step5: 编写spider爬取
改写parse函数
实现功能:
1.获取文章列表页中的文章url并交给scrapy下载后,交给解析函数进行具体字段的解析
2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse
提取一页列表中的文章url
#解析列表页中所有文章的url,遍历出来
def parse(self, response):
# 解析列表页中的所有url并交给scrapy下载后进行解析
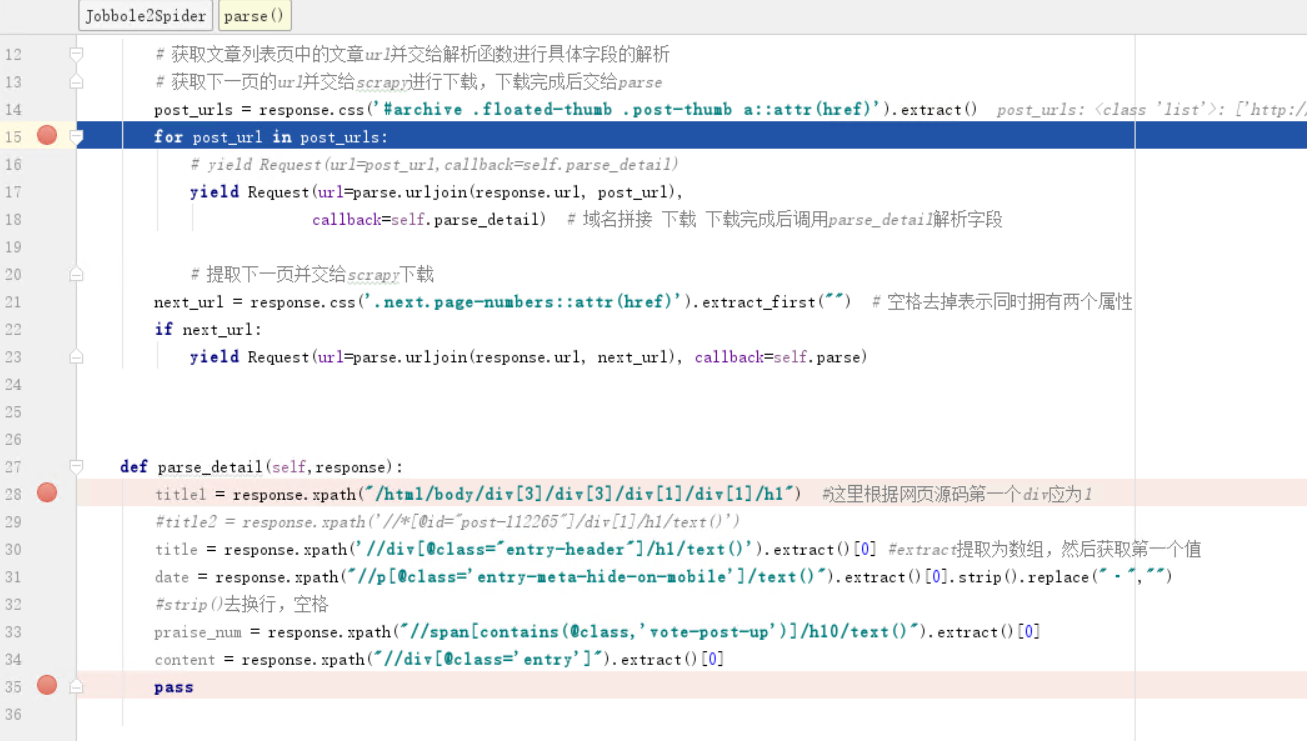
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
print(post_url)
调试输出结果

如何让scrapy进行下载
引入request对象
from scrapy.http import Request
修改提取字段类类名为parse_detail,引入parse类进行域名拼接,yield下载
from urllib import parse
def parse(self, response):
#获取文章列表页中的文章url并交给解析函数进行具体字段的解析
#获取下一页的url并交给scrapy进行下载,下载完成后交给parse
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
#yield Request(url=post_url,callback=self.parse_detail)
yield Request(url=parse.urljoin(response.url, post_url),callback=self.parse_detail) #域名拼接 下载 下载完成后调用parse_detail解析字段
获取下一页并交给scrapy进行下载
#提取下一页并交给scrapy下载
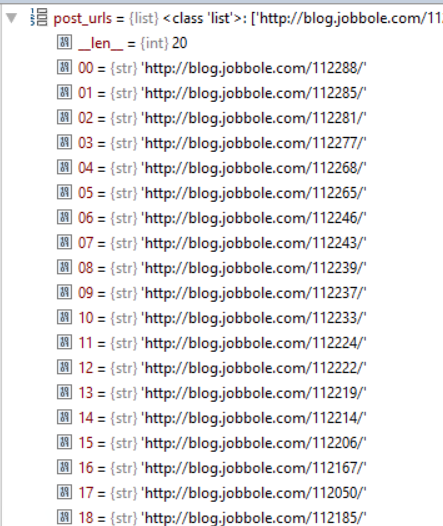
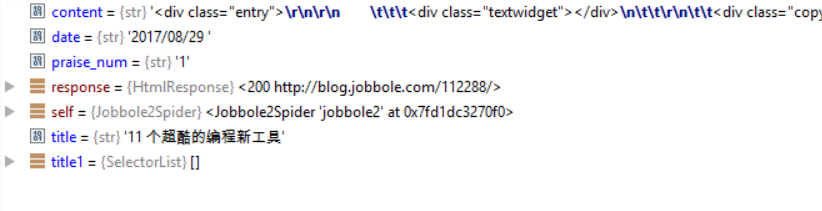
next_url = response.css('.next.page-numbers::attr(href)').extract_first("")#空格去掉表示同时拥有两个属性
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) #继续调用parse解析出列表页中具体文章的url
调试前修改start_url为all-posts
调试结果
step5: 编写spider爬取的更多相关文章
- 第八篇 编写spider爬取jobbole的所有文章
通过scrapy的Request和parse,我们能很容易的爬取所有列表页的文章信息. PS:parse.urljoin(response.url,post_url)的方法有个好处,如果post_ur ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
- 用java编写爬虫爬取电影
一.爬取前提1)本地安装了mysql数据库2)安装了idea或者eclipse等开发工具 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的htm ...
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy-redis实现分布式爬取的过程与原理
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求 ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- Java爬取51job保存到MySQL并进行分析
大二下实训课结业作业,想着就爬个工作信息,原本是要用python的,后面想想就用java试试看, java就自学了一个月左右,想要锻炼一下自己面向对象的思想等等的, 然后网上转了一圈,拉钩什么的是动态 ...
随机推荐
- 腾讯云/阿里云/微软云安装ISO镜像系统方法
如今云服务的盛行,我们的开发和应用中场景应用也层出不穷,有时我们需要安装自由的镜像却越来越难,甚至有些云出于安全原因自己用户安装自由镜像,那么今天将带给大家安装自有镜像的方法. 前提条件:你的现有服务 ...
- Oracle导出导入数据
Oracle数据导入导出imp/exp就相当与oracle数据还原与备份, 利用这个功能你可以构建俩个相同的数据库,一个用来测试,一个用来正式使用. 可以在SQLPLUS.EXE或者DOS(命令行)中 ...
- python学习之路 七 :生成器、迭代器
本节重点: 掌握列表生成式.生成器.迭代器 一.生成式 现在有个需求,把[1,2,3,4,5,6,7,8,9,10]中的每个值加1. # 二逼青年版 a = [0,1,2,3,4,5,6,7,8,9 ...
- D. Magic Box(几何)
One day Vasya was going home when he saw a box lying on the road. The box can be represented as a re ...
- JS 性别选择
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- POJ - 2031C - Building a Space Station最小生成树
You are a member of the space station engineering team, and are assigned a task in the construction ...
- 洛谷P2495 [SDOI2011]消耗战(虚树)
题面 传送门 题解 为啥一直莫名其妙\(90\)分啊--重构了一下代码才\(A\)掉-- 先考虑直接\(dp\)怎么做 树形\(dp\)的时候,记一下断开某个节点的最小值,就是从根节点到它的路径上最短 ...
- [ActionScript 3.0] 利用ColorTransform实现对象(图片)的曝光过渡效果
原图效果 过渡效果 这个效果可以用帧动画实现较为简单,只需要调节这个影片剪辑的色彩效果样式里面的高级选项的三个通道值,以下用代码简单测试,可作为文档类: package { import com.tw ...
- [ActionScript 3.0] 十进制与二进制,十六进制等数据之间的相互转换
将十进制转换为二进制,方法是:将数字除以2,根据余数来从右往左排列二进制的位数,如下以十进制数10为例 10除以2得5,余数为0,故第一个位置为0: 5除以2得2,余数为1,故第二个位置为1: 2除以 ...
- shell的算术运算
变量的数值计算方法大致有双括号 (()), expr, bc, $[ ] 例子1 注意:2**3表示2的3次方,a++表示先输出a自身的值,然后进行++的运算: --a表示先进行--的运算,然后再输 ...