Apriori算法原理总结
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了频繁出现的数据集,那么对于超市,我们可以优化产品的位置摆放,对于电商,我们可以优化商品所在的仓库位置,达到节约成本,增加经济效益的目的。下面我们就对Apriori算法做一个总结。
1. 频繁项集的评估标准
什么样的数据才是频繁项集呢?也许你会说,这还不简单,肉眼一扫,一起出现次数多的数据集就是频繁项集吗!的确,这也没有说错,但是有两个问题,第一是当数据量非常大的时候,我们没法直接肉眼发现频繁项集,这催生了关联规则挖掘的算法,比如Apriori, PrefixSpan, CBA。第二是我们缺乏一个频繁项集的标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我们需要一个评估频繁项集的标准。
常用的频繁项集的评估标准有支持度,置信度和提升度三个。
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:$$Support(X,Y) = P(XY) = \frac{number(XY)}{num(All Samples)}$$
以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:$$Support(X,Y,Z) = P(XYZ) = \frac{number(XYZ)}{num(All Samples)}$$
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为$$Confidence(X \Leftarrow Y) = P(X|Y)=P(XY)/P(Y)$$
也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:$$Confidence(X \Leftarrow YZ) = P(X|YZ)=P(XYZ)/P(YZ)$$
举个例子,在购物数据中,纸巾对应鸡爪的置信度为40%,支持度为1%。则意味着在购物数据中,总共有1%的用户既买鸡爪又买纸巾;同时买鸡爪的用户中有40%的用户购买纸巾。
提升度表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比,即:$$Lift(X \Leftarrow Y) = P(X|Y)/P(X) = Confidence(X \Leftarrow Y) / P(X)$$
提升度体先了X和Y之间的关联关系, 关联度高则提升度小,一个特殊的情况,如果X和Y独立,则有$Lift(X \Leftarrow Y) = 1$, 达到最大,因为此时$P(X|Y) = P(X)$。
一般来说,要选择一个数据集合中的频繁数据集,则需要自定义评估标准。最常用的评估标准是用自定义的支持度,或者是自定义支持度和置信度的一个组合。
2. Apriori算法思想
对于Apriori算法,我们使用支持度来作为我们判断频繁项集的标准。Apriori算法的目标是找到最大的K项频繁集。这里有两层意思,首先,我们要找到符合支持度标准的频繁集。但是这样的频繁集可能有很多。第二层意思就是我们要找到最大个数的频繁集。比如我们找到符合支持度的频繁集AB和ABE,那么我们会抛弃AB,只保留ABE,因为AB是2项频繁集,而ABE是3项频繁集。那么具体的,Apriori算法是如何做到挖掘K项频繁集的呢?
Apriori算法采用了迭代的方法,先搜索出候选1项集及对应的支持度,剪枝去掉低于支持度的1项集,得到频繁1项集。然后对剩下的频繁1项集进行连接,得到候选的频繁2项集,筛选去掉低于支持度的候选频繁2项集,得到真正的频繁二项集,以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果。
可见这个算法还是很简洁的,第i次的迭代过程包括扫描计算候选频繁i项集的支持度,剪枝得到真正频繁i项集和连接生成候选频繁i+1项集三步。
我们下面这个简单的例子看看:
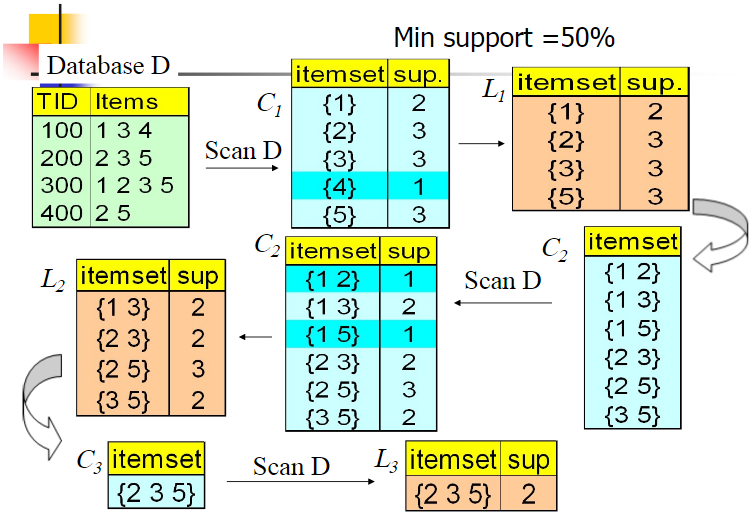
我们的数据集D有4条记录,分别是134,235,1235和25。现在我们用Apriori算法来寻找频繁k项集,最小支持度设置为50%。首先我们生成候选频繁1项集,包括我们所有的5个数据并计算5个数据的支持度,计算完毕后我们进行剪枝,数据4由于支持度只有25%被剪掉。我们最终的频繁1项集为1235,现在我们链接生成候选频繁2项集,包括12,13,15,23,25,35共6组。此时我们的第一轮迭代结束。
进入第二轮迭代,我们扫描数据集计算候选频繁2项集的支持度,接着进行剪枝,由于12和15的支持度只有25%而被筛除,得到真正的频繁2项集,包括13,23,25,35。现在我们链接生成候选频繁3项集,123, 125,135和235共4组,这部分图中没有画出。通过计算候选频繁3项集的支持度,我们发现123,125和135的支持度均为25%,因此接着被剪枝,最终得到的真正频繁3项集为235一组。由于此时我们无法再进行数据连接,进而得到候选频繁4项集,最终的结果即为频繁3三项集235。
3. Aprior算法流程
下面我们对Aprior算法流程做一个总结。
输入:数据集合D,支持度阈值$\alpha$
输出:最大的频繁k项集
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁1项集为空集。
2)挖掘频繁k项集
a) 扫描数据计算候选频繁k项集的支持度
b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
c) 基于频繁k项集,连接生成候选频繁k+1项集。
3) 令k=k+1,转入步骤2。
从算法的步骤可以看出,Aprior算法每轮迭代都要扫描数据集,因此在数据集很大,数据种类很多的时候,算法效率很低。
4. Aprior算法总结
Aprior算法是一个非常经典的频繁项集的挖掘算法,很多算法都是基于Aprior算法而产生的,包括FP-Tree,GSP, CBA等。这些算法利用了Aprior算法的思想,但是对算法做了改进,数据挖掘效率更好一些,因此现在一般很少直接用Aprior算法来挖掘数据了,但是理解Aprior算法是理解其它Aprior类算法的前提,同时算法本身也不复杂,因此值得好好研究一番。
不过scikit-learn中并没有频繁集挖掘相关的算法类库,这不得不说是一个遗憾,不知道后面的版本会不会加上。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
Apriori算法原理总结的更多相关文章
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- Apriori算法实现
Apriori算法原理:http://blog.csdn.net/kingzone_2008/article/details/8183768 import java.util.HashMap; imp ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析
机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析 关键字:Apriori.关联规则挖掘.频繁项集作者:米仓山下时间:2018 ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售.但是这个奇怪的举措却使尿布和啤酒的销量双双增加了.这不是一个笑话,而是发生在美国沃尔玛 ...
- Apriori 关联分析算法原理分析与代码实现
前言 想必大家都听过数据挖掘领域那个经典的故事 - "啤酒与尿布" 的故事. 那么,具体是怎么从海量销售信息中挖掘出啤酒和尿布之间的关系呢? 这就是关联分析所要完成的任务了. 本文 ...
随机推荐
- Android网络开发之OkHttp--基本用法POST
1.OkHttp框架使用了OkIo框架,不要忘记下OkIo.jar 2.通过POST访问网络,和通过GET访问网络基本相同,多了设置请求参数的过程.主要分为五步: (1).声明并实例化一个OkHttp ...
- Android编程中的实用快捷键
作为一个优秀的程序员,不但要能开发出漂亮的软件,也要能熟练掌握编程的技巧,包括IDE的快捷键使用.比如linux 下的VI编辑器,对于不熟练快捷键的人来说就是一个噩梦,但一旦你熟练了VI的快捷键,VI ...
- java中堆和堆栈的区别
java中堆和堆栈的区别(一) 1.栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方.与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆. 2. 栈的优势是,存取 ...
- jquery.elevateZoom实现仿淘宝看图片,一张小的,一张大用于鼠标经过时候显示
实现这个效果你需要准备两张图片,一张小的,一张大用于鼠标经过时候显示.然后我们只要为img标签添加data-zoom-image属性,其值为大图的地址,最后在javascript中选择该图片调用ele ...
- IBATIS事务处理 - - 博客频道 - CSDN.NET
body { font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI ...
- mysql连接字符集default
用mysql客户端工具输入中文数据报错,或乱码问题解决 数据库字符集为latin1时 用mysql工具,然后选择连接>l连接属性>高级>字符集选择default
- Eclipse PHP 代码无法自动提示函数
在 linux 系统的 workwpace 里按 ctrl+h,显示出隐藏的文件,找到 .metadata 文件夹,然后将该文件夹删除,再重启 Eclipse 即可.其实它会将之前 Eclipse 连 ...
- UITableView回调和table相关成员方法详解
http://blog.csdn.net/kingsley_cxz/article/details/9123959 1.UITableView的datasource实现: //回调获取每个sectio ...
- HCSR04超声波传感器驱动
HC_SR04是一款使用较为广泛的超声波测距模块,模块图如下 该模块具有四个引脚,分别为VCC GND TRIG ECHO,其中VCC GND为供电脚 TRIG为测距触发引脚,ECHO为测距输入引脚 ...
- 关于ios 推送功能的终极解决
刚刚做了一个使用推送功能的应用 遇到了一些问题整的很郁闷 搞了两天总算是弄明白了 特此分享给大家 本帖 主要是针对产品发布版本的一些问题 综合了网上一些资料根据自己实践写的 不过测试也可以看看 首先要 ...