DDD(领域驱动设计)--战略设计

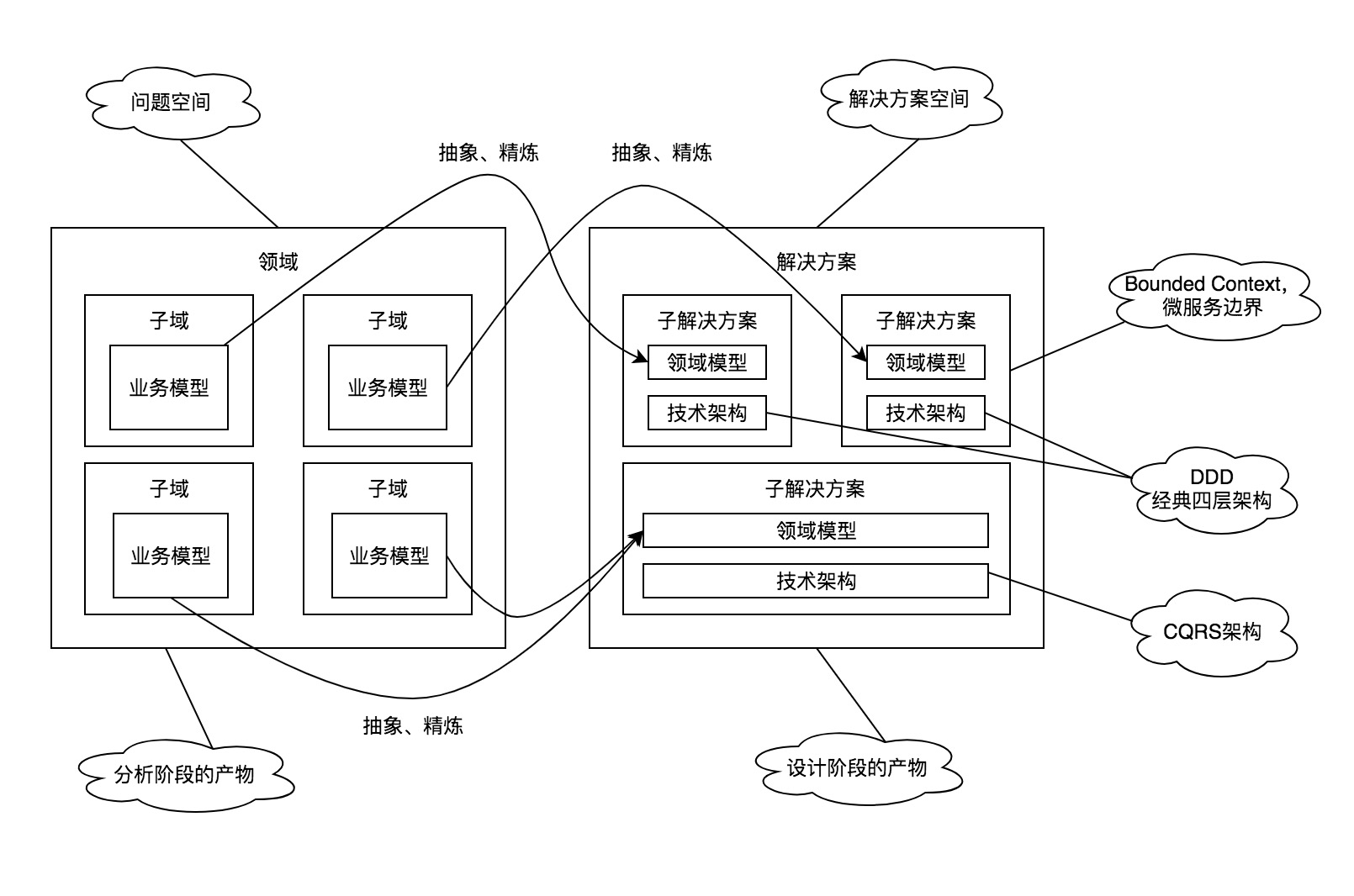
领域
领域是一个组织所做的事情以及其中所包含的一切。商业机构通常会确定一个市场,然后在这个市场中销售产品和服务。每个组织都有它自己的业务范围和做事方式。
领域就是解决一个特定范围内的业务问题。
如何分析领域
在研究与建模的过程中,开发人员是不能孤军奋战的,这个时候需要找领域专家一起建模,领域专家是精通业务的任何人,他们可能是软件产品的设计者,甚至有可能是销售。
领域专家把他的知识传给开发者,让建模更符合实际业务情况,以此也能获得更好的用户体验。
子域
分而治之,DDD是一套处理复杂领域的设计方法。
当我们遇到一个复杂的问题时,通常的做法就是将问题一步一步地细化,再针对细化出来的问题域逐个深入研究。当所有的子问题都完成研究时,我们也就建立了全部领域的完整知识。
子域是整个业务领域的一部分,大多数的业务领域都过于庞大和复杂,难以作为整体来分析,因此需要对整个业务领域进行拆分。
子域划分
- 核心域:它是一个定义明确的领域模型,需要投入大量资源去精心打磨的子域。它是组织中最重要的模块,因为这将是和其他竞争者的区别所在,需要把这个核心域打造成为组织的核心竞争力。
- 支撑域:这类子域,可能找不到现成的解决方案,对它的投入如何也达不到与核心域相同的程度。但核心域的成功离不开支撑域。这个子域不需要过度地考虑可扩展性和兼容性,如果要考虑的,应该是可替代性。这也就要求支撑子域需要有明确的契约规范和业务约束条件。这种子域一般提倡“定制开发”。
- 通用域:通用子域内的业务规则相对明确,一般解决方案可以通过采购获取,对其定制化要求比较低,而稳定性和兼容性则要求较高。
现实世界中领域与子域
领域中还同时存在问题空间和解决空间。在问题空间中,我们思考的是业务所面临的挑战,而在解决方案空间中,我们思考如何实现软件以解决这些业务挑战。
通用语言(Ubiquitous Language)
日常开发过程中,大家应该都有这种感受,在和产品经理、运营等交流过程中,经常会有各种扯皮,没法沟通的时候,很大一部分原因就是大家沟通的时候,用词含义不一致导致的。
要想创建一种灵活的、蕴含丰富知识的设计,需要一种通用的、共享的团队语言。如果语言支离破碎,项目必将受阻,实现过程中可能得不到符合要求的产品。
所以我们需要有一套通用语言,领域专家、产品、开发、运营等通用的语言,需要包括类和主要操作的名称。并将这些通用语言应用到需求讨论、技术方案设计、图和代码中。
限界上下文(Bounded Context)
生物学中,我们知道,细胞之所以能够存在,是因为细胞膜限定了什么在细胞内,什么在细胞外,并且确定了什么物质可以通过细胞膜。
软件系统中也是一样,我们需要有一个限界上下文,明确地定义模型所应用的上下文,根据团队的组织,软件系统的各个部分的用法以及物理表现(代码合数据库模式)来设置模型的边界。在这些边界中严格保持模型的一致性,而不要受到边界之外问题的干扰和混淆。
限界上下文是一个显式的边界,领域模型变存在于这个边界之内。每一个模型概念,包括它的属性和操作,在边界之内都具有特殊的含义。
在现实世界中,领域的边界很模糊,但是要设计一个好的解决方案,我们需要对问题子域加上一个边界,将不重要的信息排除在边界外。让解决方案专心解决重点问题。
每个上下文都代表着该解决方案的专业知识。在同一个上下文里,我们共享统一的语言和一致的设计。
通过界限上下文人为将问题子域限制在有限的界限内,你才可以着手创建解决方案。
上下文映射(Context Mapping)
每个限界上下文不可能独立存在,基本都需要与其他上下文进行集成,上下文映射是为了用来描述限界上下文之间的协作问题。这种集成关系在DDD中成为上下文映射,有如下几种映射方式。
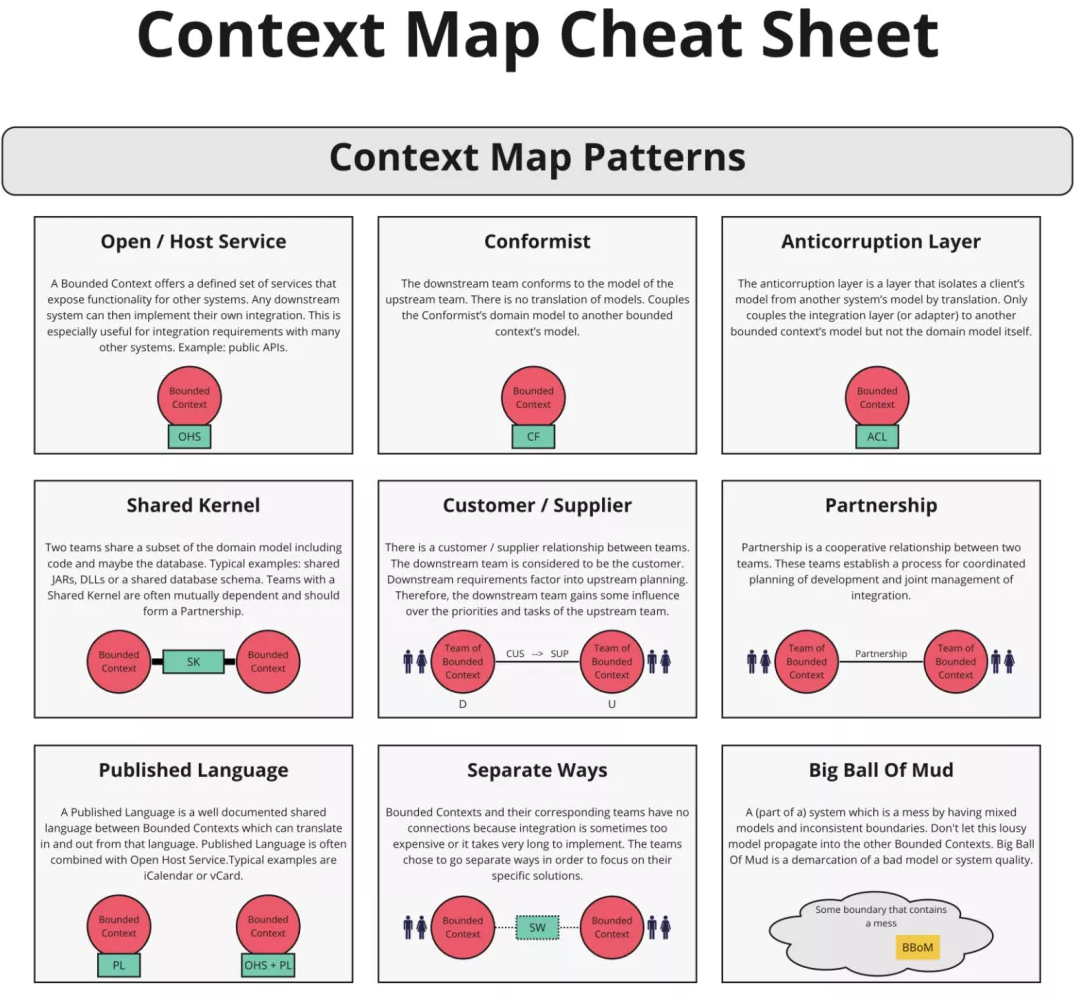
合作关系(Partnership):如果两个限界上下文的团队要么一起成功,要么一起失败,要么一起成功,此时他们需要建立起一种合作关系。合作越多依赖越多,耦合越严重,甚至出现双向依赖。
共享内核(Shared Kernel):当不同团队开发一些紧密相关的应用时,如果团队直接不进行协调,即使短时间能够取得快速进展,但他们开发出来的产品可能无法结合到一起。最后可能不得不耗费大量精力在转换层上,并且频繁地进行改动,不如一开始就从领域模型中选出两个团队都同意共享的一个子集,减少重复的工作。这种模式下,在没有与另一个团队协商的情况下,这种状态是不可改变的,同时需要引入一种持续集成过程来保证共享内核与通用语言的一致性。
客户方-供应方开发(Customer-Supplier Development):正常情况下,这是团队合作中最为常见的合作模式。当两个团队处于一种上游-下游关系时,上游团队可能独立于下游团队完成开发,此时下游团队的开发可能会受到很大的影响。因此,在上游团队的计划中,我们应该顾及到下游团队的需求。
遵奉者/追随者(Confoemist):下游团队直接使用上游团队的模型,简化集成。
防腐层(Anticorruption Layer):防腐层通过已有的接口与其他系统交互,而其他系统只需要做很小的修改,甚至无须修改。在防腐层内部,它在你自己的模型和他方模型之间翻译转换。
开放主机服务(Open Host Service):定义一种协议,让你的子系统通过该协议来访问你的服务。你需要讲该协议公开,这样任何想与你集成的人都可以使用该协议。
发布语言(Published Language):在两个限界上下文之间翻译模型需要一种公用的语言。此时你应该使用一种发布出来的共享语言来完成集成交流。发布语言通常与开放主机服务一起使用。
另谋他路/各行其道(SpeparateWay):在确定需求时,我们应该做到坚决彻底。如果两套功能没有显著的关系,那么它们是可以被完全解耦的。集成总是昂贵的,有时带给你的好处也不大。声明两个限界上下文之间不存在任何关系,这样使得开发者去另外寻找简单的、专门的方法来解决问题。
大泥球(Big Ball of Mud):当我们检查已有系统时,经常会发现系统中存在混杂在一起的模型,它们之间的边界是非常模糊的。此时你应该为整个系统绘制一个边界,然后将其归纳在大泥球范围之列。在这个边界之内,不要尝试使用复杂的建模手段来化解问题。同时,这样的系统有可能会向其他系统蔓延,你应该对此保持警觉。
参考资料
- 《领域驱动设计——软件核心复杂性应对之道》
- 《实现领域驱动设计》
- DDD战略设计相关核心概念的理解
- 上下文映射与协作
- ThoughtWorks洞见-再谈领域驱动设计
- context-mapping
DDD(领域驱动设计)--战略设计的更多相关文章
- DDD 领域驱动设计-商品建模之路
最近在做电商业务中,有关商品业务改版的一些东西,后端的架构设计采用现在很流行的微服务,有关微服务的简单概念: 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成.系统中的各个微服务可被独 ...
- 浅谈我对DDD领域驱动设计的理解
从遇到问题开始 当人们要做一个软件系统时,一般总是因为遇到了什么问题,然后希望通过一个软件系统来解决. 比如,我是一家企业,然后我觉得我现在线下销售自己的产品还不够,我希望能够在线上也能销售自己的产品 ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(3)
上一篇:<DDD 领域驱动设计-谈谈 Repository.IUnitOfWork 和 IDbContext 的实践(2)> 这篇文章主要是对 DDD.Sample 框架增加 Transa ...
- DDD 领域驱动设计-两个实体的碰撞火花
上一篇:<DDD 领域驱动设计-领域模型中的用户设计?> 开源地址:https://github.com/yuezhongxin/CNBlogs.Apply.Sample(代码已更新) 在 ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(2)
上一篇:<DDD 领域驱动设计-谈谈 Repository.IUnitOfWork 和 IDbContext 的实践(1)> 阅读目录: 抽离 IRepository 并改造 Reposi ...
- DDD 领域驱动设计-领域模型中的用户设计
上一篇:<DDD 领域驱动设计-如何控制业务流程?> 开源地址:https://github.com/yuezhongxin/CNBlogs.Apply.Sample(代码已更新,并增加了 ...
- DDD 领域驱动设计-如何控制业务流程?
上一篇:<DDD 领域驱动设计-如何完善 Domain Model(领域模型)?> 开源地址:https://github.com/yuezhongxin/CNBlogs.Apply.Sa ...
- DDD 领域驱动设计-如何完善 Domain Model(领域模型)?
上一篇:<DDD 领域驱动设计-如何 DDD?> 开源地址:https://github.com/yuezhongxin/CNBlogs.Apply.Sample(代码已更新) 阅读目录: ...
- DDD领域驱动设计之领域服务
1.DDD领域驱动设计实践篇之如何提取模型 2.DDD领域驱动设计之聚合.实体.值对象 3.DDD领域驱动设计之领域基础设施层 什么是领域服务,DDD书中是说,有些类或者方法,放实体A也不好,放实体B ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(1)
好久没写 DDD 领域驱动设计相关的文章了,嘎嘎!!! 这几天在开发一个新的项目,虽然不是基于领域驱动设计的,但我想把 DDD 架构设计的一些东西运用在上面,但发现了很多问题,这些在之前的短消息项目中 ...
随机推荐
- 第七章 TCP和UDP原理
一.引入 1.TCP/IP协议族的传输层协议主要包括TCP和UDP 2.TCP是面向连接的可靠的传输层协议.它支持在并不可靠的网络上实现面向连接的可靠的数据传输 3.UDP是无连接的传输协议,主要用于 ...
- jmeter环境变量配置
参考博客:超全 https://blog.csdn.net/qq_39720249/article/details/80721777
- Anderson《空气动力学基础》5th读书笔记 第3记——流动类型
一.连续介质与自由分子流动 分子之间相互碰撞的平均距离定义为平均自由程 .如果平均自由程的数量级远小于飞行器的尺寸时,此时,分子对物体的碰撞如此频繁以至于物体无法分辨出单个的分子碰撞,这时,对物体 ...
- poj1011 Sticks (搜索经典好题)
poj1011 Sticks 题目连接: poj1011 Description George took sticks of the same length and cut them randomly ...
- 2017年暑假ACM集训日志
20170710: hdu1074,hdu1087,hdu1114,hdu1159,hdu1160,hdu1171,hdu1176,hdu1010,hdu1203 20170711: hdu1231, ...
- Linux入门到放弃之六《磁盘和文件系统管理一》
要求:创建卷组名为 mail_store:逻辑卷名 mail,从卷组mail_store上划出50GB空间, 使用mkfs命令创建ext3文件系统,并实现开机自动挂载,挂载点/mailbox: (1) ...
- frida框架hook参数获取方法入参模板
python脚本 # -*- coding: utf-8 -*- import logging import frida import sys logging.basicConfig(level=lo ...
- 如何按名称或PID查找一个进程?如何按端口号查找一个进程?如何查看一个进程的CPU和内存、文件句柄使用情况?如何查看CPU利用率高的TOP10进程清单?如何根据PID强制终止进程?
如何按名称或PID查找一个进程?如何按端口号查找一个进程?如何查看一个进程的CPU和内存.文件句柄使用情况?如何查看CPU利用率高的TOP10进程清单? 目录 如何按名称或PID查找一个进程?如何按端 ...
- 输出5个大写英文字母的组合,并写入到txt文档中,随机数法。
1.问题起源:最近想申请几个英文商标,研究了一下,英文字母在4到7个之间最好,5个字母尤佳,所以先来输出5个字母的组合,可是想像力有限,于是想用排列组合把所有5个可能的字母组合都输出,再从中挑选几个感 ...
- Linux下如何使用X86 CPU的GPIO
目录 1.前言 2.linux pinctrl子系统 3. pin controller driver 4.手动构造device 1.前言 在arm嵌入式开发中,各个外设具有固定的物理地址,我们可以直 ...