使用scikit-learn决策树实现简单预测
1、scikit-learn决策树算法库介绍
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。
本实例采用分类库来做。
2、各环境安装
我使用的是python3环境
安装scikit-learn:pip3 install scikit-learn
安装numpy:pip3 install numpy
安装scipy:pip3 install scipy
安装matplotlib:pip3 install matplotlib
3、切入正题
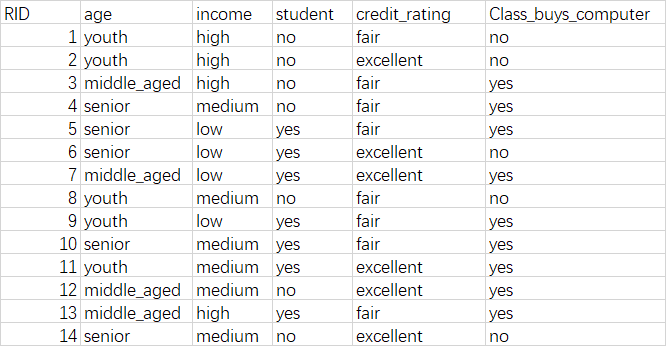
首先:我的原始数据是Excel文件,将它保存为csv格式,如data.csv
下面建一个python文件
首先读取数据
import csv # 这个库是python自带的用来处理csv数据的库
# 读取csv数据文件
allElectronicsData = open('data.csv', 'r',encoding='utf8')
reader = csv.reader(allElectronicsData) # 按行读取内容
headers=next(reader) #读取第一行的标题
因为scikit-learn处理数据时对数据的格式有要求,要求是矩阵格式的,所以对读取的数据进行预处理,处理成要求的格式。
# 对数据进行预处理,转换为字典形式
featureList = []
labelList = [] # 将每一行的数据编程字典的形式存入列表
for row in [rows for rows in reader]:
# print(row)
labelList.append(row[len(row) - 1]) # 存入目标结果的数据最后一列的
rowDict = {}
for i in range(1, len(row) - 1):
# print(row[i])
rowDict[headers[i]] = row[i]
# print('rowDict:', rowDict)
featureList.append(rowDict)
print(featureList)
使用scikit-learn自带的DictVectorizer()类将字典转换为要求的矩阵数据
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
# 将原始数据转换成矩阵数据
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX))
print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组
lb=preprocessing.LabelBinarizer()
dummyY=lb.fit_transform(labelList)
print('dummyY:'+str(dummyY))
创建决策树:
from sklearn import tree
# 创建决策树
clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法
clf=clf.fit(dummyX,dummyY)
print('clf:'+str(clf))
将决策树可视化输出:使用graphviz(下载地址)进行可视化
安装:将下载的zip文件解压到合适的位置,然后将bin目录添加到系统path中。
使用pydotplus模块输出pdf决策树。pydotplus安装:pip3 install pydotplus
# 直接导出为pdf树形结构
#import pydot
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
# graph = pydot.graph_from_dot_data(dot_data.getvalue())
# graph[0].write_pdf("iris.pdf")
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("mytree.pdf")
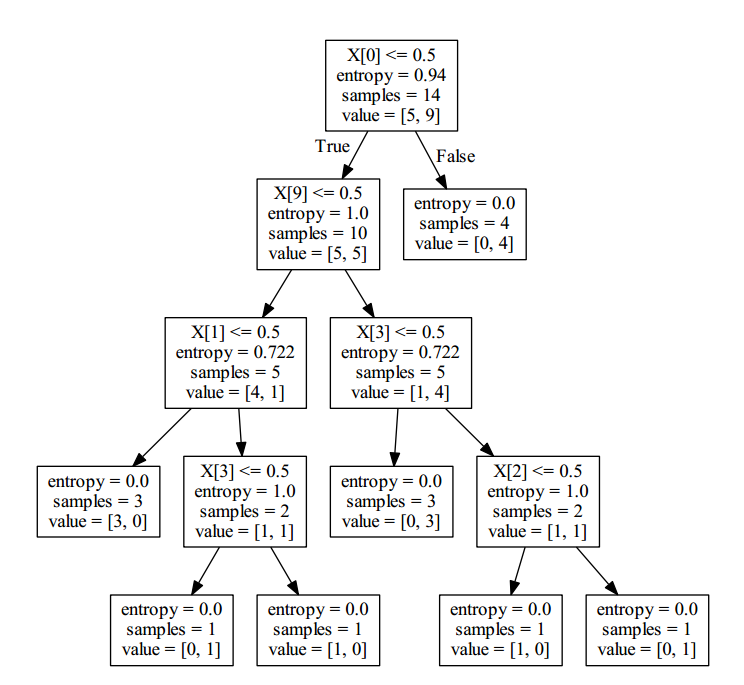
最后对新的数据进行预测:
# 预测数据
one=dummyX[2, :]
print('one'+str(one))
# one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
# 上面的数据对应下面列表:
#['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据
new=one
new[4]=1
new[3]=0
predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测
print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes
下面附上全部代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/3/20 20:37
import csv
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO # 读取csv数据文件
allElectronicsData = open('data.csv', 'r',encoding='utf8')
reader = csv.reader(allElectronicsData)# 按行读取内容
headers=next(reader) # print(list(reader))
#
# 对数据进行预处理,转换为矩阵形式
featureList = []
labelList = [] # 将每一行的数据编程字典的形式存入列表
for row in [rows for rows in reader]:
# print(row)
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
# print(row[i])
rowDict[headers[i]] = row[i]
# print('rowDict:', rowDict)
featureList.append(rowDict)
print(featureList) # 将原始数据转换成矩阵数据
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX))
print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组
lb=preprocessing.LabelBinarizer()
dummyY=lb.fit_transform(labelList)
print('dummyY:'+str(dummyY)) # 创建决策树
clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法
clf=clf.fit(dummyX,dummyY)
print('clf:'+str(clf)) # 直接导出为pdf树形结构
import pydot,pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
# graph = pydot.graph_from_dot_data(dot_data.getvalue())
# graph[0].write_pdf("iris.pdf")
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("iris2.pdf") with open('allElectronicInformationGainOri.dot','w') as f:
f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
# 通过命令行dot -Tpdf allElectronicInformationGainOri.dot -o output.pdf 输出树形结构 # 预测数据
one=dummyX[2, :]
print('one'+str(one))
# one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
# 上面的数据对应下面列表:
#['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据
new=one
new[4]=1
new[3]=0
predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测
print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes
全部代码
使用scikit-learn决策树实现简单预测的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- Spark技术在京东智能供应链预测的应用——按照业务进行划分,然后利用scikit learn进行单机训练并预测
3.3 Spark在预测核心层的应用 我们使用Spark SQL和Spark RDD相结合的方式来编写程序,对于一般的数据处理,我们使用Spark的方式与其他无异,但是对于模型训练.预测这些需要调用算 ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- 【Machine Learning in Action --3】决策树ID3算法预测隐形眼睛类型
本节讲解如何预测患者需要佩戴的隐形眼镜类型. 1.使用决策树预测隐形眼镜类型的一般流程 (1)收集数据:提供的文本文件(数据来源于UCI数据库) (2)准备数据:解析tab键分隔的数据行 (3)分析数 ...
随机推荐
- Shell脚本基础学习
Shell脚本基础学习 当你在类Unix机器上编程时, 或者参与大型项目如k8s等, 某些框架和软件的安装都是使用shell脚本写的. 学会基本的shell脚本使用, 让你走上人生巅峰, 才怪. 学会 ...
- SQL优化中的重要概念:死锁
原文:SQL优化中的重要概念:死锁 上面几篇文章讲到 事务.锁定.阻塞,最后还有一种比较极端的情况,就是死锁,这也是锁定.阻塞的一种情况. 死锁是当两个事务分别锁定了资源,而又继续请求对方已获取的资源 ...
- vue elment table根据返回值修改样式
今天在写vue项目的时候,查询出的数据库的数据想根据条件修改显示.查询资料有一个 :formatter,可以实现这个效果,废话不多说,这个是我的例子: <el-table-column prop ...
- Nginx Too many open files
2019/07/25 08:31:31 [crit] 15929#15929: accept4() failed (24: Too many open files) 2019/07/25 08:31: ...
- 基于【 Docker】四 || Docker常用镜像安装
一.nginx安装 1.拉取镜像:docker pull nginx 2.启动容器:docker run -d -p 80:80 nginx 3.查看nginx:ps aux | grep 'ngin ...
- java实现当前时间往前推N小时
import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date; /** * @author sha ...
- 用js原生加jquery实现下拉跳转至商品详情页,上拉回到商品简介
在做一个商城的项目时,做到商品详情页的时候需要实现这种下拉跳转到商品详情页加载许多图片,上拉回到商品简介的效果,并且需要用户在滑动时有一种费力的感觉.最初是通过iscroll插件实现的,但这个插件在使 ...
- S2-019、S2-020
前言 “Struts2系列起始篇”是我整各系列的核心,希望大家能花些时间先看看. 正文 我发现关于一些早期的Struts2的漏洞,网上的分析文章并不多,不知道是不是我打开浏览器的方式不对,唯一看到的两 ...
- 一步一步教你实现iOS音频频谱动画(二)
如果你想先看看最终效果再决定看不看文章 -> bilibili 示例代码下载 第一篇:一步一步教你实现iOS音频频谱动画(一) 本文是系列文章中的第二篇,上篇讲述了音频播放和频谱数据计算,本篇讲 ...
- 【Intel 汇编】ELF文件
ELF文件格式是一个开放标准,各种UNIX系统的可执行文件都采用ELF格式,它有三种不同的类型: 可重定位的目标文件(Relocatable,或者Object File) 可执行文件(Executab ...