【Python数据分析】工作日发文章比周末发文章访问量高?
前言
看前面有位朋友分析了一下每天某个时间发文章的访问量区别,以讨论非系统性因素对文章访问量的影响。之所以进一步讨论工作日和周末发文对文章访问量的影响,一是觉得很有意思,二是毕业设计与此有很大关系,三是觉得还是有点意义的,于是决定做一下这个工作。那么到底周末发文的访问量是不是总体来说比工作日低呢,请往下看。
工具
1.Python 3.5
2.BeautifulSoup 4.4.1
3.Requests模块
分析网页
由于之前的工作已知博客园博客展览页是要通过ajax请求换页,这里我采用了Requests模块,post一个请求即可。
- payload = {"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":i,"ItemListActionName":"PostList"}
- r = requests.post(posturl,data = payload)
这样就可以接收到第i页的博文列表的HTML内容了。
再来看一下我们要爬取的内容:

我们要爬取两个内容:发布时间 与 阅读量,这次我们爬取40—200页共161页的内容,并分两种情况:剔除3000以上访问量的文章以及考虑全部文章,然后要做的工作有两个:根据打扫过的数据,统计出一周周一到周日每天的文章总数与访问量总数,最后用WPS表格来制作出对比图。一提到解析网页,我毫无疑问地又想到了BeautifulSoup这款工具,简单好用,功能强大,推荐。
那么我们首先用BeautifulSoup抓出 class = post_item_foot 的 ‘发布于...’ 内容,以及抓出 class = 'article_view' 的 ’阅读(...)‘内容,再去除一些无用的部分,最后提取出日期三个数据y,m,d,以及阅读量,这里我们无需关心文章到底是谁发的或者具体时间。
(ps:Python 3.5下装BeautifulSoup老是不成功,后来发现有更高的版本4.4.1,就果断换了,然后一发成功,不知道什么原因)
部分代码如下:
- bs = BeautifulSoup(r.text,"html.parser") #转化成beautifulsoup对象
- View = bs.findAll(attrs = {'class' : 'article_view','class' : 'post_item_foot'}) #找出两个class内容
- strallview = str(View) #转化为字符串
- viewcountsmatch = re.findall('阅读\(\d+\)',strallview)
- viewdaymatch = re.findall('发布于 ....-\d+-\d+',strallview)
得出日期三个数据以后,这里我使用蔡勒公式(Zeller Fomula)直接计算出该日是星期几。蔡勒公式函数代码如下:
- def ZellerFomula(y,m,d):
- if m == 1 or m == 2:
- y -= 1
- m += 12
- c = y // 100
- y = y - c * 100
- w = (c // 4) - 2 * c + (y + y // 4) + (13 * (m + 1) // 5) + d - 1
- while w < 0:
- w += 7
- w %= 7
- if w == 0:
- w += 7
- return w
然后就是简单的统计了。
这里我有一个考虑,由于日子越早的文章显然访问量总是会更高,所以为了在一定程度上抵消这种效应,我为每一页的20篇文章设置了一个权重:
- weight = 1 - 0.0005 * (i - 40)
即i越大,页数越大,发布越早,访问量相应打一个折扣,这里我设置的最大折扣为92%,即第200页的文章相应的阅读量为其原来阅读量的92%,希望能稍微提升一下结果的公平性。
代码
这时候写出python代码(剔除3000+文章版本):
- import requests
- import re
- import urllib
- from bs4 import BeautifulSoup
- def ZellerFomula(y,m,d):
- if m == 1 or m == 2:
- y -= 1
- m += 12
- c = y // 100
- y = y - c * 100
- w = (c // 4) - 2 * c + (y + y // 4) + (13 * (m + 1) // 5) + d - 1
- while w < 0:
- w += 7
- w %= 7
- if w == 0:
- w += 7
- return w
- f = open('keyvalue.txt','w')
- posturl = 'http://www.cnblogs.com/mvc/AggSite/PostList.aspx'
- daysum = [0,0,0,0,0,0,0,0,0]
- count = [0,0,0,0,0,0,0,0,0]
- for i in range(40,201):
- weight = 1 - 0.0005 * (i - 40)
- payload = {"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":i,"ItemListActionName":"PostList"}
- r = requests.post(posturl,data = payload)
- bs = BeautifulSoup(r.text,"html.parser")
- View = bs.findAll(attrs = {'class' : 'article_view','class' : 'post_item_foot'})
- strallview = str(View)
- viewcountsmatch = re.findall('阅读\(\d+\)',strallview)
- viewdaymatch = re.findall('发布于 ....-\d+-\d+',strallview)
- #print(viewcountsmatch)
- #print(viewdaymatch)
- for j in range(len(viewcountsmatch)):
- vcm = viewcountsmatch[j]
- vcm = re.sub('阅读\(','',vcm)
- vcm = re.sub('\)','',vcm)
- #print(vcm)
- vc = int(vcm)
- if(vc > 3000):
- continue
- vdm = viewdaymatch[j]
- vdm = re.sub('发布于 ','',vdm)
- vdm = vdm.split('-',2)
- #print(vdm)
- ans = ZellerFomula(int(vdm[0]),int(vdm[1]),int(vdm[2]))
- #print(ans)
- ass = int(weight*vc)
- #print(str(ass)+ ' ' +str(vc))
- daysum[ans] += ass
- count[ans] += 1
- for i in range(1,8):
- f.write(str(daysum[i])+' ')
- f.write(str(count[i]))
- f.write('\n')
- f.close()
这代码写了很久,主要python很久没碰也不熟悉了。
运行结果与分析
然后我们运行就可以爬了,耗时大约40+秒,结果如下:
1.剔除版本数据

每行前面是161篇文章中星期1~7的文章访问总量,后面是文章数量。不算3000+访问以上的文章总数3104篇,贡献访问量1573399。
2.未剔除版本
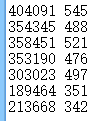
文章总数3220 = 161 x 20篇,贡献访问量2176232.
由上可以看出,3000+访问以上的较优质文章116篇,占比3.6%,其贡献的访问量为602833,占比27.7%,这也是预料之中的。
图表

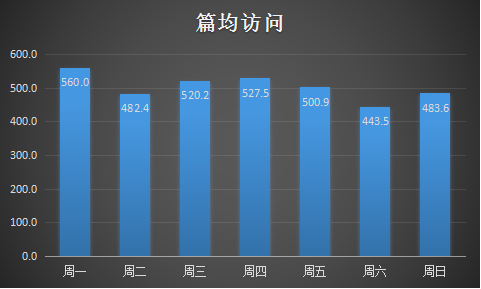
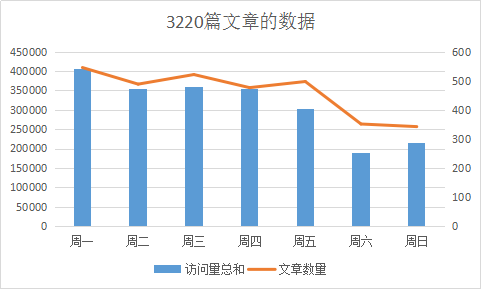
由图可得,两种方式总体上的差距并不大,从发文数量上看,周一发文最多,可能是大家都上班了,开始新一周的工作使然。随后周二到周四发文数量略有波动,但是都差不太多,并且比周一少。到周五由于放假了,文章数量也相应减少。到周末两天发文数量就有了很大下降,这也是预料之中。
从文章访问量来看,周一达到最大,随后又以较周一低的水平波动,到周末达到低谷,一大原因也是由于文章数量的减少。
从平均访问情况来看,周一至周五的平均访问量普遍比周末稍高一点,印证了结论“工作日发文要比周末发文平均访问量多”,但是并没有多太多,其中周一达到最高峰,随后有波动,到周日有一个反弹,说明“周一效应”还是有一点的。
两幅图的有些显著的不同就是访问量来看,剔除3000+文章以后,周二的访问量有10W+的显著下降,这是否说明周二的时候高质量文章的访问在急速增长的原因呢。
补充
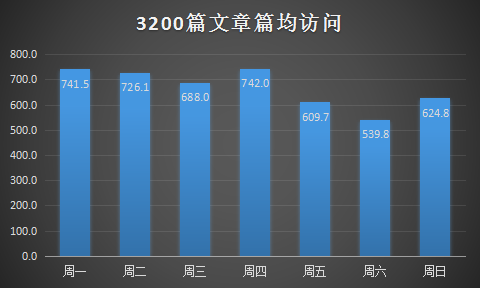
后来我发现光考虑篇均访问还不全面,因为周一即使篇均访问较高,但是它的文章数也是很大的,所以周一的文章必然会很快被覆盖过去,所以这里有一个性价比的问题,于是我又算了一项指标,即篇均访问与当日文章数量之比,底数越大小即文章数量越小,越晚被覆盖,曝光率越大,篇均访问越大自然带来的效应越大。所以有了下面这张图:
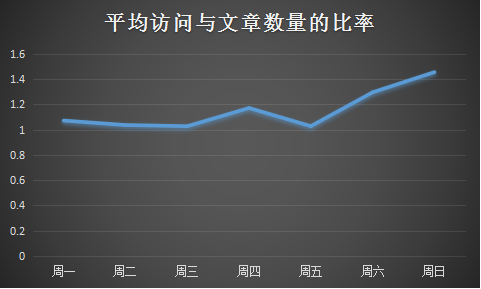
事实证明,性价比最高的发文日期居然是发的很少,访问很少的周末!
后续工作
虽然本次挖掘3220篇文章数据较小,感觉还是可以从速度方面进行优化的。
权重也是我自己简单设计的,这方面也可以进一步优化。
欢迎大家提出意见与建议。
结论与启示
所以说,如果你想要让你的文章获得更多的访问量,获得更大的影响力,尽量在工作日发文吧。当然,我前面说过,这些都只是非系统性因素,俗话说,打铁还需自身硬,提高自己文章的质量和水平才是获得更大文章影响力的决定性因素。希望广大园友能够致力于发布质量更高的文章,共同构建一个属于我们的优质的博客园。
本文就是上星期四晚上写就的,一直到现在才发,试下效果。事实是写完文章很难忍住不发,哈哈。
同样,爬取博客园只是为了学习之用,无其他目的,望理解。感谢韩子迟的工作。
【Python数据分析】工作日发文章比周末发文章访问量高?的更多相关文章
- Python数据分析基础教程
Python数据分析基础教程(第2版)(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1_FsReTBCaL_PzKhM0o6l0g 提取码:nkhw 复制这段内容后 ...
- 现在都是python 单独开发框架 执行脚本,处理结果,发报告之类的
现在都是python 单独开发框架 执行脚本,处理结果,发报告之类的
- Python数据分析(二): Numpy技巧 (1/4)
In [1]: import numpy numpy.__version__ Out[1]: '1.13.1' In [2]: import numpy as np
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (3/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- 小白学 Python 数据分析(1):数据分析基础
各位同学好,小编接下来为大家分享一些有关 Python 数据分析方面的内容,希望大家能够喜欢. 人工植入广告: PS:小编最近两天偷了点懒,好久没有发原创了,最近是在 CSDN 开通了一个付费专栏,用 ...
- 小猪的Python学习之旅 —— 16.再尝Python数据分析:采集拉勾网数据分析Android就业行情...
一句话概括本文: 爬取拉钩Android职位相关数据,利用numpy,pandas和matplotlib对招人公司 情况和招聘要求进行数据分析. 引言: 在写完上一篇<浅尝Python数据分析: ...
- python数据分析01准备工作
第1章 准备工作 1.1 本书的内容 本书讲的是利用Python进行数据控制.处理.整理.分析等方面的具体细节和基本要点.我的目标是介绍Python编程和用于数据处理的库和工具环境,掌握这些,可以让你 ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
随机推荐
- 【Win10开发】关于AutoSuggestBox
其实看名字我们就知道,这个控件可以提供一些建议文本.我们在做搜索框时可以做一些文本来让用户选择. 这个控件有两个关键的事件QuerySubmitted和SuggestionChosen事件,当下拉列表 ...
- sql常用语句(1)
--排序 select Row_Number() over(order by a.UserName) as Num --区分性别 then '男' else '女' end SexName Sqlse ...
- 图解SQL的Join(转)
对于SQL的Join,在学习起来可能是比较乱的.我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚.Codin ...
- 25M电子琴实现
module qin(input clk,output reg beep,input [3:0] col,output [3:0] row_data,output [7:0]out ,input rs ...
- 线程池深入(li)
java线程池.在jdk5之后为我们提供了线程池,只需要使用API,不用去考虑线程池里特殊的处理机制.jdk5线程池分好多种,固定尺寸的线程池.可变尺寸连接池等.常用的是ThreadPoolExecu ...
- 关系型数据库与NOSQL
本文转载自: http://www.cnblogs.com/chay1227/archive/2013/03/17/2964020.html(只作转载, 不代表本站和博主同意文中观点或证实文中信息) ...
- file_put_contents 错误:failed to open stream: Invalid argument 一种原因
今天在测试nilcms系统的时候,出现了一个报错,导致缓存无法更新: file_put_contents(C:\UPUPW_AP5.4\vhosts\d.tv\NilCMS_APP\include_r ...
- artTemplate模板引擎学习实战
在我的一篇关于智能搜索框异步加载数据的文章中,有博友给我留言,认为我手写字符串拼接效率过低,容易出错.在经过一段时间的摸索和学习之后,发现现在拼接字符串的方法都不在是自己去书写了,而是使用Javasc ...
- 设计一个自动生成棋盘格子的JS小程序
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- HTML标签界里不会再用到的标签属性(一)
为了成为一名初级前端开发工程师,最近正在探寻HTML标签的众多奥秘,果不其然,让我发现了许多被“冷落”了的标签属性. 一.<!DOCTYPE> 自从HTML5流行之后,<!DOCTY ...