LevelDB,你好~
LevelDB,你好~
上篇文章初识:LevelDB介绍了啥是LevelDB,LevelDB有啥特性,以及Linux环境下编译,使用及调试方法。
这篇文章的话,算是LevelDB源码学习的开端吧,主要讲下LevelDB的源码结构及LevelDB官方给出一些帮助文档内容,对于我个人来说,我感觉搞懂一门技术,不能直接陷到最层源码实现,而是先了解其设计原理,然后对照学习底层源码时才不会头昏脑胀~
LevelDB源码结构
LevelDB源码下载地址:https://github.com/google/leveldb.git。
leveldb-1.22
- cmake
- db LevelDB底层核心代码目录,诸如跳表,版本,MemTable等实现都在该目录下
- doc LevelDB的帮助文档
- helpers
- include LevelDB使用时需要引入的头文件
- issues
- port LevelDB底层是接入不同的文件系统的,这个目录主要是为了配置不同的文件系统平台的
- table LevelDB底层MemTable相关的诸如合并,遍历,布隆过滤器等相关实现源码
- util LevelDB底层实现中的一些工具类,例如hash,status等
- ...
上面对LevelDB源码的目录结构做了基本介绍,源码嘛,先不着急看,我们先来看看LevelDB官方给出了哪些帮助文档。
doc目录下是LevelDB提供给我们的一些帮助文档,如下图所示。
leveldb-1.22
- doc
- bench
- benchmark.html # 这两个文件呢,是LevelDB与SQLite等KV存储的性能对比,有兴趣的自己去看吧
- impl.md # 这个文件主要讲LevelDB底层实现原理,磁盘上存储的文件及大合并设计原理等
- index.md # 这个文件主要讲LevelDB基本API的使用方法
- log_format.md # 这个文件主要讲LevelDB的日志文件格式
- table_format.md # 这个文件主要讲LevelDB底层排序表的格式
接下来四部分内容依次对应doc目录中后四部分,第一部分性能对比有兴趣自己看吧~
LevelDB实现原理
LevelDB基本上是高度复刻了BigTable中的Tablet的,具体Tablet是啥样子,可以参考初识:BigTable,里面挺详细的,不清楚的小伙伴可以先去看下这篇文章。
尽管LevelDB高度复刻了Tablet的设计,然而,在底层文件组织中,还是与Tablet存在一些不同的。
对于数据库管理系统来说,每个数据库最终都是与某个目录下的一组文件对应的,对于LevelDB来说,每个数据库文件目录下的文件大致分为日志(Log)文件,排序表(Sorted Table)文件,Manifest文件,Current文件等等。
日志(Log)文件
日志(Log)文件中存储一系列顺序的更新操作,每次更新操作都会被追加到当前日志文件中。
当日志文件大小达到预定的大小(默认配置为4MB)时,日志文件会被转换为排序表(Sorted Table),同时创建新的日志文件,后续的更新操作会追加到新的日志文件中。
当前日志(Log)文件的拷贝会在内存中以跳表的数据结构形式(称为MemTable)保存,每次读取操作都会先查询该内存中的MemTable,以便所有的读操作都拿到的是最新更新的数据。
排序表(Sorted Table)
LevelDB中,每个排序表都存储一组按Key排序的KV键值对。每个键值对中要么存储的是Key的Value,要么存储的是Key的删除标记(删除标记主要用来隐藏之前旧的排序表中的过期Key)。
排序表(Sorted Tables)以一系列层级(Level)形式组织,由日志(Log)生成的排序表(Sorted Table)会被放在一个特殊的年轻(young)层级(Level 0),年轻(young)层级的文件数量超过某个阈值(默认为4个)时,所有年轻(young)层级的文件与Level 1层级重叠的所有文件合并在一起,生成一系列新的Level 1层级文件(默认情况下,我们将每2MB的数据生成一个新的Level 1层级的文件)。
年轻层级(Level 0)的文件可能存在重叠的Key,但是,其他级别的每个文件的Key范围都是非重叠的。
对于Level L(L>=1)层级的文件,当L层级的合并文件大小超过10^LMB(即Level为10MB, Level2为100MB...时进行合并。
将Level L层的一个文件file{L}与Level L+1层中所有与文件file{L}存在冲得的文件合并为Level L+1层级的一组新文件,这些合并过程会组件将最近的key更新操作与层级最高的文件通过批量读写的方式进行,优点在于,这种方式可以最大程度地减少昂贵的磁盘寻道操作。
清单/列表(Manifest)文件
单词Manifest本意是指清单,文件列表的意思,这里指的是每个Level中包含哪些排序表文件清单。
Manifest文件会列出当前LevelDB数据库中每个Level包含哪些排序表(Sorted Table),以及每个排序表文件包含的Key的范围以及其他重要的元数据。
只要重新打开LevelDB数据库,就回自动重新创建一个新的Manifest文件(文件名后缀使用新的编号)。
注意:Manifest会被格式化为log文件,LevelDB底层文件发生改变(添加/新建文件)时会自动追加到该log中。
当前(Current)文件
当前(CURRENT)文件是一个文本文件,改文件中只有一个文件名(最近生成的Manifest的文件名)。
Info Logs文件
Informational messages are printed to files named LOG and LOG.old.
其他文件
在某些特定场景下,LevelDB也会创建一些特定的文件(例如,LOCK, *.dbtmp等)。
Level 0层级
当日志(Log)文件大小增加到特定值(默认为4MB)时,LevelDB会创建新的MemTable和日志(Log)文件,并且后续用户写入的数据及更新操作都会直接写到新的MemTable和Log中。
后台主要完成的工作:
- 将之前内存中的MemTable写入到SSTable中
- 丢弃掉旧的MemTable
- 删除旧的日志(Log)文件和MemTable
- 添加新的SSTable到年轻(Level 0)层级
合并基本原理
当Level L层级的大小超过限制时,LevelDB会在后台进行大合并。
大合并会从Level L选择一个文件file{L},假设文件file{L}的key范围为[keyMin, keyMax],LevelDB会从Level L+1层级选择在文件file{L}的key范围内的所有文件files{L+1}与文件file{L}进行合并。
注意:如果Level L层级中文件file{L}仅仅与Level L+1层中某个文件的一部分key范围重叠,则需要将L+1层级中的整个文件作为合并的输入文件之一进行合并,并在合并之后丢弃该文件。
注意:Level 0层级是特殊的,原因在于,Level 0层级中的不同文件的范围可能是重叠的,这种场景下,如果0层级的文件需要合并时,则需要选择多个文件,以避免出现部分文件重叠的问题。
大合并操作会对前面选择的所有文件进行合并,并生成一系列L+1层级的文件,当输出的文件达到指定大小(默认大小为2MB)时,会切换到新的L+1层级的文件中;另外,当当前输出文件的key范围可以覆盖到L+2层级中10个以上的文件时,也会自动切换到新的文件中;最后这条规则可以确保以后在压缩L+1层级的文件时不会从L+2层级中选择过多的文件,避免一次大合并的数据量过大。
大合并结束后,旧的文件(排序表SSTable)会被丢弃掉,新文件则会继续对外提供服务。
其实,LevelDB自己有一个版本控制系统,即使在合并过程中,也可以正常对外提供服务的。
特定特定层级的大合并过程会在该层级key范围内进行轮转,更直白点说,就是针对每个层级,会自动记录该层级最后一次压缩时最大的key值,下次该层级压缩时,会选择该key之后的第一个文件进行压缩,如果没有这样的文件,则自动回到该层级的key最小的文件进行压缩,压缩在该层级是轮转的,而不是总是选第一个文件。
对于制定key,大合并时会删除覆盖的值;如果当前合并的层级中,该key存在删除标记,如果在更高的层级中不存在该key,则同时会删除该key及该key的删除标记,相当于该key从数据库中彻底删除了!!!
合并耗时分析
Level 0层级合并时,最多读取该层级所有文件(默认4个,每个1MB),最多读取Level 1层级所有文件(默认10个,每个大小约1MB),则对于Level 0层级合并来说,最多读取14MB,写入14MB。
除了特殊的Level 0层级大合并之外,其余的大合并会从L层级选择一个2MB的文件,最坏的情况下,需要从L+1层级中选择12个文件(选择10个文件是因为L+1层级文件总大小约是L层的10倍,另外两个文件则是边界范围,因为层级L的文件中key范围通常不会与层级L+1的对齐),总的来说,这些大合并最多读取26MB,写入26MB。
假设磁盘IO速率为100MB(现代磁盘驱动器的大致范围),最差的场景下,一次大合并需要约0.5秒。
假设我们将后台磁盘写入速度限制在较小的范围内,比如10MB/s,则大合并大约需要5秒,假设用户以10MB/s的速度写入,则我们可能会建立大量的Level 0级文件(约50个来容纳5*10MB文件),由于每次读取时需要合并更多的文件,则数据读取成本会大大增加。
解决方案一:为了解决这个问题,在Level 0级文件数量过多时,考虑增加Log文件切换阈值,这个解决方案的缺点在于,日志(Log)文件阈值越大,保存相应MemTable所需的内存就越大。
解决方案二:当Level 0级文件数量增加时,需要人为地降低写入速度。
解决方案三:致力于降低非常广泛的合并的成本,将大多数Level 0级文件的数据块以不压缩的方式放在内存中即可,只需要考虑合并的迭代复杂度为O(N)即可。
总的来说,方案一和方案三合起来应该就可以满足大多数场景了。
LevelDB生成的文件大小是可配置的,配置更大的生成文件大小,可以减少总的文件数量,不过,这种方式可能会导致较多的突发性大合并。
2011年2月4号,在ext3文件系统上进行的一个实验结果显示,单个文件目录下不同文件数量时,执行100k次文件打开平均耗费时间结果如下:
| 目录下文件数量 | 打开单个文件平均耗时时间 |
|---|---|
| 1000 | 9 |
| 10000 | 10 |
| 100000 | 16 |
从上面的结果来看,单个目录下,文件数量小于10000时,打开文件平均耗时差不多的,尽量控制单个目录下文件数量不要超过1w。
LevelDB数据库重启流程
- 读取CURRENT文件中存储的最近提交的MANIFEST文件名称
- 读取MANIFEST文件
- 清理过期文件
- 这一步可以打开所有SSTable,不过,最好使用懒加载,避免内存占用过高
- 将日志文件转换为Level 0级的SSTable
- 开始新的写入请求重定向到新的日志文件中
文件垃圾回收
在每次执行完大合并以及数据库恢复后,会调用DeleteObsoleteFiles()方法,该方法会检索数据库,获取数据库中中所有的文件名称,自动删除所有不是CURRENT文件中的日志(Log)文件,另外,该方法也会删除所有未被某个层级引用的,且不是某个大合并待输出的日志文件。
LevelDB日志(Log)格式
LevelDB日志文件是由一系列32KB文件块(Block)构成的,唯一例外的是日志文件中最后一个Block大小可能小于32KB。
每个文件块(Block)是由一系列记录(Record)组成的,具体格式如下:
block := record* trailer? // 每个Block由一系列Record组成
record :=
checksum: uint32 // type和data[]的crc32校验码;小端模式存储
length: uint16 // 小端模式存储
type: uint8 // Record的类型,FULL, FIRST, MIDDLE, LAST
data: uint8[length]
注意:如果当前Block仅剩余6字节空间,则不会存储新的Record,因为每个Record至少需要6字节存储校验及长度信息,对于这些剩余的字节,会使用全零进行填充,作为当前Block的尾巴。
注意:如果当前Block剩余7字节,且用户追加了一个数据(data)长度非零的Record,该Block会添加类型为FIRST的Record来填充剩余的7个字节,并在后续的Block中写入用户数据。
Record格式详解
Record目前只有四种类型,分别用数字标识,后续会新增其他类型,例如,使用特定数字标识需要跳过的Record数据。
FULL == 1
FIRST == 2
MIDDLE == 3
LAST == 4
FULL类型Record标识该记录包含用户的整个数据记录。
用户记录在Block边界处存储时,为了明确记录是否被分割,使用FIRST,MIDDLE,LAST进行标识。
FIRST类型Record用来标识用户数据记录被切分的第一个Record。
LAST类型Record用来标识用户数据记录被切分的最后一个Record。
MIDDLE则用来标识用户数据记录被切分的中间Record。
例如,假设用户写入三条数据记录,长度分别如下:
| Record 1 Length | Record 2 Length | Record 3 Length |
|---|---|---|
| 1000 | 97270 | 8000 |
Record 1将会以FULL类型存储在第一个Block中;
Record 2的第一部分数据长度为31754字节以FIRST类型存储在第一个Block中,第二部分数据以长度为32761字节的MIDDLE类型存储在第二个Block中,最易一个长度为32761字节数据以LAST类型存储在第三个Block中;
第三个Block中剩余的7个字节以全零方式进行填充;
Record 3则将以Full类型存储在第三个Block的开头;
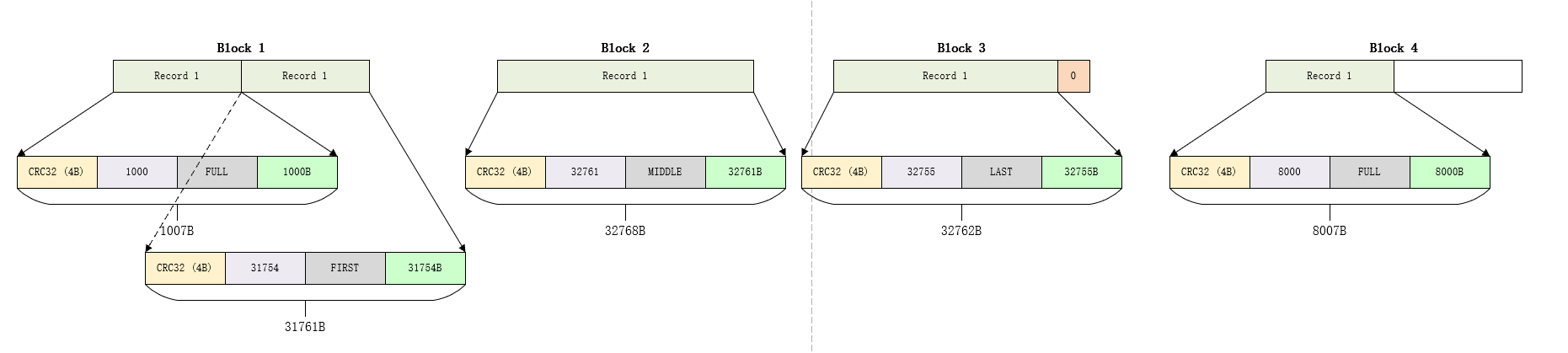
Block格式详解
上述可以说是把Record格式的老底掀了个底掉,下面给出Block的数据格式到底是啥样,小伙伴们不好奇嘛?赶快一起瞅一眼吧
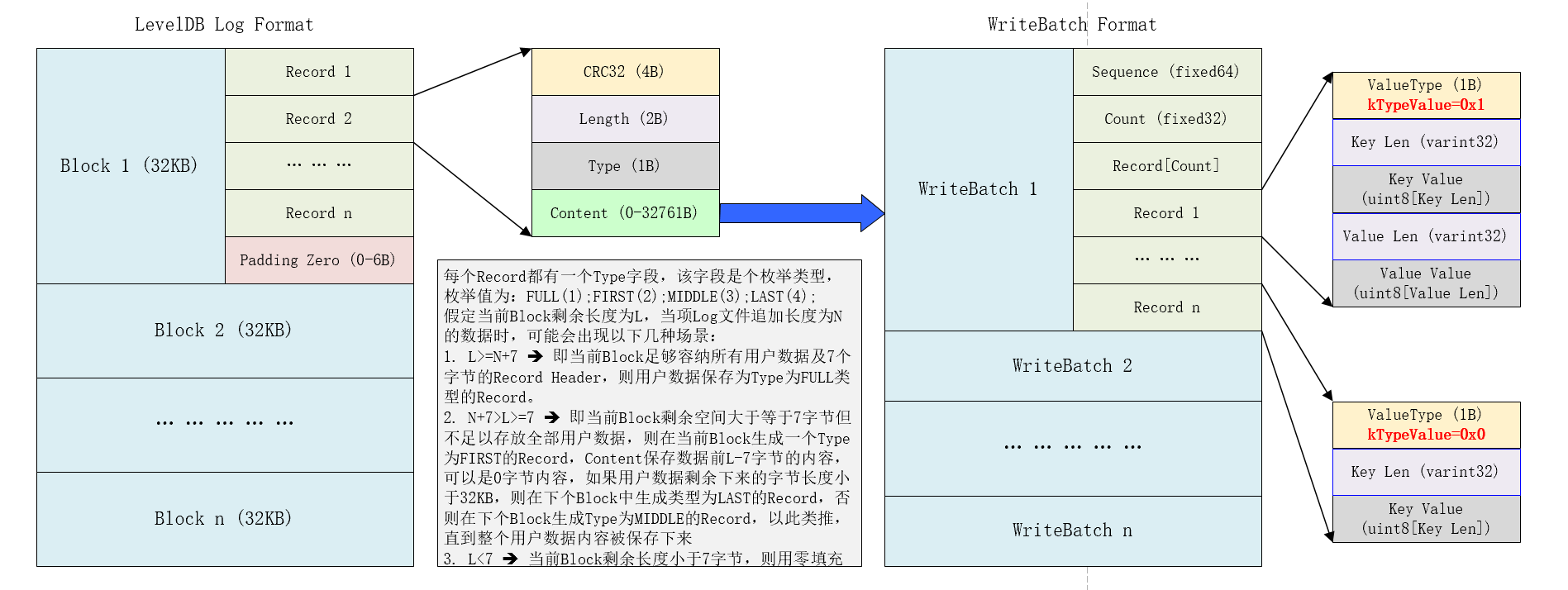
通过上图可以清晰的看到Block与Record之间的关系到底是啥样?
- LevelDB的日志文件将用户数据切分称连续的大小为32KB的Block块;
- 每个Block由连续的Log Record构成;
- 每个Log Record由CRC32,Length,Type,Content总共4部分构成;
Level日志格式优缺点
人间事,十有八九不如意;人间情,难有白头不相离。
LevelDB这种日志格式也不可能完美咯,让我们一起来掰扯掰扯其优缺点吧~
LevelDB日志格式优点
- 在日志数据重新同步时,只需要转到下一个Block继续扫描即可,如果Block存在有损坏,直接跳到下个Block处理即可。
- 当一个日志文件的部分内容作为记录嵌入到另一个日志文件中时,不需要特殊处理即可使用。
- 对于需要在Block边缘处进行拆分的应用程序(例如,MapReduce),处理时很简单:找到下个Block边界并跳过非FIRST/FULL类型记录,直到找到FULL或FIRST类型记录为止。
- 对于较大的记录,不需要额外的缓冲区即可处理。
LevelDB日志格式缺点
- 对于小的Record数据没有进行打包处理,不过,这个问题可以通过添加Record类型进行处理。
- 数据没有进行压缩,不过,这个问题同样可以通过添加Record类型进行处理。
额(⊙o⊙)…看起来,好像没有啥缺点,O(∩_∩)O哈哈~
个人感觉哈,对于日志来说,LevelDB的这种格式问题不大,毕竟,日志(例如,WAL)等通常存在磁盘上,一般情况下,也会做定期清理,对系统来说,压力不会太大,也还行,问题不大。
LevelDB Table Format
SSTable全称Sorted String Table,是BigTable,LevelDB及其衍生KV存储系统的底层数据存储格式。
SSTable存储一系列有序的Key/Value键值对,Key/Value是任意长度的字符串。Key/Value键值对根据给定的比较规则写入文件,文件内部由一系列DataBlock构成,默认情况下,每个DataBlock大小为4KB,通常会配置为64KB,同时,SSTable存储会必要的索引信息。
每个SSTable的格式大概是下面下面这个样子:
<beginning_of_file>
[data block 1]
[data block 1]
... ...
[data block N]
[meta block 1]
... ...
[meta block K] ===> 元数据块
[metaindex block] ===> 元数据索引块
[index block] ==> 索引块
[Footer] ===> (固定大小,起始位置start_offset = filesize - sizeof(Footer))
<end_of_file>
SSTable文件中包含文件内部指针,每个文件内部指针在LevelDB源码中称为BlockHandle,包含以下信息:
offset: varint64
size: varint64 # 注意,varint64是可变长64位整数,这里,暂时不详细描述该类型数据的实现方式,后续再说
- SSTable中的key/value键值对在底层文件中以有序的方式存储在一系列DataBlock中,这些DataBlock在文件开头处顺序存储,每个数据块的实现格式对应LevelDB源码中的
block_builder.cc文件,每个数据块可以以压缩方式存储 - DataBlock后面存储了一系列元数据块(MetaBlock),元数据块格式化方式与DataBlock一致
- MetaIndex索引块(MetaBlockIndex),该索引块中每项对应一个元数据块的信息,包括元数据块名称及元数据块在文件中的存储位置信息(即前面提到的BlockHandle)
- DataIndex索引块(DataBlockIndex),该索引块中每项(Entry)对应一个数据块信息,每项信息中包含一个大于等于DataBlock中最大的Key且小于后续DataBlock中第一个Key的字符串以及该DataBlock的BlockHandle信息
- 每个SSTable文件的尾部都是一个固定大小的Footer,该Footer包含MetaBlockIndex及DataBlockIndex的BlockHandle信息以及尾部魔数,中间空余字节使用全零字节进行填充
Footer的格式大概是下面这个样子:
metaindex_handle: char[p]; // MetaDataIndex的BlockHanlde信息
index_handle: char[q]; // DataBlockIndex的BlockHandle信息
padding: char[40-q-p]; // 全零字节填充
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // == 0xdb4775248b80fb57 (little-endian)
注意:metaindex_handle和index_handle最大占用空间为40字节,本质上就是varint64最大占用字节导致,后续,抽时间将varint64时再给大家好好掰扯掰扯~
SSTable格式图文详解
上面全是文字描述,有点不是特别好懂,这里呢,给大家看下我画的一张图,可以说是非常的清晰明了~
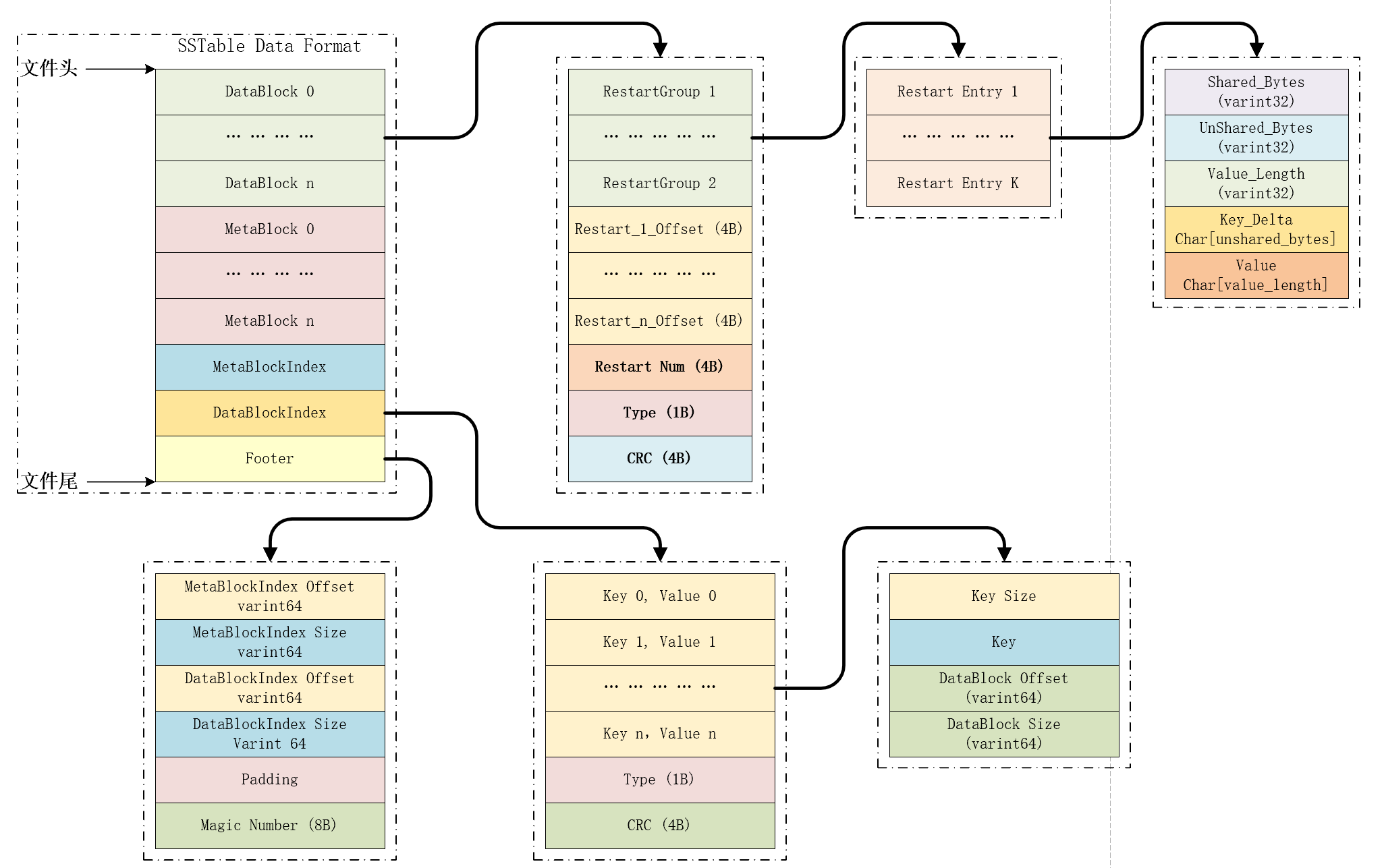
每个SSTable文件包含多个DataBlock,多个MetaBlock,一个MetaBlockIndex,一个DataBlockIndex,Footer。
Footer详解:
Footer长度固定,48个字节,位于SSTable尾部;
MetaBlockIndex的OffSet和Size及DataBlockIndex的OffSet和Size分别组成BlockHandle类型,用于在文件中寻址MetaBlockIndex与DataBlockIndex,为了节省磁盘空间,使用varint64编码,OffSet与Size分别最少占用1个字节,最多占用10个字节,两个BlockHandle占用的字节数量少于40时使用全零字节进行填充,最后8个字节放置SSTable魔数。
例如,DataBlockIndex.offset==64, DataBlockIndex.size=216,表示DataBlockIndex位于SSTable的第64字节到第280字节。
DataBlock详解:
每个DataBlock默认配置4KB大小,通常推荐配置64KB大小。
每个DataBlock由多个RestartGroup,RestartOffSet集合及RestartOffSet总数,Type,CRC构成。
每个RestartGroup由K个RestartEntry组成,K可以通过options配置,默认值为16,每16个Key/Value键值对构成一个RestartGroup;
每个RestartEntry由共享字节数,非共享字节数,Value字节数,Key非共享字节数组,Value字节数组构成;
DataBlockIndex详解:
DataBlockIndex包含DataBlock索引信息,用于快速定位到给定Key所在的DataBlock;
DataBlockIndex包含Key/Value,Type,CRC校验三部分,Type标识是否使用压缩算法,CRC是Key/Value及Type的校验信息;Key的取值是大于等于其索引DataBlock的最大Key且小于下一个DataBlock的最小Key,Value是BlockHandle类型,由变长的OffSet和Size组成。
两个有意思的问题
为什么DataBlockIndex中Key不采用其索引的DataBlock的最大Key?
主要是为了节省存储空间,假设该Key其索引的DataBlock的最大Key是"acknowledge",下一个block最小的key为"apple",如果DataBlockIndex的key采用其索引block的最大key,占用长度为len("acknowledge");采用后一种方式,key值可以为"ad"("acknowledge" < "ad" < "apple"),长度仅为2,且检索效果是一样的。
为什么BlockHandle的offset和size的单位是字节数而不是DataBlock?
SSTable中的DataBlock大小是不固定的,尽管option中可以指定block_size参数,但SSTable中存储数据时,并未严格按照block_size对齐,所以offset和size指的是偏移字节数和长度字节数;这与Innodb中的B+树索引block偏移有区别。主要有两个原因:
- LevelDB可以存储任意长度的key和任意长度的value(不同于Innodb,限制每行数据的大小为16384个字节),而同一个key/value键值对是不能跨DataBlock存储的,极端情况下,比如我们的单 个 value 就很大,已经超过了 block_size,那么这种情况,SSTable就无法进行存储了。所以,通常情况下,实际的DataBlock的大小都是要略微大于options中配置的block_size的;
- 如果严格按照block_size对齐存储数据,必然有很多DataBlock需要通过补0的方式进行对齐,肯定会浪费存储空间;
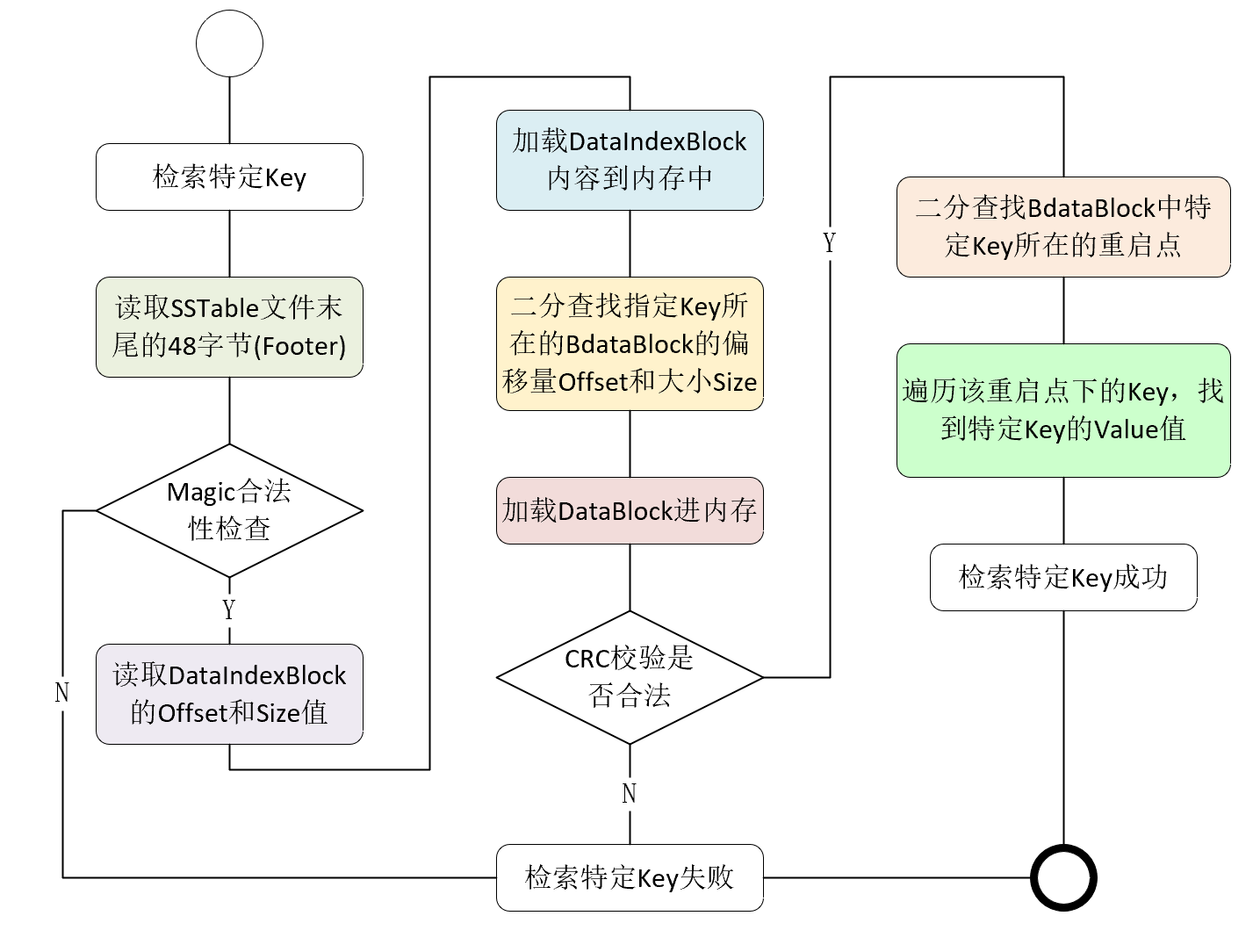
SSTable检索逻辑
基于以上实现逻辑,SSTable中的每个DataBlock主要支持两种方式读取存储的Key/Value键值对:
- 支持顺序读取DataBlock中所有Key/Value键值对
- 支持给定Key定位其所在的DataBlock,从而实现提高检索效率。
给定Key,SSTable检索流程:
遗留问题
不行了,再写下去,这篇文章字数又要破万了,写不动了,下篇文章再说吧、先打个Log,暂时有些问题还没讲清楚,如下:
- varint64到底是怎么实现的?
- SSTable中的DataBlock到底是怎么回事?
- LevelDB提供了哪些基础的API?
上面这些问题下篇文章再说,另外,我的每篇文章都是自己亲手敲滴,图也是自己画的,不允许转载的呦,有问题请私信呦~
其实,感觉LevelDB里面每个设计细节都可以好好学习学习的,欢迎各位小伙伴私信,一起讨论呀~
另外,希望大家关注我的个人公众号,更多高质量的技术文章等你来白嫖呦~~~

LevelDB,你好~的更多相关文章
- 用CIL写程序:你好,沃尔德
前言: 项目紧赶慢赶总算在年前有了一些成绩,所以沉寂了几周之后,小匹夫也终于有时间写点东西了.以前匹夫写过一篇文章,对CIL做了一个简单地介绍,不过不知道各位看官看的是否过瘾,至少小匹夫觉得很不过瘾. ...
- docker4dotnet #1 – 前世今生 & 世界你好
作为一名.NET Developer,这几年看着docker的流行实在是有些眼馋.可惜的是,Docker是基于Linux环境的,眼瞧着那些 java, python, node.js, go 甚至连p ...
- leveldb 性能、使用场景评估
最近有个业务写远远大于读,读也集中在最近写入,这不很适合采用leveldb存储么,leveldb业界貌似ssdb用得挺广,花了两天时间就ssdb简单做下测试,以下总结. ssdb 是leveldb的r ...
- leveldb源码分析--SSTable之Compaction
对于compaction是leveldb中体量最大的一部分,也应该是最为复杂的部分,为了便于理解我们首先从一些基本的概念开始.下面是一些从doc/impl.html中翻译和整理的内容: Level 0 ...
- java 写一个"HelloJavaWorld你好世界"输出到操作系统文件Hello.txt文件中
package com.beiwo.homework; import java.io.File; import java.io.FileOutputStream; import java.io.IOE ...
- leveldb 学习。
1)大概浏览了leveldb文档的介绍.本想逐步看代码,想想还是自己先实现一个看看如何改进. 2)完成了一个非常丑陋的初版,但是还是比初初版有进步. 3)key value的数据库,不允许有key重复 ...
- 解决: org.iq80.leveldb.DBException: IO error: C:\data\trie\000945.sst: Could not create random access file.
以太坊MPT树的持久化层是采用了leveldb数据库,然而在抽取MPT树代码运行过程中,进行get和write操作时却发生了错误: Caused by: org.fusesource.leveldbj ...
- 用Qt Creator 对 leveldb 进行简单的读写
#include <iostream> #include <string> #include <leveldb/db.h> #include <boost/l ...
- leveldb 学习笔记之VarInt
在leveldb在查找比较时的key里面保存key长度用的是VarInt,何为VarInt呢,就是变长的整数,每7bit代表一个数,第8bit代表是否还有下一个字节, 1. 比如小于128(一个字节以 ...
随机推荐
- IntelliJ IDEA安装配置、搭建Spring MVC
安装前必备软件: 1.jdk1.8.0_144安装包 2.IntelliJ IDEA 2016.1.1(64) 3.Tomcat安装包 4.Mysql.MySQL-JDBC驱动安装包 5.Jetbra ...
- BigDecimal类型比较数字大小
BigDecimal类型比较数字大小1.转成intBigDecimal b1 = new BigDecimal("-121454125453.145");if(b1.intValu ...
- Unity ugui Anchor锚点自动适配画布中的相对位置
本随笔参考了以下博客,在此基础上进行优化和改进: https://blog.csdn.net/qq_39640124/article/details/88284191 ugui中的Anchor预设如下 ...
- hive中left semi join 与join 的区别
LEFT SEMI JOIN:左半开连接会返回左边表的记录,前提是其记录对于右边表满足ON语句中的判定条件.对于常见的内连接(INNER JOIN),这是一个特殊的,优化了的情况.大多数的SQL方言会 ...
- Windows常用注册表文件
内容转载自我的博客 目录 1. 删除Visual Studio的右键菜单 2. 恢复Visual Studio的右键菜单 3. 右键菜单添加功能 4. USB3.0连接安卓手机刷机出现问题 1. 删除 ...
- 移动端1px像素解决方式,从1px像素问题剖析像素及viewport
在移动端web开发过程中,如果你对边框设置border:1px,会发现,边框在某些手机机型上面显示的1px比实际感觉会变粗,这也就是1像素问题.如下图是对桌面浏览器和移动端border设置1px的比较 ...
- NumPy基础知识图谱
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载.该图谱只是NumPy的基 ...
- [JAVA]SpringBoot中让接口支持跨域
官方原文:https://spring.io/blog/2015/06/08/cors-support-in-spring-framework ===抽空翻译 最简单办法:在方法上增加注解: @Cro ...
- 大型Java进阶专题(七) 设计模式之委派模式与策略模式
前言 今天开始我们专题的第七课了.本章节将介绍:你写的代码中是否觉得很臃肿,程序中有大量的if...else,想优化代码,精简程序逻辑,提升代码的可读性,这章节将介绍如何通过委派模式.策略模式让你 ...
- CTFHub_技能树_远程代码执行
RCE远程代码执行 命令分割符: linux: %0a .%0d .; .& .| .&&.|| 分隔符 描述 ; 如果每个命令都被一个分号(:)所分隔,那么命令会连续地执行下 ...