JVM升华篇
01 Garbage Collect(垃圾回收)
1.1 如何确定一个对象是垃圾?
1.1.1 引用计数法
能作为GC Root:类加载器、Thread、虚拟机栈的本地变量表、static成员、常量引用、本地方法
栈的变量等。
已经能够确定一个对象为垃圾之后,接下来要考虑的就是回收,怎么回收呢?
得要有对应的算法,下面聊聊常见的垃圾回收算法
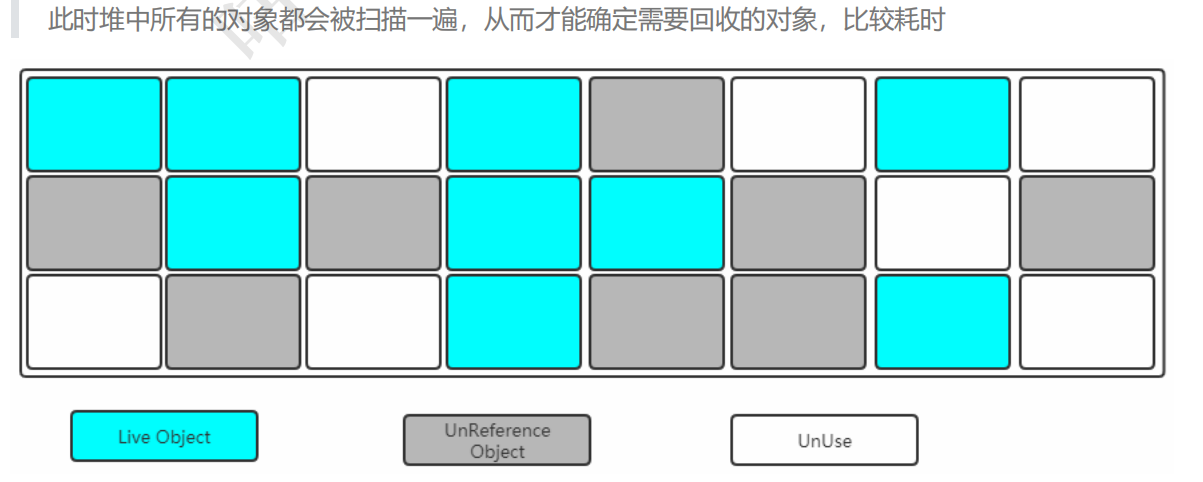
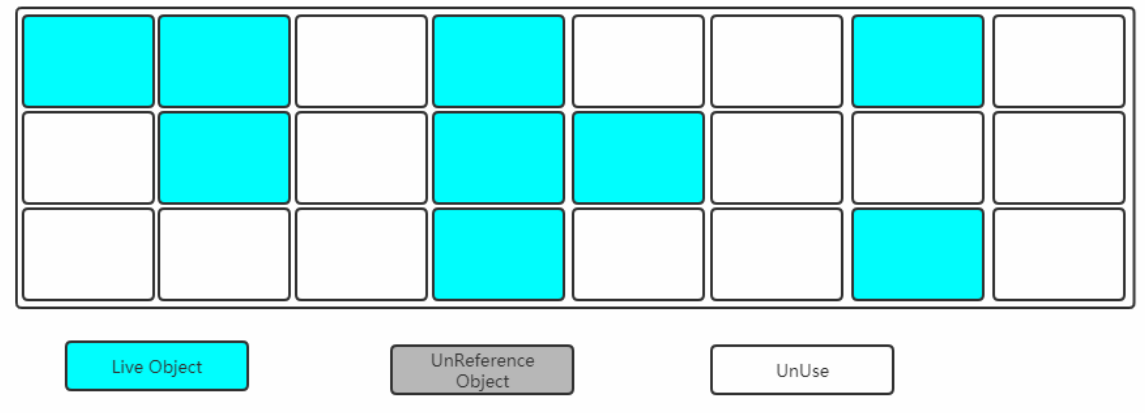
标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程 序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
(1)标记和清除两个过程都比较耗时,效率不高
(2)会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无 法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。

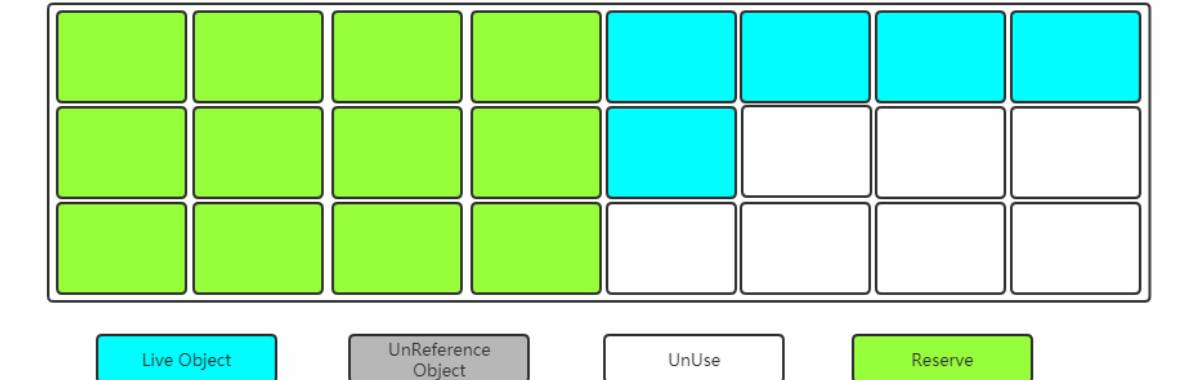
标记过程仍然与"标记-清除"算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活
的对象都向一端移动,然后直接清理掉端边界以外的内存

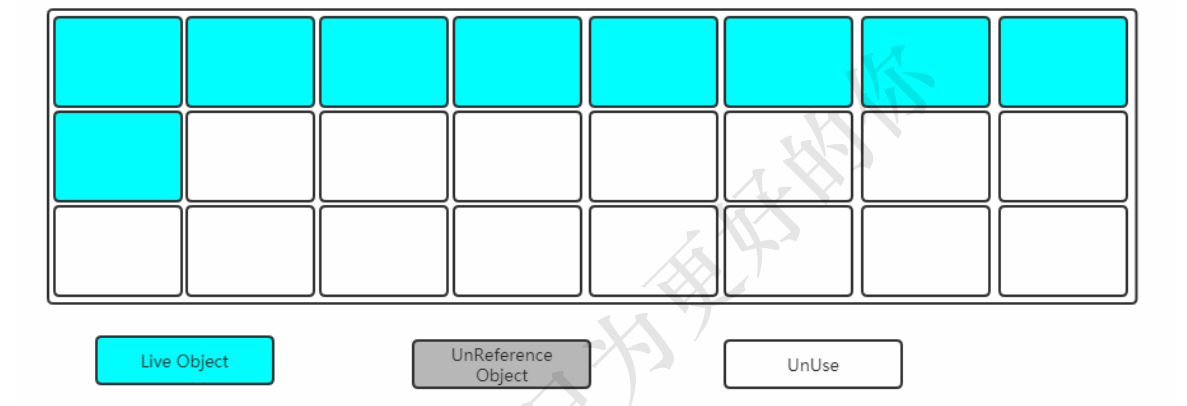
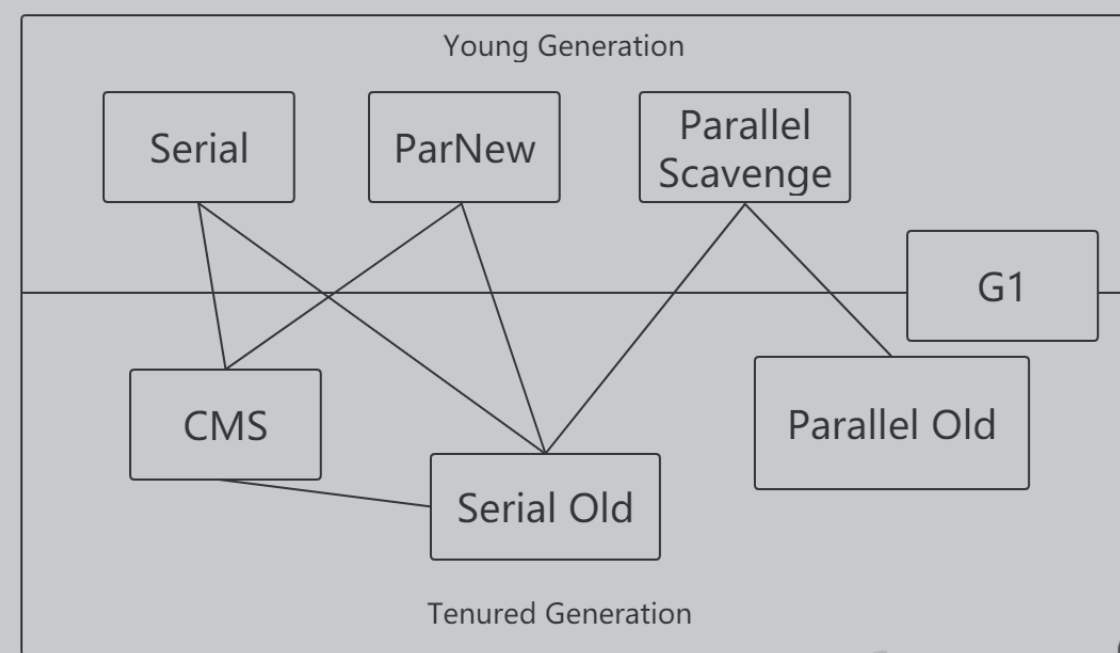
Serial收集器是最基本、发展历史最悠久的收集器,曾经(在JDK1.3.1之前)是虚拟机新生代收集的唯
一选择。
它是一种单线程收集器,不仅仅意味着它只会使用一个CPU或者一条收集线程去完成垃圾收集工作,更
重要的是其在进行垃圾收集的时候需要暂停其他线程
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器

优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
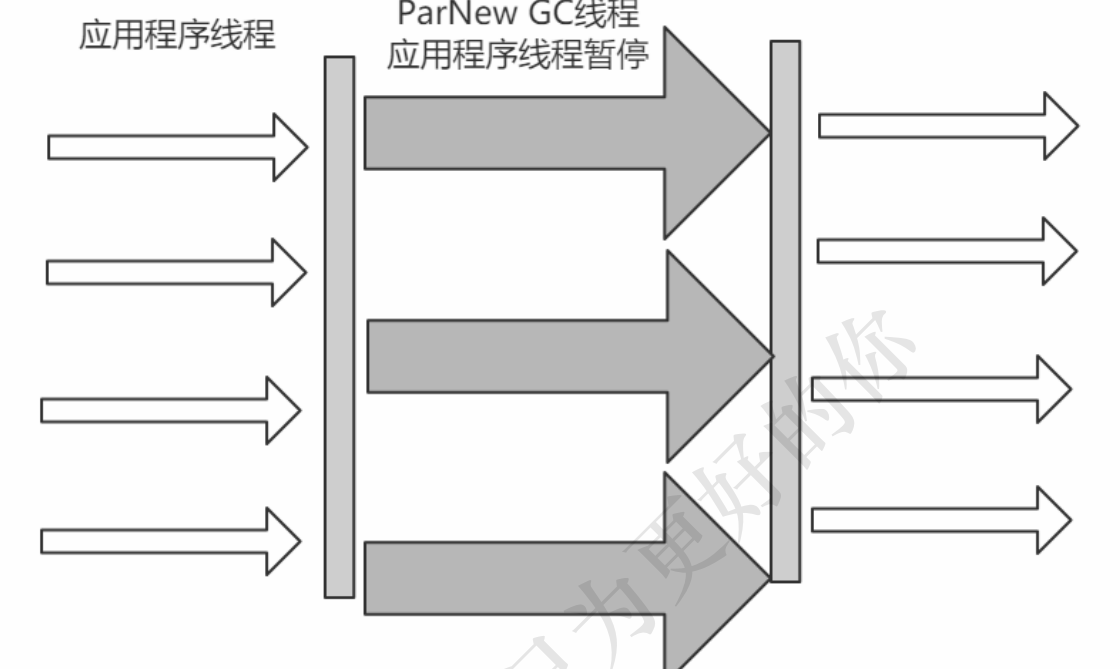
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集
器,看上去和ParNew一样,但是Parallel Scanvenge更关注 系统的吞吐量 。
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
比如虚拟机总共运行了100分钟,垃圾收集时间用了1分钟,吞吐量=(100-1)/100=99%。
若吞吐量越大,意味着垃圾收集的时间越短,则用户代码可以充分利用CPU资源,尽快完成程序
的运算任务。
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间,
-XX:GCTimeRatio直接设置吞吐量的大小。
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,不同的是采用"标记-整理算
法",运行过程和Serial收集器一样

Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和"标记-整理算法"进行垃圾
回收。
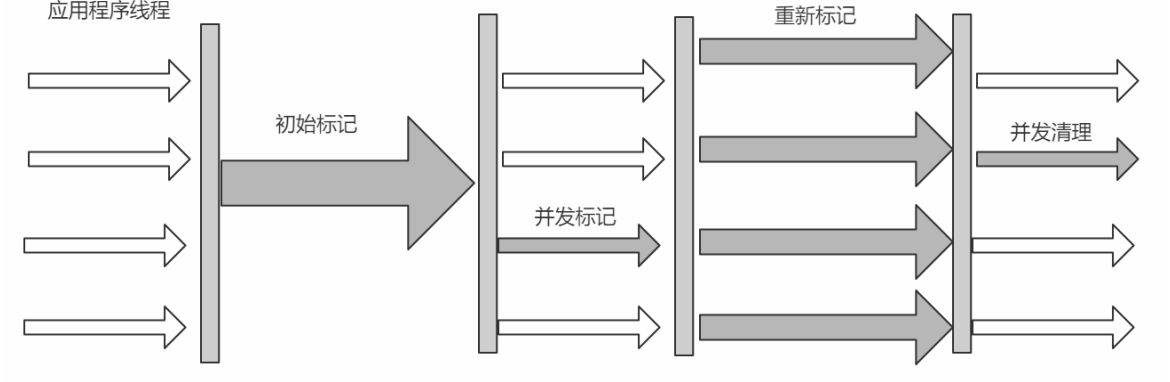
(1)初始标记 CMS initial mark 标记GC Roots能关联到的对象 Stop The World-- ->速度很快
(2)并发标记 CMS concurrent mark 进行GC Roots Tracing
(3)重新标记 CMS remark 修改并发标记因用户程序变动的内容 Stop The World
(4)并发清除 CMS concurrent sweep
采用的是"标记-清除算法",整个过程分为4步由于整个过程中,并发标记和并发清除,收集器线程可以与用户线程一起工作,所以总体上来
说,CMS收集器的内存回收过程是与用户线程一起并发地执行的。
优点:并发收集、低停顿
缺点:产生大量空间片、并发阶段会降低吞吐量
并行与并发
分代收集(仍然保留了分代的概念)
空间整合(整体上属于“标记-整理”算法,不会导致空间碎片)
可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集 上的时间不得超过N毫秒)
使用G1收集器时,Java堆的内存布局与就与其他收集器有很大差别,它将整个Java堆划分为多个
大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再
是物理隔离的了,它们都是一部分Region(不需要连续)的集合
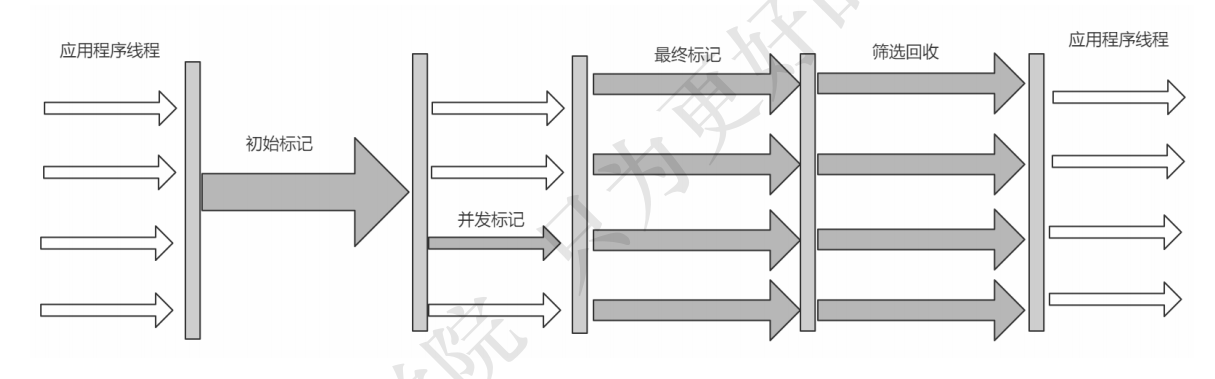
初始标记(Initial Marking) 标记一下GC Roots能够关联的对象,并且修改TAMS的值,需要暂 停用户线程
并发标记(Concurrent Marking) 从GC Roots进行可达性分析,找出存活的对象,与用户线程并发 执行
最终标记(Final Marking) 修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需 暂停用户线程
筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据 用户所期望的GC停顿时间制定回收计划
只能有一个垃圾回收线程执行,用户线程暂停。 适用于内存比较小的嵌入式设备 。
多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。 适用于科学计算、后台处理等若交互场景
用户线程和垃圾收集线程同时执行(但并不一定是并行的,可能是交替执行的),垃圾收集线程在执行的
时候不会停顿用户线程的运行。 适用于相对时间有要求的场景,比如Web 。
停顿时间->垃圾收集器 进行 垃圾回收终端应用执行响应的时间
吞吐量->运行用户代码时间/(运行用户代码时间+垃圾收集时间)
停顿时间越短就越适合需要和用户交互的程序,良好的响应速度能提升用户体验;
高吞吐量则可以高效地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任 务。
官网 :https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/collectors.html#sthr
ef28
优先调整堆的大小让服务器自己来选择
如果内存小于100M,使用串行收集器
如果是单核,并且没有停顿时间要求,使用串行或JVM自己选
如果允许停顿时间超过1秒,选择并行或JVM自己选
如果响应时间最重要,并且不能超过1秒,使用并发收集器
对于G1收集
(1)50%以上的堆被存活对象占用
(2)对象分配和晋升的速度变化非常大
(3)垃圾回收时间比较长
(1)串行 -XX:+UseSerialGC -XX:+UseSerialOldGC
(2)并行(吞吐量优先): -XX:+UseParallelGC -XX:+UseParallelOldGC
(3)并发收集器(响应时间优先) -XX:+UseConcMarkSweepGC -XX:+UseG1G咕
JVM升华篇的更多相关文章
- 初步了解JVM第二篇
在一篇<初步了解JVM第一篇>中,我们已经了解了: 类加载器:负责加载*.class文件,将字节码内容加载到内存中.其中类加载器的类型有如下: 启动类加载器(Bootstrap) 扩展类加 ...
- JVM学习篇-第一篇
JVM学习篇-第一篇 JDK( Java Development Kit): Java程序设计语言.Java虚拟机.Java类库三部分统称为JDK,JDK是用于支持Java程序开发的最小环境** ...
- JVM执行篇:使用HSDIS插件分析JVM代码执行细节--转
http://www.kuqin.com/java/20111031/314144.html 在<Java虚拟机规范>之中,详细描述了虚拟机指令集中每条指令的执行过程.执行前后对操作数栈. ...
- JVM前奏篇(大局观)
话不多说直接上干货,先来看oracle官网中是怎么描述JDK的:https://docs.oracle.com/javase/8/docs/index.html 这是官网中JDK.JRE.JVM的一个 ...
- 初步了解JVM第一篇
大家都知道,Java中JVM的重要性,学习了JVM你对Java的运行机制.编译过程和如何对Java程序进行调优相信都会有一个很好的认知. 废话不多说,直接带大家来初步认识一下JVM. 什么是JVM? ...
- 1.JVM前奏篇(看官网怎么说)
JVM(Java Virtual Machine) 前奏篇(看官网规范怎么说) 1.The relation of JDK/JRE/JVM 在下图中,我们所接触的,最熟悉,也是经常打交道的 最顶层 J ...
- JVM 第二篇:垃圾收集器以及算法
本文内容过于硬核,建议有 Java 相关经验人士阅读. 0. 引言 一说到 JVM ,大多数人第一个想到的可能就是 GC ,今天我们就来聊一聊和 GC 关系最大的垃圾收集器以及垃圾收集算法,希望能通过 ...
- 【JVM第二篇--类加载机制】类加载器与双亲委派模型
写在前面的话:本文是在观看尚硅谷JVM教程后,整理的学习笔记.其观看地址如下:尚硅谷2020最新版宋红康JVM教程 一.什么是类加载器 在类加载过程中,加载阶段有一个动作是"通过一个类的全限 ...
- 深入理解JAVA虚拟机之JVM性能篇---垃圾回收
一.基本垃圾回收算法 1. 判断对象是否需要回收的方法(如何判断垃圾): 1) 引用计数(Reference Counting) 对象增加一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回 ...
随机推荐
- Java程序入门
编写Java源程序 在d:\day01 目录下新建文本文件,完整的文件名修改为HelloWorld.java ,其中文件名为HelloWorld ,后缀名必须为.java . 用记事本打开 在文件中键 ...
- 数据库性能调优之始: analyze统计信息
摘要:本文简单介绍一下什么是统计信息.统计信息记录了什么.为什么要收集统计信息.怎么收集统计信息以及什么时候收集统计信息. 1 WHY:为什么需要统计信息 1.1 query执行流程 下图描述了Gau ...
- MySQL 5.6.35 索引优化导致的死锁案例解析
一.背景 随着公司业务的发展,商品库存从商品中心独立出来成为一个独立的系统,承接主站商品库存校验.订单库存扣减.售后库存释放等业务.在上线之前我们对于核心接口进行了压测,压测过程中出现了 MySQL ...
- linux驱动设备号
一.设备号基础 一般来说,使用ls -l命令在时间一列的前一列的数字表示的是文件大小,但如果该文件表示的是一个设备的话,那时间一列的前一列将有两个数字,用逗号分隔开,如下图: 前一个数字表示主设备号, ...
- mysql(视图 事务 索引 外键)
视图 视图本质就是对查询的封装 创建视图(定义视图 起名以v_开头) create view v_students as select classes.name as c_name ,stud ...
- cisco asa 5525 思科防火墙设置拨号访问内网以及外网
WZ-2A10-SAS5525-0938# show running-config : Saved : : Serial Number: FCH17307098 : Hardware: ASA5525 ...
- Java并发组件三之Semaphore
使用场景:常用于使用有限的资源,限制线程并发的最大数量.默认情况下,信号量是非公平性的(先等待先执行为公平.类似于买东西的时候大家排队付款,先来的先付款是公平的.但是这时候有人插队,那就是非公平的)设 ...
- RSA2对于所有商户都是单独一对一的,并且只支持开发平台密钥管理和沙箱
蚂蚁金服开发者社区 https://openclub.alipay.com/club/history/read/1495 RSA 和 RSA2 签名算法区别 - 支付宝开放平台 https://ope ...
- 端口被占用通过域名的处理 把www.domain.com均衡到本机不同的端口 反向代理 隐藏端口 Nginx做非80端口转发 搭建nginx反向代理用做内网域名转发 location 规则
负载均衡-Nginx中文文档 http://www.nginx.cn/doc/example/loadbanlance.html 负载均衡 一个简单的负载均衡的示例,把www.domain.com均衡 ...
- forEach、for in、for of三者区别
forEach更多的用来遍历数组for in 一般常用来遍历对象或jsonfor of数组对象都可以遍历,遍历对象需要通过和Object.keys()for in循环出的是key,for of循环出的 ...