DAG及拓扑排序
1.有向无环图和拓扑排序
有向无环图(Directed Acyclic Graph,简称DAG);拓扑排序指的对DAG一个有序的线性排列。即每次选出一个没有入度的节点,然后输出该点并将节点和其相关连的弧都删除(此时均为以该节点为弧头的弧),依次进行,直至遍历所有节点,就是一个DAG的拓扑排序,值得一提的是一个图的拓扑排序不一定是唯一的,很有可能有若干个排序。不过这样仍然不太清楚,我们以图来展示。
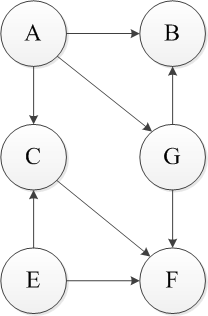
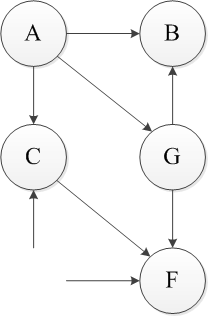

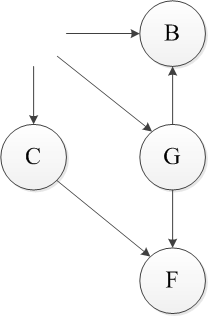



上述过程即为一个拓扑排序,首先对于该DAG来说,只有A和E是无入度的节点,任选一个E删除,接着删除相应的弧。【输出E】
同样此时只有A变成无入度节点,做同样的操作。【输出A】
删除A后只有顶点C和G没有前驱,仍然任选一个删除,依此类推,可以得到一个该图的拓扑排序。EAGCFB
2.拓扑排序的实现
前面深搜广搜已经用邻接矩阵实现无向图了,这里我们使用邻接表来表示有向图。先来复习一下邻接表

对于这样的数据结构应该怎么实现呢?如果你第一眼看上去觉得这就是若干个链表组成的,那么恭喜你回答正确,我们一般都是使用链表的思想来实现邻接表的。因此我们首先要在域中定义一个链表的数组:
private Ljtable [] vertex;
然后定义链表和节点类
class Ljtable {
char data;
Node head;
public Ljtable(char c,int n)
{
data = c;
head = new Node(n);
}
}
class Node {
int number;
Node next;
public Node(int a)
{
number = a;
next = null;
}
}
拓扑排序,纯本人手写,因为我的代码会使各节点的入度发生变化,因此需要提前存储,拓扑排序后在复原,看起来有点蠢。不过由于都是顺序排列,所以时间复杂度还好。
public void Topo()
{
int [] m = new int [vertex.length];
for (int i = 0; i < vertex.length; i++)
{
m[i] = vertex[i].inDegree;
} int k = 0;
while(k < vertex.length)
for (Ljtable l:vertex)
{
if(l.inDegree == 0) {
System.out.print(l.data);
k++;
Node h = l.head;
while(h!=null) {
vertex[h.number].inDegree--;
h = h.next;
}
} } for (int i = 0; i < vertex.length; i++)
{
vertex[i].inDegree = m[i];
} }
完整代码请看这里。
DAG及拓扑排序的更多相关文章
- 大数据工作流任务调度--有向无环图(DAG)之拓扑排序
点击上方蓝字关注DolphinScheduler(海豚调度) |作者:代立冬 |编辑:闫利帅 回顾基础知识: 图的遍历 图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点 ...
- CF-721C DAG图拓扑排序+费用DP
比赛的时候写了个记忆化搜索,超时了. 后来学习了一下,这种题目应该用拓扑排序+DP来做. dp[][]保存走到[第i个节点][走过j个点]时所用的最短时间. pre[][]用前驱节点求路径 然后遍历一 ...
- 拓扑排序(topsort)
本文将从以下几个方面介绍拓扑排序: 拓扑排序的定义和前置条件 和离散数学中偏序/全序概念的联系 典型实现算法解的唯一性问题 Kahn算法 基于DFS的算法 实际例子 取材自以下材料: http://e ...
- [ACM] hdu 1285 确定比赛 (拓扑排序)
确定比赛 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submi ...
- 关于最小生成树,拓扑排序、强连通分量、割点、2-SAT的一点笔记
关于最小生成树,拓扑排序.强连通分量.割点.2-SAT的一点笔记 前言:近期在复习这些东西,就xjb写一点吧.当然以前也写过,但这次偏重不太一样 MST 最小瓶颈路:u到v最大权值最小的路径.在最小生 ...
- POJ2762 Going from u to v or from v to u? 强连通分量缩点+拓扑排序
题目链接:https://vjudge.net/contest/295959#problem/I 或者 http://poj.org/problem?id=2762 题意:输入多组样例,输入n个点和m ...
- POJ1094——拓扑排序和它的唯一性
比较模板的topological-sort题,关键在于每个元素都严格存在唯一的大小关系,而一般的拓扑排序只给出一个可能解,这就需要每趟排序的过程中监视它是不是总坚持一条唯一的路径. 算法导论里面的拓扑 ...
- 洛谷P3275 [SCOI2011]糖果(差分约束,最长路,Tarjan,拓扑排序)
洛谷题目传送门 差分约束模板题,等于双向连0边,小于等于单向连0边,小于单向连1边,我太蒻了,总喜欢正边权跑最长路...... 看遍了讨论版,我是真的不敢再入复杂度有点超级伪的SPFA的坑了 为了保证 ...
- 拓扑排序 Topological Sort
2018-05-02 16:26:07 在计算机科学领域,有向图的拓扑排序或拓扑排序是其顶点的线性排序,使得对于从顶点u到顶点v的每个有向边uv,u在排序中都在v前.例如,图形的顶点可以表示要执行的任 ...
随机推荐
- tushare获取股票每日重要的基本面指标数据,并存入Elasticsearch
tushare是一个开放的,免费的金融数据平台,包含沪深股票数据,指数数据,基金数据,期货数据,期权数据,债券数据,外汇数据,港股数据,行业经济数据,宏观经济数据以及新闻快讯等特色数据.其中以沪深股票 ...
- 通过IP得到IP所在地省市
/// <summary> /// 通过IP得到IP所在地省市(Porschev) /// </summary> /// <param name="ip&quo ...
- WebForm——浅拷贝与深拷贝
注:本文整理来自连接 https://www.cnblogs.com/echolun/p/7889848.html ,感谢博主的分享 总结: 1.浅拷贝:只拷贝变量的名,而不拷贝变量的值——常为引用类 ...
- 创建Vofuria工程,获取产品密钥
进入Vofuria官网 https://developer.vuforia.com/vui/develop/licenses/free/new 然后点击 然后在License Name中填写izji刚 ...
- ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ:一种自动强化学习的神经网络深度量化方法 ReLeQ:一种自动强化学习的神经网络深度量化方法ReLeQ: An Automatic Reinforcement Learning Ap ...
- hdu 6047
题解:先对b排序,用一个数组预处理a,记录当前位置之后到n的最大值,然后在用一个变量维护新增变量的最大值,用的时候和前面的数组的最大值做一个比较就ok. AC代码: #include <cstd ...
- Scala学习十五——注解
一.本章要点 可以为类.方法.字段.局部变量.参数.表达式.类型参数以及各种类型定义添加注解 对于表达式和类型,注解跟在被注解的条目之后 注解的形式有@Annotation.@Annotation(v ...
- IOC+EF+Core项目搭建IOC注入及框架(二)
配置ServiceCollection /// <summary> /// 表示IServiceCollection的扩展 /// </summary> public stat ...
- Pattern Recognition and Machine Learning-01-Preface
Preface Pattern recognition has its origins in engineering, whereas machine learning grew out of com ...
- python numpy array 的sum用法
如图: sum可以指定在那个轴进行求和: 且第0轴是纵向,第一轴是横向: