ResNet论文笔记
其实ResNet这篇论文看了很多次了,也是近几年最火的算法模型之一,一直没整理出来(其实不是要到用可能也不会整理吧,懒字头上一把刀啊,主要是是为了将resnet作为encoder嵌入到unet架构中,自己复现模型然后在数据集上进行测试所以才决定进行整理),今天把它按照理解尽可能详细的解释清楚跟大家一起分享一下,哪里没有说明白或者说错的,欢迎指出留言。
深度残差神经网络(Residual Networks)是2015年(12月在arxiv.org可下载)何凯明大神提出来的一个神经网络模型,获得了2015年多个竞赛数据集的第一。模型被提出主要是为了解决如下两个主要问题:
- 减缓深度学习模型难以训练的问题(e.g. 超过100层的神经网络)
- 模型退化(degradation problem)问题,这个之后会详细解释什么是退化(表示看了论文很迷茫,还是看了不少别人的博客才恍然大悟)
这里还有一点需要被注意的是,深度残差网络是基于这么一个假设:越深的网络理应具备更好的学习能力。这个后来也确实被证明层数的增加确实带来不一样的效果,不论以什么样的形式叠加和计算(如AlexNet、GoogLeNet、DenseNet等等)。
一、简要介绍
虽然假设越深的网络应该具备更好的表征学习能力,但是接踵而来的问题也很明显,如梯度消失和梯度爆炸(vanishing/exploding gradients)会阻碍收敛的情况。但是归一化(normalized initialization & batch normalization)都极大程度的缓解了梯度所带来的问题。相反的,深度学习网络所面对的不是收敛不收敛的问题,反而是随着层数的增加所面临的网络退化问题,原文如是说:with the network depth increasing, accuracy gets saturated and then degrades rapidly。需要注意的是网络的退化不是因为过拟合等导致的。
那什么是“退化”呢?这里主要分成两块来详细进行解释:
①随着网络训练层数的增加,退化问题会以正确性达到饱和程度,这是可预见或者说符合预期的。但是何为“可预见”呢?这主要是搭建网络的时候,一般期望足够深的网络是具备相应的学习能力的,以此来保证所创建的模型能足以良好地表征(modelling)数据中所有的特征。那么这个时候就会想,是否额外增加层数会加强网络的学习能力并使其能完全学习到数据中的所有特征。然而根据观察并不是如此,当网络层数的增加(层数增加在准确率饱和区间之后),网络的预测准确率不升反降。当然这个可以认为是过拟合导致的。但是如果不是过拟合导致的原因呢?

②假设现在有一个N层网络,它的训练误差为e1,对于另外一个网络M层网络(M > N),我们的期望是至少该M层网络的表现能力跟N层网络的表现能力是一致的。假设M层网络的前面部分网络是N层网络构成,然后剩下的M-N层网络由恒等映射网络构成,也就是说剩下的这些网络的每一层的输入和输出保持一致,没有任何多余的因素加入,这么做的原因是希望后续的网络能很好的学习前N层网络学习的结果,如果存在这么一个M层网络,就希望它具备更好的表征能力。但是事实却不是如此,上图来自于原论文,可以看出深层网络并没有带来更好的结果。这就是所谓的网络退化问题,也是ResNet提出来最主要要解决的问题。那ResNet是如何解决退化问题的呢?
二、残差模块
残差模块就是ResNet提出来解决退化问题的,其主要结构如下图所示。也就是说经过叠加的基层神经网络之后,原本前面的输出会和这几层叠加神经网络输出叠加(论文中称之为恒等映射)作为下一个叠加模块的输入。假设放到卷积神经网络中,它的表现形式就是(output + ((conv + bn + relu) + (conv + bn))) + relu。这么做有一个优势就是恒等映射并不会引入新的训练参数或者增加额外的计算开销。

除此之外,残差神经网络还具备如下两个有点:①比没有引入残差模块的普通叠加网络来说具备更好的收敛及更易于优化,②除此之外,对比一般残差网络能极大地提升训练和预测地准确度。下图是ResNet-34的网络结构图:
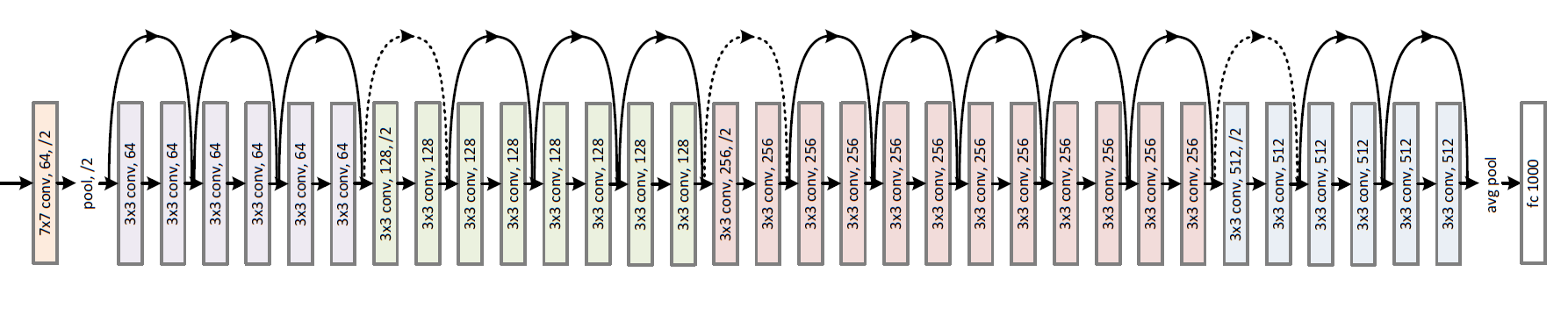
这里有些朋友对Highway Networks(15年5月)可能有了解觉得ResNet跟其是一个类型的网络,甚至有说ResNet就是变种的highway networks(这个跟论文的发布前后有关系,因为highway networks比resnet早几个月诞生,其实有点撞车的意味)。当然何凯明大神在论文中有指出他们跟highway networks的差别,主要体现在下两方面:
- highway network提出的short-cut connection with gating function是与数据独立开来的,并且有学习参数,而ResNet的identity mapping(恒等映射)是没有任何参数的;
- highway network没有提到任何关于深度网络(特别是100层以上的网络)所体现出来的性能和在特定数据上训练的结果(这点ResNet确实做得更好,其实深度学习领域相关的算法往往是先有实践后有理论,所以实验的论证是非常有必要的,ResNet在这上面做的实验是很充足,这点也反映在论文上面);
ResNet论文笔记的更多相关文章
- 转载:resNet论文笔记
<Deep Residual Learning for Image Recognition>是2016年 kaiming大神CVPR的最佳论文 原文:http://m.blog.csdn. ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- ResNet学习笔记
ResNet学习笔记 前言 这篇文章实在看完很多博客之后写的,需要读者至少拥有一定的CNN知识,当然我也不知道需要读者有什么水平,所以可能对一些很入门的基本的术语进行部分的解释,也有可能很多复杂的术语 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- 在4.0框架下使用Sqlite数据库
在4.0框架下使用Sqlite数据库出现"混合模式程序集是针对"v2.0.50727"版的运行时生成的,在没有配置其他信息的情况下,无法在 4.0 运行时中加载该程序集. ...
- leetcode 22. 括号生成 dfs
先思考符合要求的串是什么样子的 任意时刻,(数量大于),且最后(==)==n即可 考虑下一个加入string的字符时(或者)即可 dfs class Solution { public: vector ...
- 白日梦的ES笔记三:万字长文 Elasticsearch基础概念统一扫盲
目录 一.导读 二.彩蛋福利:账号借用 三.ES的Index.Shard及扩容机制 四.ES支持的核心数据类型 4.1.数字类型 4.2.日期类型 4.3.boolean类型 4.4.二进制类型 4. ...
- GPU 加速 & WebGL
GPU 加速 & WebGL 开启 GPU 加速, 硬件加速 垃圾面试官,瞎忽悠 holy shit 美国想象力英语,前端 leader WebGL 加速 ??? 是什么鬼 ??? three ...
- js var & let & const All In One
js var & let & const All In One js var & let & const 区别对比 var let const 区别 是否存在 hois ...
- skills share & free videos
skills share & free videos 技术分享 & 免费视频 https://www.infoq.cn/video/list WebAssembly https://w ...
- Xpath in JavaScript
test html <p>title</p> <ul class="list a" id="list"> <li> ...
- Flutter 创建透明的路由页面
原文 import 'package:flutter/material.dart'; void main() => runApp(MyApp()); class MyApp extends St ...
- 人物传记——Kyle Tedford:持之以恒的品质从哪里来?
心理学家表示,95%的人类行为发生在无意识中,而大多数这种行为是由习惯引起的.习惯,就像我们大脑设定的程序.通过每日持续努力,你会把坚持的习惯节奏慢慢进入身体中,并且会很容易加持下去. 做事三分钟热度 ...
- SQL EXPLAIN解析
本文转载自MySQL性能优化最佳实践 - 08 SQL EXPLAIN解析 什么是归并排序? 如果需要排序的数据超过了sort_buffer_size的大小,说明无法在内存中完成排序,就需要写到临时文 ...