crf++分词
1.linux下安装crf工具包
先下载CRF++-0.58.tar.xz,在Linux环境下安装CRF工具包
https://github.com/taku910/crfpp
- 解压到某一个目录下面
- 打开控制台,切换到解压目录
- 依次输入命令:
./configure
sudo make
sudo make install
其间,出现问题:
发现是make和make install没用sudo命令,权限不够,导致不能创建一些目录。
2.使用
https://blog.csdn.net/wqx1414161394/article/details/79411988
1.训练和测试的数据格式
训练和测试文件必须包含多个tokens,每个token又包含多个列。token的定义可根据具体的任务,如词、词性等。每个token必须写在一行,且各列之间用空格或制表格间隔。一个token的序列可构成一个sentence,每个sentence之间用一个空行间隔。
注意: 最后一列将是被CRF用来训练的最终标签!!!
例子:He reckons the current account deficit will narrow to only #1.8 billion in September.
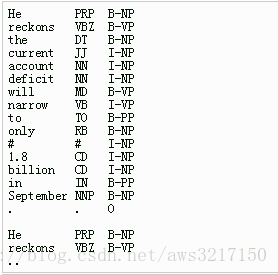
这个例子中”He reckons the current account deficit will narrow to only #1.8 billion in September .”代表一个训练语句,CRF++要求将这样的句子拆成每一个词一行并且是相同固定列数的数据,其中列除了原始输入,还可以包含一些其他信息,比如例子每个token包含3列,分别为字本身、字类型和词位标记,最后一列是Label信息,也就是标准答案yy。而不同的训练序列与序列之间的相隔,依靠一个空白行来区分。
通俗说法:训练文件由若干个句子组成(可以理解为若干个训练样例),不同句子之间通过换行符分隔,上图中显示出的有两个句子。每个句子可以有若干组标签,最后一组标签是标注,上图中有三列,即第一列和第二列都是已知的数据,第三列是要预测的标注,以上面例子为例是,根据第一列的词语和和第二列的词性,预测第三列的标注。 当然这里有涉及到标注的问题,比如命名实体识别就有很多不同的标注集。
https://blog.csdn.net/u010189459/article/details/38546115#
日文trainset的例子如下
毎 k B
日 k I
新 k I
聞 k I
社 k I
特 k B
別 k I
顧 k B
問 k I
4 n B
这里第一列是待分词的日文字,第二列暂且认为其是词性标记,第三列是字标注中的2-tag(B, I)标记,这个很重要,对于我们需要准备的训练集,主要是把这一列的标记做好,不过需要注意的是,其断句是靠空行来完成的。
注意:每一行的列数必须相同一致,否则系统将报错。
再来看测试集的格式:
よ h I
っ h I
て h I
私 k B
た h B
ち h I
の h B
世 k B
代 k I
が h B
同样也有3列,第一列是日文字,第二列第三列与上面是相似的,不过在测试集里第三列主要是占位作用。事实上,CRF++对于训练集和测试集文件格式的要求是比较灵活的,首先需要多列,但不能不一致,既在一个文件里有的行是两列,有的行是三列;其次第一列代表的是需要标注的“字或词”,最后一列是输出位”标记tag”,如果有额外的特征,例如词性什么的,可以加到中间列里,所以训练集或者测试集的文件最少要有两列。
2.准备特征模板
CRF++训练的时候,要求我们自己提供特征模板。

# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
模板文件中的每一行是一个模板。每个模板都是由%x[row,col]来指定输入数据中的一个token。row指定到当前token的行偏移,col指定列位置。


以“U01:%x[0,1]”为例,它在该语料中生成的示例函数如下:
func1 = if (output = O and feature=“U01:NN”) return 1 else return 0
func2 = if (output = O and feature=“U01:N”) return 1 else return 0
func3 = if (output = O and feature=“U01:NNP”) return 1 else return 0
…
关于CRF++中特征模板的说明和举例,请大家参考官方文档上的“Preparing feature templates”这一节.
而以下部分的说明拿上述日文分词数据举例。在特征模板文件中,每一行(如U00:%x[-2,0])代表一个特征,而宏“%x[行位置,列位置]”则代表了相对于当前指向的token的行偏移和列的绝对位置,以上述训练集为例,如果当前扫描到“新 k I”这一行,
毎 k B
日 k I
新 k I <== 扫描到这一行,代表当前位置
聞 k I
社 k I
特 k B
別 k I
顧 k B
問 k I
4 n B
那么依据特征模板文件抽取的特征如下:
# Unigram
U00:%x[-2,0] ==> 毎
U01:%x[-1,0] ==> 日
U02:%x[0,0] ==> 新
U03:%x[1,0] ==> 聞
U04:%x[2,0] ==> 社
U05:%x[-2,0]/%x[-1,0]/%x[0,0] ==> 每/日/新
U06:%x[-1,0]/%x[0,0]/%x[1,0] ==> 日/新/聞
U07:%x[0,0]/%x[1,0]/%x[2,0] ==> 新/聞/社
U08:%x[-1,0]/%x[0,0] ==> 日/新
U09:%x[0,0]/%x[1,0] ==> 新/聞
# Bigram
B
2.2模板类型
CRF++里将特征分成两种类型,一种是Unigram的,“U”起头,另外一种是Bigram的,“B”起头。对于Unigram的特征,假如一个特征模板是”U01:%x[-1,0]“, CRF++会自动的生成一组特征函数(func1 … funcN) 集合:
func1 = if (output = B and feature="U01:日") return 1 else return 0
func2 = if (output = I and feature="U01:日") return 1 else return 0
....
funcXX = if (output = B and feature="U01:問") return 1 else return 0
funcXY = if (output = I and feature="U01:問") return 1 else return 0
生成的特征函数的数目 = (L * N),其中L是输出的类型的个数,这里是B,I这两个tag,N是通过模板扩展出来的所有单个字符串(特征)的个数,这里指的是在扫描所有训练集的过程中找到的日文字(特征)。
而Bigram特征主要是当前的token和前面一个位置token的自动组合生成的bigram特征集合。最后需要注意的是U01和U02这些标志位,与特征token组合到一起主要是区分“U01:問”和“U02:問”这类特征,虽然抽取的日文”字”特征是一样的,但是在CRF++中这是有区别的特征。
Unigram feature 和 Bigram feature有什么区别呢?
unigram/bigram很容易混淆,因为通过unigram-features也可以写出类似%x[-1,0]%x[0,0]这样的单词级别的bigram(二元特征)。而这里的unigram和bigram features指定是uni/bigrams的输出标签。
这里的一元/二元指的就是输出标签的情况,这个具体的例子我还没看到,example文件夹中四个例子,也都是只用了Unigram,没有用Bigarm,因此感觉一般Unigram feature就够了。
https://blog.csdn.net/miner_zhu/article/details/83143487
3.训练
命令行:
% crf_learn template_file train_file model_file
其中,template_file和train_file需由使用者事先准备好。crf_learn将生成训练后的模型并存放在model_file中。
一般的,crf_learn将在STDOUT上输出下面的信息。
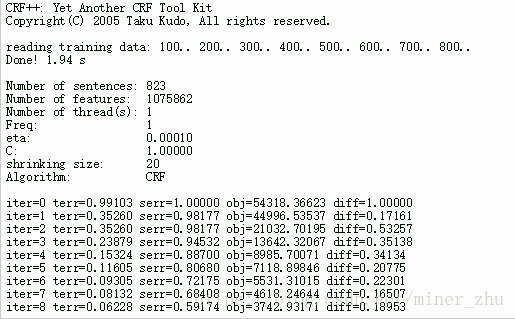
iter: 迭代次数
terr: tags的错误率(错误的tag数/所有的tag数)
serr:sentence的错误率(错误的sentence数/所有的sentence数)
obj:当前对象的值。当这个值收敛到一个确定的值时,CRF模型将停止迭代
diff:与上一个对象值之间的相对差这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),如果想保存这些信息,我们可以将这些标准输出流到文件上,命令格式如下:
% crf_learn template_file train_file model_file >> train_info_file
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
带两个参数的命令行例子:
% crf_learn -f 3 -c 1.5 template_file train_file model_file
4.测试(解码)
命令行:
% crf_test -m model_file test_files
在测试过程中,使用者不需要指定template file,因为,mode file已经有了template的信息。test_file是你想要标注序列标记的测试语料。
有两个参数-v和-n都是显示一些信息的,-v可以显示预测标签的概率值,-n可以显示不同可能序列的概率值,对于准确率,召回率,运行效率,没有影响,这里不说明了。
与crf_learn类似,输出的结果放到了标准输出流上,而这个输出结果是最重要的预测结果信息(测试文件的内容+预测标注),同样可以使用重定向,将结果保存下来,命令行如下。
% crf_test -m model_file test_files >> result_file
实验
把数据集转换为需要的格式。本次是预测词性,所以把词性放在最后一列:
 image-20200531204858243.pn
image-20200531204858243.pn
测试集:
 image-20200531204914482.pn
image-20200531204914482.pn
模版template:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
上面这个是进行分词可以用的模板
下面的是词性标注用的模板:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
训练:
重定向 >>追加 ,>覆盖
#crf_learn template_wsg 1998_1.txt model.wsg > train_info_file&
crf_learn template trainset.txt model_pos > train_info 2>&1 &
测试:
head -n 90000 1998_1.txt >test.wsg.data2
crf_test -m model.wsg test.wsg.data2 > test.wsg.rst
cut -f 1,3-4 test.wsg.rst>1.rst
python clc_f.py 1.rst
#
crf_test -m model test.data > test.rst

crf++分词的更多相关文章
- Hanlp中使用纯JAVA实现CRF分词
Hanlp中使用纯JAVA实现CRF分词 与基于隐马尔可夫模型的最短路径分词.N-最短路径分词相比,基于条件随机场(CRF)的分词对未登录词有更好的支持.本文(HanLP)使用纯Java实现CRF模型 ...
- 条件随机场 (CRF) 分词序列谈之一(转)
http://langiner.blog.51cto.com/1989264/379166 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.ht ...
- 开源自然语言处理工具包hanlp中CRF分词实现详解
CRF简介 CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比MEMM更能抵抗标记偏置的问题. [gerative-discriminative.png] CRF训练 这类耗时的任务,还 ...
- CRF分词的纯Java实现
与基于隐马尔可夫模型的最短路径分词.N-最短路径分词相比,基于随机条件场(CRF)的分词对未登录词有更好的支持.本文(HanLP)使用纯Java实现CRF模型的读取与维特比后向解码,内部特征函数采用 ...
- crf 分词(待)
http://blog.csdn.net/marising/article/details/5769653
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- Hanlp分词之CRF中文词法分析详解
这是另一套基于CRF的词法分析系统,类似感知机词法分析器,提供了完善的训练与分析接口. CRF的效果比感知机稍好一些,然而训练速度较慢,也不支持在线学习. 默认模型训练自OpenCorpus/pku9 ...
- 用条件随机场CRF进行字标注中文分词(Python实现)
http://www.tuicool.com/articles/zq2yyi http://blog.csdn.net/u010189459/article/details/38546115 主题 ...
- 基于CRF的中文分词
http://biancheng.dnbcw.info/java/341268.html CRF简介 Conditional Random Field:条件随机场,一种机器学习技术(模型) CRF由J ...
随机推荐
- IFIX 5.9 历史数据 曲线 (非SQL模式)
装完 ifix 5.9 默认是没有Hist 开头的 历史数据源的,没存,至少我装的版本是这样. 那个Historian 也没有安装包,好像还要授权,自己研究不了. 1 先把数据存本地 在你的安装包里 ...
- Leetcode(38)-报数
报数序列是指一个整数序列,按照其中的整数的顺序进行报数,得到下一个数.其前五项如下: 1. 1 2. 11 3. 21 4. 1211 5. 111221 1 被读作 "one 1&quo ...
- Leetcode(27)-移除元素
给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成 ...
- Petrozavodsk Summer Training Camp 2016H(多标记线段树)题解
题意: \(n\)个草,第\(0\)天种下,高度都为\(0\),每个草每天长高\(a_i\).现给出\(q\)询问,每次给出第\(b_i\)天,然后把高于\(d_i\)的全削成\(d_i\),每次问你 ...
- Spring(二) Mini版Spring的实现
实现思路 先来介绍一下 Mini 版本的 Spring 基本实现思路,如下图所示: 自定义配置 配置 application.properties 文件 为了解析方便,我们用 application. ...
- HTML5 动效
HTML5 动效 motion graphics toolbelt for the web https://github.com/xgqfrms/mojs A collection of loadin ...
- css 命名冲突 & solution
css 命名冲突 & solution 类似这样,为了解决模块间可能存在的 css 命名冲突问题,需要单独提供给模块开发者一套模块开发环境:同时,文档上要有如何使用的规范说明. CSS 建议: ...
- input number css hidden arrow
input number css hidden arrow show arrow OK input[type="number"]::-webkit-inner-spin-butto ...
- c++ DWORD和uintptr_t
x86模式 DWORD 是4字节 x86模式 uintptr_t 是4字节 x64模式 DWORD 是4字节 x64模式 uintptr_t 是8字节 std::cout << sizeo ...
- uniapp 扫二维码跳转
在h5和wxapp中 生成qrcode的组件 https://ext.dcloud.net.cn/plugin?id=39 wx小程序扫二位码文档 生成链接时 computed: { ...mapSt ...