MLP 之手写数字识别
0. 前言
前面我们利用 LR 模型实现了手写数字识别,但是效果并不好(不到 93% 的正确率)。 LR 模型从本质上来说还只是一个线性的分类器,只不过在线性变化之后加入了非线性单调递增 sigmoid 函数进行一一映射。实际上,这里的非线性变换对于我们分类来说是几乎没有什么作用的(在分类上,它等价于线性变换之后挑选出输出值最大的节点作为我们的预测结果),于是我们考虑用更复杂一点的带有一个隐层的 MLP (Multi-Layer Perceptron) 模型。
1. 模型
MLP 模型可以看作是在输入空间经过非线性变换(第一层与第二层)之后的 LR(第二层与第三层), MLP 的优势在于,一个经过训练的 MLP 的可以由第一层的输入经过非线性变换映射到另外一个线性可分的由隐层节点组成的空间里去。由于activation function 可以取很多种类型 (excluding polynomials), a two-layer net work with linear outputs can uniformly approximate any continuous function on a compact input domain to arbitrary accuracy provided the network has a sufficiently large number of hidden units, 隐层这种优良的表现能力,也是 deeplearning 的基础。
下面我们来看看具有 3 个隐层, 1000 个隐层节点的神经网络对 cos 函数的回归效果:
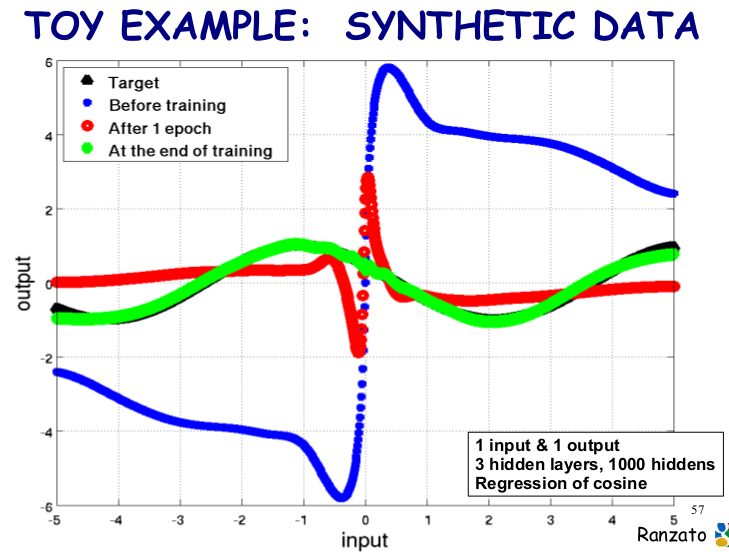
理解了前面两篇博客,对 bp 算法有了直观理解,明白了反向求导过程,再来看这个程序就变得非常简单了。在这个程序里面,我们的 MLP 模型可以表示如下:

用公式可以表示成:

这个模型包含的参数包括:

如果利用 SGD 来学习这个模型,我们需要知道 Loss Function (程序中加入了 L1 和 L2 范式)对于每个参数的偏导值 。 这里,我们可以采用前面已经介绍过的 BP 算法 (BP 算法其实就是计算 ANN 中各个参数导数的一种快速算法,就像 FDCT 对于 DCT 的快速计算。在 Theano 库里面,由于函数是自动求导的,所以在下面的代码中我们几乎看不到 BP 的具体实现过程,我猜想 BP 过程应该是 Theano 自动完成的)。
。 这里,我们可以采用前面已经介绍过的 BP 算法 (BP 算法其实就是计算 ANN 中各个参数导数的一种快速算法,就像 FDCT 对于 DCT 的快速计算。在 Theano 库里面,由于函数是自动求导的,所以在下面的代码中我们几乎看不到 BP 的具体实现过程,我猜想 BP 过程应该是 Theano 自动完成的)。
2. 构建
只带有一个隐层的 MLP 的 hidden layer 到 output layer 在结构上与 LR 没有多大的差别。我们可以在之前的 LR 基础上添加从 input layer 到 hidden layer 的结构, 就构成了这一小节中的 MLP。于是乎,我们构建了一个隐层节点,隐层的非线性函数设定为 tanh 函数(由 sigmoid 函数往下平移 0.5 再将值域扩大 2 倍)。对于隐层节点为 tanh 函数的神经网络来说, MLP 的权重空间具有很强的对称性,假设某一个解是 MLP 的最优解,那么:
- 将任意一个隐层节点的前后权重同时乘以 -1, 输出值不变,如果有 M 个 hidden units, 那么就有对应的 2^M 次方个等价的解。
- 将 M 个隐层连同它连接的权重进行不同的排列组合,最后的输出也是等价的, 这里对应有 M! 个等价的解。
这样,只有一个隐层的 MLP ,如果隐层节点采用 tanh 函数,那么权重空间就有 M!2^M 个等价的解。
全零向量正好处在解的对称中心,梯度为 0, 不能作为权重的初始值,所以需要对权重进行随机初始化,随机范围与 activation function 相关,有论文推导这一范围,暂时来不及细看。
接着我们把刚刚建立的隐层结构的输出作为 LR 的输入 (在 theano 里面实现十分简洁, graph structures 的方式真是太方便啦),这样,一个 MLP 的神经网络就搭好了。
3. 值得深入的地方
- 有些参数很难用梯度下降法进行优化, partly because some parameters are discrete values and others are real-valued. 并且由于优化的目标函数是非凸的,寻找极小值的工作量非常大,这些问题在 Yann LeCun 的论文有很好的 overview。
- tanh 相对于 sigmoid 函数有什么优势?
- 权重初始化的范围。如何既保证初始时梯度最大,有保障 FP 和 BP 阶段信息 (variance) 良好的传递性?
- learning rate 如何确定?是选择一个常量还是选择一个与迭代次数有关的变量?如果选常量,与什么因素有关?
- 隐层节点数目如何确定?一般来说,输入的 data set distribution 越复杂,需要的网络“容量”越大,隐层节点数目越多。
- Regularizaiton Parameter 如何确定才能不至于导致模型太 underfitting or overfitting?
这是源代码下载地址,具体细节就不介绍了。用这种方法进行手写数字识别,在 5w 张图片上进行 828 次迭代训练,正确率可以达到 98.35%, 相比 LR 模型,的确是一个很大的提升!
参考资料:
[1]: deeplearning tutorial
[2]: PRML, Bishop, chapter 05
MLP 之手写数字识别的更多相关文章
- keras—多层感知器MLP—MNIST手写数字识别
一.手写数字识别 现在就来说说如何使用神经网络实现手写数字识别. 在这里我使用mind manager工具绘制了要实现手写数字识别需要的模块以及模块的功能: 其中隐含层节点数量(即神经细胞数量)计算 ...
- keras框架的MLP手写数字识别MNIST,梳理?
keras框架的MLP手写数字识别MNIST 代码: # coding: utf-8 # In[1]: import numpy as np import pandas as pd from kera ...
- Keras mlp 手写数字识别示例
#基于mnist数据集的手写数字识别 #构造了三层全连接层组成的多层感知机,最后一层为输出层 #基于Keras 2.1.1 Tensorflow 1.4.0 代码: import keras from ...
- CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- 【PaddlePaddle系列】手写数字识别
最近百度为了推广自家编写对深度学习框架PaddlePaddle不断推出各种比赛.百度声称PaddlePaddle是一个“易学.易用”的开源深度学习框架,然而网上的资料少之又少.虽然百度很用心地提供 ...
- 卷积神经网络CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- C#中调用Matlab人工神经网络算法实现手写数字识别
手写数字识别实现 设计技术参数:通过由数字构成的图像,自动实现几个不同数字的识别,设计识别方法,有较高的识别率 关键字:二值化 投影 矩阵 目标定位 Matlab 手写数字图像识别简介: 手写 ...
- 【深度学习系列】PaddlePaddle之手写数字识别
上周在搜索关于深度学习分布式运行方式的资料时,无意间搜到了paddlepaddle,发现这个框架的分布式训练方案做的还挺不错的,想跟大家分享一下.不过呢,这块内容太复杂了,所以就简单的介绍一下padd ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
随机推荐
- HTML5表单之Input 类型- Date Pickers(日期选择器)
HTML5 拥有多个可供选取日期和时间的新输入类型: date-选取日.月.年 month-选取月.年 week-选取周和年 time-选取时间(小时和分钟) datetime-选取时间.日.月.年( ...
- JS判断客户端是否是iOS或者Android手机移动端
var u = navigator.userAgent; var isAndroid = u.indexOf('Android') > -1 || u.indexOf('Adr') > - ...
- 获取分组后的TOP 1和TOP N记录
MySQL获取分组后的TOP 1和TOP N记录 有时会碰到一些需求,查询分组后的最大值,最小值所在的整行记录或者分组后的top n行的记录,在一些别的数据库可能有窗口函数可以方面的查出来,但是MyS ...
- java中的抽象方法与抽象类
在继承时,会遇到一个问题.如果很多子类都要继承父类的一个方法,但是实现的逻辑都不一样. 这时候父类只提供了方法名,但是没有具体的方法体. 例如,男孩类和女孩类都继承人类这一个父类.人类有爱好这个方法, ...
- linux命令(30):touch命令
实例一:创建不存在的文件 touch test.log test1.log 实例二:更新log.log的时间和log2012.log时间戳相同 touch -r test.log test1.log ...
- http跟https的区别
http: Hypertext transform protocol 超文本传输协议 是一个为了传输超媒体文档(比如html)的应用层协议 是为了web的浏览器跟web的server端的交流而设计的, ...
- CocoaPods第三方类库依赖管理
安装cocoapods 1.移除ruby的源地址 gem sources --remove https://rubygems.org/ 2.添加ruby的源地址 gem sources -a ...
- python类的使用与多文件组织
多文件的组织 跨目录级导入模块 from ..xxfile import xxmodule #从上级目录中的xxfile中导入xxmodule import xxsub_dir.xxfile #从xx ...
- **极光推送PHP服务器端推送移动设备消息(Jpush V2 api)
jpush.php 这是推送方法 用到curl发送请求 <?php /** * 极光推送php 服务器端 * @author yalong sun * @Email <syl_ad@1 ...
- vue实现简单在线聊天
vue实现简单在线聊天 引用mui的ui库,ES6的 fetch做网络请求 //html <!DOCTYPE html> <html> <head> <met ...