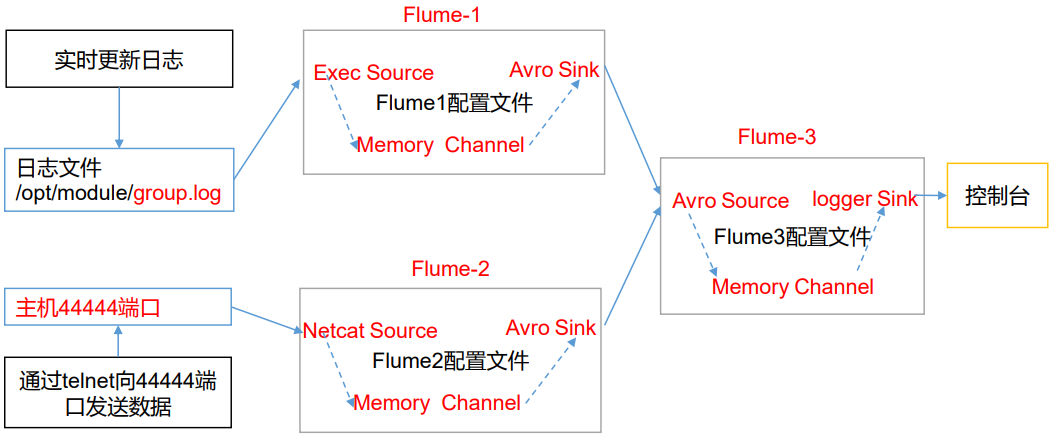
Flume-日志聚合
Flume-1 监控文件 /tmp/tomcat.log。
Flume-2 监控某一个端口的数据流。
Flume-1 与 Flume-2 将数据发送给 Flume-3,Flume-3 将最终数据打印到控制台。
一、创建配置文件
1.flume1-logger-flume.conf
配置 Source 用于监控 hive.log 文件,配置 Sink 输出数据到下一级 Flume。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /tmp/tomcat.log
a1.sources.r1.shell = /bin/bash -c # Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = h136
a1.sinks.k1.port = 4141 # Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.flume2-netcat-flume.conf
配置 Source 监控端口 44444 数据流,配置 Sink 数据到下一级 Flume。
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1 # Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = h136
a2.sources.r1.port = 4444 # Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = h136
a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
3.flume3-flume-logger.conf
配置 source 用于接收 flume1 与 flume2 发送过来的数据流,最终合并后 sink 到控制台。
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1 # Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = h136
a3.sources.r1.port = 4141 # Describe the sink
a3.sinks.k1.type = logger # Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
二、测试
flume3-flume-logger.conf 接收数据,需要先启动。
cd /opt/apache-flume-1.9.-bin bin/flume-ng agent --conf conf/ --name a3 --conf-file /tmp/flume-job/group4/flume3-flume-logger.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf/ --name a2 --conf-file /tmp/flume-job/group4/flume2-netcat-flume.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf/ --name a1 --conf-file /tmp/flume-job/group4/flume1-logger-flume.conf -Dflume.root.logger=INFO,console
向监控目录的文件和端口发送数据
echo '789qwewqe' >> /tmp/tomcat.log
echo '123cvbcvbcv' >> /tmp/tomcat.log
echo '456jkuikmjh' >> /tmp/tomcat.log yum -y install nc
# 需要与配置中的参数一致,若配的是主机名就不能写 IP 地址
nc h136

Flume-日志聚合的更多相关文章
- 网站行为跟踪 Website Activity Tracking Log Aggregation 日志聚合 In comparison to log-centric systems like Scribe or Flume
网站行为跟踪 Website Activity Tracking 访客信息处理 Log Aggregation 日志聚合 Apache Kafka http://kafka.apache.org/ ...
- 【转】Flume日志收集
from:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html Flume日志收集 一.Flume介绍 Flume是一个分布式.可 ...
- Apache Flume日志收集系统简介
Apache Flume是一个分布式.可靠.可用的系统,用于从大量不同的源有效地收集.聚合.移动大量日志数据进行集中式数据存储. Flume简介 Flume的核心是Agent,Agent中包含Sour ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Flume日志收集 总结
Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据: 同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. (1) 可靠 ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
- flume日志采集框架使用
flume日志采集框架使用 本次学习使用的全部过程均不在集群上,均在本机环境,供学习参考 先决条件: flume-ng-1.6.0-cdh5.8.3.tar 去cloudrea下载flume框架,笔 ...
- yarn配置日志聚合
[原文地址] 日志聚集是YARN提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,且提供一个中央化存储和分析机制.默认情况下, ...
- openshift 容器云从入门到崩溃之八《日志聚合》
日志可以分为两部分 业务日志 业务日志一般是要长期保留的,以供以后有问题随时查询,elk是现在比较流行的日志方案,但是容器日志最好不要落地所以不能把logstash客户端包在容器里面 可以使用logs ...
- 010 Spark中的监控----日志聚合的配置,以及REST Api
一:History日志聚合的配置 1.介绍 Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况 默认情况下历史日志是保存到tmp文件夹中的 2.参考官网的知识点 ...
随机推荐
- vue-动态路由+动态组件+动态页面
动态路由 路由组件是vue-router 动态路由即从后端请求路由信息,然后转化生成路由信息.所以这里的关键是不会提前知道什么菜单对应什么组件,因此路由声明的时候不再是写死的组件,而是可替换的动态路径 ...
- ActiveMQ入门系列之应用:Springboot+ActiveMQ+JavaMail实现异步邮件发送
现在邮件发送功能已经是几乎每个系统或网址必备的功能了,从用户注册的确认到找回密码再到消息提醒,这些功能普遍的会用到邮件发送功能.我们都买过火车票,买完后会有邮件提醒,有时候邮件并不是买完票立马就能收到 ...
- 使用百度地图API自动获取地址和经纬度
先上效果图,这是直接点击获取经纬度和地址的.没有做搜索的功能. 代码: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitiona ...
- Notepad++快捷键及使用技巧
常用快捷键: CTRL+Q 注释/取消注释 用Notepad++写代码,要是有一些重复的代码想copy一下,还真不容易,又得动用鼠标,巨烦人....有木有简单的方法呢,确实还是有的不过也不算太好用.主 ...
- Python学习记录5-面向对象
OOP 思想 以模块化思想解决工程问题 面向过程 vs 面向对象 由面向过程转向面向对象 常用名词 OO:面向对象 ooa:分析 ood:设计 oop:编程 ooI:实现 ooa -> ood ...
- CDH5.16.1的Hbase1.2的G1参数配置
1 贴一下自己的G1垃圾收集器参数(region server配置了5G内存) -Xmx5g -Xms5g -XX:MaxDirectMemorySize=5g -XX:+UseG1GC -XX:+U ...
- 一周死磕fastreport ----ASP.NET (三)
做了一周,然而说着很快 首先拖一个WebReport 点击design report 设置模板 引入dll using引用 设置好就打印就可以了 未来几天, 然后都在设置样式 ....如何就一周过去 ...
- C/C++代码规范
零.前言 笔者最近在看开源代码,看到代码格式各自参差不齐,感觉像是各家各有所长.因此打算写一篇关于C/C++代码规范文章,请各位参考,并践踏批评. 一.文件排版 1. 包含头文件 • 先系统头文件,后 ...
- EasyUi Datagrid中footer renderFooter
默认的'rowStyler' 选项不支持footer,想让footer支持rowStyler的话,dategird就得重写.代码如下. var myview = $.extend({}, $.fn.d ...
- Linux命令之nano(简单文本编辑器)
nano 字符终端文本编辑器 补充说明 nano 是一个字符终端的文本编辑器,有点像DOS下的editor程序.它比vi/vim要简单得多,比较适合Linux初学者使用.某些Linux发行版的默认编辑 ...