HashMap与ConcurrentHashMap、HashTable
(1)HashMap的线程不安全原因一:死循环
原因在于HashMap在多线程情况下,执行resize()进行扩容时容易造成死循环。
扩容思路为它要创建一个大小为原来两倍的数组,保证新的容量仍为2的N次方,从而保证上述寻址方式仍然适用。扩容后将原来的数组从新插入到新的数组中。这个过程称为reHash。
【单线程下的reHash】
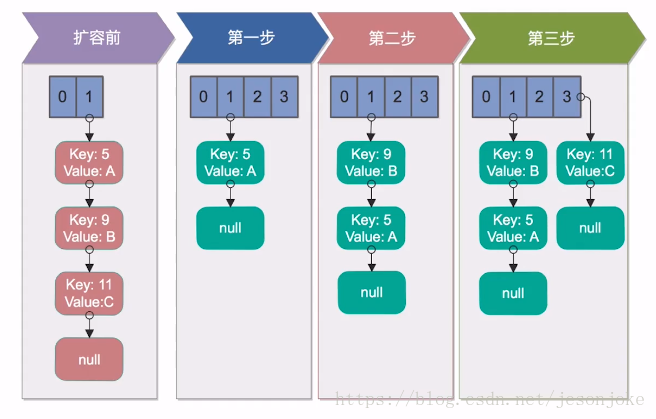
- 扩容前:我们的HashMap初始容量为2,加载因子为1,需要向其中存入3个key,分别为5、9、11,放入第三个元素11的时候就涉及到了扩容。
- 第一步:先创建一个二倍大小的数组,接下来把原来数组中的元素reHash到新的数组中,5插入新的数组,没有问题。
- 第二步:将9插入到新的数组中,经过Hash计算,插入到5的后面。
- 第三步:将11经过Hash插入到index为3的数组节点中。
单线程reHash完全没有问题。
【多线程下的reHash】

我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
(2)HashMap的线程不安全原因二:fail-fast
Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
解决办法:可以使用Collections的synchronizedMap方法构造一个同步的map,或者直接使用线程安全的ConcurrentHashMap来保证不会出现fail-fast策略。
Java7 HashMap
不支持并发操作
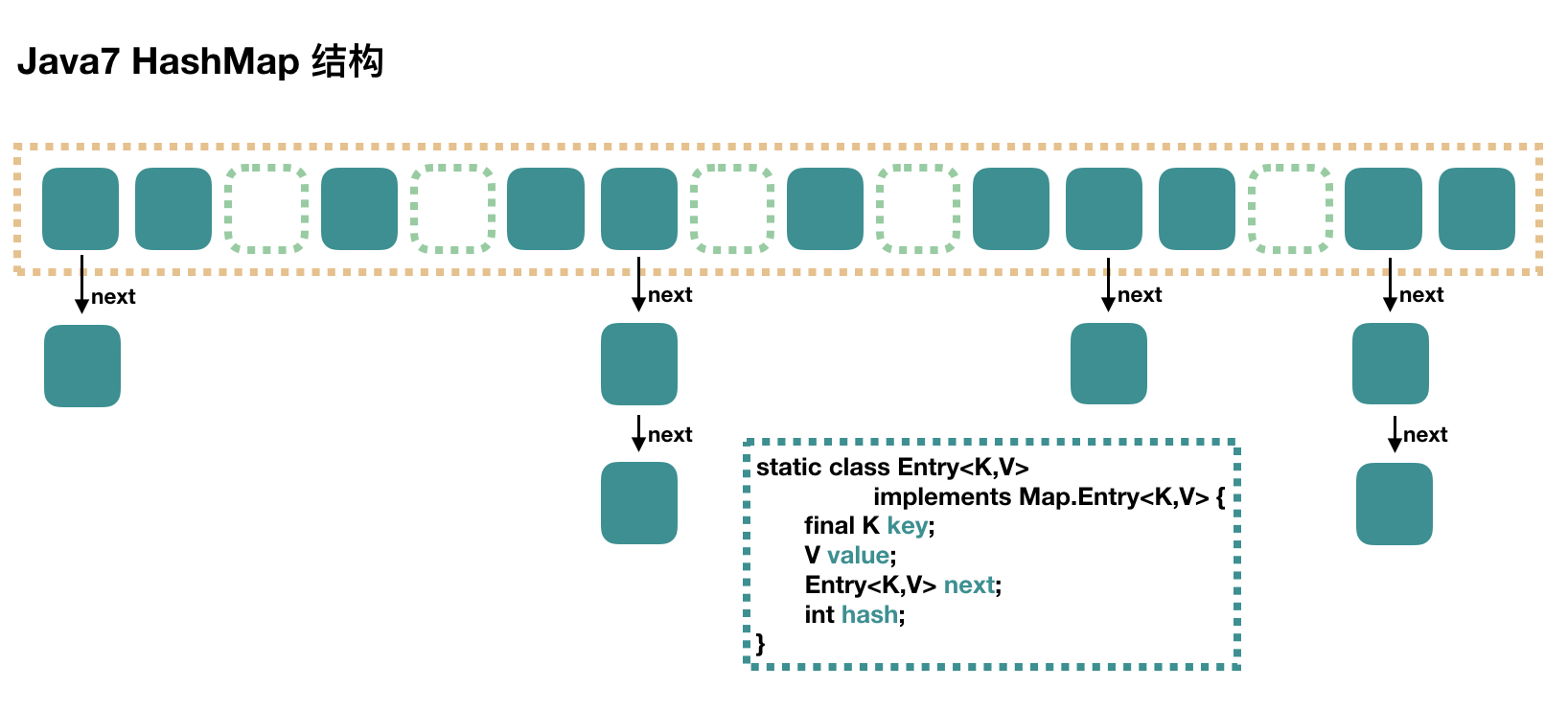
Java中的数据存储方式有两种结构,一种是数组,另一种就是链表,前者的特点是连续空间,寻址迅速,但是在增删元素的时候会有较大幅度的移动,所以数组的特点是查询速度快,增删较慢。
而链表由于空间不连续,寻址困难,增删元素只需修改指针,所以链表的特点是查询速度慢、增删快。
那么有没有一种数据结构来综合一下数组和链表以便发挥他们各自的优势?答案就是哈希表。
HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
HashMap的长度为什么要是2的n次方
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capacity * loadFactor
put 过程分析
数组初始化
在第一个元素插入 HashMap 的时候做一次数组的初始化,就是先确定初始的数组大小,并计算数组扩容的阈值。
1. 求 key 的 hash 值 int hash = hash(key);2. 找到对应的数组下标 int i = indexFor(hash, table.length);3.放入链表头部数组扩容
在插入新值的时候,如果当前的 size 已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的 2 倍。
get 过程分析
1.根据 key 计算 hash 值。
2.找到相应的数组下标:hash & (length – 1)。
3.遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
Java7 ConcurrentHashMap
——基于分段锁的ConcurrentHashMap
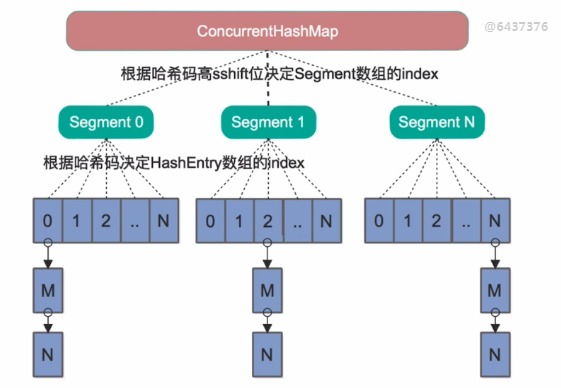
- Java7里面的ConcurrentHashMap的底层结构仍然是数组和链表,与HashMap不同的是ConcurrentHashMap的最外层不是一个大的数组,而是一个Segment数组。每个Segment包含一个与HashMap结构差不多的链表数组。
- 当我们读取某个Key的时候它先取出key的Hash值,并将Hash值的高sshift位与Segment的个数取模,决定key属于哪个Segment。接着像HashMap一样操作Segment。
- 为了保证不同的Hash值保存到不同的Segment中,ConcurrentHashMap对Hash值也做了专门的优化。
Segment继承自J.U.C里的ReetrantLock,所以可以很方便的对Segment进行上锁。即分段锁。理论上最大并发数是和segment的个数是想等的。
初始化
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。扩容是 segment 数组某个位置内部的数组 HashEntry<k,v>[] 进行扩容,扩容后,容量为原来的 2 倍。
put 过程分析
1. 计算 key 的 hash 值
2. 根据 hash 值找到 Segment 数组中的位置
3.再利用 hash 值,求应该放置的segment 内部的数组下标
4.添加到头部
get 过程分析
1.计算 hash 值,找到 segment 数组中的具体位置,或我们前面用的“槽”
2.槽中也是一个数组,根据 hash 找到数组中具体的位置
3.到这里是链表了,顺着链表进行查找即可
Java8 HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。
java8也是通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。但是java8引入红黑树,即使hash冲突比较高,寻址效率也会是比较高的。
来一张图简单示意一下吧:
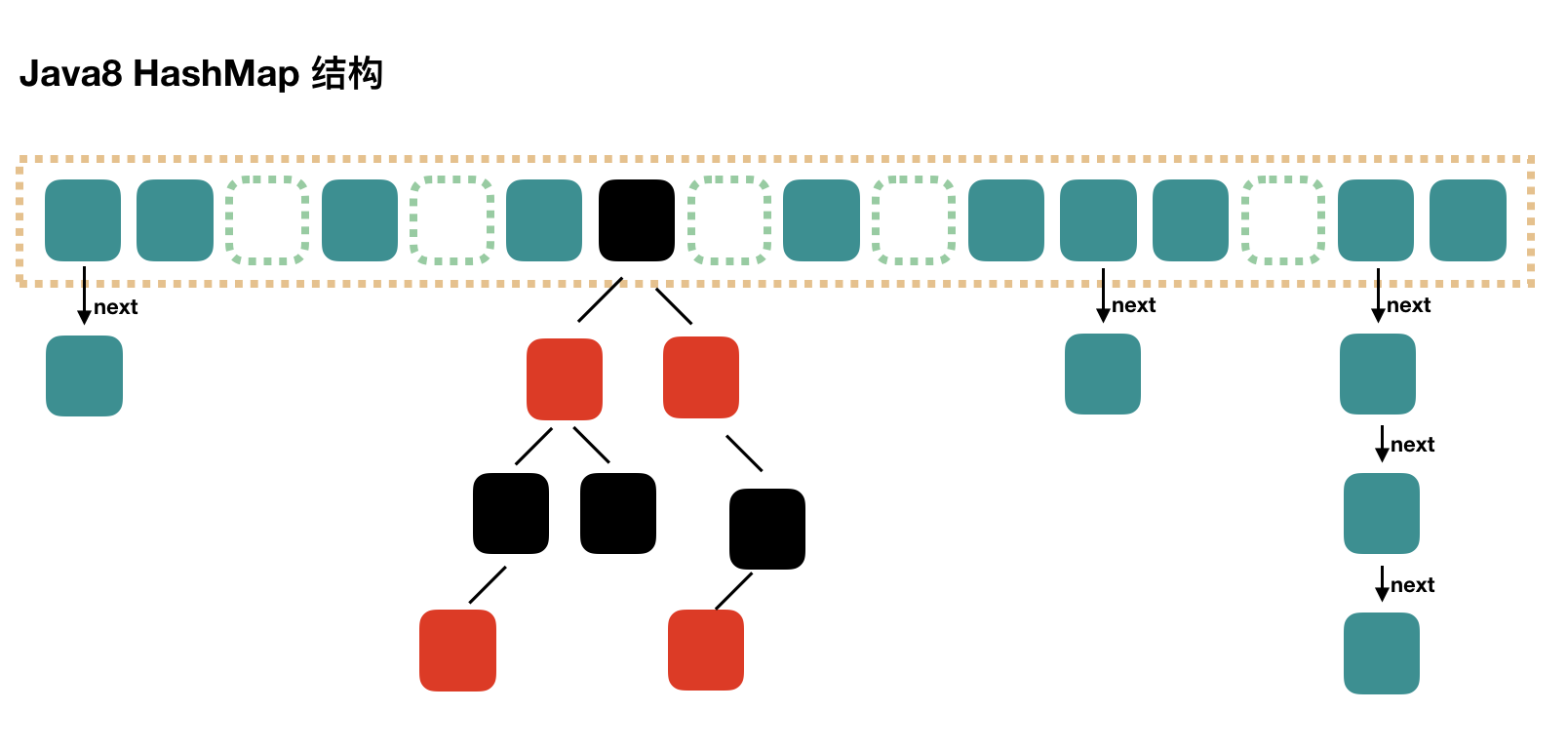
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
put 过程分析
参考get过程
get 过程分析
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
Java8 ConcurrentHashMap
——基于CAS的ConcurrentHashMap
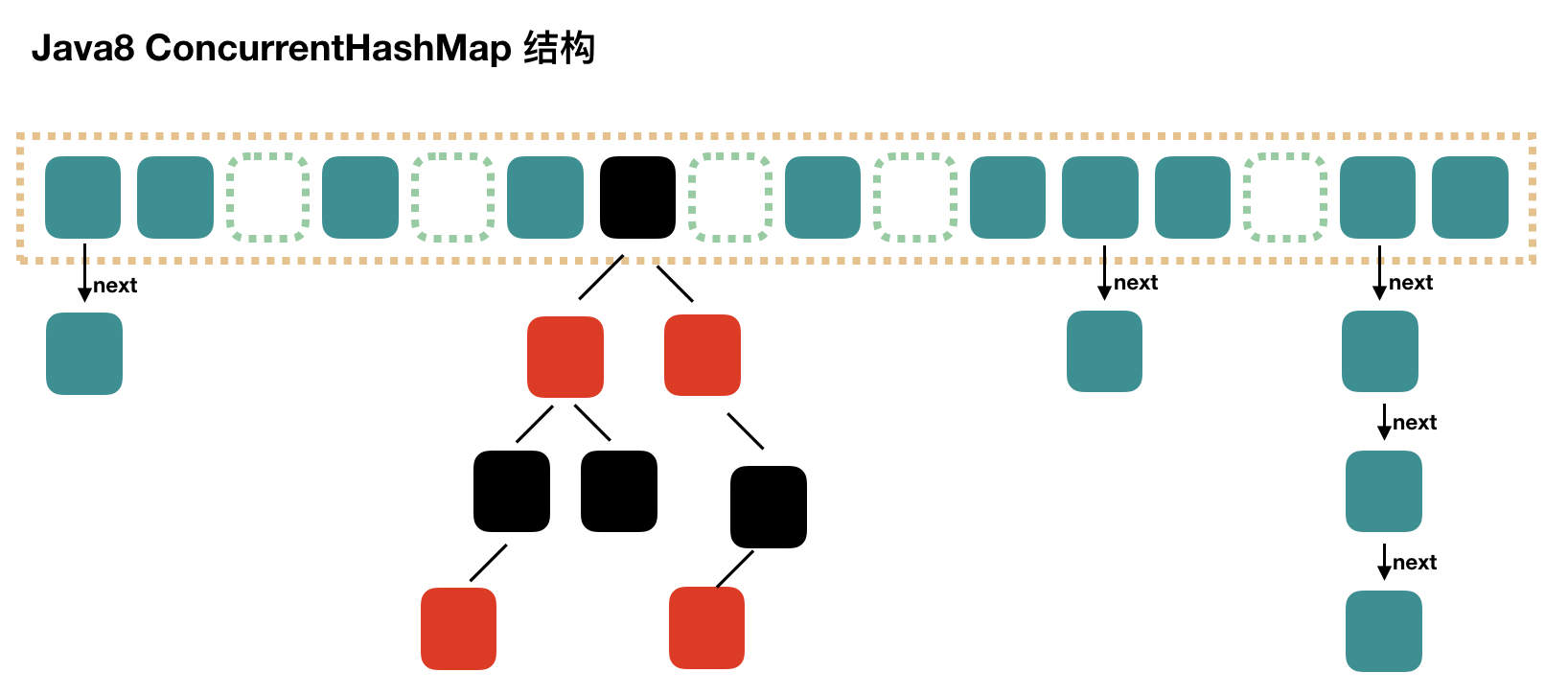
比java8的HashMap复杂很多,但是结构差不多全。
同步方式
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障
HashMap和ConcurrentHashMap对比:
- HashMap非线程安全、ConcurrentHashMap线程安全
- HashMap允许Key与Value为空,ConcurrentHashMap不允许
- HashMap不允许通过迭代器遍历的同时修改,ConcurrentHashMap允许。并且更新可见
HashMap和HashTable的对比:
(1)HashMap是非线程安全的,HashTable是线程安全的。
(2)HashMap的键和值都允许有null存在,而HashTable则都不行。
(3)因为线程安全、哈希效率的问题,HashMap效率比HashTable的要高。
HashTable和ConcurrentHashMap对比:
HashTable里使用的是synchronized关键字,这其实是对对象加锁,锁住的都是对象整体,当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。ConcurrentHashMap相对于HashTable的syn关键字锁的粒度更精细了一些,并发性能更好。
问题:在put的时候是放在链表头部还是尾部?
jdk1.7之前是放在链表头部在jdk1.8之后是放在尾部。
HashMap与ConcurrentHashMap、HashTable的更多相关文章
- 沉淀再出发:java中的HashMap、ConcurrentHashMap和Hashtable的认识
沉淀再出发:java中的HashMap.ConcurrentHashMap和Hashtable的认识 一.前言 很多知识在学习或者使用了之后总是会忘记的,但是如果把这些只是背后的原理理解了,并且记忆下 ...
- HashMap和ConcurrentHashMap和HashTable的底层原理与剖析
HashMap 可以允许key为null,value为null,但HashMap的是线程不安全的 HashMap 底层是数组 + 链表的数据结构 在jdk 1.7 中 map集合中的每一项都是一个 ...
- HashTable、HashMap与ConCurrentHashMap源码解读
HashMap 的数据结构 hashMap 初始的数据结构如下图所示,内部维护一个数组,然后数组上维护一个单链表,有个形象的比喻就是想挂钩一样,数组脚标一样的,一个一个的节点往下挂. 我们可以 ...
- HashMap TreeMap ConcurrentHashMap 源码
1 HashMap java se 1.6 1.1 父类 java.lang.Object 继承者 java.util.AbstractMap<K,V> 继承者 java.util.Has ...
- 轻松理解 Java HashMap 和 ConcurrentHashMap
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- Java中关于Map的使用(HashMap、ConcurrentHashMap)
在日常开发中Map可能是Java集合框架中最常用的一个类了,当我们常规使用HashMap时可能会经常看到以下这种代码: Map<Integer, String> hashMap = new ...
- HashMap TreeMap ConcurrentHashMap
1 HashMap java se 1.6 1.1 父类 java.lang.Object 继承者 java.util.AbstractMap<K,V> 继承者 java.util.Has ...
- 高并发第九弹:逃不掉的Map --> HashMap,TreeMap,ConcurrentHashMap
平时大家都会经常使用到 Map,面试的时候又经常会遇到问Map的,其中主要就是 ConcurrentHashMap,在说ConcurrentHashMap.我们还是先看一下, 其他两个基础的 Map ...
- 深入理解HashMap和concurrentHashMap
原文链接:https://segmentfault.com/a/1190000015726870 前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇 ...
随机推荐
- XHTML XML
XHTML是可扩展的超文本标记语言(Extensible HyperText Markup Language). l XHTML是w3c组织在2000年的时候为了增强HTML推出的,本来是想替代HT ...
- C#实现反射调用动态加载的DLL文件中的方法
反射的作用:1. 可以使用反射动态地创建类型的实例,将类型绑定到现有对象,或从现有对象中获取类型 2. 应用程序需要在运行时从某个特定的程序集中载入一个特定的类型,以便实现某个任务时可以用到反射.3. ...
- ExtJs4学习(六)MVC中的Model
Model定义的两种方式 第一种 Ext.define("User",{ extend:"Ext.data.Model", fields:[{ name:'us ...
- JS-校验表单后提交表单的三种方法总结
第一种: <script type="text/javascript"> function check(form) { if(form.userId.value=='' ...
- AngularJS 讲解,一 数据绑定
AngularJS 完全使用javascript 编写的客户端技术.通过原生的Model-View-Controller(MVC,模型视图控制器)功能增强了HTML.这个选择可以快捷和愉悦地构建出 ...
- SpringBoot专题1----springboot与mybatis的完美融合
springboot大家都知道了,搭建一个spring框架只需要秒秒钟.下面给大家介绍一下springboot与mybatis的完美融合: 首先:创建一个名为springboot-mybatis的ma ...
- FineReport---函数
1.NUMTO()需要将数字2345转换成二三四五:NUMTO(2345) 2.Toimage函数:Toimage(path)用于在报表中显示某一路径path下的图片 3.row():为获取当前行号 ...
- Windows File 管理工具:junction And Subinacl
junction.exe 是 Sysinternals 出品的命令行工具.使用前建议将其复制到%SystemRoot%/system32目录下 创建一个名为 D:/LINK 的[junction ...
- 淘宝订单数据转CSV
<html> <body> <div id="result"> </div> <div> <textarea st ...
- 【转】Spring AOP 实现原理与 CGLIB 应用
AOP(Aspect Orient Programming),作为面向对象编程的一种补充,广泛应用于处理一些具有横切性质的系统级服务,如事务管理.安全检查.缓存.对象池管理等.AOP 实现的关键就在于 ...