MongoDB Input
Configure Connection Tab
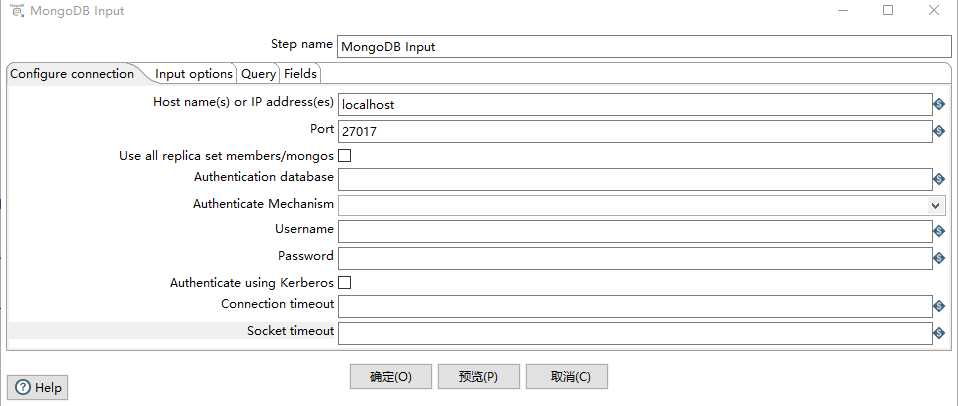
Host name(s) or IP address(es):网络名称或者地址。可以输入多个主机名或IP地址,用逗号分隔。还可以通过将主机名和端口号与冒号分隔开,为每个主机名指定不同的端口号,并将主机名和端口号的组合与逗号分隔开。例如,要为两个不同的MongoDB实例包含主机名和端口号,您将输入localhost 1:27017,localhost 2:27018,并使端口字段为空
Use all replica set members/mongos:
Port:端口号
Username:用户名
Password:密码
Authenticate using Kerberos:指示是否使用Kerberos服务来管理身份验证过程。
Connection timeout:连接超时时间(毫秒)
Socket timeout:等待写操作(以毫秒为单位)的时间
Input Options Tab
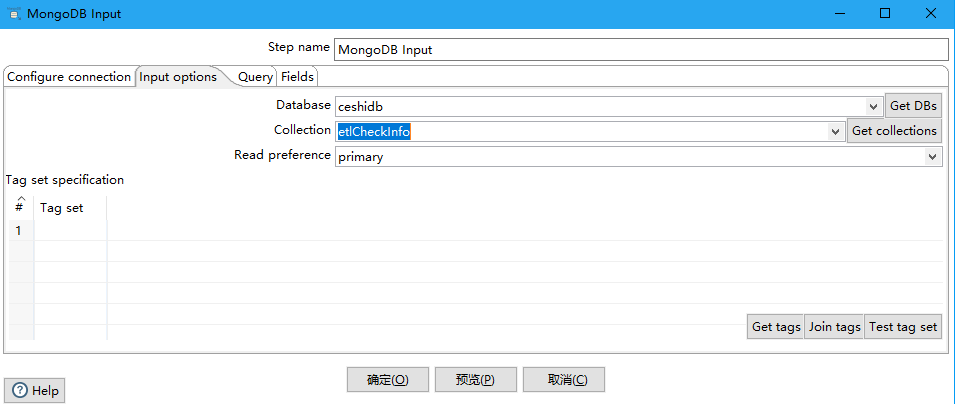
Database:检索数据的数据库的名称。单击Get DBs以在服务器上的数据库列表填充下拉菜单。
Collection:集合名称。点击 Get collections以在数据库中包含一个集合列表来填充下拉菜单
Read preference:表示要先读取哪个节点
Tag set specification/#/Tag Set:标签允许您自定义写关注和读取副本的首选项
Query Tab
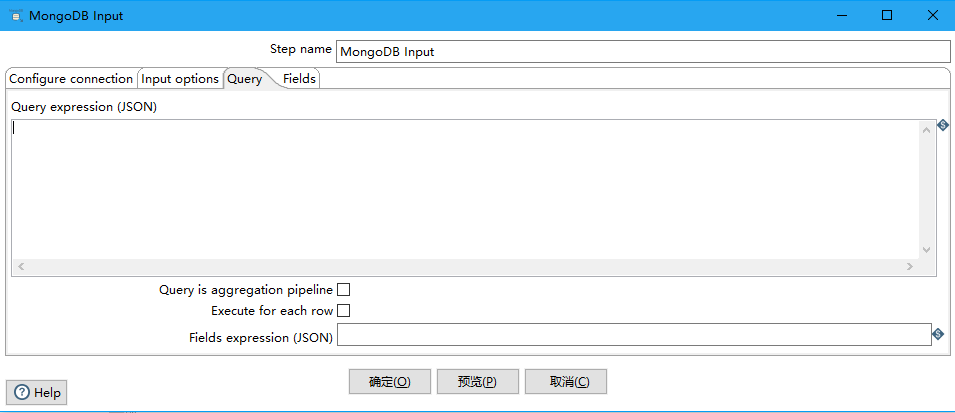
查询选项卡使您能够改进读请求。这个选项卡以两种不同的模式运行。您可以使用JSON查询表达式或使用聚合框架来创建查询。默认情况下,查询选项卡是JSON查询表达式模式。您可以输入一个JSON查询表达式。当选Query is aggregation pipeline 的时候,使用聚合表达式查询,是一种类似与json的查询语言。
Query expression (JSON):查询表达式(JSON)(Query is aggregation pipeline没被选择的情况下)
{ name : "MongoDB" } 或者{ name : { '$regex' : "m.*", '$options' : "i" } }
Query is aggregation pipeline:将多个JSON表达式连接在一起,立即执行。聚合管道将几个JSON表达式串在一起,前面的表达式的输出将成为下一个表达式的输入。
Aggregation pipeline specification (JSON):聚合管道规范(JSON)(Query is aggregation pipeline被选择)
{ $match : {state : "FL", city : "ORLANDO" } }, {$sort : {pop : -1 } }或者{ $group : { _id: "$state"} }, { $sort : { _id : 1 } }
Execute for each row:对每一行数据执行查询
Fields expression (JSON):Query is aggregation pipeline没被选中时候有效,控制字段返回
MongoDB Input的更多相关文章
- kettle之mongodb数据同步
需求: 1.源数据库新增一条记录,目标库同时新增一条记录: 2.源数据库修改一条记录,目标库同时修改该条记录: 示例用到三个Kettle组件 下面详细说下每个组件的配置 Source: 本示例连接的是 ...
- Scala spark mongodb
最好的参考是Mongo官网的地址 https://docs.mongodb.com/spark-connector/getting-started/ 需要截图所示的包 代码地址 https://git ...
- Spark连接MongoDB之Scala
MongoDB Connector for Spark Spark Connector Scala Guide spark-shell --jars "mongo-spark-connect ...
- MongoDB With Spark遇到的2个错误,不能初始化和sample重复的key
1.$sample stage could not find a non-duplicate document while using a random cursor 这个问题比较难解决,因为我用mo ...
- Scala2.11.8 spark2.3.1 mongodb connector 2.3.0
import java.sql.DriverManager import com.mongodb.spark._ import org.apache.spark.SparkConf import or ...
- spark读取mongodb数据写入hive表中
一 环境: spark-: hive-; scala-; hadoop--cdh-; jdk-1.8; mongodb-2.4.10; 二.数据情况: MongoDB数据格式{ "_i ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
- pyspark mongodb yarn
from pyspark.sql import SparkSession my_spark = SparkSession \ .builder \ .appName("myApp" ...
- Mongodb——文档数据库
mongodb是一个文档数据库. mongo操作 多个修改操作,但每个修改携带的数据包较小,可操作考虑批量操作.bulkWrite()改善性能. MongoCollection是线程安全的. db.c ...
随机推荐
- 【收藏】linux快速查找文件的技巧
有时候,我们需要在系统中查找文件,Linux有一个非常优秀的搜寻系统. 一般提到搜寻文件的时候,很多人第一反应是find命令,但其实find不是常用的,因为速度慢,而且毁硬盘.一般我们都先用where ...
- Tenka1 Programmer Contest 2019 D - Three Colors
Three Colors 思路:dp 设sum为所有边的总和 不能组成三角形的情况:某条边长度>=ceil(sum/2),可以用dp求出这种情况的方案数,然后用总方案数减去就可以求出答案. 注意 ...
- iotop命令详解
iotop是top和iostat程序的混合体,能够显示系统中所有运行进程并将进程根据I/O统计信息排序. 这个软件使用了Linux内核的一些新特性,所以需要2.6.20或者更新的内核. 一般默认情况下 ...
- Python3下UnicodeDecodeError:‘ASCII’ codec cant decode..(128)
今天准备用Keras跑一下LeNet的程序,结果总是编码出错 源代码是2.7写的,编码格式是utf-8.然后尝试网上各种方法不适用,最后还是解决了 源代码: data = gzip.open(r'C: ...
- pandas df 遍历行方法
pandas 遍历有以下三种访法. iterrows():在单独的变量中返回索引和行项目,但显着较慢 itertuples():快于.iterrows(),但将索引与行项目一起返回,ir [0]是索引 ...
- .net System.Net.Mail 之用SmtpClient发送邮件Demo
private static bool sendMail() { try { //接收人邮箱 string SendTo = "XXXXX@163.com ...
- WebApiHelper
/// <summary> /// 根据token过滤 /// </summary> /// <param name="list"></p ...
- @Import注解的作用
在@Import注解的参数中可以填写类名,例如@Import(Abc.class),根据类Abc的不同类型,spring容器有以下四种处理方式: 1. 如果Abc类实现了ImportSelector接 ...
- python 3列表推导式的的一点理解!
python 3列表推导式的的一点理解! Python的列表推导式对于新手来说一般都难以理解,简单看个例子: [x * x for x in range(1,100)] 上面是一个很简单的列表推导式, ...
- CF732D Exams 二分 贪心
思路:二分+贪心 提交次数:10次以上 错因:刚开始以为二分(边界,$+1or-1$)写错了,调了半天,后来才发现是$ck()$写错了.开始只判了最后是否小于零,而应该中间一旦小于零就$return\ ...