strings、strconv:让你高效的处理字符串
什么是Redis
面试的时候,考官会经常问你,有没有用过什么缓存框架或者什么缓存中间件,其实就是想问 MemberCached、Redis 等等,或者你可以手写一个 LRU 缓存。
今天我们要讨论下 Redis,Redis 是一个非关系型内存数据库,也叫 NoSQL,因为它是直接在内存上操作所以叫内存数据库,速度非常快,QPS 达到 10w+。
平时我们用的 MySQL、Oracle、SQL Server、PostgreSQL 这些属于关系型数据库。通俗来说,以前我们的数据库,会有固定的表结构、主键外键等等,表与表之间可以通过 SQL 进行关联查询,但表与表之间多了便会复杂(建议一般不要超过三个表,超过就要进行插表了),这种复杂的关系查询会导致在高并发海量数据读写的时候,给硬盘 IO 带来很大的压力,有时候即使我们写的 SQL 天衣无缝,也避免不了数据库的性能瓶颈。
而 Redis 这种非关系型的数据库就是专门为高并发读写频繁场景而生的,它数据结构简单,跟 Hashmap 集合用法差不多,简单的 put、get、value。
以后一说到高并发读写频繁场景,我们就会想起有这么个好用的中间件 Redis。在我们实际应用场景下它可以为我们做点什么呢?下面是自己在工作中常用到的一些场景:
缓存,经常访问但有一段时间不会变的字段,例如保存短信验证各种排行榜签到功能点赞功能简单的消息队列,异步队列Session 服务器分布式锁
下面是Redis的思维导图,如果你熟悉Redis的话,估计只看导图就可以了。
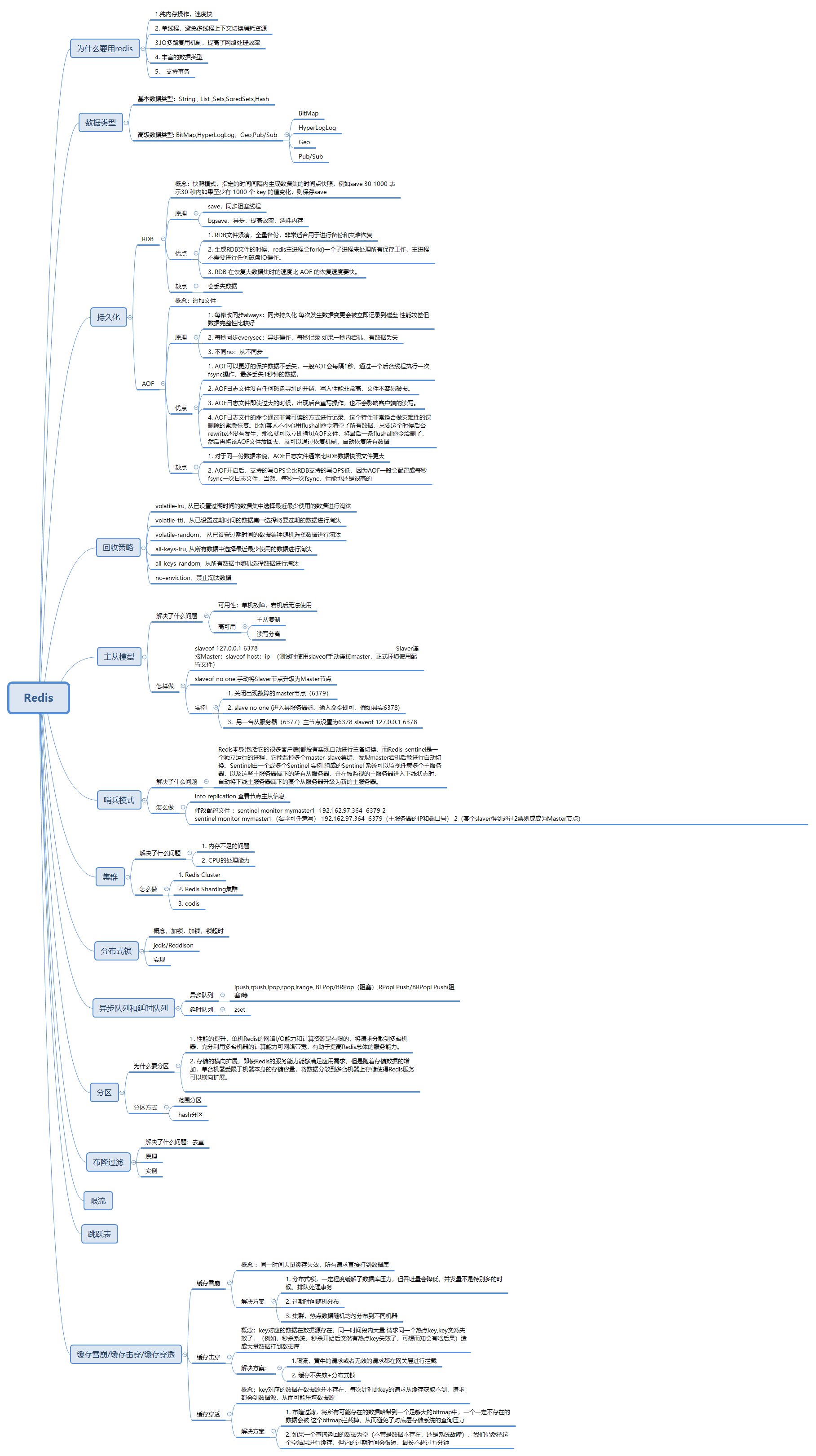
为什么是 Redis
缓存数据库那么多,为什么是Redis?
Redis 自身纯内存操作,速度快支持多种数据类型,String、List、set、Sorted Set、Hash、Stream支持持久化,RDB、AOF单线程,避免多线程上下文切换和竞争锁问题采用 epoll 多路复用非阻塞 IO,提高工作效率支持事务
那么 IO 多路复用机制是什么?epoll、select、poll 又有什么不一样呢?
复用,指的是复用同一个线程或者进程
多路 IO 复用是指在同一个线程中,会有多个 IO 流事件发生,我们可以同时去处理这些 IO 事件,不会影响到我们线程的任务。
就好像快递员发快递,他可以同时去处理顺丰,圆通,申通每一家公司的快递,只要他们快递到了快递员就会去送快递。select、poll 模式就是每次都一个个公司去询问,是否有快递到了。epoll 模式,顺丰会给你打电话,说小伙子某某的快递到了,你可以过来拣货去送快递了,不需要每次都去询问公司,公司会主动找你。这样你就有了更多的空闲时间,去做点其他事情,人生不只是送快递。
epoll、select、poll 的区别:
select:服务端会一直在轮询、监听,如果有客户端链接上,就进行处理,此过程会一直循环,消耗资源大poll:跟 select 差不多,是其加强版,select 连接数是 1024,而 poll 没有限制了epoll:服务端也会监测 IO 事件,但是它不会循环遍历的去监听,当有客户端发来连接,会去通知服务端,然后服务端才会进行处理,这就大大提高了效率。
小时候,老师提问,有时候会一个个去问学生,轮流问,那就是 select,poll 模式,估计这样问完,一节课快要下课了;此时,老师为了提高效率,就跟大家说,知道问题的答案就举手回答,那样就可以知道谁真正掌握了这个问题。这就是 epoll,并且它们本质上都是阻塞 IO。
有人会说 Memcached 也是内存数据库,为什么要用 Redis?
Redis 支持丰富的数据类型,基础数据类型 String、list、set、zset、hash、Stream,高级数据类型,例如 bitmap、geo、HyperLogLog 等数据结构的存储。Memcache 只支持简单的数据类型,String。Redis 支持数据的持久化,例如 RDB 和 AOF,一些重要的数据可以保持在磁盘中,当遇到突然停电宕机这种情况,可以用来进行灾难恢复。而 Memecache 把数据全部存在内存之中。Redis 支持集群模式,哨兵模式,主从复制,具有高可用。Redis 使用单线程的多路 IO 复用模型,单线程能保证其安全性。Memcached 是多线程。
Redis 的基本数据类型和高级数据类型
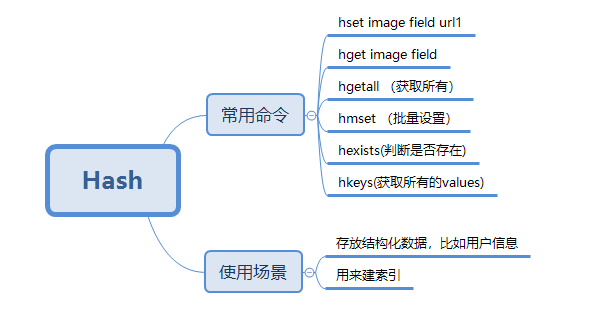
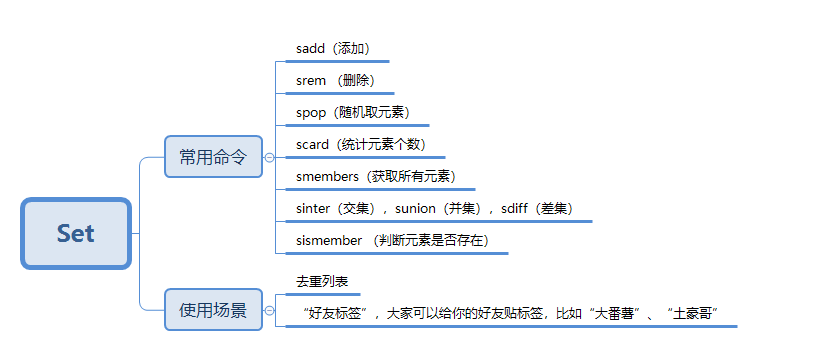
五种基本数据类型
String
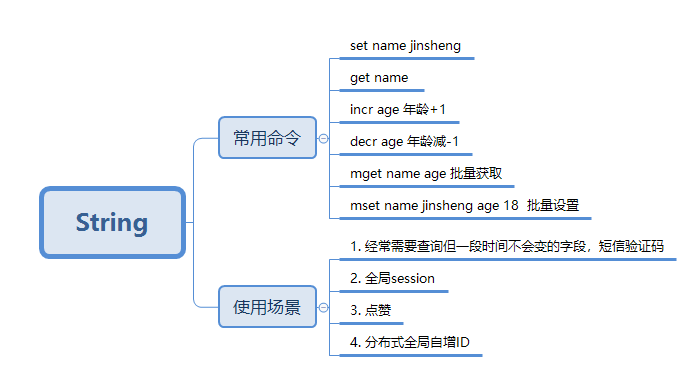
List

Hash
Set
SoredSet(也叫 zSET)
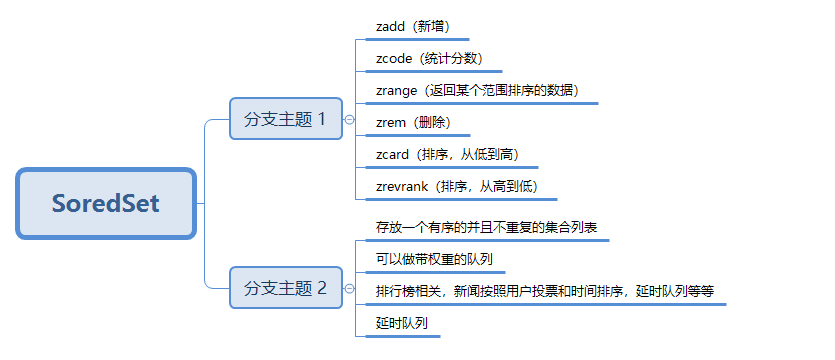
高级数据类型
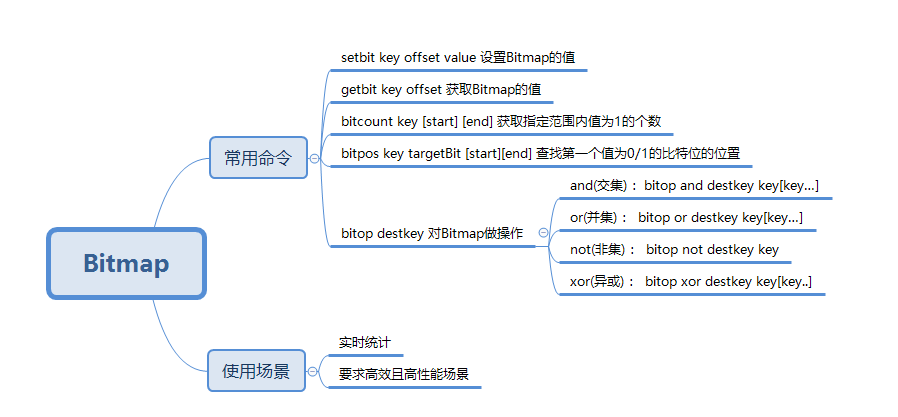
Bitmap
用来存储状态,是或否。举个栗子:
有一天老板突然说,我们系统需要增加一个每天签到送积分的功能。这个可愁死我了。按照以前的逻辑我会创建一个用户表,表中用 ID 和用户签到状态 status,用户签到一天我们会新增一条记录。当时以极快的效率做出来了,受到了老板的表演,小伙子可以啊,头发多还有实力哦。好景不长,我们的系统随着业务的高速发展,用户量暴增,达到了千万级别。
有一天发现系统突然卡死宕机了,原来是我们系统数据库挂了,一直连不到数据库。由于数据库硬盘存储不够了,而导致我们存储不够的原因,是因为用户签到表数据量太大了。你想想一个用户一天一条数据,一年 365 条,用户达到了上亿的系统,这数据量可怕啊。此时我赶紧连夜赶工,把 Bug 修复了。
这个时候 Redis 的 bitmap 就被我派上用场了。
用户是否签到可以用 0/1 来表示,0 代表用户不签到,1 表示签到,那么 1bit 就可以表示用户是否签到。
大概预估了下一亿个用户一个月的数据量也就是几百兆。此时的我,头发迎风飘扬。
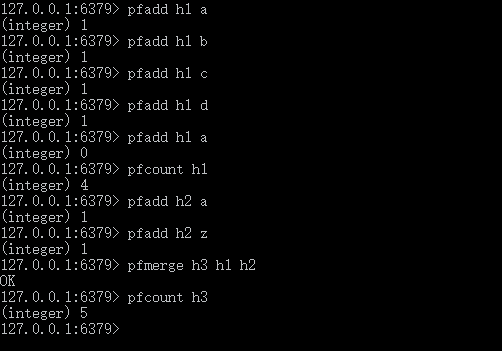
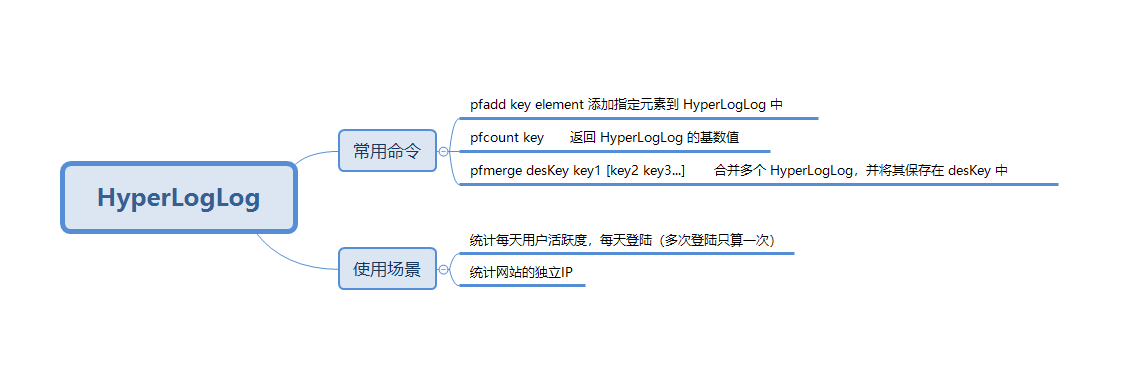
HyperLogLog
是基于基数来进行估算的,误差率大概 0.81,输入的元素越小,误差率有时候会比较大,所以当我们需要统计一些大量重复的数据 ,而这些误差可以忽略不计时候可以用它。
当你输入的数据数据量非常大的时候,亿万级,它需要的存储也不大,固定的而且每个键值只要 12K 大小,但它可以存储的 2^64 个不同的基数,大大节约了存储空间。如果我们用集合 hashmap 虽然也能实现这功能,但需要的存储成本肯定差很多。
虽然 HyperLogLog 在统计海量数据方面优势肉眼可见的优势,但因为 HyperLogLog 只会根据输入数据来计算基数,而不会储存输入元素本身,所以 使用 HyperLogLog 如果你想获取集合中的元素,这个功能是不能实现的。
当数据量越大的时候,值会不太准确。所以它只适合那些对精确度要求没那么高的场景。
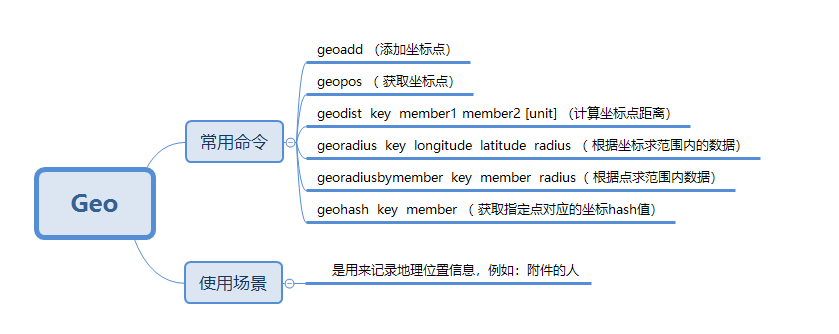
Geo
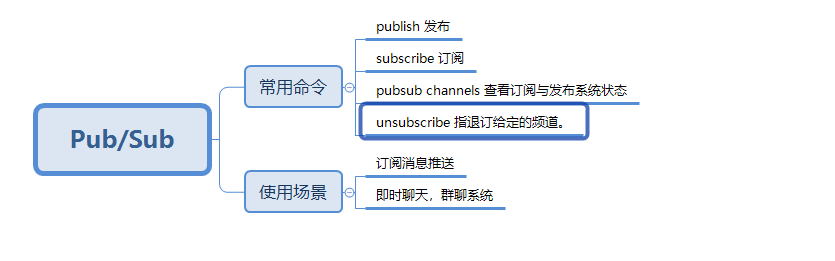
Pub/Sub(发布订阅)
举个栗子:
只发msg1publish msg1 hello
(integer) 2
发布 msg1 频道消息
返回 int 2 表示有 2 个客户端收到了 msg1 频道消息
只发msg2publish msg2 hello
(integer) 2
发布 msg2 频道消息
返回 int 2 表示有 2 个客户端收到了 msg2 频道消息
客户端 1 在监听 msg1 频道:subscribe msg1
Reading messages... (press Ctrl-C to quit)
1) "subscribe" # 显示订阅成功
2) "msg1" # 订阅的频道(通道)名称
3) (integer) 1 # 自己订阅的频道数量
客户端 2 在监听 tv1 和 tv2 多个频道:subscribe msg1 msg2
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "msg1 "
3) (integer) 1
1) "subscribe"
2) "msg2"
3) (integer) 2
分布式锁的实现
说到分布式锁,很多人可能都知道它的原理,但并没有实际的项目经验。下面说的是我工作中对分布式锁的实践运用。
分布式锁的三种方式:
- 1. 数据库 (一般不用)
- 2. Redis
优点:性能比较高缺点:需要手动实现复杂的代码
- 3. zookeeper
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,实现简单(临时节点的创建和取消)缺点:因为需要频繁的创建和删除节点,性能上不如 Redis 方式
原理
分布式锁应具备以下特点:
在分布式系统环境下,一个方法在同一时间,只能被一个机器的一个线程执行高可用的获取锁以及释放锁高性能的获取锁以及释放锁具备可重入特性具备锁失效机制,防止死锁具备非阻塞锁特性,在没有获取到锁的时候,直接返回获取锁失败
分布式锁设计遇到的坑:
加锁时候,如果没有加超时时间,机子突然宕机了,会导致死锁,其他机子会一直拿不到锁加锁的时候,应该使用原子命令任务没执行完成,就释放锁了,可以对锁续时,Redisson 客户端已经帮我我们把这个功能实现解锁的时候不要删错锁
场景
有一个订单,我们会对订单进行业务处理,例如分仓(就是生成包裹),如果只是一台服务器去执行的话,不会出现什么问题。但在高并发的场景下,会有多台服务器同时去处理这个订单。这样就会导致重复分仓,生成了多个包裹,此时老板和领导就会过来找你喝茶……
RDB 和 AOF 的理解
RDB
定义&原理:
指定的时间间隔内生成数据集的时间点快照,例如 save 30 1000 表示 30 秒内如果至少有 1000 个 key 的值变化,则保存 save。
RDB 触发机制有三种:
save,同步,阻塞进程bgsave,异步操作,消耗资源配置文件
优点:服务器突然宕机了,此时肯定是首先要把服务器快速恢复。此时候 RDB 就能当此重任,它能快速进行灾难恢复,速度比 AOF 快很多,而且在进行数据恢复的时候,RDB 模式可以异步进行,主进程会 fork 一个子进程来进行数据恢复,不会影响主进程。
缺点: 会丢失部分数据数据。
AOF
文件追加模式
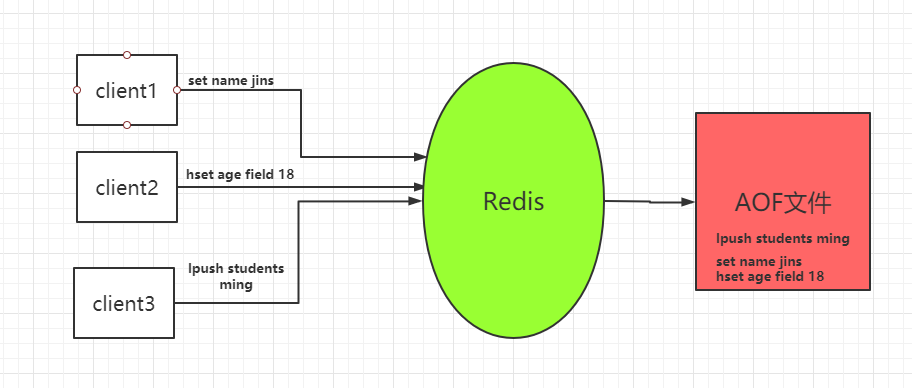
三种触发机制
always:每次有数据发生变化都会进行同步,这样能保证数据的完整性但牺牲了系统的性能,同步持久化everysec:默认配置,每秒都会进行数据保存,如果碰巧不小心一秒内停电宕机,也只会丢失这一秒的数据,异步no:从不同步数据
优点:
AOF 模式数据完整性更强更加安全,最多只会让系统丢失一秒的数据。AOF 模式写入性能高,不会频繁进行磁盘 IO,而且文件损坏相对来说概率小。AOF 模式当数据达到一个阈值的时候,可以对文件进行压缩,减小文件大小,异步 fork 另一个进程,不影响主进程 。AOF 模式适合最紧急性灾难数据恢复。如果有同事错用 flushall 命令导致所有数据都被他删除了,前提是服务器后台重写还没有开始,这个同事还是能被救的哦。此时我们应该马上复制一份 AOF 文件,并将最后一次使用的 flushall 命令删除掉,然后再拷贝的文件重新放回去便可。
缺点:
AOF 日志文件比 RDB 数据快照文件更大,速度没 RDB 快AOF 写 QPS 相对来说会比 RDB 支持的写 QPS 低
使用管道技术提高服务器性能
什么是管道技术
以前我们没发一个请求,会等服务端给我们一个响应,然后才能进行下一步操作。但我们想不等服务端给我们回应就不能做其他的事情了么?不能再给服务器发请求了么?虽然我们可以用异步去实现这个功能,今天跟大家说的 Redis 管道技术就是很好地帮我们解决了这个问题。
Redis 管道技术可以一次性读取客服端发来的请求。例如,Redis 上有一个 key age=18,当客户端 client 连续发送 incr age. 总共三次,服务端会一次性去接收这三条命令,并且处理好响应,看到的返回结果是 age=21。频繁地操作 Redis,对效率会有很大的影响。虽然这管道技术在处理请求上效率提高了,减少了链路上时间的消耗,但只能是要求实时性不是那么高的系统。如果系统要求实时性十分高,就好像我每次操作都要看到结果,管道技术就不太适合。
使用场景
群发消息,如果每发一条消息就去操作链接 Redis,一千万的话,那不是要一千万次操作,可怕,每个链接耗时 2 或者 3ms,总耗时也是很可怕的。获取或者处理批量数据。
异步队列和延时队列的实现
异步队列
Redis 是用来做轻量级消息队列的(Disque 是新出的特性,消息队列系统),如果是重量级的,kafka、rocketMq、RabbitMQ 等消息中间件是更好的选择。
延时队列
场景
订单下单后没有支付成功,订单自动取消订单完成后,系统自动评价
原理
Redis 的基本数据类型 soredSet(Zset)可以用来实现延时队列 用户下单后生成订单并记录其下单时间作为 score,我们希望 30 分钟后,如果支付不成功,我们系统便可以对它进行自动取消订单。操作。每个用户订单我们都会放到 soredSet 数据结构的列表,然后按时间大小进行排序。我们会有定时任务不断地从列表获取订单,如果当前时间和订单下单时间对比,如果大于 30 分钟以上,我们就会对它完成取消订单的操作。
Redis cluster 集群
什么是集群?
Redis 集群主要是解决单个实例在高并发场景压力过大的问题,减压分压。集群的数据会根据不同的 key 分到不同的槽中。
集群和哨兵模式和主从复制的区别?
哨兵模式:主要是为了保证服务器的高可用,哨兵会监控集群里面的每一台服务器,如果出现问题了,它就会重新进行选举,选出 master。主从模式:是为了防止主节点突然宕机,数据丢失了,它会复制一份数据到另外一台机子上,就是备份。
搭建集群的时候,如果没有配置哨兵模式,如果 master 服务器宕机了,每次都需要手动去操作:slaveof IP,选择另外一台从服务器作为 master。有了哨兵模式后,就能自动选举,不用手动进行。
Redis 集群,需要至少 3 个主节点,既然有 3 个主节点,而一个主节点搭配至少一个从节点,因此至少得 6 台 Redis 服务器。
集群的一些常用配置,以后有机会可以再分享。
分片技术
假如领导需要看下订单的半年数据报表,而这些订单的数据量大,而且获取这些报表数据除了要关联多张表,还要调用第三方接口进行统计进行复杂的逻辑的计算。如果是用正常的方式去处理数据,一天之内完成任务是不可能。
这个时候我们的 Redis 分片技术就可以帮我们解决这个问题。 利用这个技术,我们可以用更多的服务器去实现这个功能,就好像,以前我一个人干的事,现在来了 6 个人帮我,效率肯定会比之前快多。
解决方案:我们会按时间进行分区,例如 1 月份、2 月份、3 月份,每个月份代表一个区间,一个 Redis 实例会处理一个区间的数据,当所有区间的事务都处理完了就可以了。
下面是我们设置的分区,每个会根据订单的下单时间查询出所有订单,然后对订单进行一些业务处理。
首先我们会把分区信息缓存到 Redis,然后启动多台实例进行处理数据:
[{
"pageSize": 1000,
"startTime": "2018-03-02 00:00:00",
"endTime": "2019-01-02 00:00:00"
}, {
"pageSize": 1000,
"startTime": "2019-01-02 00:00:00",
"endTime": "2019-03-02 00:00:00"
}, {
"pageSize": 1000,
"startTime": "2019-03-02 00:00:00",
"endTime": "2019-06-02 00:00:00"
}, {
"pageSize": 1000,
"startTime": "2019-06-02 00:00:00",
"endTime": "2019-09-02 00:00:00"
}, {
"pageSize": 1000,
"startTime": "2019-09-02 00:00:00",
"endTime": "2019-10-02 00:00:00"
}, {
"pageSize": 1000,
"startTime": "2019-10-02 00:00:00",
"endTime": "2059-09-01 00:00:00"
}]
strings、strconv:让你高效的处理字符串的更多相关文章
- 【转自CSDN】深入 Microsoft.VisualBasic.Strings.StrConv 簡繁轉換
深入 Microsoft.VisualBasic.Strings.StrConv 簡繁轉換 昨天又遇到一個簡繁轉換的需求, 雖然這個問題以前已經處理過了, 但是以前是用自己建立的 b52gb 和 gb ...
- GO开发[三]:fmt,strings,strconv,指针,控制结构
一.fmt包 %v 值的默认格式表示.当输出结构体时,扩展标志(%+v)会添加字段名 %#v 值的Go语法表示 %T 值的类型的Go语法表示 %% 百分号 %t 单词true或false %b 表示为 ...
- JS下高效拼装字符串的几种方法比较与测试代码
在使用Ajax提交信息时,我可能常常需要拼装一些比较大的字符串通过XmlHttp来完成POST提交.尽管提交这样大的信息的做法看起来并不优雅,但有时我们可能不得不面对这样的需求.那么JavaScrip ...
- 最优雅,高效的javascript字符串拼接
这种方式是es6的语法.使用键盘1左边的那个字符 `` 拼接, 再加上js自带的模板引擎拼接字符串非常快速.这东西也没什么高深的,看几个例子就懂了. console.log(`<xml> ...
- 使用StringBuilder更高效的处理字符串
前言 本文介绍一个java中处理字符串的技巧 - 使用StringBuilder提高字符串处理效率. StringBuilder 当程序要频繁的进行字符串拼接的时候,直接使用String效率会比较低. ...
- iOS开发:Swift/Objective-C高效生成随机字符串
原文连接 Objective-C版 // 随机生成字符串(由大小写字母.数字组成) + (NSString *)random: (int)len { char ch[len]; for (int in ...
- Go中的字符串使用----strings和strconv
Go中的字符串操作 字符串是工作中最常用的,值得我们专门的练习一下.在Go中使用strings包来操作字符串,这也是内置的包哈,不像Java中要么手写,要么引入common-lang 或者 别的第三方 ...
- golang(3):strings和strconv使用 & 时间和日期类型 & 指针类型 & 流程控制 & 函数
strings和strconv使用 . strings.HasPrefix(s string, prefix string) bool: // 判断字符串s是否以prefix开头 . . string ...
- Go开发之路 -- strings以及strconv的使用
strings的使用 HasPrefix 语法: strings.HasPrefix(s, prefix string) bool // 判断字符串s是否以prefix开头 // 判断一个url是否以 ...
随机推荐
- 动态执行表不可访问,或在v$session
PLSQL Developer报“动态执行表不可访问,本会话的自动统计被禁止”的解决方案 PLSQL Developer报“动态执行表不可访问,本会话的自动统计被禁止”的解决方案 现象: 第一次用PL ...
- Hibernate查询总的记录数
1. 原生sql String hql="select count(*) from product" ;//此处的product是数据库中的表名 Query query=sessi ...
- Cinder AZ 与 Nova AZ 的同步问题
问题 今天处理了一个 Boot from volume 失败的问题,错误日志给出了明确的原因:The instance and volume are not in the same AZ. Build ...
- IPTV系统的VOD与TV业务性能测试
IPTV的未来发展正在成为业界的焦点话题.据市场研究公司MRG的统计,全球IPTV用户将由2004年的200万增加至2010年的2000万,预计全球IPTV市场2005-2010年的复合增长率为102 ...
- 正说PropertyValuesProvider的应用
Github地址:https://github.com/andyslin/spring-ext 编译.运行环境:JDK 8 + Maven 3 + IDEA + Lombok spring-boot: ...
- Django Model 基础数据库操作应用
https://blog.csdn.net/Mrzhangjwei/article/details/53001841 一.数据库操作1.创建model表 基本结构: from django.db im ...
- Linux 使用中history 默认记录数不够用了?
1.默认情况下,系统能保存1000条的历史命令. #echo $HISTSIZE 2.那么1000条不够用,该怎么办呢? #vi /etc/profile 修改HISTSIZE=1000 > ...
- 【linux开发】IO端口和IO内存的区别及分别使用的函数接口
IO端口和IO内存的区别及分别使用的函数接口 每个外设都是通过读写其寄存器来控制的.外设寄存器也称为I/O端口,通常包括:控制寄存器.状态寄存器和数据寄存器三大类.根据访问外设寄存器的不同方式,可以把 ...
- JAVA -数据类型与表达式---表达式
表达式由一个以上的运算符和操作数按一定规则组合而成,通常用于完成计算.计算结果一般是一个数值,但也不一定总是数值.用于计算的操作数可能是数值常量.符号常量.变量或其他某种类型的数据.计算和使用表达式的 ...
- 色彩空间RGB/CMYK/HSL/HSB/HSV/Lab/YUV基础理论及转换方法:RGB与YUV
之前做个设计,现在从事IT,脑子里面关于RGB,RGBA,CMY,CMYK,YUV,但是具体理论还是不扎实.若干年前之前写过<水煮RGB与CMYK色彩模型—色彩与光学相关物理理论浅叙>&l ...