kafka生产者数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
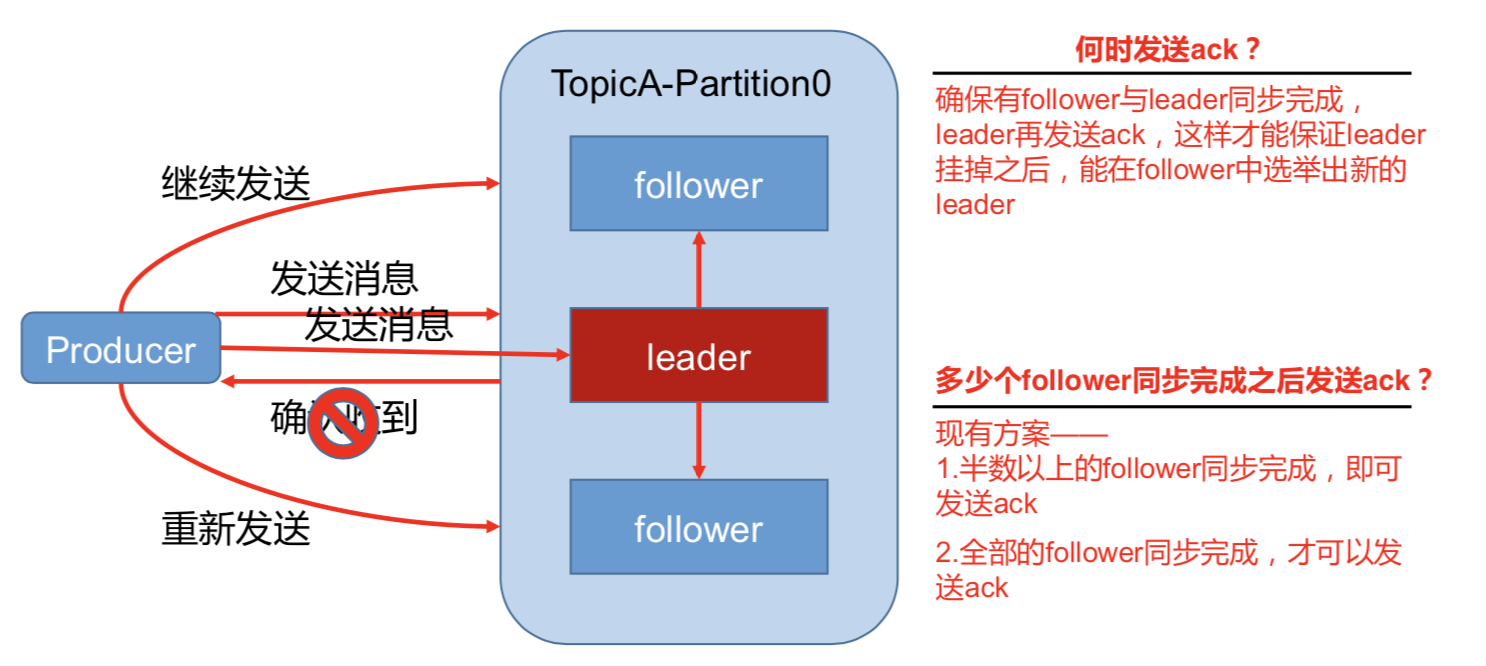
1)副本数据同步策略
|
方案 |
优点 |
缺点 |
|
半数以上完成同步,就发 送 ack |
延迟低 |
选举新的 leader 时,容忍 n 台 节点的故障,需要 2n+1 个副 本(N+1台同步完成) |
|
全部完成同步,才发送 ack |
选举新的 leader 时,容忍 n 台 节点的故障,需要 n+1 个副 本 |
延迟高(N+1台同步完成) |
Kafka 选择了第二种方案,原因如下:
1.同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1
个副本,而 Kafka 的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
2.虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
存在的问题:如果有10个副本。有一个挂了,那么永远都不会有ack发送回去。
kafak做了一个优化:

ISR(同步副本):消息条数差值replica.lag.time.max.messages/通信时间长短(同步时间replica.lag.time.max.ms) 两个条件来选副本进ISR, 高版本中不再关注副本的消息条数最大条件。 新版本:如果副本同步时间超过replica.lag.time.max.ms(默认10s),follower就会被移出ISR.
采用第二种方案之后,设想以下情景:leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。这个问题怎么解决呢?
Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集 合。
当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower 长时间未向 leader 同步数据,则该 follower 将被踢出 ISR,该时间阈值由
replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR (同步副本)中选举新的 leader。
为何会去掉消息条数差值参数?
因为kafka一般是按batch批量发数据到leader, 如果批量条数12条,replica.lag.time.max.messages参数设置是10条(默认10000条),那么当一个批次消息发到kafka leader,此时,ISR中就要踢掉所有的follower,很快follower同步完所有数据后,follower又要被加入到ISR,频繁操作。
kafka生产者数据可靠性保证的更多相关文章
- Kafka消息delivery可靠性保证(Message Delivery Semantics)
原文见:http://kafka.apache.org/documentation.html#semantics kafka在生产者和消费者之间的传输是如何保证的,我们可以知道有这么几种可能提供的de ...
- kafka如何保证数据可靠性和数据一致性
数据可靠性 Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知.本文从 Producter 往 Broker 发送消息.Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠 ...
- Kafka数据可靠性与一致性解析
Partition Recovery机制 每个Partition会在磁盘记录一个RecoveryPoint, 记录已经flush到磁盘的最大offset.broker fail 重启时,会进行load ...
- kafka学习(三)kafka生产者,消费者详解
文章更新时间:2020/06/14 一.生产者 当我们发送消息之前,先问几个问题:每条消息都是很关键且不能容忍丢失么?偶尔重复消息可以么?我们关注的是消息延迟还是写入消息的吞吐量? 举个例子,有一个信 ...
- Kafka数据可靠性深度解读
原文链接:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由Linked ...
- 【Kafka】Kafka数据可靠性深度解读
转帖:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由LinkedIn ...
- kafka数据可靠性深度解读【转】
1 概述 Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cl ...
- Kafka权威指南 读书笔记之(三)Kafka 生产者一一向 Kafka 写入数据
不管是把 Kafka 作为消息队列.消息总线还是数据存储平台来使用 ,总是需要有一个可以往 Kafka 写入数据的生产者和一个从 Kafka 读取数据的消费者,或者一个兼具两种角色的应用程序. 开发者 ...
- Kafka生产者----向kafka写入数据
开发者可以使用kafka内置的客户端API开发kafka应用程序.除了内置的客户端之外,kafka还提供了二进制连接协议,也就是说,我们直接向kafka网络端口发送适当的字节序列,就可以实现从Kafk ...
随机推荐
- day32 Pyhton 模块02复习 序列化
一. 什么是序列化 在我们存储数据或者网络传输数据的时候. 需要对我们的对象进行处理. 把对象处理成方便存储和传输的数据格式. 这个过程叫序列化 不同的序列化, 结果也不同. 但是目的是一样的. 都是 ...
- python写文件时遇到UnicodeEncodeError: 'gbk' codec can't encode character的解决方式
在window平台,文件的默认编码是gbk, 此时如果写入的字符串的编码是utf-8就会引发这种错误,打开文件的编码必须与字符串的编码一致 with open('content.txt','w',en ...
- 阅读-Calibre Library转PDF、EPUB配置
提示:如果想恢复默认设置,点击"恢复默认值"即可 -----EPUB (MOBI同理)----- 目标:解决转换过程中图片清晰度丢失问题(分辨率太低) 右击-转换书籍-逐个转换 输 ...
- 持续集成工具之jenkins+sonarqube做代码扫描
上一篇我们主要聊了下代码质量管理平台sonarqube的安装部署以及它的工作方式做了简单的描述和代码扫描演示:回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13 ...
- monolog 日志
1 安装 composer require monolog/monolog 2 使用 // 创建日志服务 $logger = new Logger('my_logger'); // 定义一个handl ...
- hbase的Java基本操作
hbase的Java基本操作 建表,建列簇操作 private static Connection connection; private static Admin admin; public sta ...
- C# 向服务器发送信息
#region 向服务器发送信息 /// <summary> /// 向服务器发送信息 /// </summary> /// <param name="post ...
- python识别视频黑屏或者低清晰度
第一步:获取视频第一帧图片 https://www.cnblogs.com/pythonywy/p/13749735.html 第二步:进行识别 import os import numpy as n ...
- net core 微服务框架 Viper 调用链路追踪
1.Viper是什么? Viper 是.NET平台下的Anno微服务框架的一个示例项目.入门简单.安全.稳定.高可用.全平台可监控.底层通讯可以随意切换thrift grpc. 自带服务发现.调用链追 ...
- 设计模式 | 职责链模式(Chain of responsibility)
定义: 使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系.将这个对象连城一条链,并沿着这条链传递该请求,直到有一个对象处理它为止. 结构:(书中图,侵删) 一个抽象的处理者 若干 ...