Mesh R-CNN 论文翻译(实验部分)
本文为 Mesh R-CNN 论文翻译(原理部分)的后续。Mesh R-CNN 原论文。
4 实验
我们在ShapeNet上对网格预测分支进行基准测试,并与最先进的方法相比较。然后,我们在野生的有挑战性的Pix3D数据集评估我们的完整Mesh R-CNN的三维形状预测任务。
4.1 ShapeNet
ShapeNet[4]提供了一组三维形状,这些形状以纹理化的CAD模型表示,这些模型根据WordNet[42]组织成语义类别,并被广泛用作三维形状预测的基准。我们使用ShapeNetCore.v1的子集,以及来自[5]:3D-R2N2的渲染图像。每个网格是由多达24个随机的视点渲染,给出大小为137×137的RGB图像(如下图)。我们使用[68]提供的train / test 划分,分配35,011个模型(840,189张图片)进行训练,8,757个模型(210,051张图片)进行测试;在训练和测试中使用的模型是不相交的。我们保留5%的培训模型作为验证集。
这个数据集的任务是在一个空白背景上输入一个渲染ShapeNet模型的RGB图像,并在相机坐标系统中输出一个对象的3D网格。在训练过程中,系统由成对的图像和网格进行监督。
评估 我们采用近期工作中使用的评价指标[55,56,68]。我们从预测网格和GT网格表面随机均匀采样10k个点,并用它们计算倒角距离(等式1),正常稠度(Normal consistency)(等于 1 减去等式2),在不同距离阈值\(\tau\)时的\(F1_{\tau}\), 其中\(F1_{\tau}\)是\(\tau\)的准确率\(P\)(即位于真实网格采样点\(\tau\)范围内的预测网格的采样点占预测网格的所有采样点的比例)和召回率\(R\)(即位于预测值网格点\(\tau\)范围内的真实网格的采样点占真实网格的所有采样点的比例)的调和平均数(\(F1_{\tau}=2PR/(P+R)\))。倒角距离越小越好;其他指标越高越好。
除了正常的一致性之外,这些指标依赖于网格的绝对尺寸。在表1中,我们遵循[68]并以0.57倍的比例缩放;对于所有其他的结果,我们遵循[8]并重新调节,所以GT网格的边界框的最长边缘长度为10。
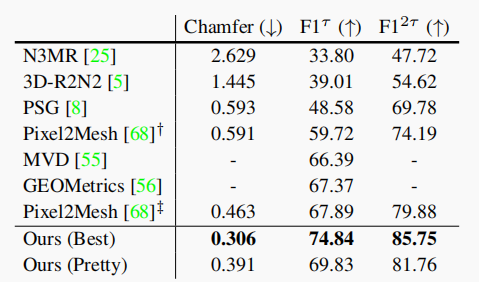
对于[68],†是他们的论文中报道的结果,‡是作者发布的模型结果。
实现细节 我们的主干特征提取器是在ImageNet上预训练的ResNet-50。由于图像描绘的是单个对象,体素分支接收整个conv5_3的特征图, 双线性调整为24×24,然后预测一个48×48×48体素网格。VertAlign操作将来自conv2_3、conv3_4、conv4_6和conv5_3的特征在投影到128维向量之前拼接(concat)起来(这里有疑问,不同特征图的大小不一致,是按照什么原则进行拼接)。网格细分分支有三个阶段,每个阶段由六个图卷积层(128维)组织成三个残差块(residual blocks)。我们在8台Tesla V100 GPU上以\(10^{-4}\)的学习速率,每批次32张图片,使用Adam[27]进行了25个周期的训练。我们将cubify阈值设置为0.2,损失权重设置为\(λ_{voxel} = 1\),\(λ_{cham} = 1\),\(λ_{norm} = 0\),\(λ_{edge} = 0.5\)。
基准 我们比较了以前发表的单幅图像形状预测方法。N3MR[25]是一种弱监督的方法,在没有三维监督下,通过一个可微渲染器调整一个网格。3D-R2N2[5]和MVD[55]输出体素预测。PSG[8]预测点云。附录还与OccNet[41]进行了比较。
Pixel2Mesh[68]通过对初始椭球的变形和细分来预测网格。GEOMetrics[56]用自适应的面孔细分扩展了[68]。两者都经过训练以最小化倒角距离;然而[68]使用预测网格顶点计算,而[56]使用从预测网格中均匀采样的点。我们采用后者,因为它更好地匹配测试时评估。与我们的方法不同,这些方法只能预测属0的连通网格(? Unlike ours, these methods can only predict connected meshes of genus zero.)。
训练处方(recipe)和主干因之前的工作而异。因此,为了与我们的方法进行公平的比较,我们还将与我们的模型的几个消融版本进行比较(详见附录):
- Voxel-Only:我们方法的一个版本,它终止于体素分支的立方网格。
- Pixel2Mesh+:我们重新实现了Pixel2Mesh[68];由于具有更深的主干和更好的训练处方,我们超越了他们的原始模型,并最小化采样点倒角距离而不是顶点位置的损失。
- Sphere-Init:类似于Pixel2Mesh+,但从一个高分辨率的球体网格初始化,执行三个阶段的顶点细化(Refinement)而不细分(subdivision)。
- Ours (light):使用一个更小的非残差网格细化分支,每个阶段有三个图卷积层。我们将在Pix3D上采用这种轻量级设计。
Voxel-Only本质上是我们的方法的一个版本,它省略了网格细分分支,而Pixel2Mesh+和Sphere-Init忽略体素预测分支。
Best vs Pretty 正如之前在[68](第4.1节)中所指出的,形状重建的标准指标与网格质量的相关性不是很好。图5显示,在没有形状调整器的情况下训练的模型,尽管高度退化,但仍提供了度量所偏爱的网格,并且具有不规则大小的面和许多自交点。这些退化网格很难进行纹理处理,而且可能对下游应用没有帮助。

添加\(L_{edge}\)消除这种退化,但输出与GT的标准指标(如倒角距离)结果较差
由于形状调整器(shape regularizers)对网格质量和定量指标都有很强的影响,我们建议只对训练了相同形状调整器的方法进行定量比较。因此,我们训练了我们所有ShapeNet模型的两个版本:一个最好的版本\(λ_{edge}=0\)作为量化性能上限,一个漂亮的版本通过设置\(λ_{edge}=0.5\)达到定量指标和网格质量之间的平衡。
与以往工作的比较 表1比较了我们的漂亮的和最好的模型与之前的工作在单一图像形状预测。我们来自[68]使用的评估方案;使用0.57的网格比例因子和欧几里得距离的平方为\(τ=10^{-4}\)的阈值。对于Pixel2Mesh,我们提供了他们的论文[68]中所报道的性能,以及他们的开源预训练模型的性能。表1显示,我们在很大程度上超过了之前的工作,验证了我们的网格预测器的设计。
消融研究 由于主干网、损耗和形状调整器的不同,与以前的工作进行公平的比较具有挑战性。对于受控评估,我们使用相同的主干和训练处方对变体进行删节,如表2所示。ShapeNet主要由属0的简单对象构成。因此,我们分别对整个测试集和包含一个或多个孔的对象的子集(孔测试集:我们注释了3075个测试集模型,并标记了它们是否包含孔。这导致17%(或534)的模型被标记,详见附录)进行评估。在这个评估中,我们去掉了专门的(ad-hoc)比例因子0.57,并且我们重新调整网格,按照[8]使得ground-truth网格的边界框的最长边长为10。我们比较了开源的Pixel2Mesh模型和我们在这个评估设置中的消融。Pixel2Mesh+(我们对[68]的重新实现)由于改进的训练处方和更深的主干结构,其性能显著优于原始版本。
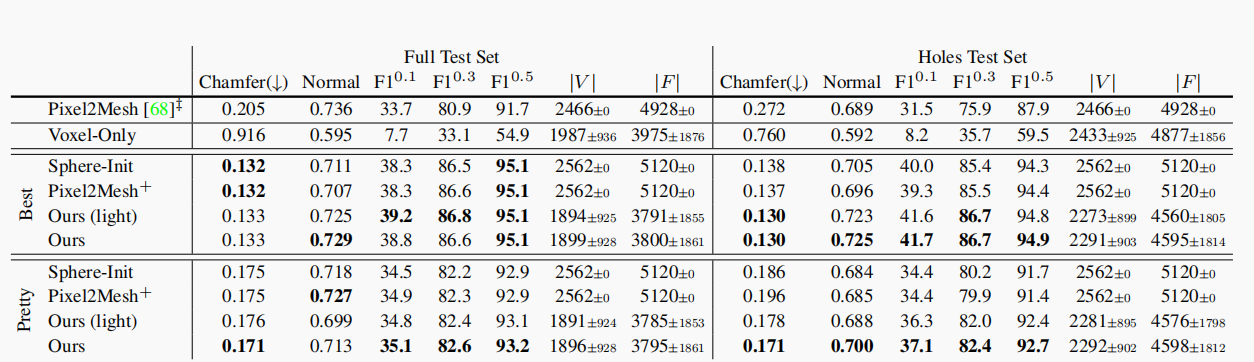
从表2中我们可以得出几点结论:
(a)在完整的测试集上,我们的完整模型和Pixel2Mesh+的表现是一样的。然而,在孔洞测试集,我们的模型占主导地位,因为它可以预测不同的拓扑形状,而Pixel2Mesh+只能对球体进行同态预测,不能对空穴或断开的组件进行建模(见图6)。这种差异在Pix3D(第4.2节)中更为明显,因为它包含了更复杂的形状。
(b)Sphere-Init和Pixel2Mesh+的整体表现类似(都是最好的,也都很漂亮),这表明网格细分对于强量化性能来说可能是不必要的。
(c)更深层次的残差网格细化架构(灵感来自[68])与更轻量的非残差架构表现相同,这激发了我们在Pix3D上使用后者。
(d)与预测网格的方法相比,Voxel-Only 表现得很差,这表明网格预测能够更好地捕捉精细的对象结构。
(e)每个最佳模型都比其对应的漂亮模型表现更好;这是预期的,因为Best是定量性能的上限。

相比之下,我们的方法可以对具有任意拓扑的对象建模。
4.2 Pix3D
现在我们来看看Pix3D[59],它由10069张真实世界的图片和395个独特的3D模型组成。这里的任务是联合检测和预测已知对象类别的三维形状。Pix3D没有提供标准的训练/测试划分(splits),所以我们准备了我们自己的两个划分子集。
我们的第一个划分子集\(S_1\),随机分配7500张图像用于训练,2500张图像用于测试。尽管与ShapeNet相比,独特的对象模型数量较少,但是\(S_1\)同样具有挑战性,因为同一个模型可以以不同的外观(例如颜色、纹理)、不同的方向、不同的光照条件、不同的上下文以及不同的遮挡出现。这是一个与ShapeNet的鲜明对比,因为ShapeNet中对象的背景是空白的。
我们的第二个划分子集\(S_2\)更具挑战性:我们确保训练和测试集中出现的3D模型是不相交的。这种划分的成功不仅需要对\(S_1\)中出现的变化进行泛化,还需要对已知类别的新3D形状进行泛化:例如,一个模型可能在训练时看到厨房椅子,但在测试时必须识别扶手椅。由于Pix3D独特的注释结构,这种划分是可实现的,并且它也提出了有趣的挑战,不论是二维识别和三维形状预测。
评估 我们采用的指标灵感来自那些用于2D识别: \(AP^{box}\),\(AP^{mask}\)和\(AP^{mesh}\)。前两个是在IoU 0.5时,用于评估COCO对象检测和实例分割的标准度量。\(AP^{mesh}\)评估三维形状预测:它是每个类别的precision-recall曲线下的平均面积(如果一个mesh预测的label是正确的,不是重复检测,并且它的\(F1^{0.3}>0.5\),那么它就被认为是一个true-positive)。Pix3D没有详尽的注释,因此,对于评估,我们只考虑使用与GT值 IoU>0.3 的框来预测。这避免了因为模型对未加注释的对象进行了正确的预测时,对它的惩罚。
我们比较了在摄像机坐标系下的预测网格和GT网格。我们的模型假设VertAlign具有已知的摄像机内部特性。Mesh R-CNN可以预测目标在图像平面上的位置,但无法解决z轴方向上的基本尺度/深度模糊问题。因此,在评估过程中,我们将预测的深度范围(\(Z_{near}\)和\(Z_{far}\))与GT形状进行匹配。未来的工作可能会基于形状先验来预测深度范围。
实现细节 我们使用ResNet-50-FPN[34]作为骨干CNN;Box 和 Mask 分支与 Mask R-CNN 相同。体素分支类似于 Mask 分支,但是由于内存限制提供了24×24×24的体素预测,所以池化降低到了12(Mask为14)。我们采用了4.1节中网格细化分支的轻量级设计。我们在8个Tesla V100 GPU(每个GPU两幅图像)上,进行批大小为64,总共12个周期的训练。我们使用具有动量的SGD,在前1K迭代中,线性地将学习率从0.002提高到0.02,然后在8K和10K迭代时以10倍衰减。我们用一个在COCO上预训练的实例分割模型初始化。我们将cubify阈值设置为0.2,将损耗权重设置为\(λ_{voxel}=3.0\),\(λ_{cham}=1.0\),\(λ_{norm}=0.1\)和\(λ_{edge}=0.5\),权重衰减为\(10^{-4}\);检测损耗权值与Mask R-CNN相同。
比较基线 正如第1节所讨论的,我们是第一个在Pix3D上解决野生的联合检测和形状推断的。为了验证我们的方法,我们与Mesh R-CNN的简化版本进行了比较,用Voxel-Only、Pixel2Mesh+和Sphere-Init分支替换了我们的完整网格预测器(见4.1节)。另外,所有的基线都使用相同的架构和训练处方。
表3(顶部)显示了\(S_1\)上的性能。我们观察到:
(a)Mesh R-CNN优于所有的基线,总体上和在大多数类别中,提高了14.9%;Tool和Misc只有很少的测试集实例(分别为11和19),因此它们的AP是有噪声的。
(b)与Sphere-Init相比,Mesh R-CNN对于具有复杂形状的对象,如书架(+23.7%)、桌子(+21.8%)和椅子(+15.0%),表现有较大的收益。
(c)Voxel-Only的性能非常差——由于它是粗预测,这个结果是意料之中的。
表3(底部)显示了更具挑战性的\(S_2\)分割的性能。这里我们看到:
(a)与\(S_1\)相比,2D识别(\(AP^{box}\),\(AP^{mask}\))的整体性能明显下降,这表明在野外识别新的形状比较困难。
(b)Mesh R-CNN在所有类别(工具除外)的形状预测方面都优于所有基线。
(c)由于在训练和测试中模型的形状差异显著,因此所有方法在服装和misc上的绝对性能都很小。
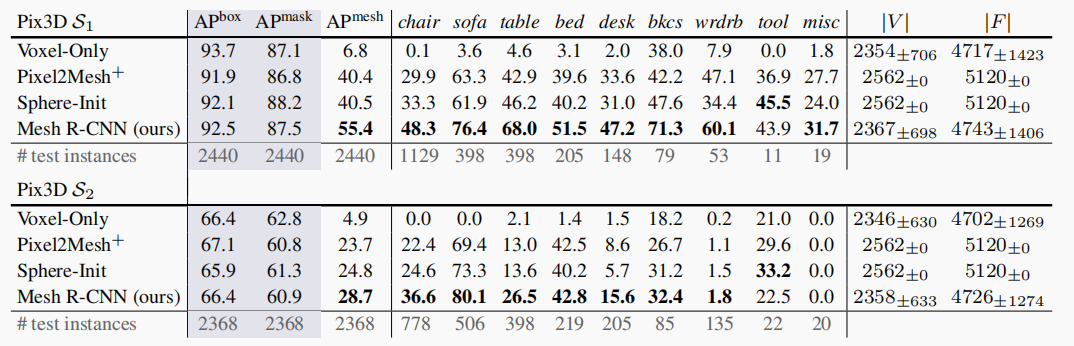
表4比较了COCO和ImageNet上的预训练,并比较了网格预测器的不同架构。COCO与ImageNet初始化显著改善了2D识别(\(AP^{mask}\) 87.5 vs. 85.5)和3D形状预测(\(AP^{mesh}\) 55.4 vs. 52.9)。仅使用一个网格细化阶段,形状预测效果明显下降(\(AP^{mesh}\) 55.4 vs. 52.4)。

在表5中,我们使用groundtruth对象区域来评估我们的训练模型,从而假设完美的边界框检测。形状重构(倒角、法线等)的绝对性能明显低于ShapeNet,表明了Pix3D的难度。与表3(顶部)相比,所有模型的\(AP^{mesh}\)下降了几个百分点,可能是由于缺少上下文的紧密物体区域不适合进行三维形状预测,而在针对不完美区域建议进行训练时,可以增强三维形状预测。

我们还报告了倒角距离、正常稠度和\(F_1\)分数
图7显示了来自Mesh R-CNN的示例预测。我们的方法可以在每张图像中检测多个物体,重建椅子腿等精细的细节,并预测有孔的物体(如书架和桌子)的变化和复杂的网格拓扑。

并预测有洞的对象(如书架和桌子)的变化和复杂的网格拓扑。
讨论
我们提出了一种新的Mesh R-CNN系统,用于联合二维感知和三维形状推断。我们在ShapeNet上验证了我们的方法,并在Pix3D上展示了它的优点。Mesh R-CNN是首次尝试在野外进行三维形状预测。尽管缺乏大量的监督数据,例如COCO,但Mesh R-CNN还是显示了有前途的结果。
Mesh R-CNN 论文翻译(实验部分)的更多相关文章
- [原创]Faster R-CNN论文翻译
Faster R-CNN论文翻译 Faster R-CNN是互怼完了的好基友一起合作出来的巅峰之作,本文翻译的比例比较小,主要因为本paper是前述paper的一个简单改进,方法清晰,想法自然.什 ...
- R-CNN论文翻译
R-CNN论文翻译 Rich feature hierarchies for accurate object detection and semantic segmentation 用于精确物体定位和 ...
- 深度学习论文翻译解析(三):Detecting Text in Natural Image with Connectionist Text Proposal Network
论文标题:Detecting Text in Natural Image with Connectionist Text Proposal Network 论文作者:Zhi Tian , Weilin ...
- 深度学习论文翻译解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application ...
- k[原创]Faster R-CNN论文翻译
物体检测论文翻译系列: 建议从前往后看,这些论文之间具有明显的延续性和递进性. R-CNN SPP-net Fast R-CNN Faster R-CNN Faster R-CNN论文翻译 原文地 ...
- 论文翻译——R-CNN(目标检测开山之作)
R-CNN论文翻译 <Rich feature hierarchies for accurate object detection and semantic segmentation> 用 ...
- 【论文翻译】NIN层论文中英对照翻译--(Network In Network)
[论文翻译]NIN层论文中英对照翻译--(Network In Network) [开始时间]2018.09.27 [完成时间]2018.10.03 [论文翻译]NIN层论文中英对照翻译--(Netw ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 深度学习论文翻译解析(十二):Fast R-CNN
论文标题:Fast R-CNN 论文作者:Ross Girshick 论文地址:https://www.cv-foundation.org/openaccess/content_iccv_2015/p ...
随机推荐
- 知名KMS模拟器的官方发布网址
些知名KMS模拟器的官方发布网址: 本机自激活安装类KMS激活软件,容易在系统升级中被查杀失效,且在软件传播过程中极易被捆绑植入后门.病毒,不推荐尝试. Windows Loaderhttps://f ...
- opencv —— HoughLines、HoughLinesP 霍夫线变换原理(标准霍夫线变换、多尺度霍夫线变换、累积概率霍夫线变换)及直线检测
霍夫线变换的原理 一条直线在图像二维空间可由两个变量表示,有以下两种情况: ① 在笛卡尔坐标系中:可由参数斜率和截距(k,b)表示. ② 在极坐标系中:可由参数极经和极角(r,θ)表示. 对于霍夫线变 ...
- C#画图之饼图
public JsonResult DrawPie() { // 预置颜色 List<Color> colors = new List<Color>() { Color.Fro ...
- Anaconda切换工作目录盘符
先回到C盘符的根目录再切换到其他盘符
- P1967 货车运输【LCA】【生成树】
题目描述 A 国有 nn 座城市,编号从 11 到 nn,城市之间有 mm 条双向道路.每一条道路对车辆都有重量限制,简称限重. 现在有 qq 辆货车在运输货物, 司机们想知道每辆车在不超过车辆限重的 ...
- 基于axios的万能封装
一 . 命名axios.js import axios from 'axios'; export default function ajax(url = '', params = {}, type = ...
- node模块化开发基本知识学习笔记
传统非模块化开发缺点: 1.命名冲突 2.文件依赖 标准的模块化规范: 1.AMD-requirejs 2.CMD-seajs 服务器端模块化规范: 1.CommonJS-Node.js 模块化相关的 ...
- 修改sudoers
使用visudo命令 [root@898f990a8808 etc]# visudo
- SSH远程登录、.sh文件后缀运行、l l命令结果说明、VIM模式切换
目录 SSH远程登录..sh文件后缀运行.l l命令结果说明.VIM模式切换 SSH远程安全登录 .sh文件后缀运行 l l命令结果说明 VIM模式切换 SSH远程登录..sh文件后缀运行.l l命令 ...
- 关于form表单提交数据后不跳转页面+ajax接收返回值的处理
1.前台的form表单建立,注意action.enctype的内容, 2.通过添加一个隐藏的iframe标签使form的target指向iframe来达到不跳转页面的效果,同时需要在js里获取ifra ...