LWIP再探----内存堆管理
LWIP的内存管理主要三种:内存池Pool,内存堆,和C库方式。三种方式中C库因为是直接从系统堆中分配内存空间且易产生碎片因此,基本不会使用,其他两种是LWIP默认全部采用的方式,也是综合效率和空间的一种实现方法,接下来将根据源码看看具体的内存管理方案的实现,其中内存池用的一些技巧,曾经让我一头雾水source insight都无法定位一些变量的声明,不过看明白才明白LWIP作者的厉害之处,接下来先说内存堆的实现。
内存堆
内存堆常见的实现方式是,通过申请一个大的内存空间,作为内存分配释放的总内存。LWIP也是这样实现的先定义的一个数组,然后将这块内存进行管理,看代码
//实际的内存堆数据声明
#ifndef LWIP_RAM_HEAP_POINTER
LWIP_DECLARE_MEMORY_ALIGNED(ram_heap, MEM_SIZE_ALIGNED + (2U*SIZEOF_STRUCT_MEM));
#define LWIP_RAM_HEAP_POINTER ram_heap
#endif
//中间的宏的定义 #ifndef LWIP_DECLARE_MEMORY_ALIGNED
#define LWIP_DECLARE_MEMORY_ALIGNED(variable_name, size) u8_t variable_name[LWIP_MEM_ALIGN_BUFFER(size)]
#endif
其中 MEM_SIZE_ALIGNE SIZEOF_STRUCT_MEM 的定义在mem.c文件中是这样定义的
/** All allocated blocks will be MIN_SIZE bytes big, at least!
* MIN_SIZE can be overridden to suit your needs. Smaller values save space,
* larger values could prevent too small blocks to fragment the RAM too much. */
#ifndef MIN_SIZE
#define MIN_SIZE 12
#endif /* MIN_SIZE */
/* some alignment macros: we define them here for better source code layout */
#define MIN_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MIN_SIZE)
#define SIZEOF_STRUCT_MEM LWIP_MEM_ALIGN_SIZE(sizeof(struct mem))
#define MEM_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MEM_SIZE)
这里需要提一下,LWIP中常用的 LWIP_MEM_ALIGN_SIZE 这个宏函数,这个宏定义如下
#ifndef LWIP_MEM_ALIGN_SIZE
#define LWIP_MEM_ALIGN_SIZE(size) (((size) + MEM_ALIGNMENT - 1U) & ~(MEM_ALIGNMENT-1U))
#endif
其中MEM_ALIGNMENT就是在配置文件中定义的对齐字节,这里先 加上MEM_ALIGNMENT - 1U,这个操作是为了避免,对齐后地址空间小于size值。
MEM_SIZE_ALIGNED:这个宏是将用户配置的内存堆总大小进行对齐后的大小 一般 MEM_SIZE_ALIGNED >= MEM_SIZE ,MEM_SIZE一般由用户配置。
SIZEOF_STRUCT_MEM:这个宏的大小内存控制块的占用空间的对齐后size大小。
内存控制块结结构体定义:
struct mem {
/** index (-> ram[next]) of the next struct */
mem_size_t next;
/** index (-> ram[prev]) of the previous struct */
mem_size_t prev;
/** 1: this area is used; 0: this area is unused */
u8_t used;
#if MEM_OVERFLOW_CHECK
/** this keeps track of the user allocation size for guard checks */
mem_size_t user_size;
#endif
};
next 保存的并不是地址,而是内存堆对应大数组的下标索引,prev同上,我猜想作者这样设计应该是为了内存释放时合并方便。通过最上面的代码可以看出来定义了一个ram_heap[ MEM_SIZE_ALIGNED + (2U*SIZEOF_STRUCT_MEM)]数组,其中多加了两个内存块的空间,一个是为了数组开头内存控制块的占用,另一个是为了后面取内存堆对齐地址会丢弃的部分增加的从而保证内存堆的总大小不小于用户配置的MEM_SIZE。
然后是内存堆的初始化
void
mem_init(void)
{
struct mem *mem; /* align the heap */
ram = (u8_t *)LWIP_MEM_ALIGN(LWIP_RAM_HEAP_POINTER);
/* initialize the start of the heap */
mem = (struct mem *)(void *)ram;
mem->next = MEM_SIZE_ALIGNED;
mem->prev = 0;
mem->used = 0;
/* initialize the end of the heap */
ram_end = (struct mem *)(void *)&ram[MEM_SIZE_ALIGNED];
ram_end->used = 1;
ram_end->next = MEM_SIZE_ALIGNED;
ram_end->prev = MEM_SIZE_ALIGNED; /* initialize the lowest-free pointer to the start of the heap */
lfree = (struct mem *)(void *)ram; if (sys_mutex_new(&mem_mutex) != ERR_OK) {
LWIP_ASSERT("failed to create mem_mutex", 0);
}
}
初始化过的内存堆结构示意图如下,就是将整个内存堆分成一块MEM_SIZE_ALIGNED的空闲块,和永久占用的结束块。
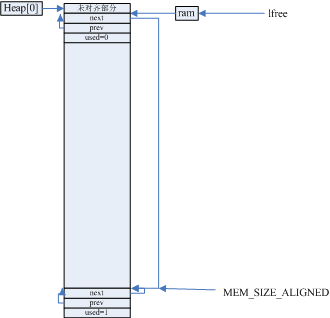
当进行内存申请时,LWIP采用最先匹配原则,并由lfree记着地址最低的空闲块地址,其中全局变量ram和ram_end分别记录着对齐后的堆起始和结束地址。内存分配函数如下,总的来说就是,将申请size进行对齐和合法检查后,从lfree指定的地方遍历,如果空闲且够size和内存控制块的总占用空间的话就开始处理,这里的处理是因为LWIP采用的是最先匹配原则,所有有可能当前内存比要需要的空间大的多,比如初始化后第一个申请的块,就会匹配到整个堆大小的块,因此不能全部拿走使用,LWIP采用的方式是,如果当前块的大小除去size和控制块的占用后剩余的部分不小于内存堆申请的最小size就要将多余的部分切除,返还给堆,否则返回一个比目标申请空间大的内存块,从而避免过小的内存块。源码简化注释后如下:
void *
mem_malloc(mem_size_t size)
{
mem_size_t ptr, ptr2;
struct mem *mem, *mem2; if (size == 0) {
return NULL;
}
/* 对齐操作调整size值,到对齐的倍数 */
size = LWIP_MEM_ALIGN_SIZE(size);
if (size < MIN_SIZE_ALIGNED) {
/*太小设置size为允许最小值 */
size = MIN_SIZE_ALIGNED;
}
if (size > MEM_SIZE_ALIGNED) {
/*超出总大小,失败返回空地址*/
return NULL;
}
/* 互斥 */
sys_mutex_lock(&mem_mutex);
/*根据最低空闲内存块地址,计算空闲地址起始索引值ptr。*/
for (ptr = (mem_size_t)((u8_t *)lfree - ram); ptr < MEM_SIZE_ALIGNED - size;
ptr = ((struct mem *)(void *)&ram[ptr])->next) {
mem = (struct mem *)(void *)&ram[ptr];
/*取ptr地址检查ptr地址处内存块是否够size加上控制块的总大小。不够:ptr=ram[ptr]->next返回第四步起始。*/
if ((!mem->used) &&
(mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size) {
/*足够。检查本内存块的进行裁切后剩余部分的大小是否小于最小内存块大小*/
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)) {
/*不是,则直接将本内存块切割*/
ptr2 = ptr + SIZEOF_STRUCT_MEM + size;
/* 将切下来的部分创建成一个新块*/
mem2 = (struct mem *)(void *)&ram[ptr2];
/* 将新块标记为空闲*/
mem2->used = 0;
/*新块的下一个块索引为原来的块的下一个块索引*/
mem2->next = mem->next;
/*新块的前一个块索引为原来块的起始索引*/
mem2->prev = ptr;
/*原来块的下一块索引更新为新块的索引*/
mem->next = ptr2;
/*标记原来的块已使用*/
mem->used = 1;
/*检查,新块的下一个块是否是结束块,如果不是,还要原整块的下一个块的前一个块新块更新为新块的索引*/
if (mem2->next != MEM_SIZE_ALIGNED) {
((struct mem *)(void *)&ram[mem2->next])->prev = ptr2;
}
} else {
/*是,则直接将本内存块不切割*/ mem->used = 1;
}
/*检查分配走的块的内存地址是否低于当前最低空闲地址lfree*/
if (mem == lfree) {
struct mem *cur = lfree;
/*遍历,更新最低空闲块地址lfree*/
while (cur->used && cur != ram_end) {
cur = (struct mem *)(void *)&ram[cur->next];
}
lfree = cur;
}
sys_mutex_unlock(&mem_mutex);
/*将申请到的内存偏移后返回,防止内存控制块被用户修改*/
return (u8_t *)mem + SIZEOF_STRUCT_MEM;
}
}
sys_mutex_unlock(&mem_mutex);
return NULL;
}
其中还考虑到有操作系统时的,内存分配函数的原子操作保护。每分配一块内存,就将内存链表重新连起来,方便后续的释放合并。
内存释放
这里就可以看出来,内存控制块next和prev中保存内存块的数组索引而不是真实地址的用意了,因为通过这样组织内存,内存块之间的物理顺序就能对应上,从而方便释放,释放内存函数很简单,需要注意的是内存分配函数返回的内存地址不是内存的真实其实地址,而是分配到的内存块向后偏移了一个内存控制块的地址,从而避免用户不小心改动内存控制块,从而破坏内存控制块。其中内存合并过程最为巧妙。
void mem_free(void *rmem)
{
struct mem *mem; if (rmem == NULL) {
return;
}
if ((u8_t *)rmem < (u8_t *)ram || (u8_t *)rmem >= (u8_t *)ram_end) {
/*地址溢出,错误返回*/
return;
}
LWIP_MEM_FREE_PROTECT();
/*将地址偏移到内存控制块起始地址*/
mem = (struct mem *)(void *)((u8_t *)rmem - SIZEOF_STRUCT_MEM);
/*标记内存块空闲*/
mem->used = 0;
if (mem < lfree) {
/* 如果释放的内存块地址,低于lfree更新lfree */
lfree = mem;
}
/*内存块合并*/
plug_holes(mem);
LWIP_MEM_FREE_UNPROTECT();
}
static void plug_holes(struct mem *mem)
{
struct mem *nmem;
struct mem *pmem; /*找出当前块的下一个块的地址*/
nmem = (struct mem *)(void *)&ram[mem->next]; if (mem != nmem && nmem->used == 0 && (u8_t *)nmem != (u8_t *)ram_end) {
/*下一个块不是自己,下一个块空闲,并且不是最后一个块*/
if (lfree == nmem) {
/* 可能需要更新lfree,存疑应该是防止,分系统移植下中断和后台程序同时执行free函数的情况出现 */
lfree = mem;
}
/*新释放的块的结束索引向后合并*/
mem->next = nmem->next;
/*新空闲块后面空闲块的后面的空闲块的前一个块的索引更新为新块的起始索引*/
((struct mem *)(void *)&ram[nmem->next])->prev = (mem_size_t)((u8_t *)mem - ram);
}
/* 取释放块的前一个块地址pmem */
pmem = (struct mem *)(void *)&ram[mem->prev];
/* pmem不是自己的地址,同时也是空闲的,需要合并 */
if (pmem != mem && pmem->used == 0) {
/* 可能需要更新lfree,存疑 */
if (lfree == mem) {
lfree = pmem;
}
/*将前一个块的next索引更新到,新释放块后面的块的结束索引上,合并三个块*/
pmem->next = mem->next;
/*将释放块的后面空闲块的下一个块的前一个块的索引值更新为释放块前一个块的起始地址索引*/
((struct mem *)(void *)&ram[mem->next])->prev = (mem_size_t)((u8_t *)pmem - ram);
}
}
内存合并函数,会查看前后块是否空闲,如果空闲就合并成一个更大的内存块,因为每次释放都会进行内存合并,因此不存在释放块前两个块都空闲的情况,因此只用处理相邻的块的合并,不过我看下了觉得内存块合并中的两处暂时无法理解,就是更新lfree指针的地方我也注释了存疑,如果有人明白还望指点下啊。下一篇再探内存池的实现。
2019-06-16 13:19:42
LWIP再探----内存堆管理的更多相关文章
- LWIP再探----内存池管理
这这里是接上一篇内存池管理部分的,这里如果读者一打开memp.c的话会感觉特别那一理解原作者在干嘛,但是看懂了就明白原作者是怎么巧妙的使用了宏.废话不多说先说了下我分析是一下宏的条件是 前提条件MEM ...
- C++内存管理4-Windows编程中的堆管理(转)
1 引言 在大多数Windows应用程序设计中,都几乎不可避免的要对内存进行操作和管理.在进行大尺寸内存的动态分配时尤其显的重要.本文即主要对内存管理中的堆管理技术进行论述. 堆(Heap)实际是位于 ...
- Android内存管理(11)*常见JVM回收机制「Java进程内存堆分代,JVM分代回收内存,三种垃圾回收器」
参考: http://www.blogjava.net/rosen/archive/2010/05/21/321575.html 1,Java进程内存堆分代: 典型的JVM根据generation(代 ...
- jboss内存查看管理 .
jboss内存查看管理 标签: jbossjavagenerationjvmclassjar 2009-04-09 14:47 4248人阅读 评论(2) 收藏 举报 本文章已收录于: // ' ...
- 再探ASP.NET 5(转载)
就在最近一段时间,微软又有大动作了,在IDE方面除了给我们发布了Viausl Studio 2013 社区版还发布了全新的Visual Studio 2015 Preview. Visual Stud ...
- Windows编程中的堆管理(过于底层,一般不用关心)
摘要: 本文主要对Windows内存管理中的堆管理技术进行讨论,并简要介绍了堆的创建.内存块的分配与再分配.堆的撤销以及new和delete操作符的使用等内容. 关键词: 堆:堆管理 1 引言 在大多 ...
- .NET依托CLR进行的内存的管理
看了http://www.cnblogs.com/liulun/p/3145351.html 不错,补习下相关技术.. 正文: .NET依托CLR进行的内存的管理 有了CLR 基本不需要担心.net ...
- 浅谈SQL Server 对于内存的管理
简介 理解SQL Server对于内存的管理是对于SQL Server问题处理和性能调优的基本,本篇文章讲述SQL Server对于内存管理的内存原理. 二级存储(secondary storage) ...
- 漫谈 C++ 的 内存堆 实现原理
如果我来设计 C++ 的 内存堆 , 我会这样设计 : 进程 首先会跟 操作系统 要 一块大内存区域 , 我称之为 Division , 简称 div . 然后 , 将这块 div 作为 堆 , 就可 ...
随机推荐
- Vue3 源码之 reactivity
注: 为了直观的看到 Vue3 的实现逻辑, 本文移除了边缘情况处理.兼容处理.DEV环境的特殊逻辑等, 只保留了核心逻辑 vue-next/reactivity 实现了 Vue3 的响应性, rea ...
- Bitter.Core系列十:Bitter ORM NETCORE ORM 全网最粗暴简单易用高性能的 NETCore 之 Log 日志
Bitter 框架的 Log 全部采用 NLog 日志组件.Bitter.Core 的 执行语句的日志记录 Nlog 日志级别为:info. 如果想要查看Bitter.Core 的执行SQL,先要去 ...
- 强制杀死进程后,进程相关的socket未必发送RST
强制杀死进程后,进程相关的socket未必发送RST
- 一文带你看遍 JDK9~14 的重要新特性!
Java9 发布于 2017 年 9 月 21 日 .作为 Java8 之后 3 年半才发布的新版本,Java 9 带 来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如 ...
- editplus 5.0 破解
先安装软件,安装步骤就不解释了,很傻瓜式的,一直下一步就行. 到了最重要的一步,请看仔细了!!! 在两个输入框中分别输入 注册名 Vovan 注册码 3AG46-JJ48E-CEACC-8E6 ...
- Language Guide (proto3) | proto3 语言指南(十四)选项
Options - 选项 .proto文件中的单个声明可以使用许多 选项 进行注释.选项不会更改声明的总体含义,但可能会影响在特定上下文中处理声明的方式.可用选项的完整列表在google/protob ...
- 通过Portainer统一管理不同服务器的Docker
通过Portainer统一管理不同服务器的Docker 一.可视化管理工具Portainer的安装 二.跨服务器管理Docker 2.1开启2375监听端口 2.2Portainer配置远程管理 一. ...
- Nginx,Nginx 搭建图片服务器
Nginx Nginx 概述 反向代理 工作流程 优点 1:保护了真实的web服务器,保证了web服务器的资源安全 2:节约了有限的IP地址资源 3:减少WEB服务器压力,提高响应速度 4:其他优点 ...
- boss导出简历css
$('body').css('background-color', '#fff')$('.keywords').hide()$('#wrap').html($('.resume-box').css(' ...
- CentOS7.X安装英伟达显卡采坑之路
1.系统信息 操作系统版本:CentOS7.X 显卡版本:英伟达 Tesla P100 其他软件包安装信息: CUDA 9.0 CUDNN 7.4.2.24 lightgbm 2.2.X Boost ...