图解Python 【第二篇】:Python基础2
本节内容一览图
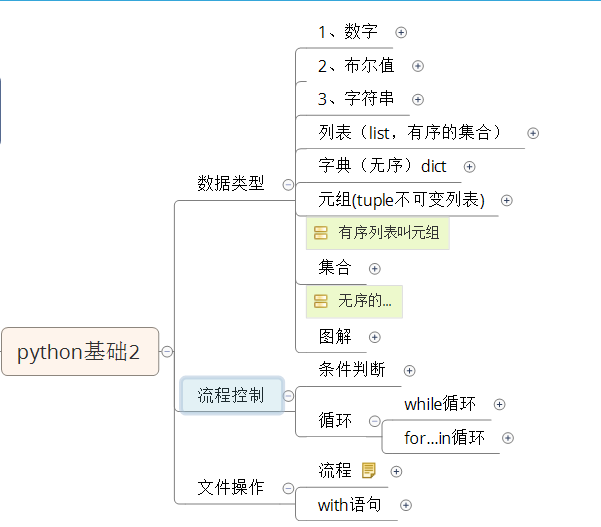
一、数据类型
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
3、字符串
"hello world"
字符串是什么

|
1
2
3
4
|
name = "alex"print "i am %s " % name #输出: i am alex |
PS: 字符串是 %s;整数 %d;浮点数%f
- 常用方法:
- name.capitalize() 首字母大写
- name.casefold() 大写全部变小写
- name.center(50,"-") 输出 '---------------------Alex Li----------------------'
- name.count('lex') 统计 lex出现次数
- name.encode() 将字符串编码成bytes格式
- name.endswith("Li") 判断字符串是否以 Li结尾
- "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格
- name.find('A') 查找A,找到返回其索引, 找不到返回-1
- format :
- >>> msg = "my name is {}, and age is {}"
- >>> msg.format("alex",22)
- 'my name is alex, and age is 22'
- >>> msg = "my name is {1}, and age is {0}"
- >>> msg.format("alex",22)
- 'my name is 22, and age is alex'
- >>> msg = "my name is {name}, and age is {age}"
- >>> msg.format(age=22,name="ale")
- 'my name is ale, and age is 22'
- format_map
- >>> msg.format_map({'name':'alex','age':22})
- 'my name is alex, and age is 22'
- msg.index('a') 返回a所在字符串的索引
- '9aA'.isalnum() True
- ''.isdigit() 是否整数
- name.isnumeric
- name.isprintable
- name.isspace
- name.istitle
- name.isupper
- "|".join(['alex','jack','rain'])
- 'alex|jack|rain'
- maketrans
- >>> intab = "aeiou" #This is the string having actual characters.
- >>> outtab = "" #This is the string having corresponding mapping character
- >>> trantab = str.maketrans(intab, outtab)
- >>>
- >>> str = "this is string example....wow!!!"
- >>> str.translate(trantab)
- 'th3s 3s str3ng 2x1mpl2....w4w!!!'
- msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}')
- >>> "alex li, chinese name is lijie".replace("li","LI",1)
- 'alex LI, chinese name is lijie'
- msg.swapcase 大小写互换
- >>> msg.zfill(40)
- '00000my name is {name}, and age is {age}'
- >>> n4.ljust(40,"-")
- 'Hello 2orld-----------------------------'
- >>> n4.rjust(40,"-")
- '-----------------------------Hello 2orld'
- >>> b="ddefdsdff_哈哈"
- >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
- True

python有四种常用的数据结构:一览表如图

注意: 集合是指包含一组元素的数据结构,我们已经介绍的包括:
1. 有序集合:list,tuple,str和unicode;
2. 无序集合:set
3. 无序集合并且具有 key-value 对:dict
下面分别介绍用法:
4.列表(list)操作
列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
列表是有序的集合
列表总结:

基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
定义列表
names = ['Alex',"Tenglan",'Eric']切片:取多个元素
- >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
- >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4
- ['Tenglan', 'Eric', 'Rain']
- >>> names[1:-1] #取下标1至-1的值,不包括-1
- ['Tenglan', 'Eric', 'Rain', 'Tom']
- >>> names[0:3]
- ['Alex', 'Tenglan', 'Eric']
- >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样
- ['Alex', 'Tenglan', 'Eric']
- >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写
- ['Rain', 'Tom', 'Amy']
- >>> names[3:-1] #这样-1就不会被包含了
- ['Rain', 'Tom']
- >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个
- ['Alex', 'Eric', 'Tom']
- >>> names[::2] #和上句效果一样
- ['Alex', 'Eric', 'Tom']
追加
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy']
- >>> names.append("我是新来的")
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
append()总是把新的元素添加到 list 的尾部
插入
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.insert(2,"强行从Eric前面插入")
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.insert(5,"从eric后面插入试试新姿势")
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
- >>> names[2] = "该换人了"
- >>> names
- ['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
删除
- >>> del names[2]
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
- >>> del names[4]
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>>
- >>> names.remove("Eric") #删除指定元素
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.pop() #删除列表最后一个值
- '我是新来的'
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
扩展
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
- >>> b = [1,2,3]
- >>> names.extend(b)
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
拷贝
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
- >>> name_copy = names.copy()
- >>> name_copy
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计
- >>> names
- ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
- >>> names.count("Amy")
- 2
排序&翻转
- >>> names
- ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
- >>> names.sort() #排序
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦
- >>> names[-3] = ''
- >>> names[-2] = ''
- >>> names[-1] = ''
- >>> names
- ['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '', '', '']
- >>> names.sort()
- >>> names
- ['', '', '', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom']
- >>> names.reverse() #反转
- >>> names
- ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '', '', '']
获取下标
- >>> names
- ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '', '', '']
- >>> names.index("Amy")
- 2 #只返回找到的第一个下标
5、元组-tuple
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
创建tuple和创建list唯一不同之处是用( )替代了[ ]。
语法
|
1
|
names = ("alex","jack","eric") |
它只有2个方法,一个是count,一个是index
Python在打印单元素tuple时,也自动添加了一个“,”,为了更明确地告诉你这是一个tuple
多元素 tuple 加不加这个额外的“,”效果是一样的
注意:tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
6、字典(dict)操作
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
特点:
1,dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样
2,dict的第二个特点就是存储的key-value序对是没有顺序的!
3,dict的第三个特点是作为 key 的元素必须不可变
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。


定义一个字典
- info = {
- 'stu1101': "TengLan Wu",
- 'stu1102': "LongZe Luola",
- 'stu1103': "XiaoZe Maliya",
- }
增加
- >>> info["stu1104"] = "苍井空"
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
删除
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
- >>> info.pop("stu1101") #标准删除姿势
- '武藤兰'
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>> del info['stu1103'] #换个姿势删除
- >>> info
- {'stu1102': 'LongZe Luola'}
- >>>
- >>>
- >>>
- >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除
- >>> info.popitem()
- ('stu1102', 'LongZe Luola')
- >>> info
- {'stu1103': 'XiaoZe Maliya'}
修改
- >>> info['stu1101'] = "武藤兰"
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
查找
- >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>>
- >>> "stu1102" in info #标准用法
- True
- >>> info.get("stu1102") #获取
- 'LongZe Luola'
- >>> info["stu1102"] #同上,但是看下面
- 'LongZe Luola'
- >>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- KeyError: 'stu1105'
循环dict
- #方法1
- for key in info:
- print(key,info[key])
- #方法2
- for k,v in info.items(): #会先把dict转成list,数据里大时莫用
- print(k,v)

py3 已经取消itervalues
7.集合操作
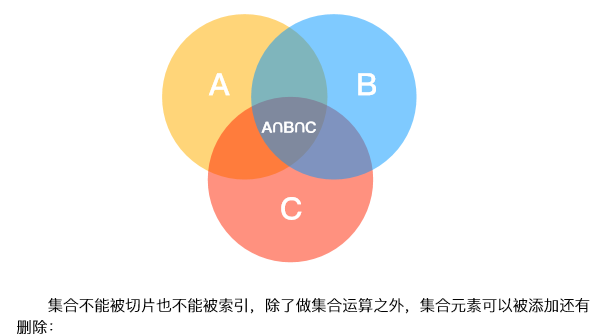
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
set存储的元素和dict的key类似,必须是不变对象,因此,任何可变对象是不能放入set中的。
最后,set存储的元素也是没有顺序的。
常用操作:
- s = set([3,5,9,10]) #创建一个数值集合
- t = set("Hello") #创建一个唯一字符的集合
- a = t | s # t 和 s的并集
- b = t & s # t 和 s的交集
- c = t – s # 求差集(项在t中,但不在s中)
- d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
- 基本操作:
- t.add('x') # 添加一项
- s.update([10,37,42]) # 在s中添加多项
- 使用remove()可以删除一项:
- t.remove('H')
- len(s)
- set 的长度
- x in s
- 测试 x 是否是 s 的成员
- x not in s
- 测试 x 是否不是 s 的成员
- s.issubset(t)
- s <= t
- 测试是否 s 中的每一个元素都在 t 中
- s.issuperset(t)
- s >= t
- 测试是否 t 中的每一个元素都在 s 中
- s.union(t)
- s | t
- 返回一个新的 set 包含 s 和 t 中的每一个元素
- s.intersection(t)
- s & t
- 返回一个新的 set 包含 s 和 t 中的公共元素
- s.difference(t)
- s - t
- 返回一个新的 set 包含 s 中有但是 t 中没有的元素
- s.symmetric_difference(t)
- s ^ t
- 返回一个新的 set 包含 s 和 t 中不重复的元素
- s.copy()
- 返回 set “s”的一个浅复制
二、流程控制
动态讲解
http://codingpy.com/article/10-gifs-to-understand-some-programming-concepts/
一览表:
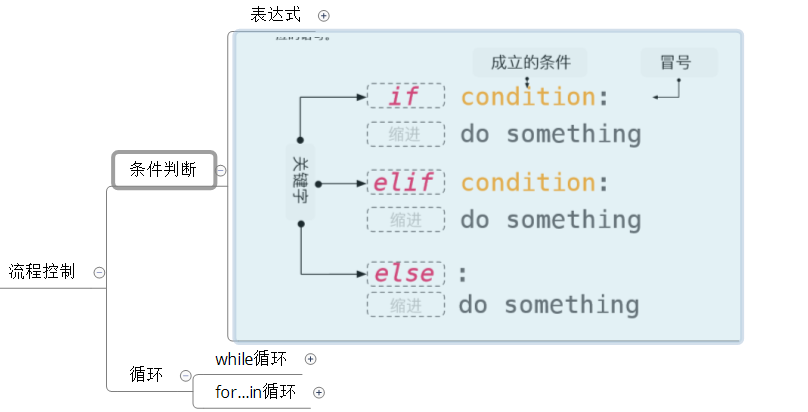
1.条件判断
表达式:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>
场景一、用户登陆验证
- # 提示输入用户名和密码
- # 验证用户名和密码
- # 如果错误,则输出用户名或密码错误
- # 如果成功,则输出 欢迎,XXX!
- #!/usr/bin/env python
- # -*- coding: encoding -*-
- import getpass
- name = raw_input('请输入用户名:')
- pwd = getpass.getpass('请输入密码:')
- if name == "alex" and pwd == "cmd":
- print("欢迎,alex!")
- else:
- print("用户名和密码错误")
基本结构:

例子分析:
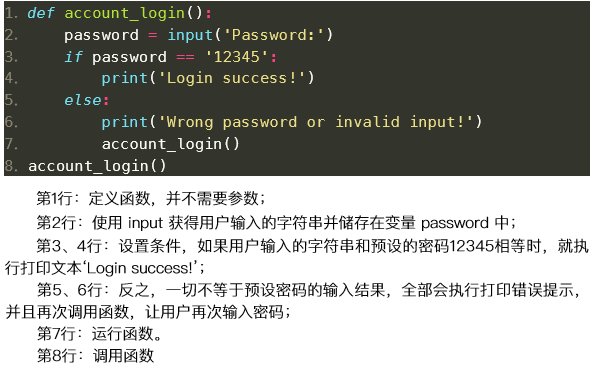
多条件判断:


2、循环
for循环

例子:
- #_*_coding:utf-8_*_
- __author__ = 'Alex Li'
- for i in range(10):
- print("loop:", i )
while loop循环


- count = 0
- while True:
- print("你是风儿我是沙,缠缠绵绵到天涯...",count)
- count +=1
1.基本循环
- while 条件:
- # 循环体
- # 如果条件为真,那么循环体则执行
- # 如果条件为假,那么循环体不执行
2、break
break用于退出所有循环
- while True:
- print ""
- break
- print ""
3、continue
continue用于退出当前循环,继续下一次循环
- while True:
- print ""
- continue
- print ""
三、文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
基本操作
|
1
2
3
4
5
6
7
8
|
f = open('lyrics') #打开文件first_line = f.readline()print('first line:',first_line) #读一行print('我是分隔线'.center(50,'-'))data = f.read()# 读取剩下的所有内容,文件大时不要用print(data) #打印文件f.close() #关闭文件 |
Python3 File(文件) 方法
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open('log','r') as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
|
1
2
|
with open('log1') as obj1, open('log2') as obj2: pass |
声明:
本人在学习老男孩python自动化网络课程后,结合所学整理做次笔记,本文内容多出
Alex老师博客:http://www.cnblogs.com/alex3714/articles/5740985.html
武沛齐老师博客:http://www.cnblogs.com/wupeiqi/articles/5444685.html
感谢老男孩教育老师Alex,武沛齐老师,本文多从二位老师文章中结合整理
感谢麻瓜编程侯爵
http://www.runoob.com/python3/python3-basic-syntax.html
https://python.xiaoleilu.com/100/101.html
http://www.ituring.com.cn/book/1863
图解Python 【第二篇】:Python基础2的更多相关文章
- 第二篇 python进阶
目录 第二篇 python进阶 一 数字类型内置方法 二 字符串类型内置方法 三 列表类型内置方法(list) 四 元组类型内置方法(tuple) 五 字典内置方法 六 集合类型内置方法(self) ...
- [转帖]虚拟内存探究 -- 第二篇:Python 字节
虚拟内存探究 -- 第二篇:Python 字节 http://blog.coderhuo.tech/2017/10/15/Virtual_Memory_python_bytes/ 是真看不懂哦 ...
- 孤荷凌寒自学python第二十八天python的datetime.date模块
孤荷凌寒自学python第二十八天python的datetime.date模块 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 一.toordinal() 此方法将访问从公元1年1月1日至当 ...
- 孤荷凌寒自学python第二十二天python类的继承
孤荷凌寒自学python第二十二天python类的继承 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) python中定义的类可以继承自其它类,所谓继承的概念,我的理解 是,就是一个类B继承自 ...
- 前端第二篇---前端基础之CSS
前端第二篇---前端基础之CSS 目录 一.css介绍 二.css语法 三.css的几种引入方式 四.css选择器 五.css属性相关 六.盒子模型 拓展 一.css介绍 CSS(Cascading ...
- 第二篇 Python初识别及变量名定义规范
第一个Python程序 可以打开notepad或者其他文本编辑器,输入:print("Hello Python!"),将文件保存到任意盘符下,后缀名是 .py 两种python程 ...
- python第一篇-------python介绍
一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,Guido开始写Python语言的编译器.Python这个名字,来自Guido所 ...
- python第二天 python介绍与变量
编程语言的分类: 分别为 机器语言,汇编语言,高级语言 所以按照翻译方式又被分为两种 编译型:在代码执行时,需要先进行编译成二进制文件之后,才能够被执行 代表如:c语言,执行速度快,但是调试麻烦 解释 ...
- python之路第二篇(基础篇)
入门知识: 一.关于作用域: 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. if 10 == 10: name = 'allen' print name 以下结论对吗? ...
- Python 第二篇:python字符串、列表和字典的基本操作方法
本文基于python 3.5.1 python常见的数据类型有字串.列表.元组.字典等,本文将详细介绍每一种数据类型的操作方法. 一:str字串的操作方法: 1.capitalize()--> ...
随机推荐
- 13.MySQL锁机制
锁的分类 从对数据的类型 (读\写)分: 1.读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响 2.写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁 从对数据操作的粒度 ...
- 【转载】python format遇上花括号{}
在format string中, 大括号已经被format占用,想要使用大括号本身,该怎么办? 以下转载自这里. ============ 分割线 ============ 使用format时,字符串 ...
- idea目录因包名而未合并、逐级显示的问题
如图包名里含有多个.,从而导致一个加载时出现了好多层.. 只要右键java目录,转换为source root就行.
- golang struct的使用
Go struct tag深入理解 喜欢本站的朋友可以收藏本站,或者加入QQ群:172816590,我们大家一起来交流技术! 欢迎来到梁钟霖个人博客网站.本个人博客网站提供最新的站长新闻,各种互联网资 ...
- python_列表方法
1.在列表后面追加元素 user = [] while True: name = input("输入名字:") # 在列表后面追加元素 user.append(name) prin ...
- CAP理论概述
CAP理论 CAP原则,指在一个分布式系统中,Consistency(一致性).Availability(可用性).Partitiontolerance(分区容错性),三者不可同时拥有. 一致性(C) ...
- 基于IAP的STM32程序更新技术
引言 嵌入式系统的开发最终需要将编译好的代码下载到具体的微控制器芯片上,而不同厂家的微控制器芯片有不同的下载方式.随着技术的发展和应用需求的更新,用户程序加载趋向于在线编程的方式,越来越多的芯片公司提 ...
- ios的uc浏览器图片加载不出来原因
最近做一个落地页发现一个在ios设备上uc浏览器的bug 在uc浏览器开启广告过滤的时候,会把图片过滤掉,无论是背景图还是img标签加载的图片 经过搜索与实验,发现广告过滤的设置关掉就可以,可是一般情 ...
- [codeforces792C][dp]
https://codeforc.es/contest/792/problem/C C. Divide by Three time limit per test 1 second memory lim ...
- 题解 [CF891C] Envy
题面 解析 首先根据Kruskal算法, 我们可以知道, 在加入权值为\(w\)的边时, 权值小于\(w\)的边都已经加进树里了(除了连成环的). 所以,我们可以保存一下每条边的端点在加入生成树之前的 ...