[CDH] New project for ML pipeline
启动后台服务: [CDH] Cloudera's Distribution including Apache Hadoop
这里只介绍一些基本的流程,具体操作还是需要实践代码。
一、开发环境配置
JDK安装
Ref: Ubuntu安装jdk8的两种方式
(base) hadoop@unsw-ThinkPad-T490:jvm$ java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) -Bit Server VM (build 25.231-b11, mixed mode) (base) hadoop@unsw-ThinkPad-T490:jvm$ javac -version
javac 1.8.0_231
然后,Project Structure --> SDKs --> 配置为新jdk。
Scala插件安装
Setting --> Plugins
Maven更新
"Error:(5, 37) java: 程序包org.apache.ibatis.annotations不存在"
不要使用IDE内嵌的Maven,因为IDE内嵌的版本不一定一致,而版本不一致很容易导致构建行为的不一致。
项目Maven版本号在哪里体现?如何更新呢?
Goto: 修改Idea默认的maven版本
Spring-boot依赖

IDEA Cannot access alimaven (http://maven.aliyun.com/nexus/content/groups/public/)
可能有用,也可能没用。改为Settings --> maven --> Work offline
二、Maven和包依赖
Ref: Maven 教程
1. Maven POM
POM ( Project Object Model,项目对象模型 ) 是 Maven 工程的基本工作单元,是一个XML文件,包含了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。
执行任务或目标时,Maven 会在当前目录中查找 POM。它读取 POM,获取所需的配置信息,然后执行目标。
2. 新建项目以及模块
New Project --> maven
New Module --> maven // 若干模块可以拖拉到统一的文件夹内,相应的配置文件会自动编辑好。
然后根据如下模块图,依次添加模块。

建立模板代码,web作为“入口”。
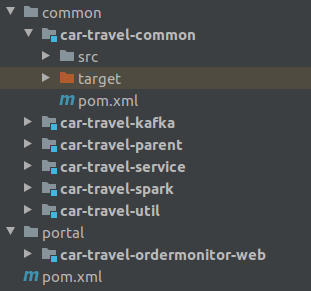
3. 模块 "配置" 文件
Spark相关的配置: pom.xml --> https://www.runoob.com/maven/maven-pom.html
(1) 基本要素样例
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd"> <!-- 模型版本 -->
<modelVersion>4.0.0</modelVersion>
<!-- 公司或者组织的唯一标志,并且配置时生成的路径也是由此生成, 如com.companyname.project-group,maven会将该项目打成的jar包放本地路径:/com/companyname/project-group -->
<groupId>com.companyname.project-group</groupId> <!-- 项目的唯一ID,一个groupId下面可能多个项目,就是靠artifactId来区分的 -->
<artifactId>project</artifactId> <!-- 版本号 -->
<version>1.0</version>
</project>
(2) 子模块"目录"
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>car-travel</groupId>
<artifactId>car-travel</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>car-travel-common</module>
</modules> </project>
(3) 子模块"内容"
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>car-travel</groupId>
<artifactId>car-travel-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../car-travel-parent/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion> <artifactId>car-travel-spark</artifactId> <dependencies>
<!--spark 离线任务 核心依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency> <!--spark 实时任务 核心依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>2.1.0</version>
</dependency> <!--spark streaming 和 kafka集成 的依赖配置-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency> <!--依赖本项目中的module开始-->
<dependency>
<groupId>car-travel</groupId>
<artifactId>car-travel-util</artifactId>
<version>1.0-SNAPSHOT</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies> </project>
(4) 包依赖
Ref: Maven 引入外部依赖
Ref: Maven添加外部依赖【Maven无能为力,无法自动下载时】
Ref: maven可选依赖(Optional Dependencies)和依赖排除(Dependency Exclusions)
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.0.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
</exclusion>
</exclusions>
</dependency>
(5) Maven右边栏依赖检测
/* implement */
三、"测试" 子模块
这里若是 "测试spark模块" 的话,需要安装scala,使该模块支持Scala语言。

Spark环境配置的测试代码样例。
package spark.examples import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} class WordCount { } object WordCount {
def main(args: Array[String]): Unit = {
//1.创建spark的配置对象
val sparkConf = new SparkConf().setAppName("SparkWordCount").setMaster("local");
//2.创建spark context的上下文
val sc = new SparkContext(sparkConf); //3.使用spark上下文的api接口textFile读取文件形成spark数据处理模型RDD
val linesRDD: RDD[String] = sc.textFile("C:\\work_space\\car-travel\\common\\car-travel-spark\\src\\test\\scala\\words")
//4.对RDD每一行行进行分割(使用空格分割)
val wordArrayRdd = linesRDD.map(_.split(" "))
//5.分割完成之后,我们做一下扁平化,把多维集合转化为一维集合
val wordsRDD = wordArrayRdd.flatMap(x => x)
//6.单词计数,出现一次计数一个1
// val wordCount = wordsRDD.map((_,1))
val wordCount = wordsRDD.map(word => {
(word,1)
}) //7.最关键的一步就是对单词的所有计数进行汇总
()
val restCount = wordCount.reduceByKey(_ + _) restCount.foreach(println(_))
restCount.checkpoint()
restCount.persist()
sc.stop();
}
}
End.
[CDH] New project for ML pipeline的更多相关文章
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- spark ML pipeline 学习
一.pipeline 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出.这非常类似于流水线式工作,即通常会包含源数据ETL(抽取.转化.加载),数据预处理,指标提取,模型训练与 ...
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- spark ml pipeline构建机器学习任务
一.关于spark ml pipeline与机器学习一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的流 ...
- 使用 ML Pipeline 构建机器学习工作流
http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice5/
- Spark.ML之PipeLine学习笔记
地址: http://spark.apache.org/docs/2.0.0/ml-pipeline.html Spark PipeLine 是基于DataFrames的高层的API,可以方便用户 ...
- ML Pipelines管道
ML Pipelines管道 In this section, we introduce the concept of ML Pipelines. ML Pipelines provide a uni ...
- Spark ML机器学习
Spark提供了常用机器学习算法的实现, 封装于spark.ml和spark.mllib中. spark.mllib是基于RDD的机器学习库, spark.ml是基于DataFrame的机器学习库. ...
- Spark的MLlib和ML库的区别
机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.其目标是使实际的机器学习可扩展和容易.在高层次上,它提供了如下工具: ML算法:通用学习算法,如分类,回归,聚类和协同过滤 特 ...
随机推荐
- Hadoop_33_Hadoop HA的搭建
Hadoop HA的搭建,可参考链接:https://blog.csdn.net/mrbcy/article/details/64939623 说明: 1.在hadoop2.0中通常由两个Nam ...
- kotlin字符串比较&空值处理&when表达式
字符串比较: 字符串的比较也是实际中比较常见的,下面来看下它的比较跟java中有啥不同,下面走起! 如我们所预期,其结果: 下面再来: 如果是java,结果肯定是为false,因为"==&q ...
- 关于从入 OI 以来学的各种知识点的系统总结
前言 OI 之路差不多快结束了,最近水平也萎得很厉害,这里就开个目录,记录一些需要总结的知识点吧.不定期更,勿催,我还要改模拟赛的题. 目录
- python_模块1
1.将指定的字符串进行加密 # 导入模块 import hashlib def get_md5(data): # 获取hashlib模块中的md5加密算法 obj = hashlib.md5() # ...
- mongodb的安装与使用(二)之 增删改查与索引
0.MongoDB数据库和集合创建与删除 MongoDB 创建数据库 语法: use DATABASE_NAME note:查看所有数据库使用show dbs 创建的空数据库 test并不在数据库的列 ...
- git + idea 配置 github设置ssh免登陆方式提交拉取代码
1.下载安装git,官网:https://git-scm.com/download/win 安装默认配置安装 git2.20版本地址百度网盘地址: 链接:https://pan.baidu.com/ ...
- Semantic 导航条
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> ...
- 【转】css样式的书写顺序及原理——很重要!
记得刚开始学习前端的时候,每次写css样式都是用到什么就在样式表后添加什么,完全没有考虑到样式属性的书写顺序对网页加载代码的影响.后来逐渐才知道正确的样式顺序不仅易于查看,并且也属于css样式优化的一 ...
- Educational Codeforces Round 33 (Rated for Div. 2) D题 【贪心:前缀和+后缀最值好题】
D. Credit Card Recenlty Luba got a credit card and started to use it. Let's consider n consecutive d ...
- javascript JSON.parse and JSON.stringify
var jstu = '{"name": "xiaoqiang", "age": 18}'; console.log(jstu); var ...