从零开始学会GAN 0:第一部分 介绍生成式深度学习(连载中)
本书的前四章旨在介绍开始构建生成式深度学习模型所需的核心技术。
在第1章中,我们将首先对生成式建模领域进行广泛的研究,并从概率的角度考虑我们试图解决的问题类型。然后,我们将探讨我们的基本概率生成模型的第一个例子,并分析为什么随着生成式任务的复杂性增长,可能需要部署深度学习技术。
第2章提供了开始构建更复杂的生成模型所需的深度学习工具和技术的指南。这旨在成为深度学习的实用指南,而不是对该领域的理论分析。特别是,我将介绍Keras,一个构建神经网络的框架,可用于构建和训练已在文献中发表的一些最先进的深度神经网络架构。
在第3章中,我们将看看我们的第一个生成式深度学习模型,即变分自动编码器。这种强大的技术不仅可以生成逼真的面部,还可以改变现有的图像 - 例如,通过添加微笑或改变某人头发的颜色。
第4章探讨了近年来最成功的生成式建模技术之一,生成对抗网络GAN。这种构建生成建模问题的优雅框架是大多数最先进的生成模型背后的基础引擎。我们将看到它经过微调和调整的方式,以不断推动生成建模能够实现的界限。
第一章 生成建模
什么是生成式建模?
生成式模型可以大致定义如下:
生成式模型通过概率模型描述了如何生成数据。 通过从该模型中抽样,我们能够生成新数据。
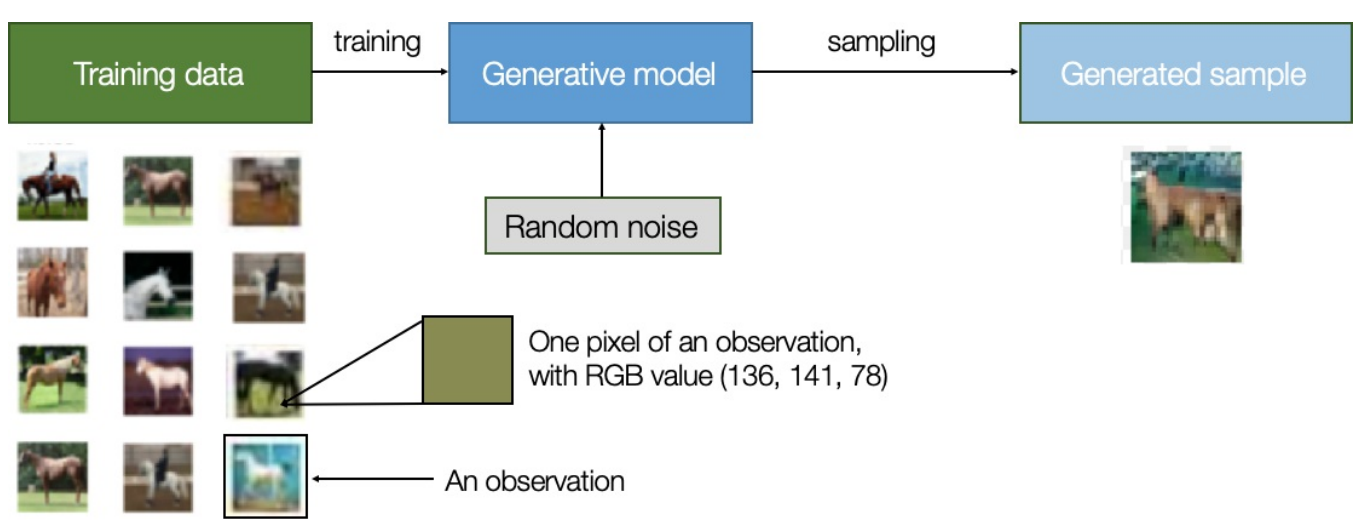
图1-1 生成式建模的过程
每个观测包括许多特征 - 对于图像生成问题,这些特征通常是各个像素值。 我们的目标是构建一个可以生成新特征集合的模型,这些特征集合看起来好像是使用与原始数据相同的规则创建的。从概念上讲,图像生成来说是一项非常困难的任务,考虑到对单个像素值进行放置有大量不同的方式,相对微小的这种放置构成了我们试图模拟的实体图像。
生成性与判别性建模
为了真正理解生成建模的目的是什么以及为什么这很重要,将它与其对应物进行比较是有用的-判别模型。如果你学过机器学习,那么你将面临的大多数问题都很可能是判别性的。为了理解这些差异,让我们看一个例子。
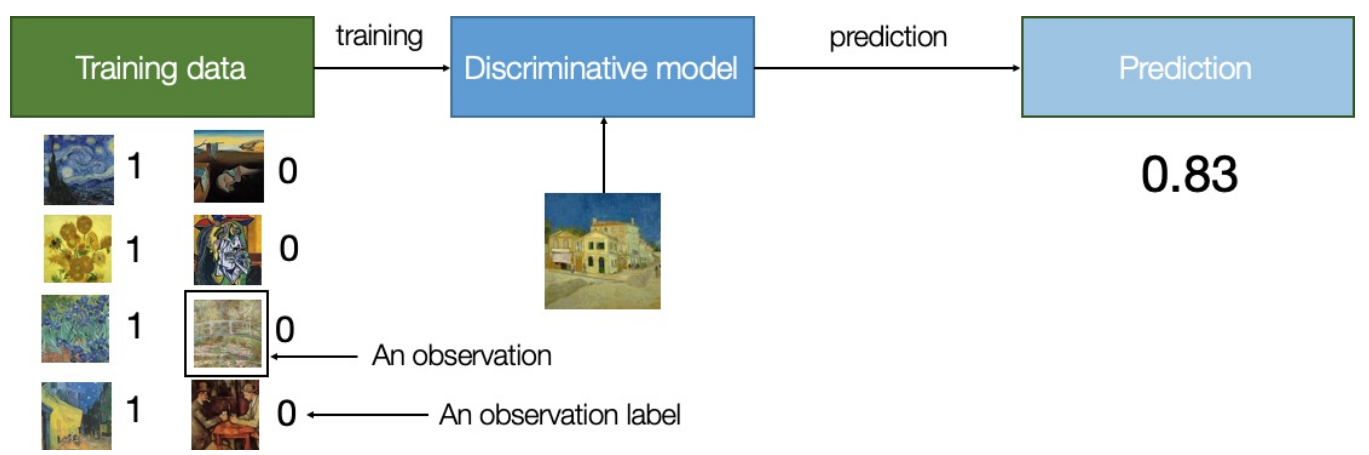
图1-2 判别建模的过程
判别建模是估计 p(y|x) 给定观测x其标签是y的概率
生成建模是估计 p(x) 观察观测x的概率
如果数据集是有标签的,我们还可以构建一个生成模型来估计分布 p(x|y)
换句话说,判别建模试图估计观测x属于类别y的概率。 生成建模不关心标签。 相反,它试图估计了解观测的概率。
鉴于卫星图像,政府国防官员只会关心它包含敌方单位的概率,而不是这个特定图像应该出现的概率。
- 客户关系经理只会想知道收到的电子邮件的观点是积极的还是消极的,并且在生成模型中没有多少用处,因为生成模型可能会输出尚不存在的客户电子邮件的示例。
- 医生希望知道给定视网膜图像含有青光眼的可能性,而不是能够获得可以生成新颖的眼睛后部图像的模型。
由于企业所需的大多数解决方案都属于判别建模领域,因此机器学习即服务(MLaaS,Machine-Learning-as-a-Service)工具的数量不断增加,这些工具旨在将工业中的判别建模商品化,
通过在很大程度上自动化的生产,验证和监视过程,这些过程几乎是所有判别建模任务所共有的。
特别是,媒体对生成建模项目的关注度越来越高,例如NVIDIA的StyleGAN,它能够创建人脸的超逼真图像,以及OpenAI的GPT-2语言模型,它能够通过简短的介绍段落完成文本的传递。
图1-3显示了自2014年以来3在面部图像生成方面取得的惊人进展。游戏设计和电影摄影等行业有明显的积极应用,自动音乐生成的改进也必将在这些领域内引起共鸣。 我们是否有一天会阅读由生成模型撰写的新闻文章或小说还有待观察,但最近这方面的进展是惊人的,毫无疑问,某一天可能就是这样。 虽然令人兴奋,但这也引发了关于互联网上虚假内容激增的道德问题,这意味着可能变得越来越难以信任我们通过公共沟通渠道看到和阅读的内容。

图1-3 使用生成建模的面部生成在过去四年中得到了显着改善 4
除了生成建模的实际应用(其中许多尚未被发现)之外,有三个更深层次的原因可以解释为什么生成建模可以被认为是解锁更复杂的人工智能形式的关键,这超出了判别建模可以独自实现的范畴。
首先,纯粹从理论的角度来看,我们不应满足于只能在数据分类方面表现出色,而且还应该首先寻求更全面地了解数据的生成方式。 这无疑是一个需要解决的难题,这是由于可行输出空间的维度高,同时创造的能被归类为数据集的样本数量相对较少。然而,正如我们将要看到的,许多驱动判别建模发展的相同技术,例如深度学习,也可以被生成模型利用。
其次,生成建模很可能是推动机器学习其他领域未来发展的核心,例如强化学习(通过试错来教agents以优化环境目标的研究)。例如,我们可以使用强化学习来训练机器人在特定地形上行走。一般方法是建立地形的计算机模拟,然后运行许多实验,其中agents尝试不同的策略。随着时间的推移,agents将了解哪些策略比其他策略更成功,因此逐渐改进。这种方法的一个典型问题是环境的物理特性通常非常复杂,需要在每个时间步长计算,以便将信息反馈给agents以决定其下一步行动。但是,如果agents能够通过生成模型模拟其环境,则不需要在计算机模拟或现实世界中测试策略,而是可以在其自己的想象环境中学习。在第8章中,我们将看到这个想法的实施,通过允许它直接从其自己的幻觉环境中学习,训练汽车尽可能快地在轨道上行驶。
最后,如果我们要真实地说我们已经建立了一种能够获得与人类相似的智能机器,那么生成建模肯定是解决方案的一部分。自然界中最好的生成模型之一就是阅读本书的人。花点时间考虑一下你是一个令人难以置信的生成模型。你可以闭上眼睛,从任何可能的角度想象大象会是什么样子。你可以想象你最喜欢的电视节目有许多看似合理的不同结局,你可以通过在脑海中处理各种未来并相应地采取行动来计划你的一周。目前的神经科学理论表明,我们对现实的感知并不是一个运作在我们的感官输入上以产生我们正在经历的预测,高度复杂的判别模型,而是一个受过训练的生成模型。从出生到产生我们周围环境的模拟,准确地匹配未来。有些理论甚至认为这种生成模型的输出是我们直接认为的现实。很明显,深入了解我们如何建立机器以获得这种能力将是我们对大脑运作和一般人工智能的持续理解的关键。
考虑到这一点,让我们开始进入令人兴奋的生成建模世界。 首先,我们将看一下最简单的生成模型示例和一些有助于我们完成本书后面将要遇到的更复杂架构的想法。
参考文献:
从零开始学会GAN 0:第一部分 介绍生成式深度学习(连载中)的更多相关文章
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 4.keras实现-->生成式深度学习之用GAN生成图像
生成式对抗网络(GAN,generative adversarial network)由Goodfellow等人于2014年提出,它可以替代VAE来学习图像的潜在空间.它能够迫使生成图像与真实图像在统 ...
- 本文可能是国内第一篇介绍C/4HANA Foundation的中文博客
SAP C/4HANA从去年发布已经过去了一年多的时间,C/4HANA的从业者,对于这五朵云里包含的产品集,想必都有了一些了解. Jerry注意到,SAP C/4HANA Foundation这个概念 ...
- 4.keras实现-->生成式深度学习之DeepDream
DeepDream是一种艺术性的图像修改技术,它用到了卷积神经网络学到的表示,DeepDream由Google于2015年发布.这个算法与卷积神经网络过滤器可视化技术几乎相同,都是反向运行一个卷积神经 ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
- 【深度学习与TensorFlow 2.0】入门篇
注:因为毕业论文需要用到相关知识,借着 TF 2.0 发布的时机,重新捡起深度学习.在此,也推荐一下优达学城与 TensorFlow 合作发布的TF 2.0入门课程,下面的例子就来自该课程. 原文发布 ...
- ArXiv最受欢迎开源深度学习框架榜单:TensorFlow第一,PyTorch第四
[导读]Kears作者François Chollet刚刚在Twitter贴出最近三个月在arXiv提到的深度学习框架,TensorFlow不出意外排名第一,Keras排名第二.随后是Caffe.Py ...
- Gradle2.0用户指南翻译——第一章. 介绍
翻译项目请关注Github上的地址:https://github.com/msdx/gradledoc本文翻译所在分支:https://github.com/msdx/gradledoc/tree/2 ...
随机推荐
- zabbix3.0升级到4.0
升级步鄹: 3.0->3.2 1.停服务 service zabbix-server stop 2.备份配置文件 #cp /etc/zabbix/zabbix_server.conf /data ...
- python3 速查参考- python基础 9 -> MySQL基础概念、数据库create、alter、insert、update、delete、select等基础命令
前置步骤: 下载一个绿色版的mysql数据库客户端连接工具 :http://wosn.net/821.html mysql平台为win7(以后会有CentOS上的) 学习目的: 掌握数据库的基本概念, ...
- window 安装指定的node版本
有时候不同的项目需要不同的node版本,window切换node版本命令很不管用,甚至需要卸载后重新装,同事分享了一下他的做法,很便利. 1.打开node官网 https://nodejs.org/e ...
- USACO 1.2 Friday the Thirteenth
注意闰月的部分细节很多. /* ID:Starry21 LANG:C++ TASK:friday */ #include<iostream> #include<string> ...
- springboot使用elasticsearch的客户端操作eslaticsearch
一 ES客户端 ES提供多种不同的客户端: 1.TransportClient ES提供的传统客户端,官方计划8.0版本删除此客户端. 2.RestClient RestClient是官方推荐使用的 ...
- python多进程单线程+协程实现高并发
并发:看起来像同时运行就是并发 并行:同一时间同时被执行叫做并行,最大并行数就是CPU核数 协程不是实实在在存在的物理基础和操作系统运行逻辑,只是程序员从代码层面避开了系统对遇到IO的程序会切走CPU ...
- Java中简单测试FastDFS的文件上传
pom.xml文件内容如下: <dependencies> <!-- fastdfs --> <dependency> <groupId>org.cso ...
- B-tree 和 B+tree过程
https://blog.csdn.net/baiyan3212/article/details/91043695 https://www.jianshu.com/p/0371c9569736
- 【转帖】Linux图形用户界面:KDE与GNOME的由来
Linux图形用户界面:KDE与GNOME的由来 置顶 2018年08月11日 15:51:25 hwpipixia 阅读数 4778 https://blog.csdn.net/u013895853 ...
- git合并时冲突<<<<<<< HEAD
<<<<<<< HEAD 本地代码 ======= 拉下来的代码 >>>>>>>