常用algorithm及其Python实现
冒泡排序
def bubble_sort(li):
for i in range(len(li)-1): # i表示第几趟
for j in range(len(li)-i-1): # j表示图中的箭头
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
============冒泡排序(优化)============
def bubble_sort_1(li):
for i in range(len(li)-1): # i表示第几趟
exchange = False
for j in range(len(li)-i-1): # j表示图中的箭头
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
return
选择排序
def select(li):
for i in range(len(li)):
# 第i趟开始时 无序区:li[i:]
# 找无序区最小值,保存最小值的位置
min_index = i
for j in range(i + 1, len(li)):
if li[j] < li[min_index]:
min_index = j
li[min_index], li[i] = li[i], li[min_index]
插入排序
def insert_sort(li):
for i in range(1, len(li)): # i是摸到的牌的下标
tmp = li[i] # tmp是摸到牌的值
# 方法一
j = i - 1 # j是手里最后一张牌的下标 li[j]是手里最后一张牌的值
while j >= 0 and li[j] > tmp: # 两个终止条件:j小于0表示tmp是最小的 顺序不要乱
li[j+1] = li[j]
j -= 1
# 方法二
# for j in range(i-1, -1, -1):
# if li[j] > tmp:
# li[j+1] = li[j]
# else:
# break
li[j+1] = tmp #将摸到的牌 插入到 往前挪过之后的 j 的后一位
快速排序
def part(li, left, right): # 列表,最左索引,最右索引
tmp = li[left] # 先找个临时变量把第一个元素存起来
while left < right: # 当最左小于最右
while left < right and li[right] >= tmp: # 当最左<最右 且 最右边的值大于等于临时变量
right -= 1 # 最右 往左 挪 1 个单位长度
li[left] = li[right] # 都不满足:把挪完之后的最右的值 赋值给 最左的值(即最右的值小于临时变量时,这个值挪到当前最左的值)
while left < right and li[left] <= tmp: # 当最左<最右 且 最左边的值小于等于临时变量
left += 1 # 最左 往右 挪 1 个单位长度
li[right] = li[left] # 都不满足:把挪完之后的最左的值 赋值给 最右的值(即最左的值大于临时变量时,这个值挪到当前最右的值)
li[left] = tmp # 当前最左最右的值相等时,把这个值赋给临时变量
return left # 返回当前临时变量的索引
def quick(li, left, right):
if left < right: # 如果左索引<右索引
mid = part(li, left, right) # 调用part进行分区 返回一个索引赋给mid
quick(li, left, mid - 1) # 递归调用quick 直到left=mid-1
quick(li, mid + 1, right) # 递归调用quick 直到mid+1=right
li = list(range(1000))
import random
random.shuffle(li)
print(li)
quick(li, 0, len(li) - 1)
print(li)
堆排序

def sift(li, low, high):
tmp = li[low]
i = low
j = 2 * i + 1
while j <= high: # 退出条件2:当前i位置是叶子结点,j位置超过了high
# j 指向更大的孩子
if j + 1 <= high and li[j+1] > li[j]:
j = j + 1 # 如果右孩子存在并且更大,j指向右孩子
if tmp < li[j]:
li[i] = li[j]
i = j
j = 2 * i + 1
else: # 退出条件1:tmp的值大于两个孩子的值
break
li[i] = tmp
@cal_time
def heap_sort(li):
# 1. 建堆
n = len(li)
for i in range(n//2-1, -1, -1):
# i 是建堆时要调整的子树的根的下标
sift(li, i, n-1)
# 2.挨个出数
for i in range(n-1, -1, -1): #i表示当前的high值 也表示棋子的位置
li[i], li[0] = li[0], li[i]
# 现在堆的范围 0~i-1
sift(li, 0, i-1)
归并排序
def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high:
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
# for k in range(low, high+1):
# li[k] = ltmp[k-low]
li[low:high+1] = ltmp
def merge_sort(li, low, high):
if low < high:
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid+1, high)
merge(li, low, mid, high)
# li = list(range(10000))
# random.shuffle(li)
# merge_sort(li, 0, len(li)-1)
# print(li)
li = [10,4,6,3,8,2,5,7]
merge_sort(li, 0, len(li)-1)
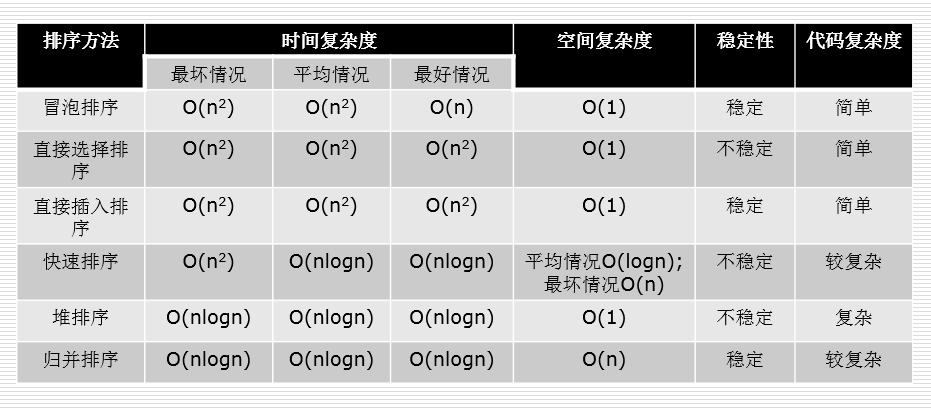
总结
参考资料
http://www.cnblogs.com/haiyan123/p/8395926.html
常用algorithm及其Python实现的更多相关文章
- 常用的自定义Python函数
常用的自定义Python函数 1.时间戳转为日期字串,精确到ms.单位s def timestamp2datems(timestamp): ''' 时间戳转为日期字串,精确到ms.单位s :param ...
- MongoDB 安装详细教程 + 常用命令 + 与 Python 的交互
MongoDB 简介 MongoDB (名称来自 humongous/巨大无比的, 是一个可扩展的高性能,开源,模式自由,面向文档的NoSQL,基于 分布式 文件存储,由 C++ 语言编写,设计之初旨 ...
- ProE常用曲线方程:Python Matplotlib 版本代码(蝴蝶曲线)
花纹的生成可以使用贴图的方式,同样也可以使用方程,本文列出了几种常用曲线的方程式,以取代贴图方式完成特定花纹的生成. 注意极坐标的使用................. 前面部分基础资料,参考:Pyt ...
- 常用正则表达式与python中的re模块
正则表达式是一种通用的字符串匹配技术,不会因为编程语言不一样而发生变化. 部分常用正则表达式规则介绍: . 匹配任意的一个字符串,除了\n * 匹配任意字符串0次或者任意次 \w 匹配字母.数字.下划 ...
- 矩阵或多维数组两种常用实现方法 - python
在python中,实现多维数组或矩阵,有两种常用方法: 内置列表方法和numpy 科学计算包方法. 下面以创建10*10矩阵或多维数组为例,并初始化为0,程序如下: # Method 1: list ...
- Spark中RDD的常用操作(Python)
弹性分布式数据集(RDD) Spark是以RDD概念为中心运行的.RDD是一个容错的.可以被并行操作的元素集合.创建一个RDD有两个方法:在你的驱动程序中并行化一个已经存在的集合:从外部存储系统中引用 ...
- 网站渗透常用到的Python小脚本
0×00渗透的很多时候,找到的工具并不适用,自己码代码才是王道,下面三个程序都是渗透时在网络上找不到合适工具,自己辛苦开发的,短小使用,求欣赏,求好评. 0×01记录root密码小工具 root.py ...
- 常用算法及其Python实现
冒泡排序 def bubble_sort(li): for i in range(len(li)-1): # i表示第几趟 for j in range(len(li)-i-1 ...
- ProE常用曲线方程:Python Matplotlib 版本代码(玫瑰曲线)
Pyplot教程:https://matplotlib.org/gallery/index.html#pyplots-examples 玫瑰曲线 文字描述 平面内,围绕某一中心点平均分布整数个正弦花瓣 ...
随机推荐
- 112. Path Sum (判断路径和是否等于某值)
Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up a ...
- Resharper 快捷键
编辑 Ctrl + Space 代码完成 Ctrl + Shift + Space代码完成 Ctrl + Alt + Space代码完成 Ctrl + P 显示参数信息 Alt + Insert ...
- Linux 下的 core dump
core dump 的基本概念 当一个进程要异常终止时 ,可以选择把进程的用户空间内存数据全部保存到磁盘上 ,文件名通常是 core, 这叫做 Core Dump.通常情况下,core文件会 ...
- 20145222黄亚奇《网络对抗》web安全基础实践
web安全基础实践 实验后回答问题 (1)SQL注入攻击原理,如何防御 原理:指web应用程序对用户输入数据的合法性没有判断,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语 ...
- Linux系统运行级别配置
Linux的运行级别 Linux的运行级别有七种,可以通过查看/etc/inittab文件进行了解: Level0:系统停机状态,默认系统运行级别不能设置为0,否则系统不能正常启动: Level1:单 ...
- PHP设计模式(一):简单工厂模式
- tar 解压命令学习与总结
tar -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个 ...
- js 前台ajax验证马克一下
function check_form(){ var email=$("#email").val(); var code=$("#code").val(); v ...
- 使用node-inspector调试NodeJS代码
使用node-inspector调试NodeJS代码 任何一门完备的语言技术栈都少不了健壮的调试工具,对于NodeJS平台同样如此,笔者研究了几种调试NodeJS代码的方式,通过对比,还是觉得node ...
- JMS-activMq与spring进行整合
对JMS做了一个简要介绍之后,接下来就讲一下Spring整合JMS的具体过程.JMS只是一个标准,真正在使用它的时候我们需要有它的具体实现,这里我们就使用Apache的activeMQ来作为它的实现 ...