DPDK 网络加速在 NFV 中的应用
目录
文章目录
前文列表
《OpenStack Nova 高性能虚拟机之 NUMA 架构亲和》
《OpenStack Nova 高性能虚拟机之 CPU 绑定》
《OpenStack Nova 高性能虚拟机之大页内存》
《多进程、多线程与多处理器计算平台的性能问题》
《计算机组成原理 — 存储系统》
《计算机组成原理 — 输入输出系统》
《计算机组成原理 — 总线系统》
《Linux 的零拷贝技术》
《数据包从物理网卡流经 Open vSwitch 进入 OpenStack 云主机的流程》
传统内核协议栈的数据转发性能瓶颈是什么?
在 x86 结构中,处理数据包的传统方式是 CPU 中断方式,即网卡驱动接收到数据包后通过中断通知 CPU 处理,然后由 CPU 拷贝数据并交给内核协议栈。在数据量大时,这种方式会产生大量 CPU 中断,导致 CPU 无法运行其他程序。
传统内核协议栈的数据转发流程:

传统内核协议栈的数据转发性能瓶颈有:
- 硬件中断导致的线程/进程切换:硬件中断请求会抢占优先级较低的软件中断,频繁到达的硬件中断和软中断意味着频繁的线程切换,随着而来的就是运行模式切换、上下文切换、线程调度器负载、高速缓存缺失(Cache Missing)、多核缓存共享数据同步、竞争锁等一系列的 CPU 性能损耗。
- 内存拷贝:网卡驱动位于内核态,网络驱动接收到的数据包后会经过内核协议栈的处理,然后再拷贝到处于用户态的应用层缓冲区,这样的数据拷贝是很耗时间的。据统计,这个拷贝的时间会占数据包处理流程时间的 57.1%。
- 多处理器平台的 CPU 漂移:一个数据包可能中断在 CPU0,内核态处理在 CPU1,用户态处理在 CPU2,这样跨多个物理核(Core)的处理,导致了大量的 CPU Cache Miss,造成局部性失效。如果是 NUMA 架构,还会出现跨 NUMA remote access Memory 的情况,这些都极大地影响了 CPU 性能。
- 缓存失效:传统服务器大多采用页式虚拟存储器,内存页默认为 4K 的小页,所以在存储空间较大的处理机上会存在大量的页面映射条目。同时因为 TLB 缓存空间有限,最终导致了 TLB 快表的映射条目频繁变更,产生大量的快页表 Cache Miss。
与之对应的优化方案为:
- 使用 NUMA 亲和:避免 CPU 跨 NUMA 访问内存。
- 使用 CPU 绑核:避免跨 CPU 的线程/进程切换。
- 使用大页内存:避免 TLB Cache Miss。
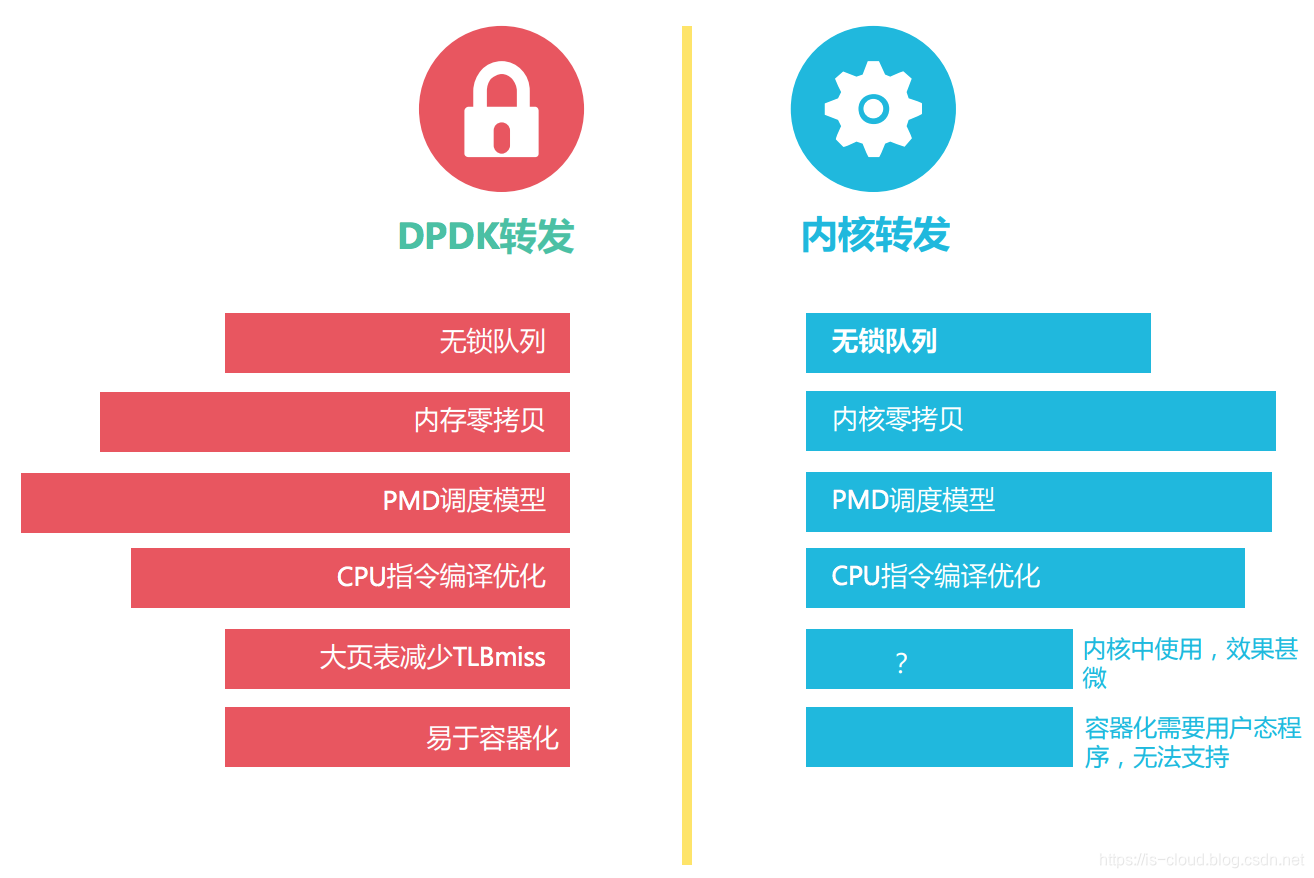
- 使用 DPDK:DPDK 改造了传统的协议栈数据包转发路径,避免了频繁的硬件中断和无效数据拷贝。
DPDK
DPDK(Data Plane Development Kit,数据平面开发套件)是一个开源的、快速处理数据平面数据包转发的开发平台及接口。运行于 Intel x86 与 ARM 平台上,最新版本也开始支持 PowerPC。
DPDK 提供了一个用户态的高效数据包处理库函数,它通过环境抽象层、旁路内核协议栈、轮询模式的报文无中断收发、优化内存/缓冲区/队列管理、基于网卡多队列和流识别的负载均衡等多项技术,实现了在 x86 处理器架构下的高性能报文转发能力,用户可以在 Linux 用户态开发各类高速转发应用,也适合与各类商业化的数据平面加速解决方案进行集成。简而言之,DPDK 重载了网卡驱动,将数据包的控制平面和数据平面分离,驱动在收到数据包后不再硬中断通知 CPU,而是让数据包通过旁路的内核协议栈绕过了 Linux 内核协议栈,并通过零拷贝技术存入内存,这时应用层的程序就可以通过 DPDK 提供的接口,直接从内存读取数据包。
DPDK 数据包处理流程:
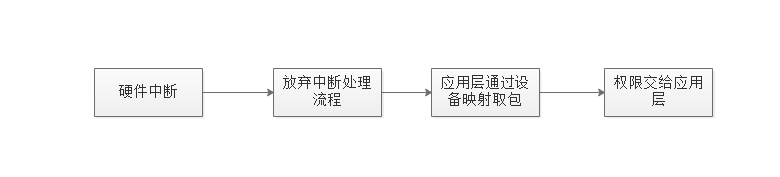
这种处理方式节省了 CPU 中断时间、内存拷贝时间,并向应用层提供了简单易行且高效的数据包处理方式,使得网络应用的开发更加方便。但同时,由于需要重载网卡驱动,因此该开发包目前只能用在部分采用 Intel 网络处理芯片的网卡中。DPDK 可以将数据包处理性能最多提高十倍。在单个英特尔至强处理器上获得超过 80 Mbps 的吞吐量,在双处理器配置中则可将该其提高一倍。
英特尔在 2010 年启动了对 DPDK 技术的开源化进程,于当年 9 月通过 BSD 开源许可协议正式发布源代码软件包,并于 2014 年 4 月在 www.dpdk.org 上正式成立了独立的开源社区平台,为开发者提供支持。开源社区的参与者们大幅推进了 DPDK 的技术创新和快速演进,而今它已发展成为 SDN 和 NFV 的一项关键技术。
DPDK 基本技术
DPDK 基本技术指标准的 DPDK 数据平面开发包和 I/O 转发实现技术。我们首先从 DPDK 的架构入手,再逐一解析 DPDK 的核心技术。
DPDK 架构
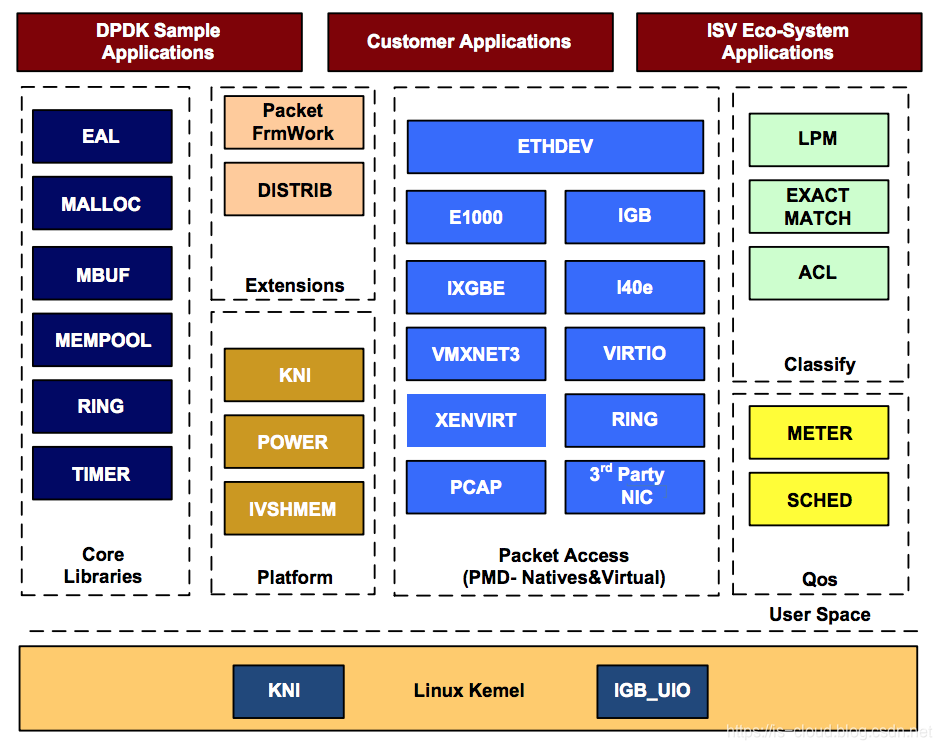
在最底部的内核态(Linux Kernel)DPDK 有两个模块:KNI 与 IGB_UIO。其中,KNI 提供给用户一个使用 Linux 内核态的协议栈,以及传统的 Linux 网络工具(e.g. ethtool、ifconfig)。IGB_UIO(igb_uio.ko 和 kni.ko.IGB_UIO)则借助了 UIO 技术,在初始化过程中将网卡硬件寄存器映射到用户态。
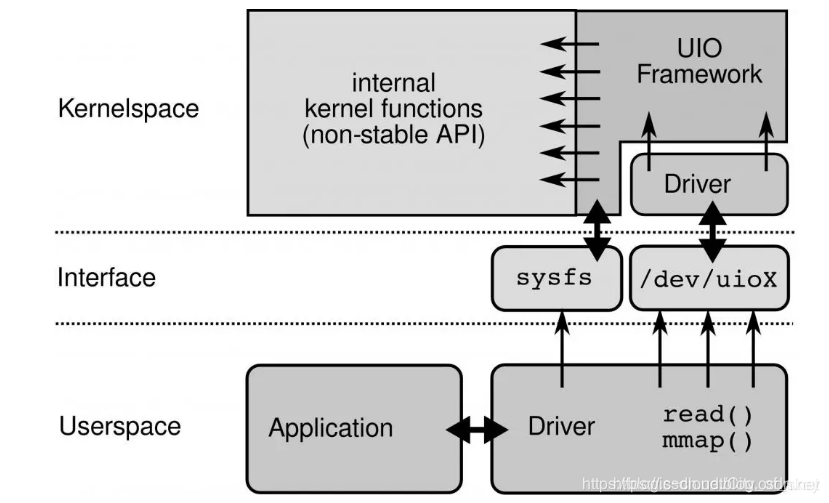
- UIO:是用户态的一种 I/O 技术,DPDK 能够绕过内核协议栈,本质是得益于 UIO 技术,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。UIO 的实现机制其实是对用户态暴露文件接口,比如当注册一个 UIO 设备 uioX,就会出现文件 /dev/uioX,对该文件的读写就是对设备内存的读写。除此之外,对设备的控制还可以通过 /sys/class/uio 下的各个文件的读写来完成。
DPDK 的上层用户态由很多库组成,主要包括核心部件库(Core Libraries)、平台相关模块(Platform)、网卡轮询模式驱动模块(PMD-Natives&Virtual)、QoS 库、报文转发分类算法(Classify)等几大类,用户应用程序可以使用这些库进行二次开发。
核心部件库:该模块构成的运行环境是建立在 Linux 上,通过环境抽象层(EAL)的运行环境进行初始化,包括:HugePage 内存分配、内存/缓冲区/队列分配与无锁操作、CPU 亲和性绑定等;其次,EAL 实现了对操作系统内核与底层网卡 I/O 操作的屏蔽(I/O 旁路了内核及其协议栈),为 DPDK 应用程序提供了一组调用接口,通过 UIO 或 VFIO 技术将 PCI 设备地址映射到用户空间,方便了应用程序调用,避免了网络协议栈和内核切换造成的处理延迟。另外,核心部件还包括创建适合报文处理的内存池、缓冲区分配管理、内存拷贝、以及定时器、环形缓冲区管理等。
- EAL(Environment Abstraction Layer,环境抽象层):为应用提供了一个通用接口,隐藏了与底层库与设备打交道的相关细节。EAL 实现了 DPDK 运行的初始化工作,例如:基于大页表的内存分配,多核亲和性设置,原子性和锁操作,并将 PCI 设备地址映射到用户空间,方便应用程序访问。
- MALLOC(堆内存管理组件):为应用程序提供从大页内存分配堆内存的接口。当需要分配大量小块内存时,如:用于存储列表中每个表项指针的内存,使用这些接口可以减少 TLB 缺页。
- MBUF(网络报文缓存块管理组件):为应用程序提供创建和释放用于存储报文信息的缓存块的接口,这些 MBUF 存储在一内存池中。提供两种类型的 MBUF,一种用于存储一般信息,一种用于存储报文数据。
- Buffer Manager API:通过预先从 EAL 上分配固定大小的多个内存对象,避免了在运行过程中动态进行内存分配和回收来提高效率,常常用作数据包 Buffer 来使用。
- MEMPOOL(内存池管理组件):为应用程序和其它组件提供分配内存池的接口,内存池是一个由固定大小的多个内存块组成的内存容器,可用于存储相同对像实体,如报文缓存块等。内存池由内存池的名称(一个字符串)来唯一标识,它由一个环缓中区和一组核本地缓存队列组成,每个核从自已的缓存队列分配内存块,当本地缓存队列减少到一定程度时,从内存环缓冲区中申请内存块来补充本地队列。
- RING(环缓冲区管理组件):为应用程序和其它组件提供一个无锁的多生产者多消费者 FIFO 队列 API。
- Queue Manager API:以高效的方式实现了无锁的 FIFO 环形队列,适合与一个生产者多个消费者、一个消费者多个生产者模型来避免等待,并且支持批量无锁的操作。
- TIMER(定时器组件):提供一些异步周期执行的接口(也可以只执行一次),可以指定某个函数在规定的时间异步的执行,就像 LIBC 中的 timer 定时器,但是这里的定时器需要应用程序在主循环中周期调用
rte_timer_manage来使定时器得到执行,使用起来没有那么方便。定时器组件的时间参考来自 EAL 层提供的时间接口。 - Flow Classification API:通过 Intel SSE 基于多元组实现了高效的 hash 算法,以便快速的将数据包进行分类处理。该 API 一般用于路由查找过程中的最长前缀匹配中,安全产品中根据 DataFlow 五元组来标记不同用户的场景也可以使用。
平台相关模块:其内部模块主要包括 KNI、能耗管理以及 IVSHMEM 接口。其中,KNI 模块主要通过 kni.ko 模块将数据报文从用户态传递给内核态协议栈处理,以便用户进程使用传统的 Socket 接口对相关报文进行处理;能耗管理则提供了一些 API,应用程序可以根据收包速率动态调整处理器频率或进入处理器的不同休眠状态;另外,IVSHMEM 模块提供了虚拟机与虚拟机之间,或者虚拟机与主机之间的零拷贝共享内存机制,当 DPDK 程序运行时,IVSHMEM 模块会调用核心部件库 API,把几个 HugePage 映射为一个 IVSHMEM 设备池,并通过参数传递给 QEMU,这样,就实现了虚拟机之间的零拷贝内存共享。
轮询模式驱动模块:PMD 相关 API 实现了在轮询方式下进行网卡报文收发,避免了常规报文处理方法中因采用中断方式造成的响应延迟,极大提升了网卡收发性能。此外,该模块还同时支持物理和虚拟化两种网络接口,从仅仅支持 Intel 网卡,发展到支持 Cisco、Broadcom、Mellanox、Chelsio 等整个行业生态系统,以及基于 KVM、VMWARE、 XEN 等虚拟化网络接口的支持。
- PMD(Poll Mode Drivers):实现了 Intel 1GbE、10GbE 和 40GbE 网卡下基于轮询收发包的工作模式,大大加速网卡收发包性能。
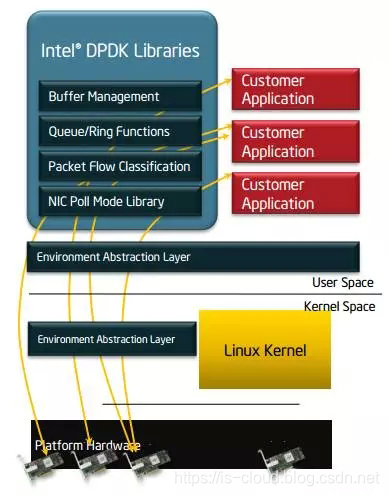
DPDK 核心组件
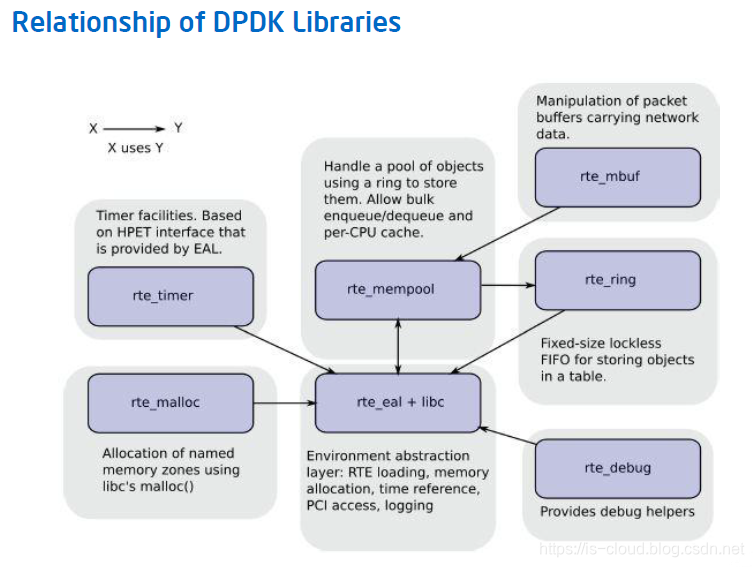
Memory Manager(librte_malloc,内存管理器):提供一组 API,用于从 HugePages 创建的 memzones 中分配内存而不是在堆中分配。这有助于改善 Linux 用户态环境下典型的从堆中大量分配 4KB 页面而容易引起 TLB miss。
Ring Manager(librte_ring,环形队列管理器):在一个有限大小的页表中,Ring 数据结构提供了一个无锁的多生产者,多消费者的 FIFO API。相较于无锁队列,它有一些的优势,如:更容易实现,适应于大容量操作,而且速度更快。 Ring 在 Memory Pool Manager 中被使用,而且 Ring 还用于不同 Core 之间或是 Processor 上处理单元之间的通信。
Memory Pool Manager(librte_mempool,内存池管理器):内存池管理器负责分配的内存中的 Pool 对象。Pool 由名称唯一标识,并使用一个 Ring 来存储空闲对象。它提供了其他一些可选的服务,例如:每个 Core 的对象缓存和对齐方式帮助器,以确保将填充的对象在所有内存通道上均匀分布。
Network Packet Buffer Management(librte_mbuf,网络报文缓冲管理):提供了创建和销毁数据包缓冲区的能力。DPDK 应用程序中可以使用这些缓存区来存储消息。应用程序通常在启动时通过 DPDK 的 Memory Pool Manager 库创建并存储。
Timer Manager(librte_timer,定时器管理):为 DPDK 执行单元提供了定时服务,为函数异步执行提供支持。定时器可以设置周期调用或只调用一次。应用程序可以使用 EAL 提供的接口获取高精度时钟,并且能在每个核上根据需要进行初始化。
注:
- RTE:Run-Time Environment
- EAL:Environment Abstraction Layer
- PMD:Poll-Mode Driver
应用 NUMA 亲和性技术减少跨 NUMA 内存访问
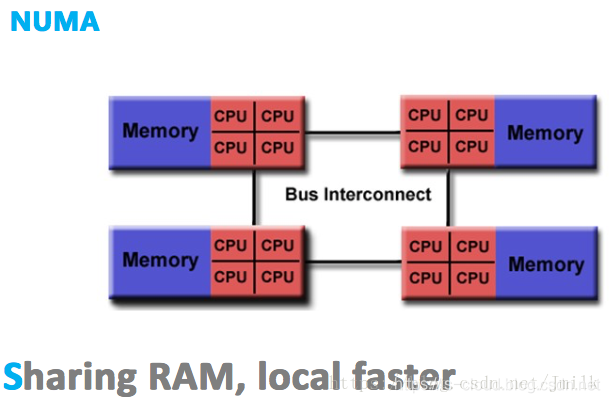
在 NUMA(Non-Uniform Memory Access,非一致性存储器访问)架构的处理机中,CPU 访问本地内存(同 NUMA)和远程内存(跨 NUMA)的耗时并不相同,NUMA “非一致性存储器访问” 架构由此得名。
NUMA 的结构设计能够在一定程度上解决 SMP 低存储器访问带宽的问题。假如一个 4 NUMA 节点的系统,每一个 NUMA 节点内部都具有 1GB/s 的存储带宽,外部共享总线也同样具有 1GB/s 的带宽。理想状态下,如果所有的 CPU 总是访问本地内存的话,那么系统就拥有了 4GB/s 的存储带宽能力。此时的每个 NUA 节点都可以近似的看作为一个 SMP(这种假设为了便于理解,并不完全正确);相反,在最不理想的情况下,如果所有处理器总是访问远程内存的话,那么系统就只能有 1GB/s 的存储器访问带宽。
除此之外,使用外部共享总线时可能会触发 NUMA 节点间的 Cache 同步损耗,这会严重影响内存密集型工作负载的性能。当 I/O 性能至关重要时,外部共享总线上的 Cache 资源浪费,会让连接到远程 PCIe 总线上的设备(不同 NUMA 节点间通信)作业性能急剧下降。
由于这个特性,基于 NUMA 架构开发的应用程序应该尽可能避免跨 NUMA 节点的远程内存访问。因为,跨节点内存访问不仅通信速度慢,还可能需要处理不同节点间内存、缓存的数据一致性问题。多线程在不同 NUMA 节点间的切换,是需要花费大成本的。
应用 CPU 绑核技术减少上下文切换损耗
现代操作系统都是基于分时调用方式来实现任务调度,多个进程或线程在多核处理器的某一个核上不断地交替执行。每次切换过程,都需要将处理器的状态寄存器保存在堆栈中,并恢复当前进程的状态信息,这对系统其实是一种处理开销。将一个线程固定一个核上运行,可以消除切换带来的额外开销。另外将进程或者线程迁移到多核处理器的其它核上进行运行时,处理器缓存中的数据也需要进行清除,导致处理器缓存的利用效果降低
CPU 亲和技术,就是将某个进程或者线程绑定到特定的一个或者多个核上执行,而不被迁移到其它核上运行,这样就保证了专用程序的性能。DPDK 使用了 Linux pthread 库,在系统中把相应的线程和 CPU 进行亲和性绑定,然后相应的线程尽可能使用独立的资源进行相关的数据处理。
应用大页内存技术减少 TLB miss
处理器的内存管理包含两个概念:物理内存和虚拟内存。Linux 操作系统里面整个物理内存按帧(Frames)来进行管理,虚拟内存按照页(Page)来进行管理。内存管理单元(MMU)完成从虚拟内存地址到物理内存地址的转换。内存管理单元进行地址转换需要的信息保存在
一个叫页表(Page Table)的数据结构里面,页表查找是一种极其耗时的操作。为了减少页表的查找过程,Intel 处理器实现了一块缓存来保存查找结果,这块缓存被称为 TLB(Translation Lookaside Buffer),它保存了虚拟地址到物理地址的映射关系。所有虚拟地址在转换为物理地址以前,处理器会首先在 TLB 中查找是否已经存在有效的映射关系,如果没有发现有效的映射,也就是 TLS miss,处理器再进行页表的查找。页表的查找过程对性能影响极大,因此需要尽量减少 TLB miss 的发生。
x86 处理器硬件在缺省配置下,页的大小是 4K,但也可以支持更大的页表尺寸,例如 2M 或 1G 的页表。使用了大页表功能后,一个 TLB 表项可以指向更大的内存区域,这样可以大幅减少 TLB miss 的发生。早期的 Linux 并没有利用 x86 硬件提供的大页表功能,仅在 Linux 内核 2.6.33 以后的版本,应用软件才可以使用大页表功能。DPDK 则利用大页技术,所有的内存都是从 HugePage 里分配,实现对内存池(Mempool)的管理,并预先分配好同样大小的 mbuf,供每一个数据包使用。
DPDK 目前支持了 2M 和 1G 两种 HugePage。通过编辑 /etc/grub.conf 来设置:
default_hugepagesz=1G hugepagesz=1G hugepages=32 isolcpus=0-22
然后,执行下述指令,将 HugePage 文件系统 hugetlbfs 挂载到 /mnt/huge 目录:
mount –t hugetlbfs nodev /mnt/huge
如此,用户进程就可以使用 mmap() 系统调用映射 HugePage 目标文件来使用大页面了。测试表明应用程序使用大页表比使用 4K 的小页表性能提高 10%~15%。
NOTE:大页内存的具体介绍可以参见 Linux 的大页表文件系统(hugetlbfs)特性。
应用 PMD 轮询技术减少网卡外设的硬件中断
传统网卡的报文接收/发送过程中,网卡硬件收到网络报文,或发送完网络报文后,需要发送中断到 CPU,通知应用软件有网络报文需要处理。在 x86 处理器上,一次中断处理需要将处理器的状态寄存器保存到堆栈,并运行中断服务程序,最后再将保存的状态寄存器信息从堆栈中恢复。整个过程需要至少 300 个处理器时钟周期。对于高性能网络处理应用,频繁的中断处理开销极大降低了网络应用程序的性能。
为了减少中断处理开销,DPDK 使用了轮询技术来处理网络报文,网卡收到报文后,可以借助 DDIO(Direct Data I/O)技术直接将报文保存到处理器 Cache 中,或者保存到内存中(没有 DDIO 技术的情况下),并设置报文到达的标志位。应用软件则周期性地轮询报文到达的标志位,检测是否有新报文需要处理。整个过程中完全没有中断处理过程,因此应用程序的网络报文处理能力得以极大提升。
针对 Intel 网卡,DPDK 实现了基于轮询方式的 PMD(Poll Mode Drivers)网卡驱动。该驱动由 API、用户空间运行的驱动程序构成,除了链路状态通知仍必须采用中断方式以外,均使用无中断方式直接操作网卡的接收和发送队列。目前 PMD 驱动支持 Intel 的大部分 1G、10G 和 40G 的网卡。
PMD 驱动从网卡上接收到数据包后,会直接通过 DMA 方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。
应用 UIO 和内存池技术减少内存拷贝
如果让 Linux 来处理收包过程,首先网卡通过中断方式通知内核协议栈对数据包进行处理,内核协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否本机的 Socket,满足条件则会将数据包拷贝一份向上递交给用户态 Socket 来处理,不仅处理路径冗长,还需要从内核到应用层的一次拷贝过程。
DPDK 则利用 UIO 技术,提供了应用空间下 PMD 驱动程序的支持,也就是说网卡驱动直接就是运行在用户空间的,减下了报文在用户空间和应用空间的多次拷贝。
DPDK 还在用户空间实现了一套精巧的内存池技术,内核空间和用户空间的内存交互不进行拷贝,只做控制权转移。这样,当收发数据包时,就减少了内存拷贝的开销。
应用无锁循环队列较少锁操作对 CPU 的开销
DPDK 基于 Linux 内核的无锁环形缓冲 kfifo 实现了一套自己的无锁机制。支持单生产者入列/单消费者出列和多生产者入列/多消费者出列操作,在数据传输的时候,降低性能的同时还能保证数据的同步。
DPDK 优化技术
DPDK 优化技术指在 DPDK 应用过程中,为进一步提高各类用户应用程序的转发性能,所采取的性能调优方法和关键配置。
DPDK 性能影响因素
本节主要介绍基于 DPDK 进行应用开发和环境配置时,应用程序性能的影响因素以及相应的优化调整方法。这些因素并非必然劣化性能,可能因硬件能力、OS 版本、各类软硬环境参数配置等的差异产生较大波动,或者存在较大的不稳定性,相关的调优方法需要用户结合自身的 VNF 应用部署在实践中不断完善。
硬件结构的影响
DPDK 具有广泛的平台适应性,可以运行在整个 x86 平台,从主流服务器平台(从高性能或者高能效产品系列),到桌面或者嵌入式平台,也可以运行于基于 Power 或者其他架构的运算平台。下图展示了一个通用双路服务器的内部架构,它包含了 2 个中央处理器,2 个分离的内存控制单元来连接系统内存,芯片组会扩展出大量高速的 PCIe 2.0/3.0 接口,用于连接外设,如 10Gbps 或者 25Gbps 网卡外设。
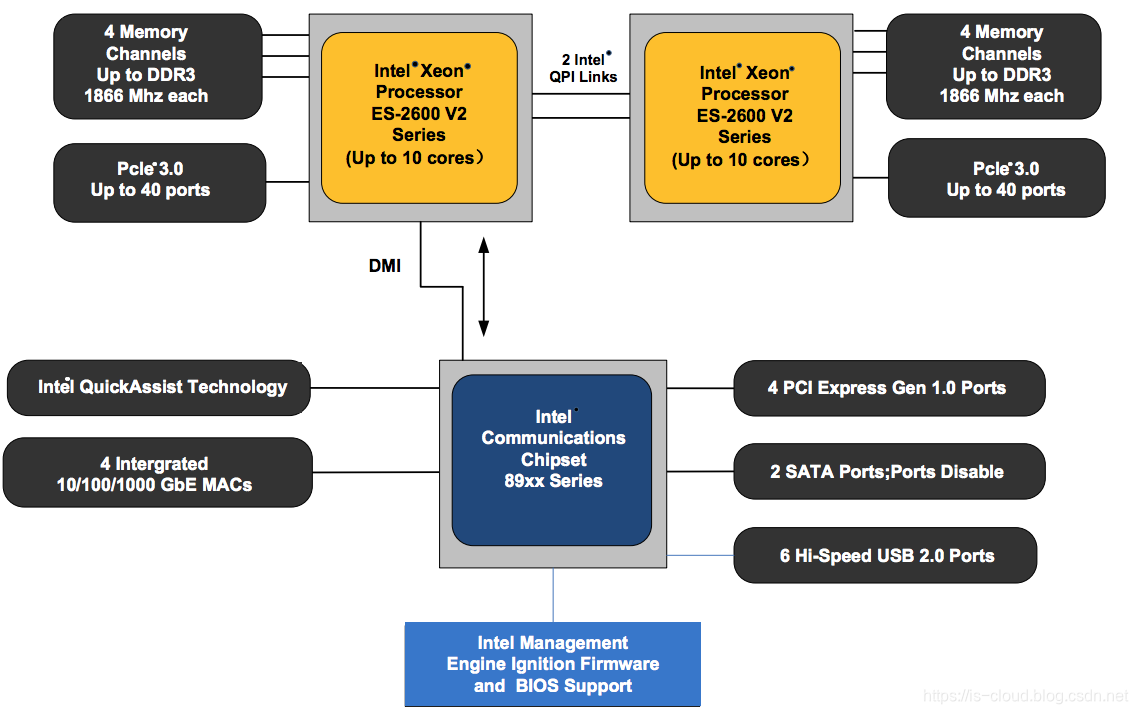
硬件规格对 DPDK 性能的影响体现在几个方面:
- CPU 频率:CPU 频率越高,DPDK 性能越高。
- LLC(Last Leve Cache)大小:缓存越大,DPDK 性能越高。
- PCIe Lane 的数目:PCIe 链路可以支持 1、2、4、8、12、16 和 32 个 Lane,需要确保其带宽可以满足所插网卡的带宽。
- NUMA:网络数据报文的处理由网卡所在的 NUMA 节点处理,将会比远端 NUMA 节点处理的性能更高。
OS 版本及其内核的影响
不同的 Linux OS 发行版使用的 Linux 内核版本不一样,配置的 Linux OS 服务也不一样。这些差异都会导致应用程序在网络报文处理能力上有所差别。由于 Linux 内核还在不断演进,Linux 的发行版也数量众多,同样的硬件配置环境下,不同的 Linux 发行版在小包的处理能力上存在差异。本文无法提供最佳 Linux 内核版本和配置,而只能给出部分参考建议,如:关闭部分 OS 服务。
OVS 性能问题
OVS 作为 NFV 的一个重要组成模块,会运行在绝大多数的服务器节点上,提供虚拟机和虚拟机之间,以及虚拟网络和物理网络间的互连接口,其性能至关重要。OVS 2.4 开始正式支持 DPDK 加速,相比传统基于 Linux 内核的 OVS 版本,转发性能提高了数倍,为 VNF 在通用 x86 服务器上部署提供了有力支持。
OVS 缺省会为每一个 NUMA 节点创建一个 pmd 线程,该 pmd 线程以轮询方式处理属于其 NUMA 节点上的所有 DPDK 接口。为了高性能,需要利用前面提到的 CPU 绑核技术,把 pmd 线程绑定在一个固定的 CPU core 上处理。此外,为了增加扩展性,OVS 2.4 也支持网卡多队列以及多 pmd 线程数,这些参数均可动态配置,但具体配置应根据具体需求来决定。
内存管理
如前所述,DPDK 考虑了 NUMA 以及多内存通道的访问效率,会在系统运行前要求配置 Linux 的 HugePage,初始化时申请其内存池,用于 DPDK 运行的主要内存资源。Linux 大页机制利用了处理器核上的的 TLB 的 HugePage 表项,这可以减少内存地址转换的开销。
CPU 核间无锁通信
如果想建立一个基于消息传递的核间通信机制,可以使用 DPDK Ring API,它是一个无锁的 ring 实现。该 Ring 机制支持批量和突发访问,即使同时读取几个对象,也只需要一个昂贵的原子操作,批量访问可以极大地改善性能。
设置正确的目标 CPU 类型与模式
DPDK 支持 CPU 微架构级别的优化,可以通过修改 DPDK 配置文件中的 CONFIG_RTE_MACHINE 参数来定义。优化的程度根据随编译器的能力而不同,通常建议采用最新的编译器进行编译。如果编译器的版本不支持该款 CPU 的特性,比如 Intel AVX 指令,那么它在编译时只会选用自己支持的指令集,这可能导致编译后生成的 DPDK 应用的性能下降。
优化方案
笔者在 DPDK 的优化方面的实践因为商业敏感的问题,本文不便提及。网上有很多资料,推荐阅读这一篇文章 https://zhaozhanxu.com/2016/08/09/DPDK/2016-08-09-dpdk-optimization/ 和《DPDK 技术白皮书》。
DPDK 在 NFV 中的应用
ETSI NFV 技术通过运行在通用 x86 架构硬件上的虚拟化网络功能,为电信运营商和互联网服务商提供了一种灵活的业务部署手段和高效的组网方案,可以支持固移网络和 IDC 中 NAT、DPI、EPC、FW 等各类业务功能的广域灵活部署与网元弹性扩展。
不同于典型数据中心业务和企业网业务,电信广域网业务要求网元(如 BNG、DPI 等)具有高吞吐、低时延、海量流表支持、用户级 QoS 控制的特点。大量实践表明,通用 x86 服务器作为 NFV 基础设施用于高转发业务时,面临着严重的转发性能瓶颈,需要有针对性地从硬件架构、系统 I/O、操作系统、虚拟化层、组网与流量调度、VNF 功能等层面进行性能优化,才能达到各类 NFV 网络业务的高性能转发要求。
根据 ETSI 的 NFV 参考架构,现实中的 NFV 应用系统一般由 NFV 基础设施和 VNF 两类系统服务商提供。因此,相应的 NFV 端到端性能测试,也应划分为底层的 NFV 基础设施性能与上层的 VNF 性能两类,以明确各自的性能瓶颈,并避免性能调优工作相互干扰。
在 NFV 基础设施性能层面,由于采用软件转发和软件交换技术,单个物理服务器内部的转发能力是 NFV 系统的主要性能瓶颈。在各类高速转发的 NFV 应用中,数据报文从网卡中接收,再传送到虚拟化的用户态应用程序(VNF)处理。整个过程要经历 CPU 中断处理、虚拟化 I/O 与地址映射转换、虚拟交换层、内核协议栈、内核上下文切换、内存拷贝等多个费时的 CPU 操作和 I/O 处理环节。面对这样的性能损耗问题,业内通常采用消除海量中断、旁路内核协议栈、减少内存拷贝、CPU 多核任务分担、Intel VT 等技术来综合提升服务器数据平面的报文处理性能。但由于技术栈复杂,普通用户较难掌握,业界迫切需要一种综合的性能优化方案,同时提供良好的用户开发和商业集成环境。
在各类 NFV 基础设施性能优化技术方案中,DPDK 加速技术方案成为其中的典型代表。DPDK 以用户数据 I/O 通道优化为基础,结合了 Intel VT 技术、操作系统、虚拟化层与 vSwitch 等多种优化方案,已经形成了完善的性能加速整体架构,并提供了用户态 API 供高速转发类应用访问。

参考文章
https://vcpu.me/packet_from_nic_to_user_process/
https://blog.csdn.net/City_of_skey/article/details/85038684
https://blog.csdn.net/qq_15437629/article/details/78146823
https://zhaozhanxu.com/2016/08/09/DPDK/2016-08-09-dpdk-optimization/
https://mp.weixin.qq.com/s/RW0GO8hNxoE7upAeAExWHg
DPDK 网络加速在 NFV 中的应用的更多相关文章
- 利用1.1.1.1进行DNS网络加速,仅需2分钟让网络更快
NEWS 近日,Cloudflare 和 APNIC联合推出了1.1.1.1DNS网络加速. Cloudflare 运行全球规模最大.速度最快的网络之一.APNIC 是一个非营利组织,管理着亚太和大洋 ...
- cdn网络加速
CDN全称Content Delivery Network,即内容分发网络.其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快.更稳定.通过在网络各处放置节点服 ...
- [ipsec][strongswan] VirtualPN隧道网络加速FEC(forward error correction)
引用 跟一个网友就有关IPsec的网络加速以及降低延迟等问题进行了一些讨论,并总结了一写粗浅的看法. 因为FEC的资料并不多,所以分享出来,希望能被有需要的人看见:) 先说一下FEC. 我们使用ips ...
- 【HMS Core 6.0全球上线】Network Kit全链路网络加速技术,应用无惧网络拥塞
HMS Core 6.0已于7月15日全球上线,本次版本向广大开发者开放了众多全新能力与技术.其中HMS Core Network Kit开放了全链路网络加速技术,助力开发者为用户提供低时延的畅快网络 ...
- 阅读【现代网络技术 SDN/NFV/QOE 物联网和云计算】 第一章
本人打算阅读这本书来了解物联网和云计算的基础架构和设计原理.特作笔记如下: 作者: William Stallings 本书解决的主要问题: 由单一厂商例如IBM向企业或者个人提供IT产品和服务,包 ...
- 网络损伤仪WANsim中的时延的不同模型
网络损伤仪WANsim中的3种时延模型 时延指的是报文从网络的一端到达另一端所花费的时间. 网络损伤仪WANsim中为用户提供了3种时延损伤的模型.常量模型.均匀分布.正态分布. 这3种模型按照各自的 ...
- 网络损伤仪WANsim中关于丢包的介绍
网络损伤仪WANsim中的4种丢包模型 丢包是指在网络上传输的数据包无法到达指定目的地.丢包在广域网中是一个很常见的问题.想要模拟出真实的广域网环境,对丢包的精确模拟是必不可少的. 在网络损伤仪WAN ...
- 网络切片在5G中的应用
SDNLAB君 • 16-11-25 •1509 人围观 5G和网络切片 当5G被广泛提及的时候,网络切片是其中讨论最多的技术.像KT.SK Telecom.China Mobile.DT.KDDI. ...
- 网络虚拟化(SDN,NFV..)和企业骨干网的演化
本来昨天就规划了今天的这篇文章,无奈昨天中午自己喝了将近一瓶的52度二锅头...晚上想着今天怎么着也完了,要颓废难受一天了...没想到早上居然一点都不难受了.于是就写下了本文.正文之前,还是做个广告, ...
随机推荐
- DOS导出文件夹或文件名
dir /s /w >a.txt 应用dos导出当前目录下的文件夹名称(包括子目录,但是不包括文件,仅仅导出文件夹) dir /s/b/a:d >a.txt
- 一周死磕fastreport ----ASP.NET (二)
前一章忘了为什么要死磕fastreport 了,这次简单说一下, 公司本来有一个winfrom 窗体打印程序,可是上司觉得太麻烦了,(前几天 我一直在做web版看板,然后发现还不错,于是 想把公 ...
- Centos使用光盘yum源
yum查看所有源 yum repolist all 方法一:本机使用光盘源安装软件的设置 mkdir /media/cdrom mount /dev/cdrom /media/cdrom vim / ...
- Ubuntu下多个gcc版本之间的切换
Ubuntu下多个gcc版本之间的切换 1.查看当前系统的gcc版本 gcc -v 会输出以下信息: Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO ...
- Python---安装路径查看
python是解释型脚本语言,在执行时,逐句解释执行,不需要进行预编译.但需要有自身的Python解释器. 所以在执行Python代码时,需要指定python解释器. 指定解释器方法: 在文件开头 ...
- 关于create-react-app(react-scripts@3.3.0)升级的坑
今天用create-react-app my-app,看到下面的提示: A template was not provided. This is likely because you're using ...
- 零基础免费搭建个人博客-hexo+github
使用hexo生成静态博客并架设在免费的github page平台 准备 系统: Window 7 64位 使用软件: Git v1.9.5[下载地址] 百度云 360云盘 访问密码 d269 Git官 ...
- 计算机网络|C语言Socket编程,实现两个程序间的通信
C语言Socket编程,实现两个程序间的通信 server和client通信流程图 在mooc上找到的,使用Socket客户端client和服务端server通信的流程图
- .net core Areas区域
//使用MVC app.UseMvc(routes => { routes.MapRoute( name: "areas", template: "{area:ex ...
- 封装Vue组件的一些技巧
封装Vue组件的一些技巧 本文同步在个人博客shymean.com上,欢迎关注 写Vue有很长一段时间了,除了常规的业务开发之外,也应该思考和反思一下封装组件的正确方式.以弹窗组件为例,一种实现是在需 ...