ElasticSearch——分词
前言:
最近在使用elasticSearch中发现有些数据查不出来,于是研究了一下,发现是分词导致的,现梳理并总结一下。
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
ElasticSearch字符串将默认被同时映射成text和keyword类型,将会自动创建下面的动态映射(dynamic mappings):
"relateId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
这就是造成部分字段还会自动生成一个与之对应的“.keyword”字段的原因。
存储查询示例:
relateId存储:20191101R672499460503 1个值
relateId.keyword存储:20191101 R 672499460503 3个值
这时用relateId进行精确查询,查不出数据,因为已经被分成3个词了:
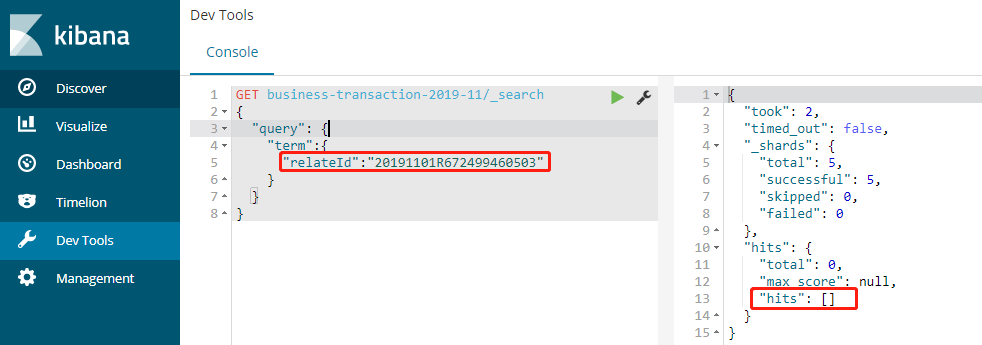
用relateId.keyword进行精确查询则可以查出数据来:
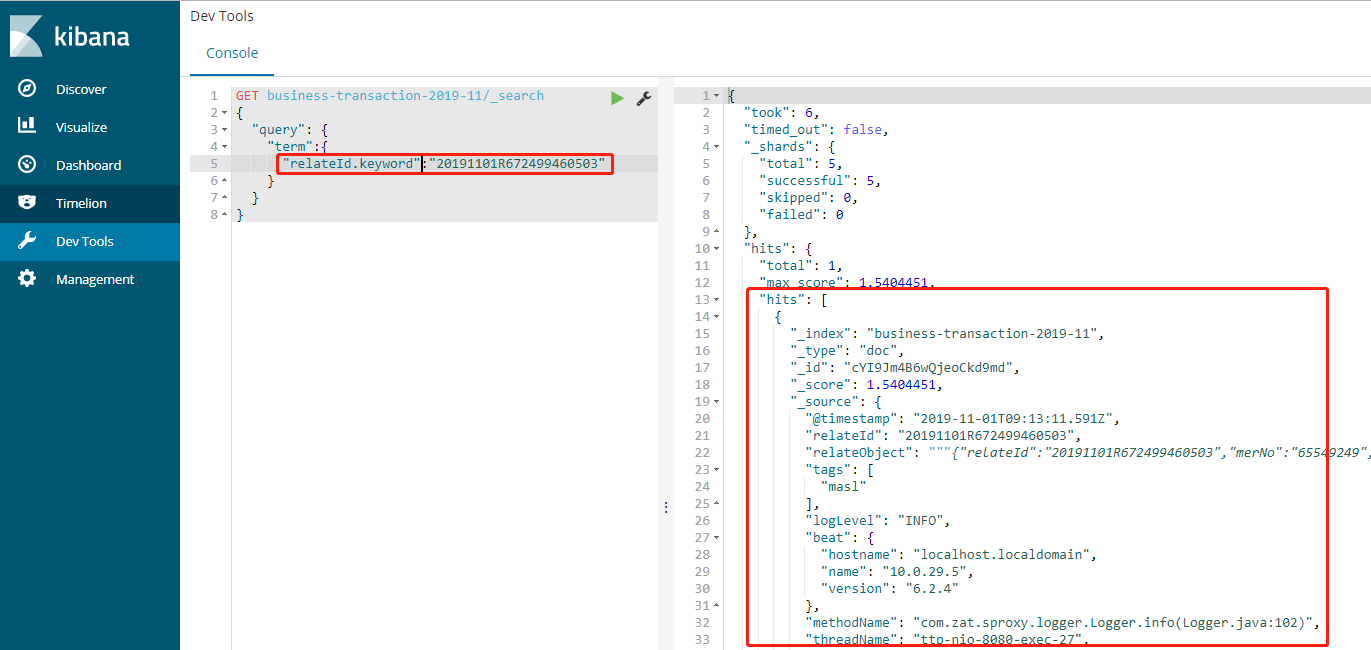
两者比较:
Text:默认会分词,然后进行索引,支持模糊、精确查询,不支持聚合
keyword:不进行分词,直接索引,支持模糊、精确查询,支持聚合
进阶处理:
注意:Text默认会分词,这是很智能的,但在有些字段里面是没用的,所以对于有些字段使用text则浪费了空间。这时可以设置mapping为not analyzied,让它不分词。
"relateId": {
"type": "text",
"index": "not_analyzed"
}
如果要指定分词则用下面的方式:
"relateId": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above":
}
}
}
ElasticSearch——分词的更多相关文章
- Elasticsearch——分词器对String的作用
更多内容参考:Elasticsearch学习总结 关于String类型--分词与不分词 在Elasticsearch中String是最基本的数据类型,如果不是数字或者标准格式的日期等这种很明显的类型, ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
- elasticsearch分词器Jcseg安装手册
Jcseg是什么? Jcseg是基于mmseg算法的一个轻量级中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于Jetty的web服务器,方便各大语言 ...
- Elasticsearch 分词器
无论是内置的分析器(analyzer),还是自定义的分析器(analyzer),都由三种构件块组成的:character filters , tokenizers , token filters. 内 ...
- elasticsearch分词器ik
1. 下载和es配套的版本 git clone https://github.com/medcl/elasticsearch-analysis-ik 2. 编译 cd elasticsearch-an ...
- Elasticsearch分词导致的查找错误
这周在做视频搜索的过程中遇到一个问题,就是用下面的查询表达式去Elasticsearch检索,检索不到想要的结果.查询语句如下: 而查询的字段的值为: "mergeVideoName&quo ...
- ElasticSearch分词器
什么是分词器? 分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具.到目前为止呢,分词器没有办法做到完全的符合人们的要求.和我们有关的分词器有英文的和中文的.英文的分词器过程:输入文本-关键词切 ...
- 掌握 analyze API,一举搞定 Elasticsearch 分词难题
初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,比如如下这些场景: 为什么明明有包含搜索关键词的文档,但结果里面就没有相关文档呢? 我存进去的文档到底被分成哪些词(term)了? ...
- ElasticSearch 分词器,了解一下
这篇文章主要来介绍下什么是 Analysis ,什么是分词器,以及 ElasticSearch 自带的分词器是怎么工作的,最后会介绍下中文分词是怎么做的. 首先来说下什么是 Analysis: 什么是 ...
随机推荐
- h5 特效
地址:http://www.cnblogs.com/sun927/p/5842852.html 几个别人总结的css3炫酷效果,有需要直接拿来用即可,包括以下几个效果: 1.悬浮时放大 2.悬浮时转一 ...
- iFrame跨域的方式
4种通过iframe跨域与其他页面通信的方式 不同域下的iframe不能进行操作. 1.location.hash: 在url中,http://www.baidu.com#helloword的#hel ...
- C# 之 .net core -- EF code first连接Mysql数据库
一.在Models 新建两个数据库类 这个是数据库需要生成的类基础(塑造外观) public class User { [Key] public string ID { get; set; } [Ma ...
- solrcloud2
分片的原因 由于底层Lucene的限制,每个solr索引中包含的文档数不能超过231个,大约是21亿个.但是solr分片一般不是基于这个的原因,因为一般没有到这个峰值的之后,solr的各中性能问题就暴 ...
- Linux初始化脚本
以下脚本用于linux系统的初始化脚本,可以在服务器系统安装完毕之后立即执行.脚本结合各位大牛一些参数,已经在CentOS 5下通过. 使用方法:将其复制,保存为一个shell文件,比如init.sh ...
- ubuntu nginx 启动多个Django项目
1.将 /etc/nginx/sites-enabled/ 目录下的nginx默认配置文件default,重命名,例如:default1 2.给每个Django项目添加nginx.conf配置文件,建 ...
- Java8-Stream-No.09
import java.util.Arrays; public class Streams9 { public static void main(String[] args) { Arrays.asL ...
- CodeForces 839D - Winter is here | Codeforces Round #428 (Div. 2)
赛后听 Forever97 讲的思路,强的一匹- - /* CodeForces 839D - Winter is here [ 数论,容斥 ] | Codeforces Round #428 (Di ...
- spring-boot web项目常用配置
一.对用户输入query参数过滤空字符串 使用 WebBindingInitializer 来对string类型参数进行过滤,但是这种方式只能处理query参数不能处理body参数 代码例子: /** ...
- MSMQ使用
Message Message是MSMQ的数据存储单元,我们的用户数据一般也被填充在Message的body当中,因此很重要,让我们来看一看其在.net中的体现,如图: 在图上我们可以看见,Messa ...