计算广告(5)----query意图识别
目录:
(1)基于规则
(2)基于穷举
(3)基于分类模型
query纠错、【query rewrite】
query 词自动提示、【query相关性计算】
query扩展,【query相关性计算】
query自动分类、【query类目预测】
语义标签。【query tagging】
一、简介:
1、概念:
什么是用户意图识别?
就是让搜索引擎能够识别出与用户输入的查询最相关的信息,例如用户输入查询“仙剑奇侠传”时,我们知道“仙剑奇侠传”既有游戏又有电视剧还有新闻、图片等等,如果我们通过用户意图识别发现该用户是想看“仙剑奇侠传”电视剧的,那我们直接把电视剧作为结果返回给用户,就会节省用户的搜索点击次数,缩短搜索时间,大大提升使用体验。
意识识别要做什么?(分类)
比如在我们熟悉的搜索,我们搜索的时候如果涉及到一条信息对应多个分类的时候,这样搜索结果会比较差,但是如果我们通过意图识别发现用户是个游戏迷,我们就可以在用户搜索时将游戏的搜索结果优先返还给用户,这本身也是很有意义的一件事。
通用搜索和垂直搜索:
通用搜索是抓取互联网上的页面,以索引和关键字匹配的形式,把网页的标题、摘要、URL等信息展示出来。google, 百度,搜狗,搜搜,有道
垂直搜索则针对某一特定领域,搜索结果也只限定在该领域内,例如商品搜索、招聘搜索、 机票搜索,地图搜索,购物搜索(一淘)等,一个例子见图1:

因为垂直搜索已经将用户的意图限定在以特定领域了,因此搜索结果的准确率也很高。那如何在通用领域也能做到了解用户的搜索需求即意图呢?那就需要用到意图识别的技术了。
2、用户意图识别的难点
用户输入不规范,输入方式多样化,使用自然语言查询,甚至非标准的自然语言。比如上面提到的“附近的特价酒店” 、“上海到扬州高速怎么走”都是自然语言查询的例子,又如 “披星 ( ) 月”、“吾尝终日而思矣, 下面“
用户的查询词表现出多意图,比如用户搜索“变形金刚”,是指变形金刚的电影还是游戏?
如:仙剑奇侠传
游戏?--> 游戏软件?……
电视剧?--> 电视剧下载?相关新闻?……
电影?--> 电影下载?查看影评?剧情介绍?……
音乐?--> 歌曲下载?在线听歌?歌词下载?……
小说?--> 小说下载?在线观看?……意图强度,表现为不同用户对相同的查询有不同的需求强度。比如:宫保鸡丁。宫保鸡丁菜,菜谱需求占 90%。宫保鸡丁歌曲,歌曲下载需求占 10%。又比如:荷塘月色。荷塘月色歌曲,歌曲下载需求占 70%。荷塘月色小区,房产需求占 20%。荷塘月色菜,菜谱需求占 10%。
意图存在时效性变化,就是随着时间的推移一些查询词的意图会发生变化。比如:华为 P10 国行版 3 月 24 日上市。3 月 21 日的查询意图:新闻 90%,百科 10%3 月 24 日的查询意图:新闻 70%,购买 25%,百科 5%5 月 1 日的查询意图:购买 50%,资讯 40%,其他 10%5 年以后的查询意图:百科 100%
数据冷启动的问题,用户行为数据较少时,很难准确获取用户的搜索意图。
没有固定的评估的标准,CTR、MAP、MRR、nDCG 这些可以量化的指标主要是针对搜索引擎的整体效果的,具体到用户意图的预测上并没有标准的指标。
3、用户搜索意图分类:
1.导航类:用户明确的要去某个站点,但又不想自己输入 URL,比如用户搜索“新浪网“
2.信息类:又可以细分为如下几种子类型,
直接型:用户想知道关于一个话题某个方面明确的信息,比如“地球为什么是圆的”、“哪些水果维生素含量高”。间接型:用户想了解关于某个话题的任意方面的信息,比如粉丝搜索“黄晓明”。建议型:用户希望能够搜索到一些建议、意见或者某方面的指导,比如“如何选股票”。定位型:用户希望了解在现实生活中哪里可以找到某些产品或服务,比如“汽车维修”。列表型:用户希望找到一批能够满足需求的信息,比如“陆家嘴附近的酒店”。
3.资源类:这种类型的搜索目的是希望能够从网上获取某种资源,又可以细分为以下几种子类型,
下载型:希望从网络某个地方下载想要的产品或者服务,比如“USB 驱动下载”。娱乐型:用户出于消遣的目的希望获得一些有关信息,比如“益智小游戏”。交互型:用户希望使用某个软件或服务提供的结果,用户希望找到一个网站,这个网站上可以直接计算房贷利息。获取型:用户希望获取一种资源,这种资源的使用场合不限于电脑,比如“麦当劳优惠券”,用户希望搜到某个产品的折扣券,打印后在现实生活中使用。
4、意图识别的方法:
因为意图识别本身也是一个分类问题,其实方法和分类模型的方法大同小异。
常用的有:
1:基于词典模板的规则分类
一种是基于规则模板的分类方法,这种方法比较适用于查询非常符合规则的类别,通过规则解析的方式来获取查询的意图。比如:今天天气怎么样, 可以转化为 [日期][实体: 天气][询问词: 怎么样]上海到曼谷的机票价格, 可以转化为 [地点] 到 [地点][机票 / 车票 / 火车票] 价格
如:236.2美金能换多少RMB?
[236.2][美金][今天]能换多少[人民币]?
[数字][货币单位][日期]能换多少[货币单位]?
★通过知识图表,来替换/对应/归一
解析:
数量:236.2
源货币:美元(不再是“美金”)
目的货币:人民币
★配合自己建立的一些语言模型,可以比较好的解决召回率比较低的问题
模型训练的比较好的话,相对召回也很不错
但是比如购物啊什么的,是无法做这种信息模型的
这种方法的对比较明确的规则性强的方式有精确的识别度,缺点是覆盖度低,用户查询稍作变换可能就不 match 了,另外规则的发现和制定主要靠人工进行。
2:基于过往日志匹配【穷举】(适用于搜索引擎)
这种方法最简单暴力,通过词表直接匹配的方式来获取查询意图,同时,也可以加入比较简单并且查询模式较为集中的类别。
查询词:德国[addr] 爱他美[brand] 奶粉[product] 三段[attr]
查询模式:[brand]+[product];[product]+[attr];[brand]+[product]+[attr]
当然查询模式是可以做成无序的。这种意图识别的方式实现较为简单,能够较准确的解决高频词。由于query一般是满足20/80定律,20%的query占据搜索80%的流量。但是,80%得长尾query是无法通过这种方式来解决的,也就是说这种方式在识别意图的召回可能只占20%。同时,需要人工参与较多,很难自动化实现。
如:北京的天气怎么样啊
(停用词替换) --> [北京][天气][怎么样]
(查询词归一) --> {城市][关键词][疑问词]
(顺序无关) --> {[城市], [关键词], [疑问词]}
3:基于分类模型进行意图识别
这三种方式基本上是目前比较主流的方法,现在进行意图识别的难点主要是两点,
一点是数据来源的匮乏,因为方法已经比较固定,基本都是有监督学习,需要很多的标记数据,现在我们常用的数据要么就是找专业标记团队去买(我们是自己标记的,很恶心。。),要么就是自己去爬,这方面还是很麻烦的。二点是尽管是分类工作,但是意图识别分类种类很多,并且要求的准确性,拓展性都不是之前的分类可比的,这一点也是很困难的。
二、意图识别的做法
1、数据集
意图识别离不开数据,搜索领域的意图识别用到的数据通常就是用户的搜索日志了。一般一条搜索日志记录会包括时间-查询串-点击URL记录-在结果中的位置等信息。
2、数据清洗
拿到日志数据,一般是不能直接用的,里面会包含很多的噪声数据,无用信息,我们都需要把它给清洗掉。
3、query分析
角度1:
Query的类目预测。例如搜索“运动鞋”,可能包括:男士运动鞋、女士运动鞋、儿童运动鞋等类目,预测Query所在的类目对提高搜索结果的相关性非常重要。如果能够识别用户或者意图是男性还是女性,搜索结果又可以去掉很多不相关的类目。
Query的相关性计算。用于下拉补全词推荐、相关词推荐。不过补全词和相关词推荐在产品上是不同的。补全词一般要包含搜索输入词,更严格的是要以输入的搜索词作为前缀;而相关词是为了帮助用户找到自己想要的东西,是细化搜索意图还是改变搜索意图就值得推敲。细化意图可以推荐下位词。
Query Tagging。即把Query中表示颜色、性别、尺寸、材质、产品属性词提取出来。
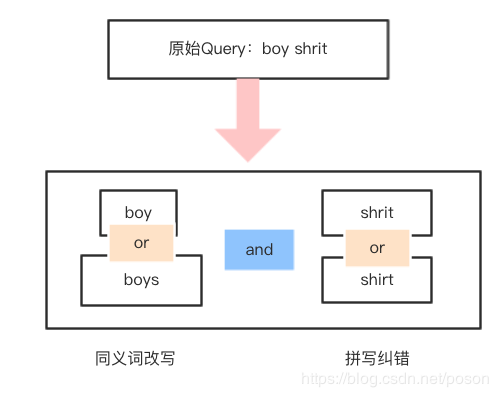
Query Rewrite。搜索引擎改写包括:同义词、单复数的改写,即找出等价的Query去做搜索。如果把纠错也当成是改写
角度2:
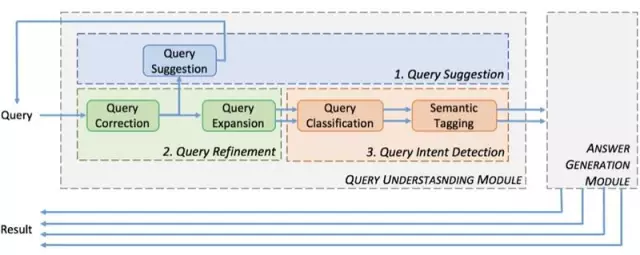
查询意图理解的过程就是结合用户历史行为数据对 query 进行各种分析处理的过程,包括
query纠错、【query rewrite】
query 词自动提示、【query相关性计算】
query扩展,【query相关性计算】
query自动分类、【query类目预测】
语义标签等。【query tagging】
下面这张图是一个具体的例子说明 query understanding 的工作过程
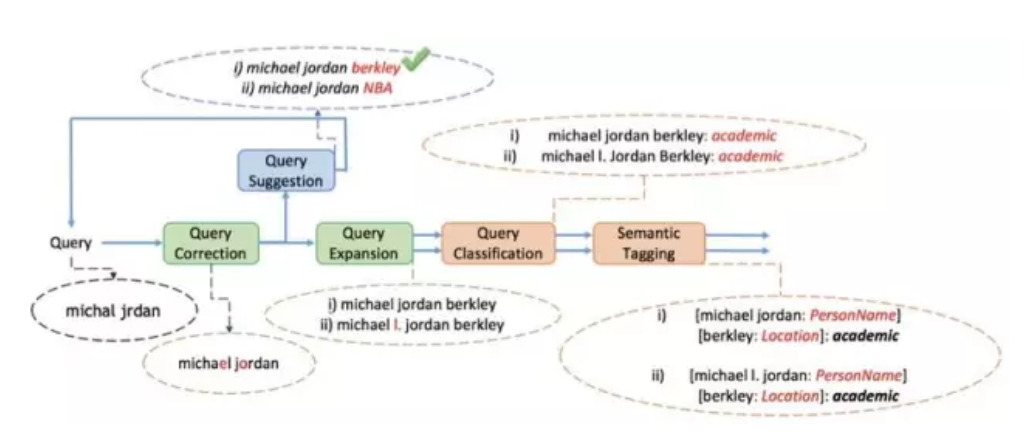
稍微解释一下这张图:
用户的原始 query 是 “michal jrdan”
Query Correction 模块进行拼写纠错后的结果为:“Michael Jordan”
Query Suggestion 模块进行下拉提示的结果为:“Michael Jordan berkley”和 “Michael Jordan NBA”,假设用户选择了“Michael Jordan berkley”
Query Expansion 模型进行查询扩展后的结果为:“Michael Jordan berkley”和 “Michael I. Jordan berkley”
Query Classification 模块进行查询分类的结果为:academic
最后语义标签(Semantic Tagging)模块进行命名实体识别、属性识别后的结果为:[Michael Jordan: 人名][berkley:location]:academic
Query Correction 模块,也即查询纠错模块。
对于英文,最基本的语义元素是单词,因此拼写错误主要分为两种:一种是 Non-word Error,指单词本身就是拼错的,比如将“happy”拼成“hbppy”,“hbppy”本身不是一个词。另外一种是 Real-word Error,指单词虽拼写正确但是结合上下文语境确是错误的,比如“two eyes”写成“too eyes”,“too”在这里是明显错误的拼写。
而对于中文,最小的语义单元是字,往往不会出现错字的情况,因为现在每个汉字几乎都是通过输入法输入设备,不像手写汉字也许会出错。虽然汉字可以单字成词,但是两个或以上的汉字组合成的词却是更常见的语义元素,这种组合带来了类似英文的 Non-word Error,比如“大数据”写成“大树据”,虽然每个字是对的,但是整体却不是一个词,也就是所谓的别字。
query 纠错的具体方案有:
基于编辑距离
基于噪声信道模型
Query Suggest 模块,也即输入下拉提示
根据用户输入的查询词前缀自动提示用户最有可能输入的完整查询词列表。
这里涉及几个问题:
Suggest 词条来从哪里来
如何根据当前的输入快速匹配到候选 suggest 词条列表
如何对候选 suggest 词条列表进行排序
suggest 词条通常主要来自用户搜索历史 query log,但存在数据冷启动的问题,开始时缺少 query log 时如何处理?对于一些垂直的应用场景,比如小说搜索中,suggest 词条也可以是作品的标题、标签、作家名等,电商搜索中可以是品牌词库、产品列表等。
对于 suggest 词条列表的存储结构与快速匹配,如果 suggest 词条列表不是很大,Trie 树(又称字典树)是一个不错的选择,用 Trie 树实现的主要优点是利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的,实现也比较简单,但缺点是节点数增加到一定程度内存开销会成为瓶颈。如果 suggest 词条列表很大,可以选择 Ternary Tree(又称三叉搜索树), 三叉搜索树对 Trie 的内存问题(空的指针数组)进行了专门优化,具体细节大家可以 google,这里不再深入。
Suggest 候选词的排序通常根据候选词项的整体热门指数,即搜索的多的排在前面。当然实际应用场景中的排序会考虑更多的排序因素,比如个性化的因素,当下热门指数等因素。
query同义词挖掘:
在电商搜索环境中,同义词分成好几类:
1. 品牌同义词:nokia=诺基亚,Adidas=阿迪达斯
2. 产品同义词:投影仪≈投影机,电话≈cell phone; automobile 和car。
3.旧词和新词:自行车 -> 脚踏车
4.南方用词和北方用词:番茄-> 西红柿。
5.传统的同义词:储物柜和收纳柜。
6.错别字同义词:瑜伽和瑜珈(错误写为斜王旁)
对应英文来说,还有词干提取,如单复数、动词原形和ing形式;英文还有一个特殊的现象,例如两个单词可以分开写,也可以合并在一起,例如keychain和key chian(钥匙链),boyfriend 和boy friend。
近义词就比较多了: 包括size 大码≈大号;短裤和热裤;边疆和边疆。
上位词:苹果手机上位词 是手机。
反义词:宽松和修身。当我们做query改写的时候,改写千万不能改写出反义词。
如果我们仔细观察,我们会发现有的词可以互相替换,有些词是只能单向替换(换一个方向就不对了,例如周杰伦可以替换为周董,但是周董只能在一定情况下替换为周董)。
如何挖掘同义词?
我们可以从用户搜索词、商品标题、搜索和点击来获取。最根本的来源还是商家对商品标题的优化,聪明的商家会把同义词堆叠在标题中,以期望获取到更多的流量。
从点击日志上看,如果w1和w2是同义词,那么搜索w1和搜索w2,理论上会有大量的共同点击的商品x1、x2、x3等等。
标题商品标题得到大量的语料,例如投影仪和投影机,拉杆箱(draw bar box)和旅行箱(luggage)。
通过统计或者word2vec训练词的相关性,找到高相关度的词。统计这些词在标题中共同出现次数,即w1和w2的共现次数。
通过word2vec,我们可以找出原始词和最相似的10个单词,然后我们统计origin 和substitute(原始词和替代词)在标题中的共现次数,通过这种挖掘,我们找到大量的候选词对,这种词通过人工review可以作为同义词的候选。
对这种情况稍微做一些扩展,我们就能得到同义query到同义query之间的对应关系。
统计分析上位词,统计每个商品类目下的产品词,出现次数top n的产品词w,对应到商品的类目词c,那么w -> c很可能 就是一个上位词关系。
query 相似性计算:
https://blog.csdn.net/poson/article/details/85922519
1、计算两个query的编辑距离
2、计算两个query(x和y)在session中的互信息,PMI(x,y)=p(x,y)/(p(x)*p(y))
例如QA有一个点击的商品集合,QB有两个点击的商品集合,用点击数量或者点击率作为商品的权重来设计一个向量,这样两个Query就可以通过cosin(vector(QA),vector(QB)) 来计算相关性。还有比较简单的方法是计算两个Query(x和y)在session 中的互信息,PMI(x,y)=p(x,y)/(p(x)*p(y))
3、协同过滤
把query和点击item作为一个评分矩阵,按照协同过滤的方法来计算相关性。由于协同过滤没有考虑点击的次数信息,因此推荐词的点击次数和原始词的搜索次数、长度可能不够匹配,还需要很多方法来纠正。
4、稀疏
由于点击数据受到搜索结果的影响,由于排序质量的问题,点击的位置bias,有很多办法来纠正;以及部分Query的点击比较稀疏,商品的点击比较稀疏。
例如simrank,simrank++(http://www.vldb.org/pvldb/1/1453903.pdf)等算法。
前阿里妈妈的yangxudong 文章里面有mapreduce 的实现:https://blog.csdn.net/yangxudong/article/details/24788137 。主要是基于分块矩阵的计算。实现中利用二次排序,做了不少优化。
另外github 上面有两个代码:
(1)https://github.com/thunderain-project/examples 其部分代码无法通过编译。
(2)https://blog.csdn.net/dengxing1234/article/details/78933187 编译通过,少量数据可以通过编译,大量数据还无法跑得结果。

5、用商品向量来表示Query,也有一些方法借鉴了simrank和向量的思想,用词向量来表示Query和Title。
例如yahoo研究院的这篇论文《Learning Query and Document Relevance from a Web-scale Click Graph》。

6、DSSM(cikm2013)https://www.cnblogs.com/baiting/p/7195998.html
把Query 先和Title 先分别用word hash 到一个3万维的空间,然后一层层embedding 到一个128维的向量, 最后可以简单的用cosin来计算相似性。

7、一个用户在一个session中点击的商品序列可以用来做embedding ,得到商品id到embedding vector。
同时我们可以可以考虑把用户在一个session中输入的Query当成序列来做embedding 。按照这个思路找了一下论文,果然2018年有人用这个想法写了论文。《Querying Word Embeddings for Similarity and Relatedness》http://aclweb.org/anthology/N18-1062
We tested vector spaces with varying dimensionalities (dim=100/200/300) and number of context words (win=3/6/10), as well as minimum occurrence cutoff (min=1/5), negative samples (neg=1/5) and iterations (iter=1/5). These variations were tested to ensure the observed patterns reported in the experiments, but we report numerical results only for best performing models. In particular, higher dimensional vectors with dim=300 produced consistently better alignment with human scoring data. We also found min=1, neg=5 and iter=5 to be the optimal parameter settings across all experiments.
8、目前图计算有很多方法。
我们尝试了用node2vec的方法来计算Query的相似性,也取得了非常好的效果。即把query和item 的二部图上面做node2vec。
另外准备尝试用阿里妈妈的euler平台里面的图embedding方法来计算节点之间相关性。
Query Expansion 查询扩展模块
查询词扩展技术通过将与用户查询词相近、相关的词扩展到用户查询词中的方法, 更准确地描述用户的信息需求, 去除用户查询词的多义性, 从而更精确地查询用户所需信息。在信息检索技术中, 查询词扩展是一种能够有效提高查询效率的技术。通过用户搜索日志和点击日志可以挖掘出查询扩展词。
我们在实践中采用一种基于搜索日志会话局部上下文和全局上下文为语料库使用 word2vec 构建 skip-gram 词向量模型,根据词向量模型可以取得与查询词最相似的前 N 个词构成初步的相关候选词表,然后再利用 K 近邻算法从相关词候选词表选取出语义最相关的候选词作为查询词的扩展词。
搜索日志会话局部上下文是指与当前 query 在同一个会话上下文中的共现 query, 也是用户对 query 的查询重构,比如初始 query 为“变形金刚”,用户在查询会话中可能将 query 变换为 “变形金刚电影”进行搜索,则“变形金刚电影”为原始 query 的局部上下文。
query 的全局上下文挖掘思路:
根据查询词和查询所点击的结果构建二部图,利用随机游走模型计算出每个查询词的文档分布作为查询词的查询向量,再利用 KL 距离来计算两查询向量之间的相似性。
上面提到,意图识别可以看成是文本分类的问题,但是只依赖查询串是肯定不行的,提供的信息太少太少,所以常做的就是考虑利用先前的搜索日志信息,例如历史查询串对应的标题、时间、近义词等信息。有的场景下还会加入地点信息,例如地图搜索。
一些可以用来扩展的信息有:
(1)点击标题。通常在搜索日志中,会以一个session为单位,一个session中保存的是一个时间段内的相关搜索信息,我们可以用的信息字段是查询串-点击标题-点击次数-时间等,在不同session的同一查询可能对应的点击记录不一样,我们可以把它们合并起来,将标题放到查询文档中;
(2)相似查询串。同样,同一点击记录的不同查询我们也可以拿来用的;
(3)此外,同义词词林、利用word2vec得到的近义词集合都可以扩展进来。
这样我们就可以得到一个信息比较丰富的查询文档了。值得注意的是,同一session下的不同查询,如果有递增关系,说明用户在根据搜索结果进行修正查询,那么新增的词应该对意图分类作用很大,例如图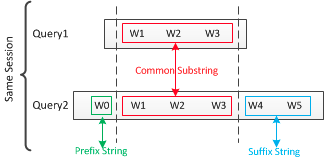
Query Classification 查询意图分类模块
在关键词做类目预测之前可以做一个预处理提高准确率。如query归一化、纠错、去除价格区间词、中英文翻译对照等等。
通常有基于规则模板的分类方法和基于机器学习的分类方法。
- 通过pair <商品标题词,类目> ,统计关键词和类目的共现关系
- 统计用户搜索Query,然后在结果集中点击的商品的集合,统计商品类目的分布。注意这里的Query的term要全部在命中的商品标题中出现,而不是部分出现。
- 用分类算法的方式,样本是<商品的标题词,类目>,<Query,点击的商品类目>。使用适合多分类的算法分类:最大熵、FastText、TextCNN、BI-LSTM + attention等算法。
1、一种是基于规则模板的分类方法,
这种方法比较适用于查询非常符合规则的类别,通过规则解析的方式来获取查询的意图。比如:今天天气怎么样, 可以转化为 [日期][实体: 天气][询问词: 怎么样]上海到曼谷的机票价格, 可以转化为 [地点] 到 [地点][机票 / 车票 / 火车票] 价格
这种方法的对比较明确的规则性强的方式有精确的识别度,缺点是覆盖度低,用户查询稍作变换可能就不 match 了,另外规则的发现和制定主要靠人工进行。
2、另一种是基于机器学习分类的方法。
如果有确定的查询类别体系,基于机器学习的查询意图分类是一个不错的选择,可以选择 SVM 作为分类器,关键在分类特征的选择, 还有训练样本的准确标注。
这个和我们之前参加过的 2014 ACM CIKM 竞赛的问题类似,那年 CIKM 竞赛的题目是自动识别用户的查询意图(Query Intent Detection,QID):给定一批标注过类别的搜索日志包括查询日志和点击日志作为训练样本,其中也有部分未标注的,类别为 unknown。
在特征的选择方面,除了基本的 Query 的长度、Query 的频次、Title 的长度、Title 的频次、BM-25、Query 的首字、尾字等,我们通过对 log session 上下文的分析,进行了 Query 间特征词汇的挖掘,运用了 query 在相同 session 中的共现关系,挖掘 query 之间的子串包含关系,query 和点击的 title 之间的文本特征关系等。
在分类模型的选择方面,我们选择了 Ensemble 框架。Ensemble 的基本思想是充分运用不同分类算法各种的优势,取长补短,组合形成一个强大的分类框架。不过 Ensemble 不是简单的把多个分类器合并起来结果,或者简单将分类结果按固定参数线性叠加 (例如不是 a1 * ALGO1 + a2 * ALGO2 + a3 * ALGO3),而是通过训练 Ensemble 模型,来实现最优的组合。
在 Ensemble 框架下,我们分类器分为两个 Level: L1 层和 L2 层。L1 层是基础分类器,L2 层基于 L1 层,将 L1 层的分类结果形成特征向量,再组合一些其他的特征后,形成 L2 层分类器(如 SVM)的输入。这里需要特别留意的是用于 L2 层的训练的样本必须没有在训练 L1 层时使用过。

Semantic Tagging 模块
这个模块主要是对 query 中的命名实体进行识别,比如对电商搜索 query 中的品牌词、产品词、属性词、地址进行识别。对 query,用一个相对准确的词典 (品牌词 / 产品词 / 属性词 / 地址词) 去标注语料。
比如对于 ”新西兰安佳奶粉二段“ 标注语料如下所示:新 B-loc 西 I-loc 兰 I-loc 安 B-brand 佳 I-brand 奶 B-product 粉 I-product 二 B-attr 段 I-attr实体词识别模型可以通过 crf 来进行训练。
至此,第二部分 如何识别用户搜索意图 也讲完了总结一下,我们首先简单说明了用户搜索意图的主要分类:导航类、信息类、资源类,然后对搜索意图识别的主要功能模块查询纠错、查询词自动提示、查询扩展,查询自动分类、语义标签等实现思路分别进行了介绍。
Term Weight
中文自然语言处理的第一步就是分词,分词的结果中,每个词的重要性显然应该时候区别的。Term Weight就是为了给这些词不同的打分,根据分值就可以判断出核心词,进而可以应用到不同的场景。比如,有一个商品的标题为“碗装保温饭盒套装”,通过Term Weight可以得到核心词为“饭盒”。当用户搜"碗"召回这个商品的时候,是可以根据term weight来进行排序降权的。
4、特征工程
把上面扩展得到的查询文档利用tfidf向量化,就可以得到一个特征向量,一般情况下,这个特征向量维度会非常高,我们可以利用词频、卡方、互信息等方法进行特征选择,保留更有用的特征信息。
我们还可以加入一些数字特征在里面,例如:
(1)Query的长度
(2)Query的频次
(3)Title的长度
(4)Title的频次
(5)BM-25
(6)Query的首字、尾字等
对 log session 上下文的分析,
进行了 Query 间特征词汇的挖掘,
运用了 query 在相同 session 中的共现关系,
挖掘 query 之间的子串包含关系,
query 和点击的 title 之间的文本特征关系
一些统计特征也可以考虑,例如论文【2】
提到的不同页面点击数DPCN(Different Page Click Number)、异源页面点击数PCNS(Page Click Number without Subpage)等,其中:
(1)不同页面点击数DPCN,表示用户对查询串的返回结果的点击情况统计,因为作者统计发现对于导航类查询,用户目标很明确,通常只点击一两个网页就完成查询了,而对应信息事务型则点击的不同页面数目比较多,例如作者统计显示当不同页面点击数不大于7时,查询串中导航意图的占66.7%,大于7时,信息事务意图的占83%。
(2)异源页面点击数PCNS,表示查询串的返回结果中,以点击频次最高的网页为基准,不同页面点击数与其子页面数量的差值。例如对于某个查询串w,不同页面点击数DPCN为17,而点击频次最高的网页子网页出现了15次,那么异源页面点击数就为17-15 = 2,这样做的目的是为了消除将同一网页的子页面算成不同页面的情况。
5、分类器训练
在完成特征任务后,接下来就是选择合适的分类器进行训练了,因为意图识别可以看作是一个多分类任务,所以通常可以选择SVM、决策树等来训练分类器。
三、应用场景:

先说一下Query分析。
最下层词语,比如说搜索五道口附近的钢铁侠3,最上面就会做一些成分识别。
成分是根据业务制订的一些标准体系,比如说五道口是一个地址的核心词,附近其实是地址的修饰词,钢铁侠3其实是店的核心词,店可以理解成商家的产品,比如说电影院里面某一个电影。
再往下就是结构、主体和泛化可做的东西比较多,比如说做一些拓展,五道口可能有华联等等,这个现在是基于图谱来做的。
其实,这个用处非常多,比如说举个例子,就是望京华联搜这个可能出不来结果,但如果做一个扩展之后就可以很顺利的找到它想要的一些结果。
从图谱方面的一些东西可以很好的应用。从内容方面的话,比如说钢铁侠3有一些相似的电影等等,这个其实也是我们的一些泛化。
再往上会对Query做一些概念的识别,主要是电影。

以Query意图识别做为例子。说一个Query,我们对它的类别做一个判别,比如动物园门票就是旅游,全聚德和望京是美食。我们可以分成不同的类别,这些类别有美食、电影、酒店之类的,还有很多二三级的品类。
说到这个场景之后,其实大家脑子里就可以想到这个事情怎么来做。
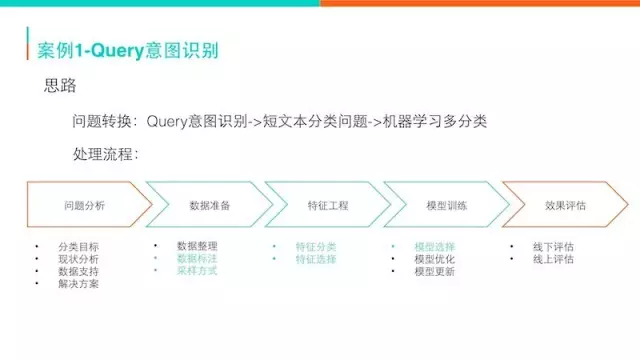
Query意图识别可以转换成机器学习多分类的问题。机器学习对一个问题有一套标准的流程,做过机器学习的都知道。首先要对问题做一个分析,要分哪一些类别,根据现状制定一个目标。现有数据的支持是否有一些标注的辞典、数据等等,根据这个再来整理数据,比如说如果标注数据不够怎么办,后面会做一些介绍。特征工程需要抽取很多特征,特别是你要考虑到O2O的一些特点,需要做一些事情。特征做完之后再做模型方面的一些选择和分析,最后做一些线下的评估,然后在线上镶嵌看它的效果。这个流程是非常通用的。
摘出几点,有可能和其他地方不太一样的地方做一个介绍。首先就是训练样本怎么获取,这个其实比较难,第一种是人工标注,第二种就是自动标注。思路有几种,可以通过主动学习用模型学习,它的执行度比较高的,作为它已经有了,区分比较低的再来标一下,这样标注的样本量就非常多。还有Query的思想其实也是来扩充执行度比较高的样本作为它的标注数据。

第二个问题就是特征设计,我们会把Query的一些语义的特征,Query扩充的一些信息也会融进来。说一下不一样的,我们Query是有地域区分的,例如黄鹤楼,可能在北京搜更多的是一个酒店饭店;但如果在武汉搜的话,其实就是一个景点。模型尝试的话,(PPT图示)右边就是精准化简单的图,中间两层还做了文本分类的模型。
最后再说一下整体的流程。我们的分类目标就是定一些品类体系,用的话,可能就是在流量分发、统计到排序里面会用;现状有一些辞典的,解决思路其实就是想通过机器学习的方法来解决。数据准备刚才已经介绍了,特征工程也说了一下,最后用DN加很多点,在线上我们在旅游产品上线可以提升5%的水平。
四、query线上处理:
对query的线上处理,如果是较为hot的query,可以以查表为主,可以用hash表,trie树等进行查表,把在线下计算好的数据,通过查表的方式找到对应的结果,附加到给引擎的搜索条件上,并返回。
另外,可以把线下训练好的模型,在线上进行预测,一般的分类算法预测速度都比较快。可以对长尾的query,进行及时的预测。
也可以做一些规则,如我们上面举的例子,“1000元左右”,可以通过正则表达式进行识别,将其转为对应的搜索条件。这些规则如何来定呢,这是比较麻烦的一点,像这类的query,肯定是pv比较低的,属于长尾的query,这些query效果提升可能比较明显,但是对总体搜索系统效果影响会较小。这个问题比较尴尬,如果我们这类query处理的效果好的话,那用户会使用的更多;用户知道了这样的query效果不好,所以就换成了效果好的query。如果要做好规则,那就把长尾的这些query都拿出来,多看看,分下类,再结合实际的问题分类,总结出一些通用的规则,来进行优化。
参考:
https://blog.csdn.net/w97531/article/details/83892403
https://www.jianshu.com/p/718039922161
http://www.52nlp.cn/cikm-competition-topdata?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
https://mp.weixin.qq.com/s/xkcQLPgFzRzQclnP9JSPDw
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247486229&idx=1&sn=5c04e52b5e4cf9ff0e2ad4d5bba4925b&source=41#wechat_redirect
https://blog.csdn.net/weixin_33705053/article/details/87087191
https://www.jianshu.com/p/7db0b4a2a208
https://max.book118.com/html/2018/1016/7131141051001153.shtm
http://www.sohu.com/a/325793598_465959
http://www.chinahadoop.cn/course/122
http://www.jinciwei.cn/f775883.html
https://www.jianshu.com/p/27b61e72794c
https://www.zhihu.com/question/19895141
https://www.zhihu.com/question/19895141
https://blog.csdn.net/asialee_bird/article/details/85702874#8%E3%80%81NLP%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B
计算广告(5)----query意图识别的更多相关文章
- 计算广告(4)----搜索广告召回(也叫match、触发)
一.搜索广告形态 1.特征工程 特征主要有用户画像(user profile).用户行为(user behavior).广告(ad)和上下文(context)四部分组成,如下所示: 2.平台算法主要分 ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- 如何使用padlepadle 进行意图识别-开篇
前言 意图识别是通过分类的办法将句子或者我们常说的query分到相应的意图种类.举一个简单的例子,我想听周杰伦的歌,这个query的意图便是属于音乐意图,我想听郭德纲的相声便是属于电台意图.做好了意图 ...
- ML学习分享系列(1)_计算广告小窥[上]
原作:面包包包包包包 修改:寒小阳 && 龙心尘 时间:2016年1月 出处: http://blog.csdn.net/breada/article/details/50572914 ...
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- 智能问答中的NLU意图识别流程梳理
NLU意图识别的流程说明 基于智能问答的业务流程,所谓的NLU意图识别就是针对已知的训练语料(如语料格式为\((x,y)\)格式的元组列表,其中\(x\)为训练语料,\(y\)为期望输出类别或者称为意 ...
- 浅谈意图识别各种实现&数学原理
\[ J_\alpha(x) = \sum_{m=0}^\infty \frac{(-1)^m}{m! \Gamma (m + \alpha + 1)} {\left({ \frac{x}{2} }\ ...
- [Computational Advertising] 计算广告学笔记之基础概念
因为工作需要,最近一直在关注计算广告学的内容.作为一个新手,学习计算广告学还是建议先看一下刘鹏老师在师徒网的教程<计算广告学>. 有关刘鹏老师的个人介绍:刘鹏现任360商业产品首席架构师, ...
- ML学习分享系列(2)_计算广告小窥[中]
原作:面包包包包包包 改动:寒小阳 && 龙心尘 时间:2016年2月 出处:http://blog.csdn.net/Breada/article/details/50697030 ...
随机推荐
- Jenkins入坑记
记录一遍Jenkins初级使用教程 一,安装 (操作系统 centerOS7) 1-1.本次使用的是rpm包安装方式,在Jenkins官网下载rpm安装文件 下载地址: https://pkg.jen ...
- c#窗体程序绘制简单心形
分析思路: 两个圆形和一个矩形如图叠加再逆时针旋转45°,就能得到一个极其简陋的心. 我们只需要将圆心放在矩形上边中点和右边中点即可. 代码如下: private void button1_Cli ...
- Win7 JavaEE 安装
新建四个目录 D:\ApacheServer\eclipse 存放eclipse D:\ApacheServer\jdk jdk安装目录 D:\ApacheServer\apache-tomcat 存 ...
- java输入输出 -- java NIO之文件通道
一.简介 通道是 Java NIO 的核心内容之一,在使用上,通道需和缓存类(ByteBuffer)配合完成读写等操作.与传统的流式 IO 中数据单向流动不同,通道中的数据可以双向流动.通道既可以读, ...
- 数据结构 -- 链表(LinkedList)
链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成. 每个结点包括两个部分 ...
- 《统计学习方法》极简笔记P4:朴素贝叶斯公式推导
<统计学习方法>极简笔记P4:朴素贝叶斯公式推导 朴素贝叶斯基本方法 通过训练数据集 T={(x_1,y_1),(x_2,y_2),(x_N,y_N)...,(x_1,y_1)} 学习联合 ...
- SAS学习笔记4 基本运算语句(lag、retain、_n_函数)
lag:返回的是上一次lag函数运行时的实参,即lag(argument)=上一次lag函数执行时的argument retain:对变量进行值的初始化和保留到下一个迭代步 _n_:data步的自动变 ...
- (转)从0移植uboot (一) _配置分析
ref : https://www.cnblogs.com/xiaojiang1025/p/6106431.html 本人建议的uboot学习路线,先分析原有配置,根据现有的配置修改.增加有关的部分, ...
- linux中部署jenkins(war包)及jenkins忘记登录账号密码
未登录状态 登录状态 一:部署jenkins(war包) 1.直接下载war包jenkins.war,下载地址https://jenkins.io/download 2.将下载的war包放到服务器上t ...
- Qt中容器类应该如何存储对象(最好使用对象指针类型,如:QList<TestObj*>,而不要使用 QList<TestObj> 这样的定义,建议采用 智能指针QSharedPointer)
Qt提供了丰富的容器类型,如:QList.QVector.QMap等等.详细的使用方法可以参考官方文档,网上也有很多示例文章,不过大部分文章的举例都是使用基础类型:如int.QString等.如果我们 ...