[Algorithms] Graph Traversal (BFS and DFS)
Graph is an important data structure and has many important applications. Moreover, grach traversal is key to many graph algorithms. There are two systematic ways to traverse a graph, breadth-first search (BFS) and depth-frist search (DFS).
Before focusing on graph traversal, we first determine how to represent a graph. In fact, there are mainly two ways to represent a graph, either using adjacency lists or adjacency matrix.
An adjacency list is an array of lists. Each list corresponds to a node of the graph and stores the neighbors of that node.
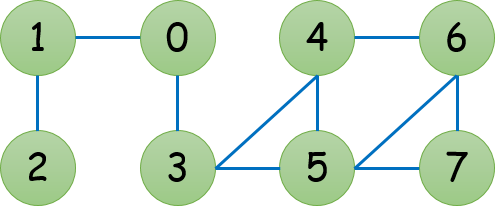
For example, for the (undirected) graph above, its representation using adjacency lists can be:
0: 1 -> 3 -> NULL
1: 0 -> 2 -> NULL
2: 1 -> NULL
3: 0 -> 4 -> 5 -> NULL
4: 3 -> 5 -> 6 -> NULL
5: 3 -> 4 -> 6 -> 7 -> NULL
6: 4 -> 5 -> 7 -> NULL
7: 5 -> 6 -> NULL
An adjacency matrix is a matrix of size m by m (m is the number of nodes in the graph) and the (i, j)-the element of the matrix represents the edge from node i to node j.
For the same graph above, its representation using adjacency matrix is:
0 1 0 1 0 0 0 0
1 0 1 0 0 0 0 0
0 1 0 0 0 0 0 0
1 0 0 0 1 1 0 0
0 0 0 1 0 1 1 0
0 0 0 1 1 0 1 1
0 0 0 0 1 1 0 1
0 0 0 0 0 1 1 0
In this passage, we use adjacency lists to represent a graph. Specifically, we define the node of the graph to be the following structure:
struct GraphNode {
int label;
vector<GraphNode*> neighbors;
GraphNode(int _label) : label(_label) {}
};
Now let's move on to BFS and DFS.
As suggested by their names, BFS will first visit the current node, then its neighbors, then the non-visited neighbors of its neighbors... and so on in a breadth-first manner while DFS will try to move as far as possible from the current node and backtrack when it cannot move forward any more (all the neighbors of the current node has been visited).
The implementation of BFS requries the use of the queue data structure while the implementation of DFS can be done in a recursive manner.
For more details on BFS and DFS, you may refer to Introduction to Algorithms or these two nice videos: BFS video and DFS video.
In my implementation, BFS starts from a single node and visits all the nodes reachable from it and returns a sequence of visited nodes. However, DFS will try to start from every non-visited node in the graph and starts from that node and obtains a sequence of visited nodes for each starting node. Consequently, the function bfs returns a vector<GraphNode*> while the function dfs returns a vector<vector<GraphNode*> >.
I also implement a function read_graph to input the graph manually. For the above graph, you first need to input its number of nodes and number of edges. Then you will input each of its edge in the form of "0 1" (edge from node 0 to node 1).
The final code is as follows.
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_set> using namespace std; struct GraphNode {
int label;
vector<GraphNode*> neighbors;
GraphNode(int _label) : label(_label) {}
}; vector<GraphNode*> read_graph(void) {
int num_nodes, num_edges;
scanf("%d %d", &num_nodes, &num_edges);
vector<GraphNode*> graph(num_nodes);
for (int i = ; i < num_nodes; i++)
graph[i] = new GraphNode(i);
int node, neigh;
for (int i = ; i < num_edges; i++) {
scanf("%d %d", &node, &neigh);
graph[node] -> neighbors.push_back(graph[neigh]);
graph[neigh] -> neighbors.push_back(graph[node]);
}
return graph;
} vector<GraphNode*> bfs(vector<GraphNode*>& graph, GraphNode* start) {
vector<GraphNode*> nodes;
queue<GraphNode*> toVisit;
unordered_set<GraphNode*> visited;
toVisit.push(start);
visited.insert(start);
while (!toVisit.empty()) {
GraphNode* cur = toVisit.front();
toVisit.pop();
nodes.push_back(cur);
for (GraphNode* neigh : cur -> neighbors) {
if (visited.find(neigh) == visited.end()) {
toVisit.push(neigh);
visited.insert(neigh);
}
}
}
return nodes;
} bool visitAllNeighbors(GraphNode* node, unordered_set<GraphNode*>& visited) {
for (GraphNode* n : node -> neighbors)
if (visited.find(n) == visited.end())
return false;
return true;
} void dfs_visit(vector<GraphNode*>& graph, GraphNode* node, \
unordered_set<GraphNode*>& visited, vector<GraphNode*>& tree, \
vector<vector<GraphNode*> >& forest) {
visited.insert(node);
tree.push_back(node);
if (visitAllNeighbors(node, visited)) {
forest.push_back(tree);
tree.clear();
return;
}
for (GraphNode* neigh : node -> neighbors)
if (visited.find(neigh) == visited.end())
dfs_visit(graph, neigh, visited, tree, forest);
} vector<vector<GraphNode*> > dfs(vector<GraphNode*>& graph) {
vector<GraphNode*> tree;
vector<vector<GraphNode*> > forest;
unordered_set<GraphNode*> visited;
for (GraphNode* node : graph)
if (visited.find(node) == visited.end())
dfs_visit(graph, node, visited, tree, forest);
return forest;
} void graph_test(void) {
vector<GraphNode*> graph = read_graph();
// BFS
printf("BFS:\n");
vector<GraphNode*> nodes = bfs(graph, graph[]);
for (GraphNode* node : nodes)
printf("%d ", node -> label);
printf("\n");
// DFS
printf("DFS:\n");
vector<vector<GraphNode*> > forest = dfs(graph);
for (vector<GraphNode*> tree : forest) {
for (GraphNode* node : tree)
printf("%d ", node -> label);
printf("\n");
}
} int main(void) {
graph_test();
system("pause");
return ;
}
If you input the above graph to it as follows (note that you only need to input each edge exactly once):
The output will be as follows:
BFS: DFS:
You may check it manually and convince yourself of its correctness :)
[Algorithms] Graph Traversal (BFS and DFS)的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- [LeetCode] 785. Is Graph Bipartite?_Medium tag: DFS, BFS
Given an undirected graph, return true if and only if it is bipartite. Recall that a graph is bipart ...
- BFS 、DFS 解决迷宫入门问题
问题 B: 逃离迷宫二 时间限制: 1 Sec 内存限制: 128 MB提交: 12 解决: 5[提交][状态][讨论版] 题目描述 王子深爱着公主.但是一天,公主被妖怪抓走了,并且被关到了迷宫. ...
- BFS和DFS详解
BFS和DFS详解以及java实现 前言 图在算法世界中的重要地位是不言而喻的,曾经看到一篇Google的工程师写的一篇<Get that job at Google!>文章中说到面试官问 ...
- 【数据结构与算法】自己动手实现图的BFS和DFS(附完整源码)
转载请注明出处:http://blog.csdn.net/ns_code/article/details/19617187 图的存储结构 本文的重点在于图的深度优先搜索(DFS)和广度优先搜索(BFS ...
- BFS与DFS常考算法整理
BFS与DFS常考算法整理 Preface BFS(Breath-First Search,广度优先搜索)与DFS(Depth-First Search,深度优先搜索)是两种针对树与图数据结构的遍历或 ...
- HDU-4607 Park Visit bfs | DP | dfs
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4607 首先考虑找一条最长链长度k,如果m<=k+1,那么答案就是m.如果m>k+1,那么最 ...
- 算法录 之 BFS和DFS
说一下BFS和DFS,这是个比较重要的概念,是很多很多算法的基础. 不过在说这个之前需要先说一下图和树,当然这里的图不是自拍的图片了,树也不是能结苹果的树了.这里要说的是图论和数学里面的概念. 以上概 ...
- hdu--1026--Ignatius and the Princess I(bfs搜索+dfs(打印路径))
Ignatius and the Princess I Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (J ...
随机推荐
- struct2常用标签
Struts2常用标签总结 一 介绍 1.Struts2的作用 Struts2标签库提供了主题.模板支持,极大地简化了视图页面的编写,而且,struts2的主题.模板都提供了很好的扩展性.实现了 ...
- 动态添加easyui 控件
jquery提供了append,appendTo方法,可以动态添加静态的html文本,在easyui中,要动态添加easyui控件要怎么做呢,下面就来介绍动态添加easyui控件. 使用方法:和添加静 ...
- MVC项目发布到IIS遇到的问题
MVC4 + .NET Framework 4.5 +Windows Server 2008+ IIS7.5 + 4.0集成模式池 ,发布后可能会遇到404.0 或者403.14错误,在web.con ...
- laydate 和 Vue 奇怪的清空问题
laydate的input,会自动被清空,当别的input修改的时候.改成这样既可解决 <td><input type="text" id="retur ...
- zookeeper(二):linux centos下安装zookeeper(单机和集群)
下载 http://zookeeper.apache.org/releases.html 解压 tar –zxvf zookeeper-3.4.6.tar.gz 解压文件到"/usr/loc ...
- 开启ss-libev多用户
原理:通过查看进程,得到命令及需要的参数,然后,在制作一个配置文件,pid文件随意写. 1.首先正常开启一个: /etc/init.d/shadowsocks-libev start 2.然后:利用查 ...
- Java生成随机不反复推广码邀请码
欢迎进入我的博客:blog.scarlettbai.com查看很多其它文章 近期接到一个需求.要批量生成推广码,首先我们知道推广码的特效有例如以下两点: 1:不可反复 2:不能够被猜測出 关于这两点, ...
- JS事件类型详解
一般事件 onclick IE3.N2 鼠标点击时触发 此事件 ondblclick IE4.N4 鼠标双击时触发 此事件 onmousedown IE4.N4 按下鼠标时触发 此事件 onmouse ...
- java 发送带Basic Auth认证的http post请求实例代码
构造http header private static final String URL = "url"; private static final String APP_KEY ...
- 547. Intersection of Two Arrays【easy】
Given two arrays, write a function to compute their intersection. Notice Each element in the result ...