Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本课主题
- Master 资源调度的源码鉴赏
资源调度管理
- 任务调度与资源是通过 DAGScheduler、TaskScheduler、SchedulerBackend 等进行的作业调度
- 资源调度是指应用程序如何获得资源
- 任务调度是在资源调度的基础上进行的,没有资源调度那么任务调度就成为了无源之水无本之木
Master 资源调度的源码鉴赏
- 因为 Master 负责资源管理和调度,所以资源调度方法 scheduer 位于 Master.scala 这个类中,当注册程序或者资源发送改变的时候都会导致 Scheduler 的调用,例如注册的时候。
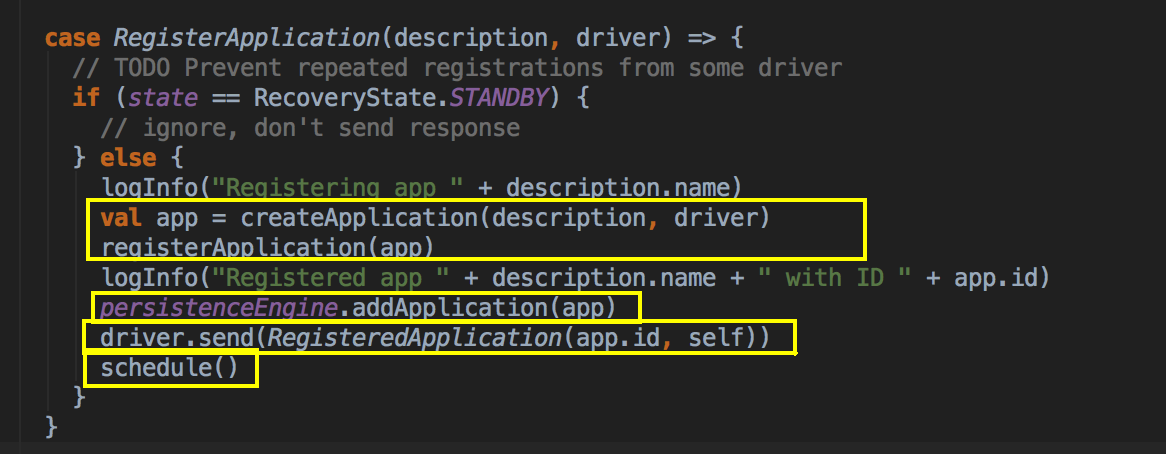
当这个应用程序向 Master 注册的时候,会把 ApplicationInfo 的信息放在一个 case class 里,过程中会新增新的 AppId,当注册的时候会分发给不同的数据结构记录起来,比如说 idToApp、endpointToApp、



- Scheduler 调用的时机,每次都有新的应用程序提交或者集群資源狀況发生改变的时候(包括 Executor 增加或者減少、Worker 增加或者減少等)具体代码运行顺序:scheduler( ) --> Random.shuffle( ) --> 有一个for循环过滤出ALIVE的Worker --> 过滤出付合Memory和Cores的Worker --> 然后调用 lanuchDriver( ) --> startExecutorsOnWorker( )

WorkerState 有以下几种:ALIVE, DEAD, DECOMMISSIONED, UNKNOWN
- 当前 Master 必需是 Alive 的方式才可以进行资源调度,一开始的时候会判断一下状态,如果不是 Alive 的状态会直接返回,也就是 StandByMaster 不会进行 Application 的资源调用
- 使用 Random.shuffle 把 Master 中保留的集群中所有 Worker 的信息随机打乱;其算法內部是循环随机交换所有 Worker 在 Master 緩存的數数据结构中的位置
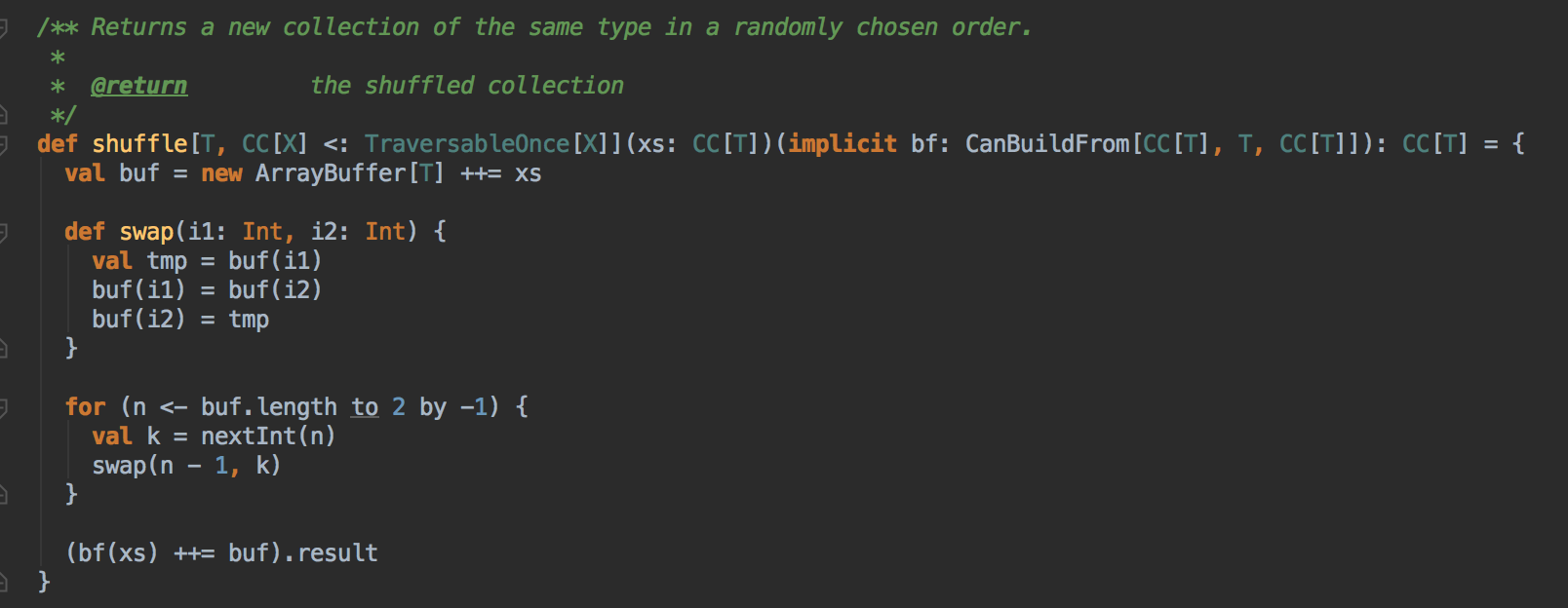
- 接下来要判断所有 Worker 中哪些是 ALIVE 级別的 Worker 才能夠参与资源的分配工作
- 当 SparkSubmit 指定 Driver 在 Cluster 模式的情況下,此时 Driver 会加入 waitingDrivers 等待列表中,在每个 DriverInfo 中的 DriverDescription 中要启动 Driver 时候对 Worker 的內存及 CPU 要求等內容:


- 在符合资源要求的情況下然后采用随机打乱后的的一个 Worker 来启动 Driver,Master 发指令给 Worker 让远程的 Worker 启动 Driver,这就可以保证负载均衡。先启动 Driver 才会发生后续的一切的资源调度的模式

正式启动在Worker中启动Executor
Spark 默认为应用程序启动 Executor 的方式是 FIFO 的方式,也就是说所有的提交的应用程序都是放在调度的等待队列中的,先进先出,只有满足了前面应用程序的分配的基础上才能夠满足下一各应用程序资源的分配。正式启动在Worker中启动Executor:为应用程序具体分配 Executor 之前要判断应用程序是否还需要分配 core 如果不需要则不会会应用程序分配 Executor
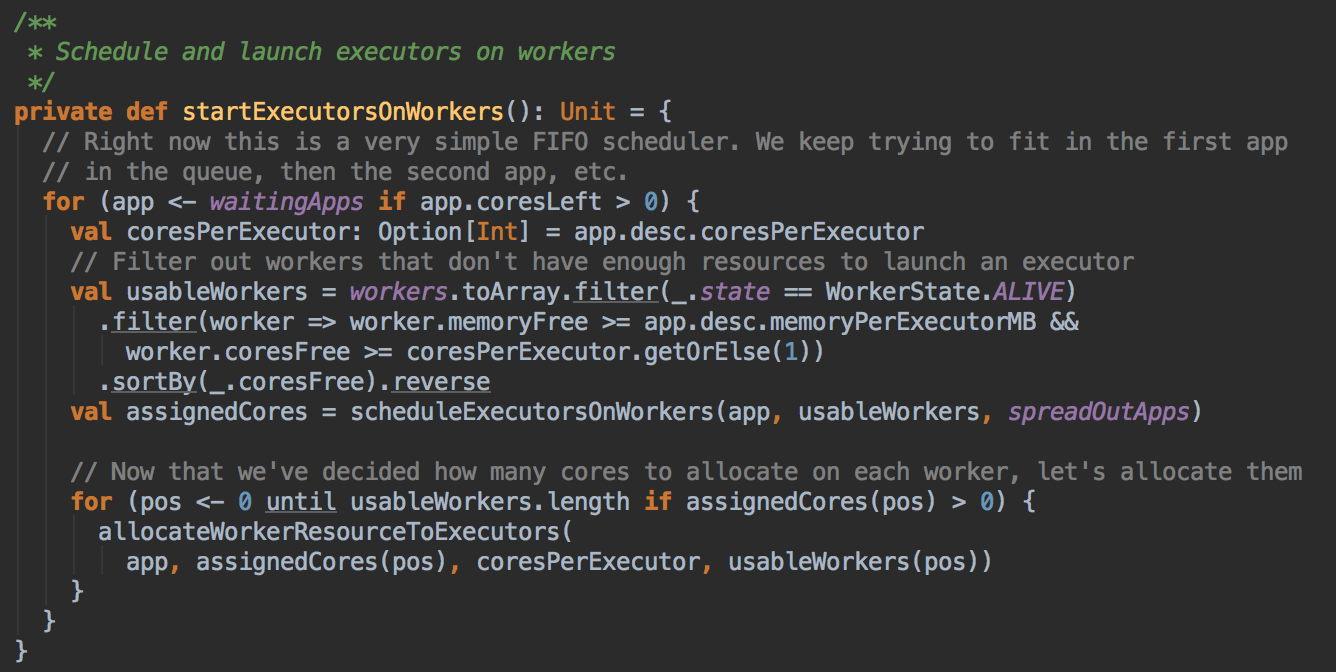
- 具体分配 Executor 之前要求 Worker 必需是 Alive 的状态且必需满足 Application 对每个 Executor 的內存和 Cores 的要求,并且在此基础上进行排序,谁的 Cores 多就排在前面。计算资源由大到小的 usableWorkers 数据库结构。把最好的资源放在前面。


在 FIFO 的情況下默认是 spreadOutApps 来让应用程序尽可能多的运行在所有的 Node 上。
- 然后调用 scheduleExecutorsOnWorkers 方法,为应用程序分配 executor 有两种情況,第一种方式是尽可能在集群的所有 Worker 上分配 Executor ,这种方式往往会来带潜在的更好的数据本地性。具体在集群上分配 Cores 的时候会尽可能的满足我们的要求,如果是每个 Worker 下面只能够为当前的应用程序分配一个 Executor 的话,每次是分配一个 Core! (每次为这个 Executor 增加一个 Core)。每次给 Executor 增加的时候都是增加一个 Core, 如果是 spreadout 的方式,循环一轮下一轮,假设有4个 Executors,如果 spreadout 的方式,它会在每个 Worker 中启动一个 Executor, 第一次为每个 Executor 分配一个线程,第二次再次循环后再分配一个线程。
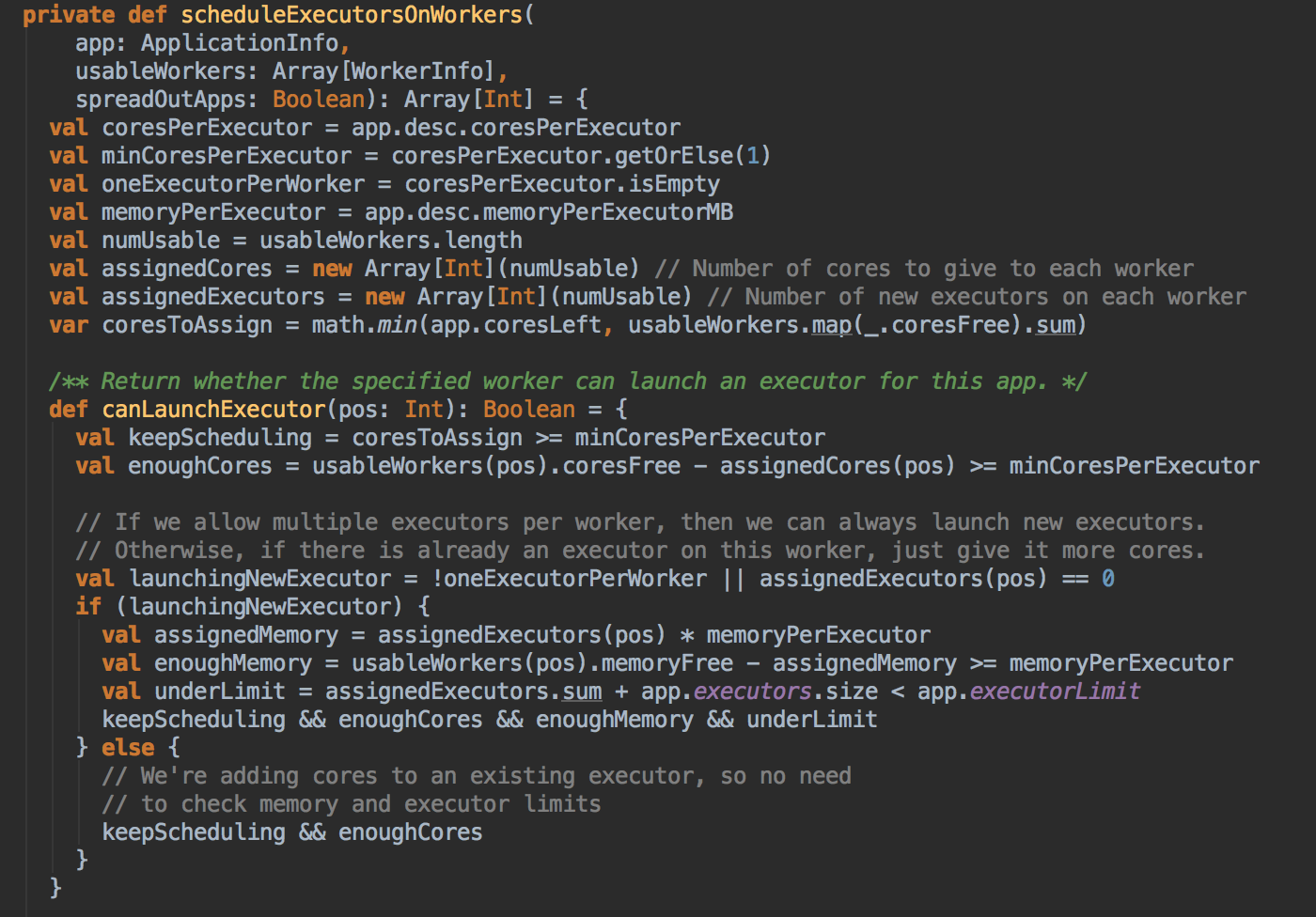
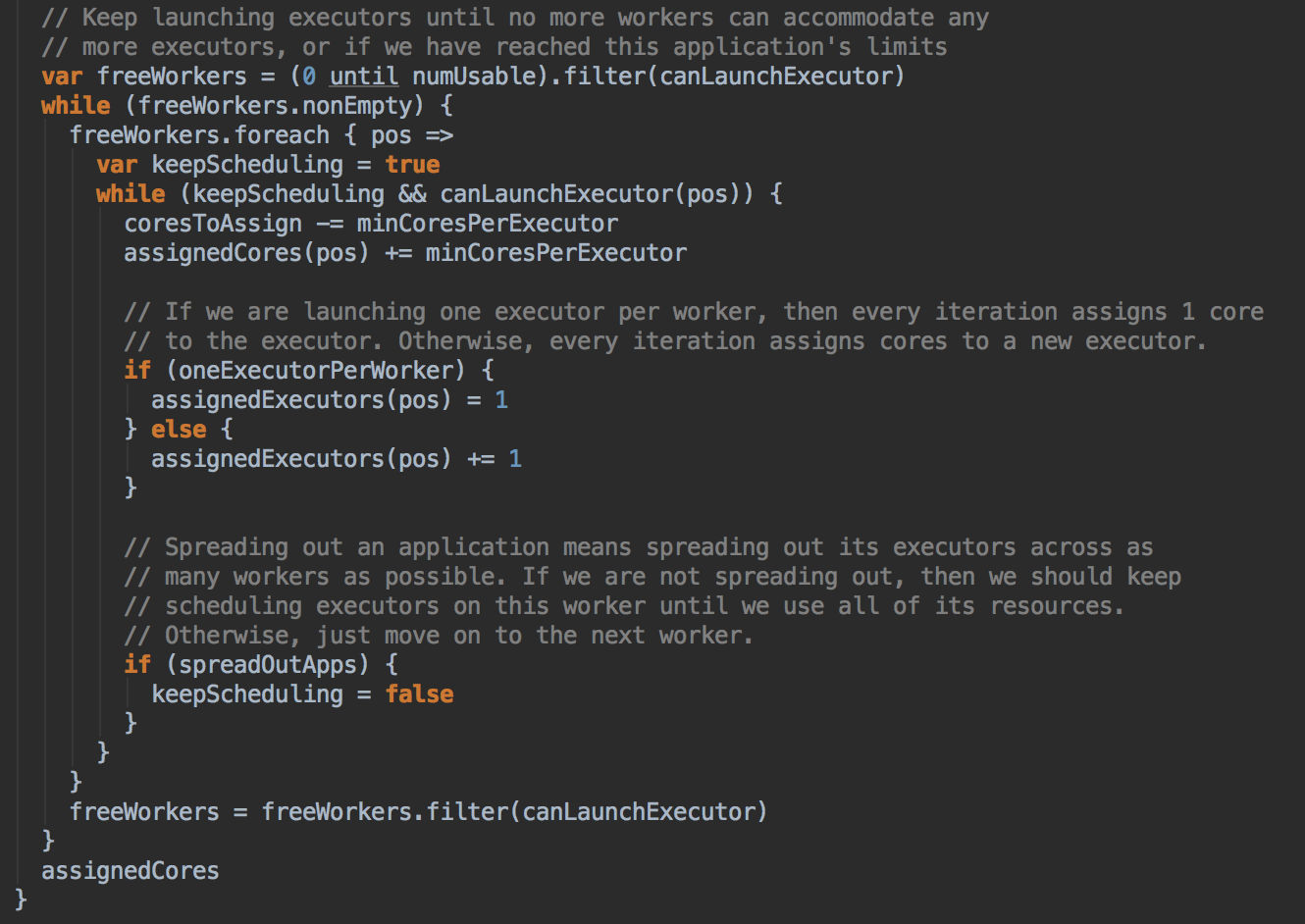
- 然后调用 allocateWorkerResourceToExecutors 方法
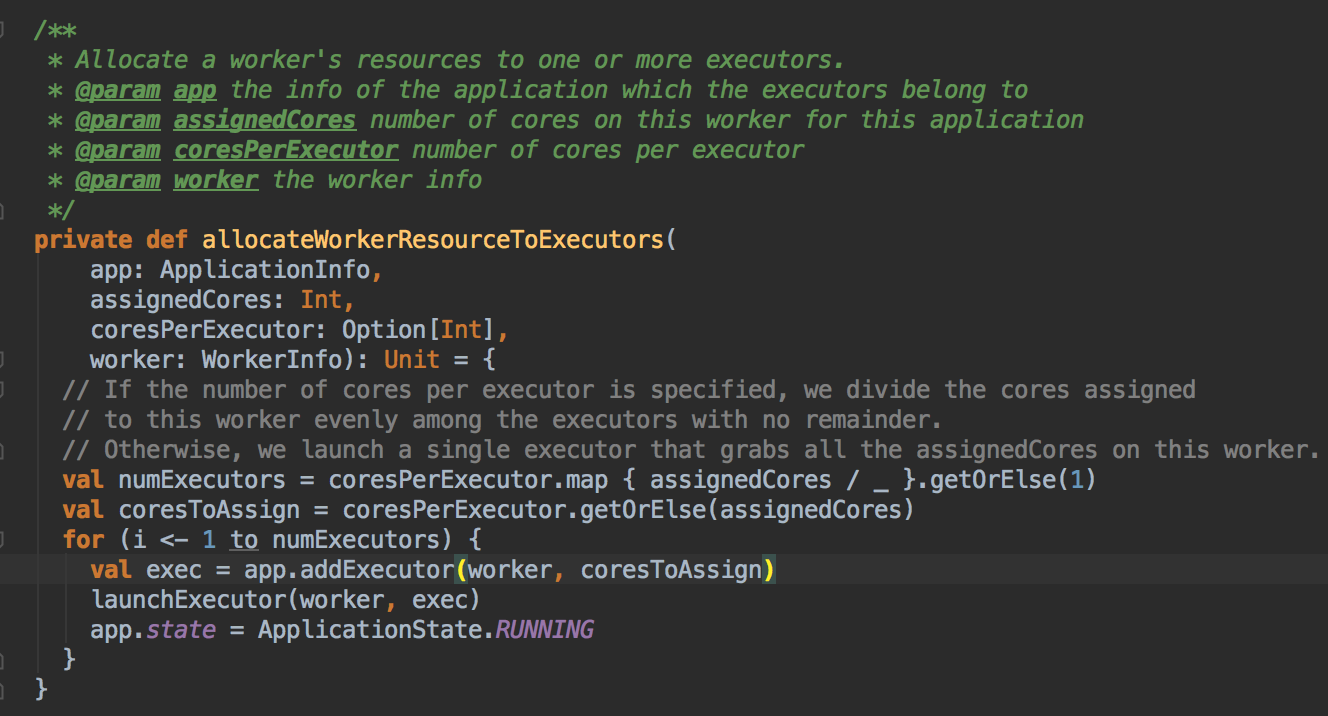
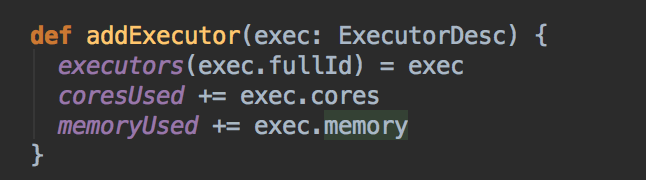
- 然后会调用 addExecutor 方法
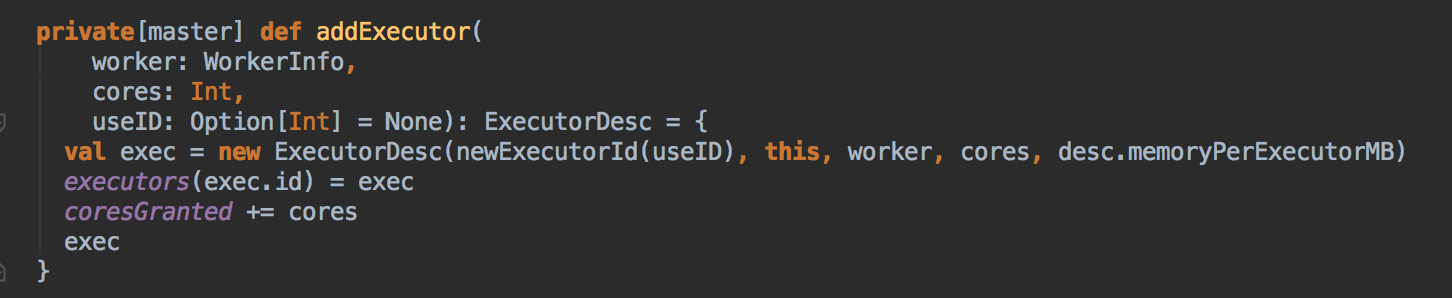
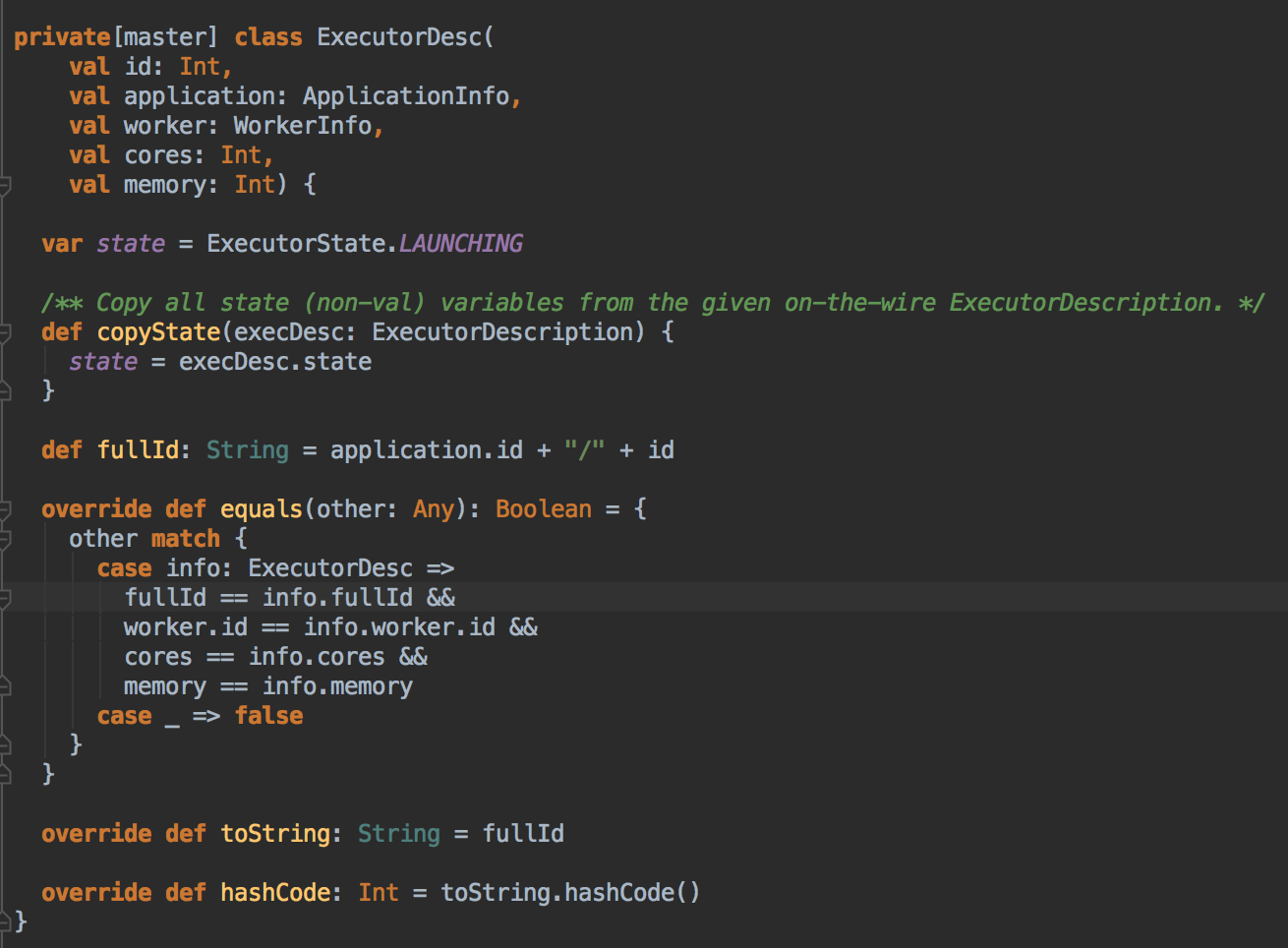
- 新增 Executor 后然后就真正的启动 Executor,准备具体要为当前应用程序分配的 Executor 信息后,Master 要通过远程通信发指令给 Worker 來具体启动 ExecutorBackend 进程,紧接给我们应用程序的 Driver 发送一个 ExecutorAdded 的信息。(Worker收到由Master发送LaunchExector信息之后如何处理可以参考我的下一篇博客!)
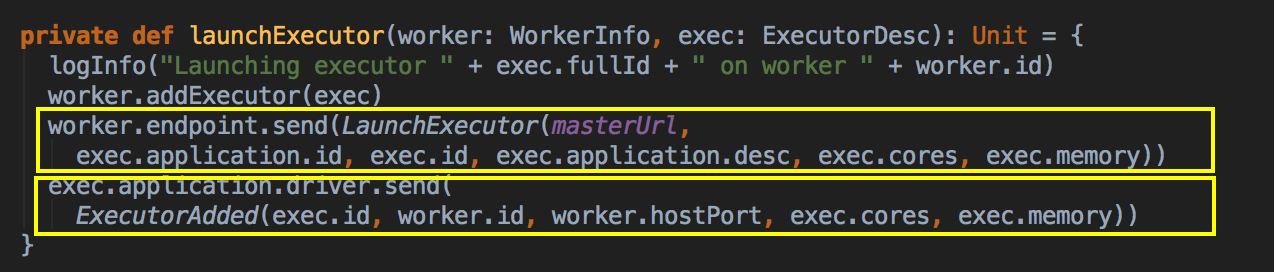
LaunchExecutor case class 数据结构,Master 会把这个数据发送到 Worker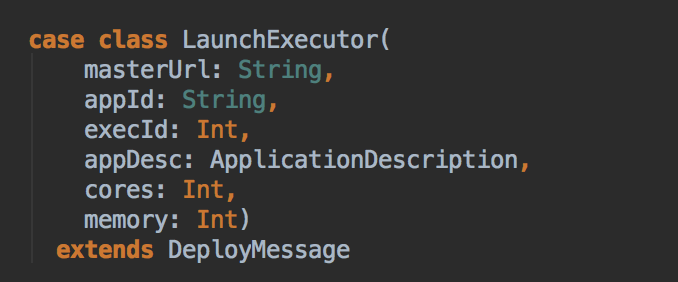
Master 会把这个数据发送到 Driver
[总结部份]
更新中......
Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结的更多相关文章
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文主要讲述在standalone cluster部署模式下,Spark Application在整个运行期间,资源(主要是cpu core和内存)的申请与 ...
- spark yarn cluster模式下任务提交和计算流程分析
spark可以运行在standalone,yarn,mesos等多种模式下,当前我们用的最普遍的是yarn模式,在yarn模式下又分为client和cluster.本文接下来将分析yarn clust ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- netty源码解解析(4.0)-23 ByteBuf内存管理:分配和释放
ByteBuf内存分配和释放由具体实现负责,抽象类型只定义的内存分配和释放的时机. 内存分配分两个阶段: 第一阶段,初始化时分配内存.第二阶段: 内存不够用时分配新的内存.ByteBuf抽象层没有定义 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- spark源码解析大全
第1章 Spark 整体概述 1.1 整体概念 Apache Spark 是一个开源的通用集群计算系统,它提供了 High-level 编程 API,支持 Scala.Java 和 Pytho ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
随机推荐
- Oracle 通过数据字典查询系统信息
简介:数据字典记录了数据库系统的信息,他是只读表和视图的集合,数据字典的所有者是sys用户.注:用户只能在数据字典上执行查询操作,而维护和修改是由系统自己完成的. 1.数据字典的组成:数据字典包括数据 ...
- HTML5离线资源缓存简介
cache manifest 示例 要使用离线资源缓存,开发者首先要提供一个 cache manifest 文件 它列出了所有需要在离线状态下使用的资源,浏览器会把这些资源缓存到本地 下面就是一个 c ...
- VS2008默认的字体居然是 新宋体
本人还是觉得 C#就是要这样看着舒服
- Bootstrap使用模态框modal实现表单提交弹出框
Bootstrap 模态框(Modal)插件 模态框(Modal)是覆盖在父窗体上的子窗体.通常,目的是显示来自一个单独的源的内容,可以在不离开父窗体的情况下有一些互动.子窗体可提供信息.交互等.如果 ...
- Mybatis Dao开发的两种方式(一)
原始Dao的开发方式: 1.创建数据库配置文件db.properties jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localh ...
- Exception from System.loadLibrary(smjavaagentapi) java.lang.UnsatisfiedLinkError: no smjavaagentapi in java.library.path
可能原因: 缺少smjavaagentapi.jar文件或者libsjavaagentapi.so缺少相关的依赖包. 解决方法: 1. 检查sso的lib下面是否有smjavaagentapi.jar ...
- 项目管理系列--从零开始Code Review[转]
从零开始Code Review 这篇帖子不是通篇介绍Code Review的方法论, 而是前大段记录了我们团队怎么从没有这个习惯到每天都进行review的过程, 后小段给出了我的一些建议. 希望能对诸 ...
- .netCore2.0 过滤器
不同的过滤器类型会在执行管道的不同阶段运行,因此他们各自有一套自己的应用场景.可以根据不同的业务需求和在请求管道中的执行位置来选择合适创建的过滤器.运行与MVC Action调用管道内的过滤器有时候被 ...
- ASP.NET Visual Studio2010 发布Web网站问题详解
今天研究了一下如何发布web网站,之前总是没耐心,遇到点问题就没心情搞了,今天总算有点耐心搞明白了.其实遇到的问题还是挺多的,网上也没有太全的解释,所以结合自己还有别人的方法进行一下总结. 环境:Wi ...
- JDBC编程错误:Exception in thread "main" java.sql.SQLException: Access denied for user ''@'localhost' (using password: YES)
出现上面的错误是因为连接数据库的用户名不对或密码赋值不对,请对用户名和密码进行检查. 或者在程序中没有获取到正确的用户名或密码.看是否少写了用户名或密码.