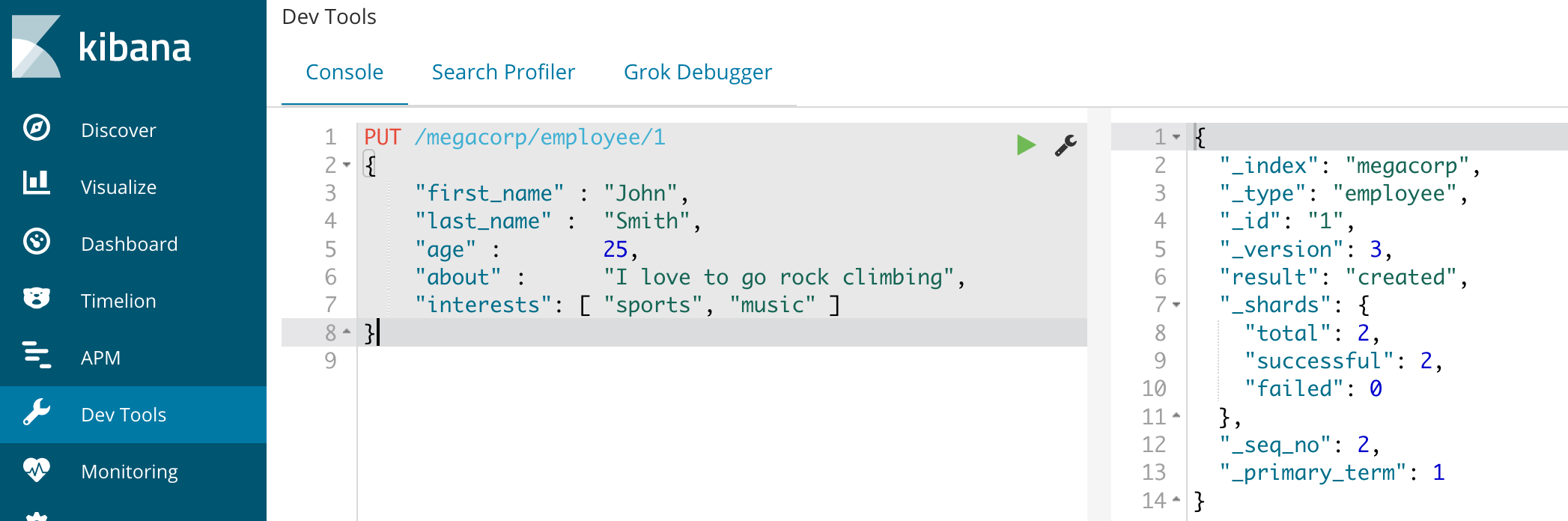
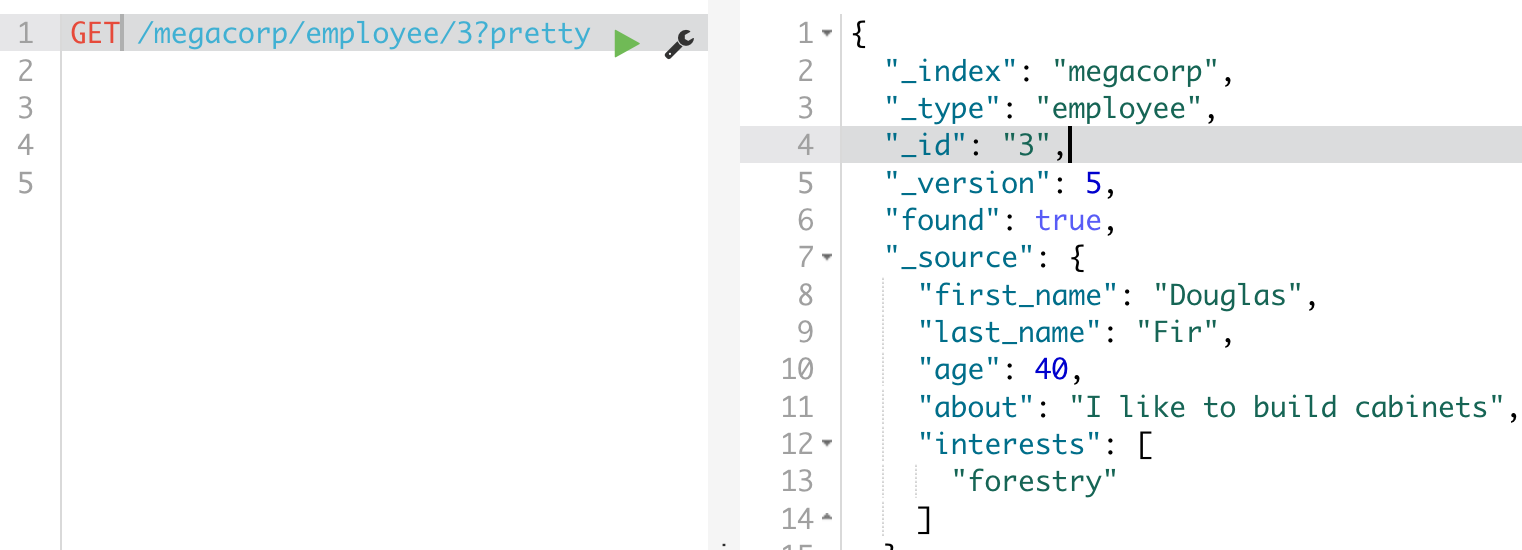
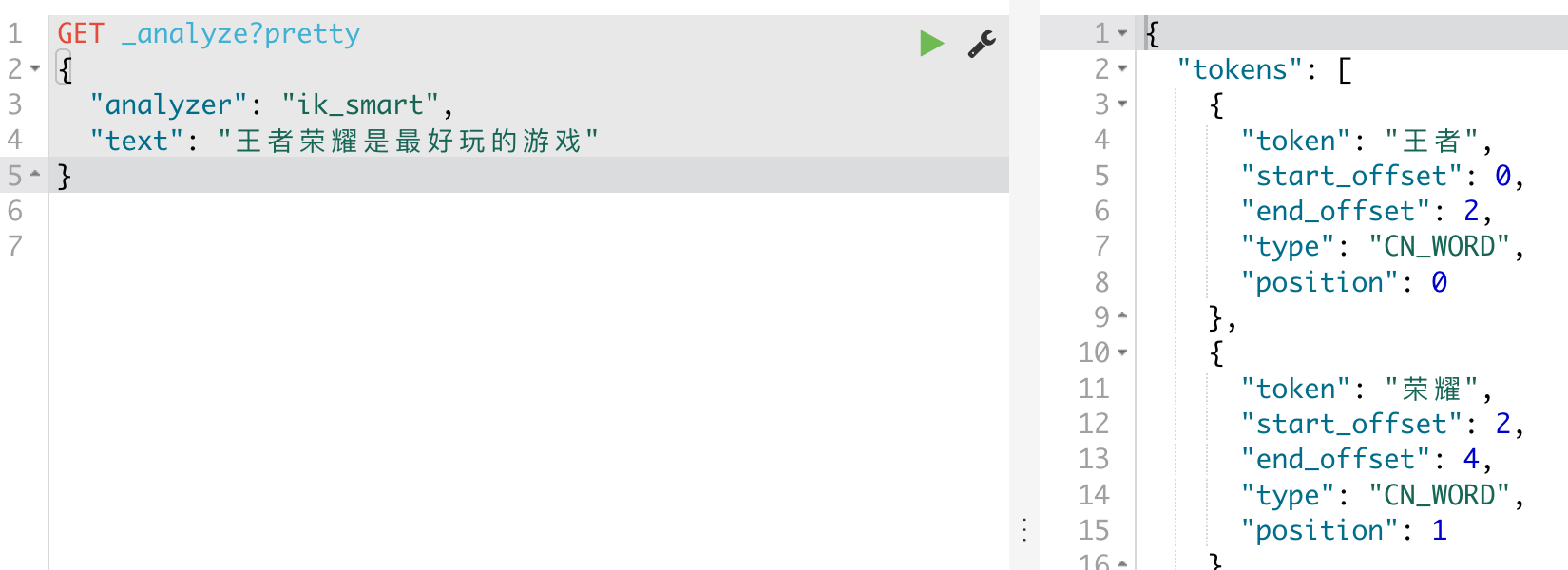
elasticsearch 初步
|
a
|
172.20.10.2
|
9200
|
物理机
|
|
b
|
172.20.10.3
|
9200
|
虚拟机
|
#集群名称
cluster.name: my-application
#节点名称
node.name: node-1
# 是否可以作为master节点,默认true
node.master: true
#本机地址
network.host: 172.20.10.2
#本机es端口
http.port: 9200
#单播模式下,具有master资格的节点列表,新加入的节点向这个列表中的节点发送请求来加入集群
discovery.zen.ping.unicast.hosts: ["172.20.10.2", "172.20.10.3"]
#一个节点需要看到的具有master资格的节点的最小数量
discovery.zen.minimum_master_nodes: 1
#es的数据存储目录
path.data: /var/elasticsearch/data
#es日志存储目录
path.logs: /var/elasticsearch/logs
ES_PATH_CONF=/opt/elasticsearch/config
export ES_PATH_CONF

ERROR: [2] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
*** hard nofile 65536
*** soft nofile 65536


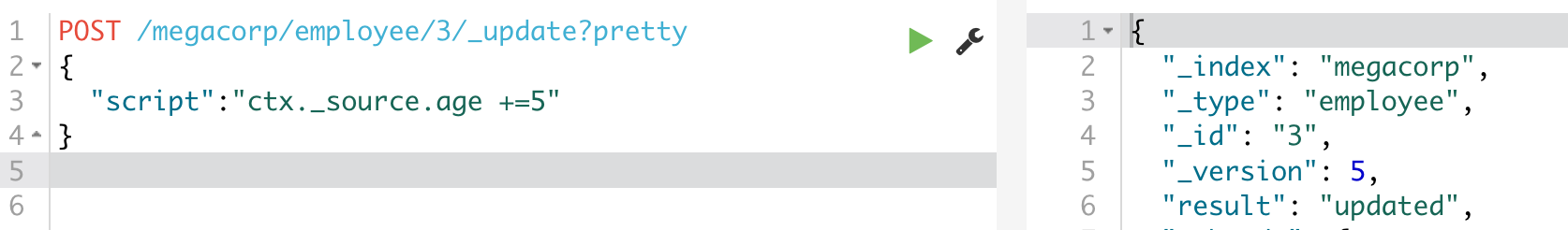
elasticsearch 初步的更多相关文章
- Elasticsearch初步使用(安装、Head配置、分词器配置)
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.ElasticSearch简单说明 a.ElasticSearch是一个基于Lu ...
- ElasticSearch初步了解和安装(windows上安装)
ElasticSearch是什么 ElasticSearch(一般简称es)是一个基于Lucene的分布式搜索和数据分析引擎.它提供了REST api 的操作接口.它可以快速的存储.搜索.分析海量数据 ...
- 全文检索学习历程目录结构(Lucene、ElasticSearch)
1.目录 (1) Apache Lucene(全文检索引擎)—创建索引:http://www.cnblogs.com/hanyinglong/p/5387816.html (2) Apache Luc ...
- Elasticsearch 中文分词(elasticsearch-analysis-ik) 安装
由于elasticsearch基于lucene,所以天然地就多了许多lucene上的中文分词的支持,比如 IK, Paoding, MMSEG4J等lucene中文分词原理上都能在elasticsea ...
- Open Source
资源来源于http://www.cnblogs.com/Leo_wl/category/246424.html RabbitMQ 安装与使用 摘要: RabbitMQ 安装与使用 前言 吃多了拉就是队 ...
- 沉淀再出发:ELK使用初探
沉淀再出发:ELK使用初探 一.前言 ELK是Elasticsearch.Logstash.Kibana的简称,这三者是核心套件,但并非全部. 最近ElasticSearch可以说是非常火的一款开源软 ...
- elasticsearch学习笔记——安装,初步使用
前言 久仰elasticsearch大名,近年来,fackbook,baidu等大型网站的搜索功能均开始采用elasticsearch,足见其在处理大数据和高并发搜索中的卓越性能.不少其他网站也开始将 ...
- Elasticsearch suggester搜索建议初步
环境 Elasticsearch 2.3.5 Elasticsearch-ik-plugin 实现 搜索建议的对象 假设有以下两个json对象,需要对其中tags字段进行搜索建议: //对象Produ ...
- Lucene/ElasticSearch 学习系列 (2) Information Retrival 初步之名词解释
计算机领域一半是理论,一半是在理论基础之上的应用.要想深入地掌握某个方面的应用,就需要先学习那方面的理论. “搜索”是应用,其背后的理论是 "Information Retrieval&qu ...
随机推荐
- 学习python2
字符串遍历 列表遍历 元组遍历 字典遍历 <1> 遍历字典的key(键) <2> 遍历字典的value(值) <3> 遍历字典的项(元素) <4> 遍历 ...
- C++ 内敛函数
在主调函数调用函数时,先将现场压入栈以保存现场-转去执行被掉函数-返回主调函数.现场出栈以恢复现场-继续往下执行. 为了减少函数调用的成本,特别是对于小型函数,C++提供了内敛函数(inline).C ...
- Java NIO学习-详细内容(一)
一.三大类 1.Channels FileChannel DatagramChannel SocketChannel ServerSocketChannel 2.Selector与SelectionK ...
- Backup--完整备份会打破现有的日志备份链么?
--问题描述: --对数据库有一个周期性数据库备份和事务日志备份的维护计划,在维护计划外有工作人员对数据库进行完整备份,该备份会打乱现有的日志备份链么? --===================== ...
- RobotFramework与Jenkins集成后失败用例重跑
Jenkins的执行Windows批处理命令填写如下: call pybot.bat -i 1adsInterface 01_测试用例\接口测试用例\adsInterface.txt call pyb ...
- [C#]C#中字符串的操作
1.Replace(替换字符):public string Replace(char oldChar,char newChar);在对象中寻找oldChar,如果寻找到,就用newChar将oldCh ...
- .net core i上 K8S(五).netcore程序的hostip模式
上一章讲了pod的管理,今天再分享一个pod的访问方式 1.Pod的HostIP模式 Pod的HostIP模式,可以通过宿主机访问pod内的服务,创建yaml文件如下 apiVersion: v1 k ...
- 关于Git的那些事
以前一直使用tfs 或者svn当做代码管理器,随着GitHub的越来越火,git的使用人说也越来越多,这不我也开始来折腾git .GitHub的连接速度有的时候很慢,在国内不是太稳定,正好看到开源中国 ...
- Linux下卸载删除.Net Core
最近在技术博客和技术交流群遇到很多小伙伴们在Linux下更新或者安装.Net Core SDK后dotnet命令无法识别等问题,现如下解决: 卸载SDK命令 sudo yum remove dotne ...
- 用Visual Studio 2015 编译张帆的第一个NT式驱动,并且成功安装到Windows XP里面!!!
开发工具:Visual Studio 2015 企业版 目 标 机:Windows XP X86 前提:我们已经成功安装了Visual Studio 2015以及WDK,而且更重要一点是一定要SDK版 ...