Python爬虫学习==>第十一章:分析Ajax请求-抓取今日头条信息
学习目的:
解决AJAX请求的爬虫,网页解析库的学习,MongoDB的简单应用
正式步骤
Step1:流程分析
- 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果;
- 抓取页面详情内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息;
- 下载图片并保存数据库:将图片下载到本地,把页面信息及图片url保存至MongoDB;
- 开启循环及多线程:对多页面内容遍历,开启多线程并提高抓取效率。
Step2:实例分析
1. 打开今日头条搜索页,搜索“中超”,查看页面的请求方法为:GET
2. 创建一个Python文件:spider_ajax.py
3.网站url信息获取
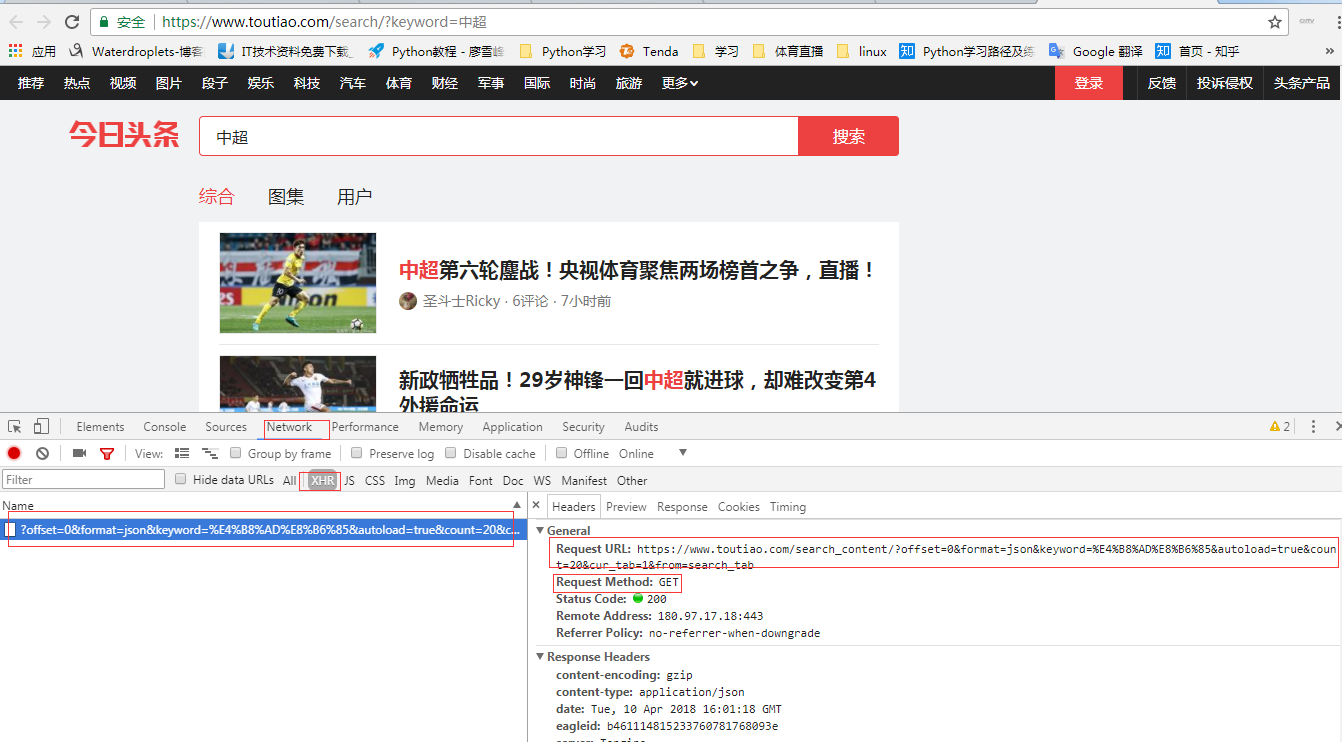
4. 打印抓取的文章超链接和抓取的html内容
# -*- coding:utf-8 -*-
import json
from urllib.parse import urlencode
from requests.exceptions import RequestException import requests
def get_page_html(offset,keyword):
data = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'',
'cur_tab':1
}
# urlencode把字典对象自动转化为url参数,
# 快速导入,请选中以后,按alt+enter
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求索引页失败')
return None def parse_page_index(html):
#因为html打印出来是json字符串格式,json.loads作用是将已编码的 JSON 字符串解码为 Python 对象
# json.dumps作用是将 Python 对象编码成 JSON 字符串
#参考http://www.runoob.com/python/python-json.html
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') def main():
html = get_page_html(0,'中超')
#打印抓取的文章详细内容的url
for url in parse_page_index(html):
print(url)
#打印获取页面内容
print(html) if __name__ == '__main__':
main()
后面的内容因为爬虫被封,很多信息获取不到,暂时不会,以后再补全这节内容
学习总结:
想爬取商业的门户网站,感觉一脸懵逼
Python爬虫学习==>第十一章:分析Ajax请求-抓取今日头条信息的更多相关文章
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
- 通过分析Ajax请求 抓取今日头条街拍图集
代码: import os import re import json import time from hashlib import md5 from multiprocessing import ...
- python3爬虫-分析Ajax,抓取今日头条街拍美图
# coding=utf-8 from urllib.parse import urlencode import requests from requests.exceptions import Re ...
- python爬虫---实现项目(二) 分析Ajax请求抓取数据
这次我们来继续深入爬虫数据,有些网页通过请求的html代码不能直接拿到数据,我们所需的数据是通过ajax渲染到页面上去的,这次我们来看看如何分析ajax 我们这次所使用的网络库还是上一节的Reques ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 分析Ajax来爬取今日头条街拍美图并保存到MongDB
前提:.需要安装MongDB 注:因今日投票网页发生变更,如下代码不保证能正常使用 #!/usr/bin/env python #-*- coding: utf-8 -*- import json i ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
随机推荐
- AIDE入侵检测系统
一.AIDE简介 • AIDE(Advanced Intrusion Detection Environment)• 高级入侵检测环境)是一个入侵检测工具,主要用途是检查文件的完整性,审计计算机上的那 ...
- MySQL字符集或字符序
字符集基础 字符集:数据库中的字符集包含两层含义 各种文字和符号的集合,包括各国家文字,标点符号,图形符号,数字等. 字符的编码方式,即二进制数据与字符的映射规则: 字符集分类: ASCI ...
- hive的事物性 transaction manager
create table lk3 (id string,nname string,grade int,goldUser int); insert into lk3 values (,, ), (,, ...
- guava的一些用法
package guavaTest; import com.google.common.base.CharMatcher; import com.google.common.base.Joiner; ...
- [人物存档]【AI少女】【捏脸数据】活泼少女
AISChaF_20191028022750507.png
- vue使用ajax
1.Vue的Ajax基本用法 在vue中用Ajax需要用到vue.js和vue-resource.js; vue-resource.js的下载地址:https://cdn.staticfile.org ...
- ACM-ICPC 2018 沈阳赛区网络预赛 G Spare Tire (素因子分解+容斥)
. 样例输入复制 4 4 样例输出复制 14 #include<bits/stdc++.h> using namespace std; typedef long long ll; cons ...
- Codeforces Round #567 (Div. 2) E2 A Story of One Country (Hard)
https://codeforces.com/contest/1181/problem/E2 想到了划分的方法跟题解一样,但是没理清楚复杂度,很难受. 看了题解觉得很有道理,还是自己太菜了. 然后直接 ...
- Inter IPP 处理图像数据的方法
Inter IPP没有读取图片和保存图片的函数,需要结合opencv完成这个功能. opencv读到图片以后逐个像素点赋值给IPP显然是不可取的,方法如下: int main(int argc, ch ...
- win7安装Elasticsearch和Elasticsearch-Head插件
1.环境搭建 1)Java环境搭建可以参考相关的资料,这里不做详细介绍 2)nodejs环境搭建 到官方网站下载相应的zip包:https://nodejs.org/dist/v8.9.1/node- ...