名字在index或columns里要是唯一的。
使用python自己的shell展示创建的结果是这样的:

或者在jupyter里面更酷点的样子,接下来都使用jupyter输出展示吧。
当然,如果你的数据量贼小,也可以自己输入创建,类似这样。
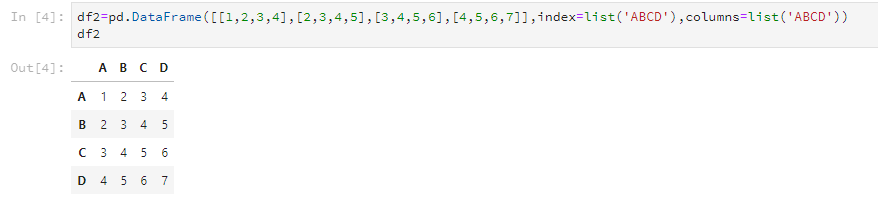
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],
[3,4,5,6],[4,5,6,7]],
index=list('ABCD'),columns=list('ABCD'))这样也可以得到这样子的DataFrame:
2.2 使用字典创建
仍然是使用DataFrame这个函数,但是字典的每个key的value代表一列,而key是这一列的列名。比如这样。
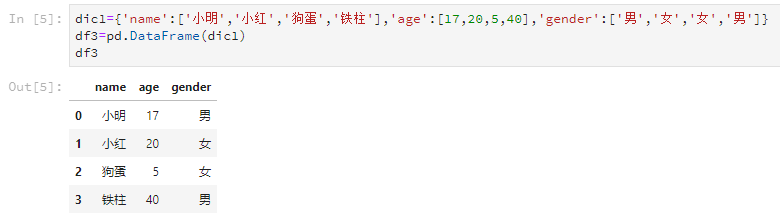
dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'gender':['男','女','女','男']}
df3=pd.DataFrame(dic1)输出结果是这样的
3 查看与筛选数据
python没有matlab的工作区直接查看变量与内容,这大概是python科学计算的一个缺点。所以需要格外的代码来查看,最基本的直接写变量名与print就不说了。
3.1 查看列的数据类型
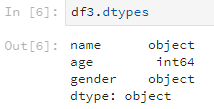
使用dtypes方法可以查看各列的数据类型,比如说刚刚的df3。
df3.dtypes输出的结果是这样:
3.2 查看DataFrame的头尾
使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。
使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。
比如随意设置一个6*6的数据,只看前5行。
df4=pd.DataFrame(np.random.randn(6,6))
df4.head()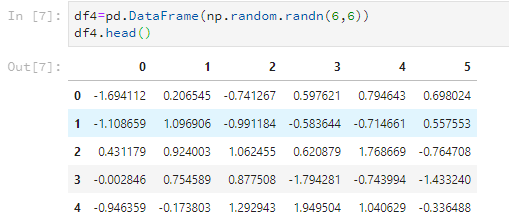
比如只看前3行。
df4.head(3)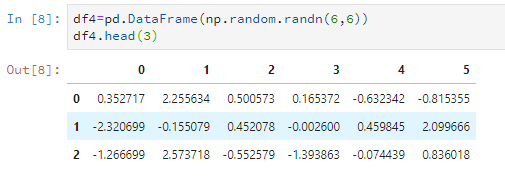
比如看后5行。
df4.tail()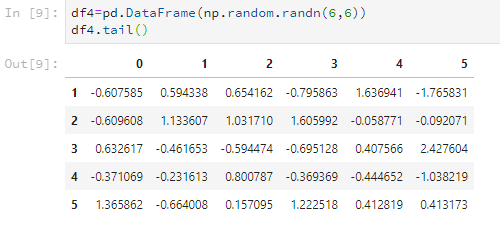
比如只看后2行。
df4.tail(2)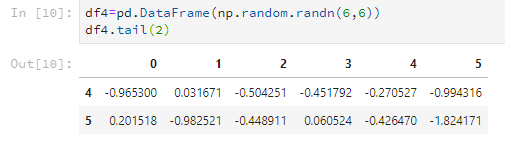
3.3 查看行名与列名
使用index查看行名,columns查看列名。具体由例子感受吧。
查看行名。
df1.index
查看列名。
df3.columns
3.4 查看数据值
使用values可以查看DataFrame里的数据值,返回的是一个数组。
比如说查看所有的数据值。
df3.values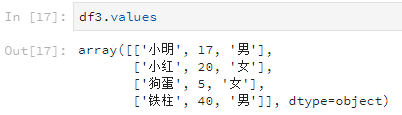
比如说查看某一列所有的数据值。
df3['name'].values
还有另一种操作,使用loc或者iloc查看数据值(但是好像只能根据行来查看?)。区别是loc是根据行名,iloc是根据数字索引(也就是行号)。
比如说这样。
df1.loc['A']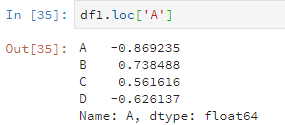
或者这样。
df1.iloc[0]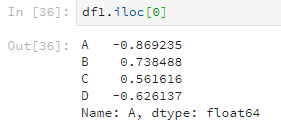
按列进行索引查看数据还能直接使用列名,但这种方法对行索引不适用。
df3['name']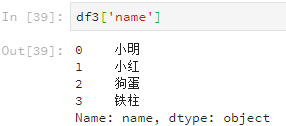
3.5 查看行列数
使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。
df3.shape[0]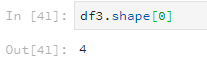
df3.shape[1]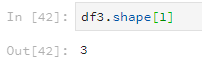
4 基本操作
DataFrame有些方法可以直接进行数据统计,矩阵计算之类的基本操作。
4.1 转置
直接字母T,线性代数上线。
比如说把之前的df2转置一下。
df3.T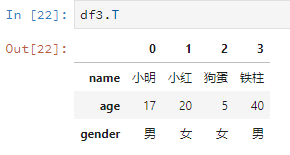
4.2 描述性统计
使用describe可以对数据根据列进行描述性统计。
比如说对df1进行描述性统计。
df1.describe()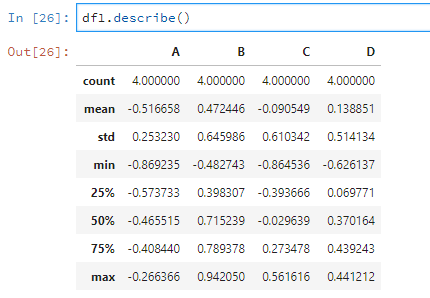
如果有的列是非数值型的,那么就不会进行统计。
如果想对行进行描述性统计,请参看4.1(转置后进行describe呀!)
4.3 计算
使用sum默认对每列求和,sum(1)为对每行求和。比如
df3.sum()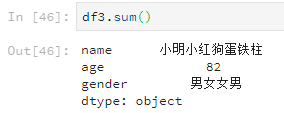
可以发现就算元素是字符串,使用sum也会加起来。
df3.sum(1)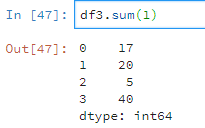
而一行中,有字符串有数值则只计算数值。
数乘运算使用apply,比如。
df2.apply(lambda x:x*2)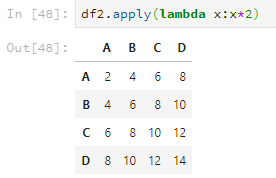
如果元素是字符串,则会把字符串再重复一遍。
乘方运算跟matlab类似,直接使用两个*,比如。
df2**2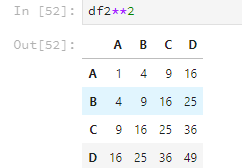
乘方运算如果有元素是字符串的话,就会报错。
4.4 新增
扩充列可以直接像字典一样,列名对应一个list,但是注意list的长度要跟index的长度一致。
df2['E']=['999','999','999','999']
df2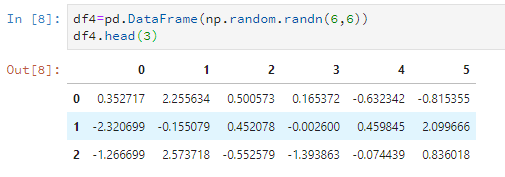
还可以使用insert,使用这个方法可以指定把列插入到第几列,其他的列顺延。
df2.insert(0,'F',[888,888,888,888])
df2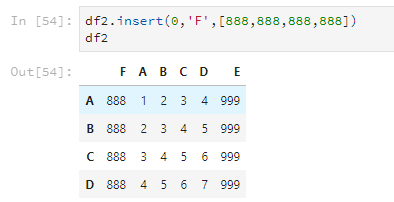
4.5 合并
使用join可以将两个DataFrame合并,但只根据行列名合并,并且以作用的那个DataFrame的为基准。如下所示,新的df7是以df2的行号index为基准的。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7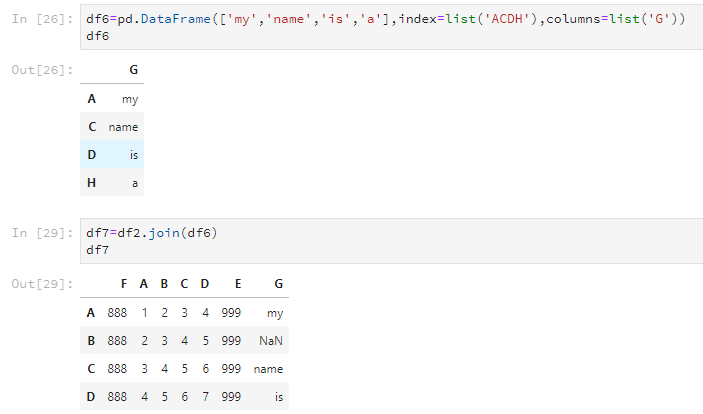
但是,join这个方法还有how这个参数可以设置,合并两个DataFrame的交集或并集。参数为'inner'表示交集,'outer'表示并集。
df8=df2.join(df6,how='inner')
df8
df9=df2.join(df6,how='outer')
df9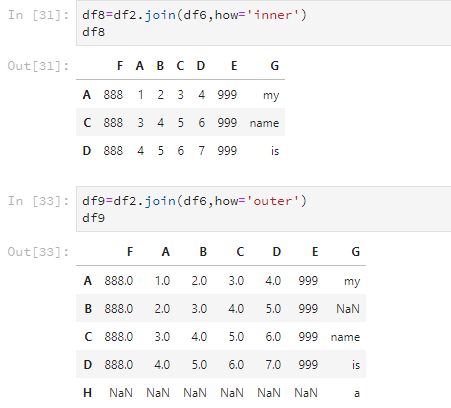
如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe。
df10=pd.DataFrame([1,2,3,4],index=list('ABCD'),columns=['a'])
df11=pd.DataFrame([10,20,30,40],index=list('ABCD'),columns=['b'])
df12=pd.DataFrame([100,200,300,400],index=list('ABCD'),columns=['c'])
list1=[df10.T, df11.T, df12.T]
df13=pd.concat(list1)
df13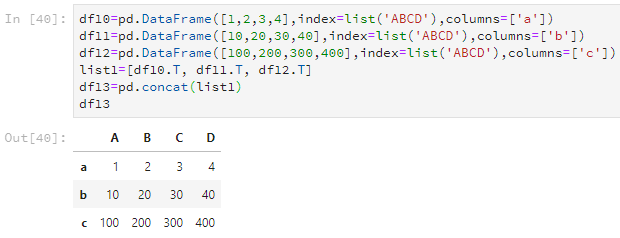
Pandas库之DataFrame的更多相关文章
- 【Python学习笔记】Pandas库之DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
- Pandas 库之 DataFrame
How to use DataFrame ? 简介 创建 DataFrame 查看与筛选数据:行列选取 DataFrame 数据操作:增删改 一.About DataFrame DataFrame 是 ...
- python数据分析之pandas库的DataFrame应用二
本节介绍Series和DataFrame中的数据的基本手段 重新索引 pandas对象的一个重要方法就是reindex,作用是创建一个适应新索引的新对象 ''' Created on 2016-8-1 ...
- [转]python中pandas库中DataFrame对行和列的操作使用方法
转自:http://blog.csdn.net/u011089523/article/details/60341016 用pandas中的DataFrame时选取行或列: import numpy a ...
- python中pandas库中DataFrame对行和列的操作使用方法
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFram ...
- python数据分析之pandas库的DataFrame应用一
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值,字符串,布尔型).DateFrame既有行索引也有列索引,可以被看作为由Series组成的字典. 构建Dat ...
- 数据分析与展示---Pandas库入门
简介 一:Pandas库的介绍 二:Pandas库的Series类型 (一)索引 (1)自动索引 (2)自定义索引 (二)Series类型创建 (1)列表创建 (2)标量值创建 (3)字典类型创建(将 ...
- pandas库学习笔记(二)DataFrame入门学习
Pandas基本介绍——DataFrame入门学习 前篇文章中,小生初步介绍pandas库中的Series结构的创建与运算,今天小生继续“死磕自己”为大家介绍pandas库的另一种最为常见的数据结构D ...
- Pandas库中的DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
随机推荐
- JSP Web第八章整理复习 过滤器
P269 Filter过滤器的基本原理 P269 Filter过滤器体系结构 原理和体系结构看懂了就行 P270 例8-1过滤器代码与配置文件 略
- NOIP模拟 17.8.17
NOIP模拟17.8.17 A 小 G 的字符串文件名 输入文件 输出文件 时间限制 空间限制str.pas/c/cpp str.in str.out 1s 128MB[题目描述]有一天,小 L 给小 ...
- 【JZOJ3824】【NOIP2014模拟9.9】渴
SLAF 世界干涸,Zyh认为这个世界的人们离不开水,于是身为神的他要将他掌控的仅仅两个水源地放置在某两个不同的城市.这个世界的城市因为荒芜,他们仅仅保留了必要的道路,也就是说对于任意两个城市有且仅有 ...
- PyCharm2019 永久激活
<!-- 2019激活码 2019-06-21新更新 --> D00F1BDTGF-eyJsaWNlbnNlSWQiOiJEMDBGMUJEVEdGIiwibGljZW5zZWVOYW1l ...
- 遗传算法MATLAB实现(1):工具箱下载及安装
到官网下载谢菲尔德大学的GA工具箱:http://codem.group.shef.ac.uk/index.php/ga-toolbox(其实蛮不懂为什么有人把这个传到某个网上还需要积分才能下载,人家 ...
- day40-Spring 01-上次课内容回顾
- 洛谷 P3258 [JLOI2014]松鼠的新家 树链剖分+差分前缀和优化
目录 题面 题目链接 题目描述 输入输出格式 输入格式 输出格式 输入输出样例 输入样例: 输出样例: 说明 说明 思路 AC代码 优化 优化后AC代码 总结 题面 题目链接 P3258 [JLOI2 ...
- vue_qqmapdemo1
腾讯地图vue组件,实现异步加载腾讯地图,坐标拾取器,支持按城市名称搜索. 搜索框样式依赖elementUI,不需要可删除顶部,地图部分无依赖项 //qqmap.vue <template> ...
- hdu2044 dp
/* 每一种情况都可以由周围2个点得出 */ #include<stdio.h> int main() { __int64 dp[]; int i,t,l,r; dp[]=; dp[]=; ...
- 干货 | 解读MySQL 8.0新特性:Skip Scan Range
MySQL从8.0.13版本开始支持一种新的range scan方式,称为Loose Skip Scan.该特性由Facebook贡献.我们知道在之前的版本中,如果要使用到索引进行扫描,条件必须满足索 ...