五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url

# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
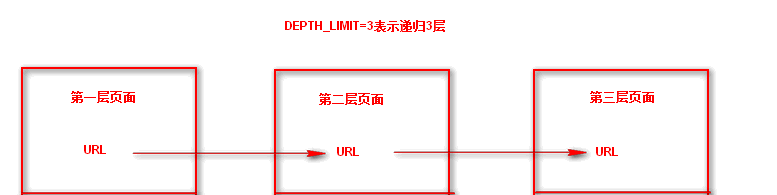
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
五 web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 爬虫scrapy模块
首先下载scrapy模块 这里有惊喜 https://www.cnblogs.com/bobo-zhang/p/10068997.html 创建一个scrapy文件 首先在终端找到一个文件夹 输入 s ...
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 二 web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安 ...
随机推荐
- javascript自定义属性的应用
你知道吗?JavaScript可以为任何HTML元素添加任意的自定义属性,而且你可能无意中已经使用过自定义属性了,那么自定义属性通常有哪些应用呢? 1.想用“匹配”.对应关系的时候就用索引值 2.同时 ...
- 我的Android进阶之旅------>解决Error:Unable to find method 'org.gradle.api.internal.project.ProjectInternal.g
错误描述 今天在Github上面下载了一份代码,然后导入到Android Studio中直接报了如下图所示的错误: 错误描述如下: Error: Unable to find method 'org. ...
- django 多并发,多线程。
参考http://blog.csdn.net/u013378306/article/details/76215982 django 原生为单线程序,当第一个请求没有完成时,第二个请求辉阻塞,知道第一个 ...
- Django-1版本的路由层、Django的视图层和模板层
一.Django-1版本的路由层(URLconf) URL配置(URLconf)就像Django所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:我们就是以这种方式告诉Dja ...
- NYOJ 119 士兵杀敌(三)(RMQ算法)
採用的的是小牛的写法,蒟蒻第一次写.. RMQ (Range Minimum/Maximum Query)问题是指:对于长度为n的数列A,回答若干询问RMQ(A,i,j)(i,j<=n).返回数 ...
- mysql 内置功能 函数 date_format函数
创建数据库db12 create database db12 charset=utf8; use db12; 准备表和记录 CREATE TABLE blog ( id INT PRIMARY KEY ...
- Java并发—并发工具类
在JDK的并发包里提供了几个非常有用的并发工具类.CountDownLatch.CyclicBarrier和Semaphore工具类提供了一种并发流程控制的手段,Exchanger工具类则提供了在线程 ...
- iOS学习之移除Main.storyboard
每次使用Single View Application模板创建工程之后,总是会有一个Main.storyboard文件,那么,当我们使用代码布局的时候,很显然是不需要它的.那么,如何将它从工程中移除呢 ...
- Mac OS X下搭建Android开发环境(包括SDK和NDK)
资源准备: JDK Eclipse Android SDK Android NDK ADT CDT ANT 搭建Android SDK开发环境: 1.JDK安装,要求版本>1.5, Mac O ...
- 介绍Web项目中用到的几款JS日历日期控件和JS文本编辑框插件
第一款日历日期控件:layDate 官方网站:http://laydate.layui.com/ 第二款日历日期控件:my97 官方网站:http://www.my97.net/ 第三款 文本编辑器控 ...