怎样用Java 8优雅的开发业务
怎样用Java 8优雅的开发业务
函数式编程
流式编程
基本原理
在Java中流式编程的基本原理有两点。
- 构建流
- 数据流转(流水线)
- 规约
IntStream.rangeClosed(1, 100) // 1. 构建流
.mapToObj(String::valueOf)// 2. 数据流转(流水线)
.collect(joining()); // 3. 规约
案例
- 英雄的主位置一共有几类,分别是什么
@Test
fun t1() {
// 英雄的主位置一共有几类,分别是什么
// 映射
val roleMains = heroes.map(Hero::getRoleMain)
// 过滤为空的数据
.filter(Objects::nonNull)
// 去重
.distinct()
println(roleMains.size)
println(roleMains)
}
@Test
public void t1() {
// 英雄的主位置一共有几类,分别是什么
List<String> roleMains = heroes.stream()
// 映射
.map(Hero::getRoleMain)
// 过滤为空的数据
.filter(Objects::nonNull)
// 去重
.distinct()
// 收集列表
.collect(toList());
System.out.println(roleMains.size());
System.out.println(roleMains);
}
- 英雄按主次位置分组后,输出每个分组有多少英雄,其中:近战英雄有多少位,远程英雄有多少位
@Test
fun t2() {
// 英雄按主次位置分组后,输出每个分组有多少英雄,其中:近战英雄有多少位,远程英雄有多少位
// 主次位置分组的英雄数量
val groupHeroCount = heroes.groupingBy {
Pair.of(it.roleMain, it.roleAssist)
}.eachCount()
// 主次分组后,再按攻击范围分组的英雄数量
val groupThenGroupCount = heroes.groupBy {
Pair.of(it.roleMain, it.roleAssist)
}.map {
val value = it.value.groupingBy(Hero::getAttackRange).eachCount()
Pair.of(it.key, value)
}.associateBy({ it.left }, { it.value })
// 遍历输出
groupThenGroupCount.forEach { (groupKey, groupValue) ->
val groupingCount = groupHeroCount[groupKey]
print("英雄分组key为:$groupKey;英雄数量:$groupingCount;")
groupValue.forEach { (countKey, countValue) ->
print("英雄攻击范围:$countKey;英雄数量:$countValue;")
}
println()
}
}
@Test
public void t2() {
// 英雄按主次位置分组后,输出每个分组有多少英雄,其中:近战英雄有多少位,远程英雄有多少位
// 主次位置分组的英雄数量
Map<Pair<String, String>, Long> groupHeroCount = heroes.stream()
.collect(groupingBy(hero -> Pair.of(hero.getRoleMain(), hero.getRoleAssist()), counting()));
// 主次分组后,再按攻击范围分组的英雄数量
Map<Pair<String, String>, Map<String, Long>> groupThenGroupCount = heroes.stream()
.collect(groupingBy(hero -> Pair.of(hero.getRoleMain(), hero.getRoleAssist()),
groupingBy(Hero::getAttackRange, counting())));
// 遍历输出
groupThenGroupCount.forEach((groupKey, groupValue) -> {
Long groupingCount = groupHeroCount.get(groupKey);
System.out.print("英雄分组key为:" + groupKey + ";英雄数量:" + groupingCount + ";");
groupValue.forEach((countKey, countValue) -> System.out.print("英雄攻击范围:" + countKey + ";英雄数量:" + countValue + ";"));
System.out.println();
});
}
- 求近战英雄HP初始值的加总
@Test
fun t3() {
// 求近战英雄HP初始值的加总
val sum = heroes.filter { "近战" == it.attackRange }
.map(Hero::getHpStart)
.filter(Objects::nonNull)
.reduce(BigDecimal::add)
println("近战英雄HP初始值的加总为:$sum")
}
@Test
public void t3() {
// 求近战英雄HP初始值的加总
BigDecimal sum = heroes.stream()
.filter(hero -> "近战".equals(hero.getAttackRange()))
.map(Hero::getHpStart)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
System.out.println("近战英雄HP初始值的加总为:" + sum);
}
- 通过最小列表收集器获取最小列表
@Test
public void t4() {
// 通过最小列表收集器获取最小列表
List<BigDecimal> minAttackGrowth = heroes.stream()
.map(Hero::getAttackGrowth)
.collect(new MinListCollector<>());
System.out.println(minAttackGrowth);
List<Hero> minHero = heroes.stream()
.collect(new MinListCollector<>());
System.out.println(minHero);
}
import java.util.*;
import java.util.concurrent.atomic.AtomicReference;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
import java.util.stream.Collectors;
import static java.util.stream.Collector.Characteristics.*;
/**
* 最小列表收集器
*
* @author switch
* @since 2020/8/18
*/
public class MinListCollector<T extends Comparable<? super T>> implements Collector<T, List<T>, List<T>> {
/**
* 收集器的特性
*
* @see Characteristics
*/
private final static Set<Characteristics> CHARACTERISTICS = Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH));
private final static int ZERO = 0;
/**
* 最小值
*/
private final AtomicReference<T> min = new AtomicReference<>();
@Override
public Supplier<List<T>> supplier() {
// supplier参数用于生成结果容器,容器类型为A
return ArrayList::new;
}
@Override
public BiConsumer<List<T>, T> accumulator() {
// accumulator用于消费元素,也就是归纳元素,这里的T就是元素,它会将流中的元素一个一个与结果容器A发生操作
return (list, element) -> {
// 获取最小值
T minValue = min.get();
if (Objects.isNull(minValue)) {
// 第一次比较
list.add(element);
min.set(element);
} else if (element.compareTo(minValue) < ZERO) {
// 发现更小的值
list.clear();
list.add(element);
min.compareAndSet(minValue, element);
} else if (element.compareTo(minValue) == ZERO) {
// 与最小值相等
list.add(element);
}
};
}
@Override
public BinaryOperator<List<T>> combiner() {
// combiner用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果A
return (left, right) -> {
// 最小值列表合并
List<T> leftList = getMinList(left);
List<T> rightList = getMinList(right);
leftList.addAll(rightList);
return leftList;
};
}
private List<T> getMinList(List<T> list) {
return list.stream()
.filter(element -> element.compareTo(min.get()) == ZERO)
.collect(Collectors.toList());
}
@Override
public Function<List<T>, List<T>> finisher() {
// finisher用于将之前整合完的结果R转换成为A
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
// characteristics表示当前Collector的特征值,这是个不可变Set
return CHARACTERISTICS;
}
}
优雅的空处理
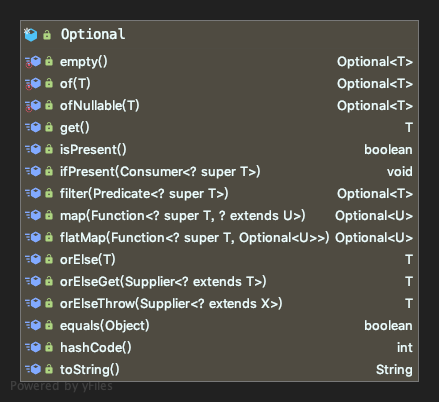
import org.junit.Test;
import java.util.Optional;
/**
* @author switch
* @since 2020/8/18
*/
public class OptionalTests {
@Test
public void t1() {
// orElse
System.out.println(Optional.ofNullable(null).orElse("张三"));
System.out.println(Optional.ofNullable(null).orElseGet(() -> "李四"));
System.out.println(Optional.ofNullable("王五").orElseThrow(NullPointerException::new));
}
@Test
public void t2() {
// isPresent
Optional<String> name = Optional.ofNullable("张三");
if (name.isPresent()) {
System.out.println(name.get());
}
}
@Test
public void t3() {
// map
Optional<Integer> number = Optional.of("123456").map(Integer::valueOf);
if (number.isPresent()) {
System.out.println(number.get());
}
}
@Test
public void t4() {
// flatMap
Optional<Integer> number = Optional.of("123456").flatMap(s -> Optional.of(Integer.valueOf(s)));
if (number.isPresent()) {
System.out.println(number.get());
}
}
@Test
public void t5() {
// 过滤
String number = "123456";
String filterNumber = Optional.of(number).filter(s -> !s.equals(number)).orElse("654321");
System.out.println(filterNumber);
}
}
新的并发工具类CompletableFuture
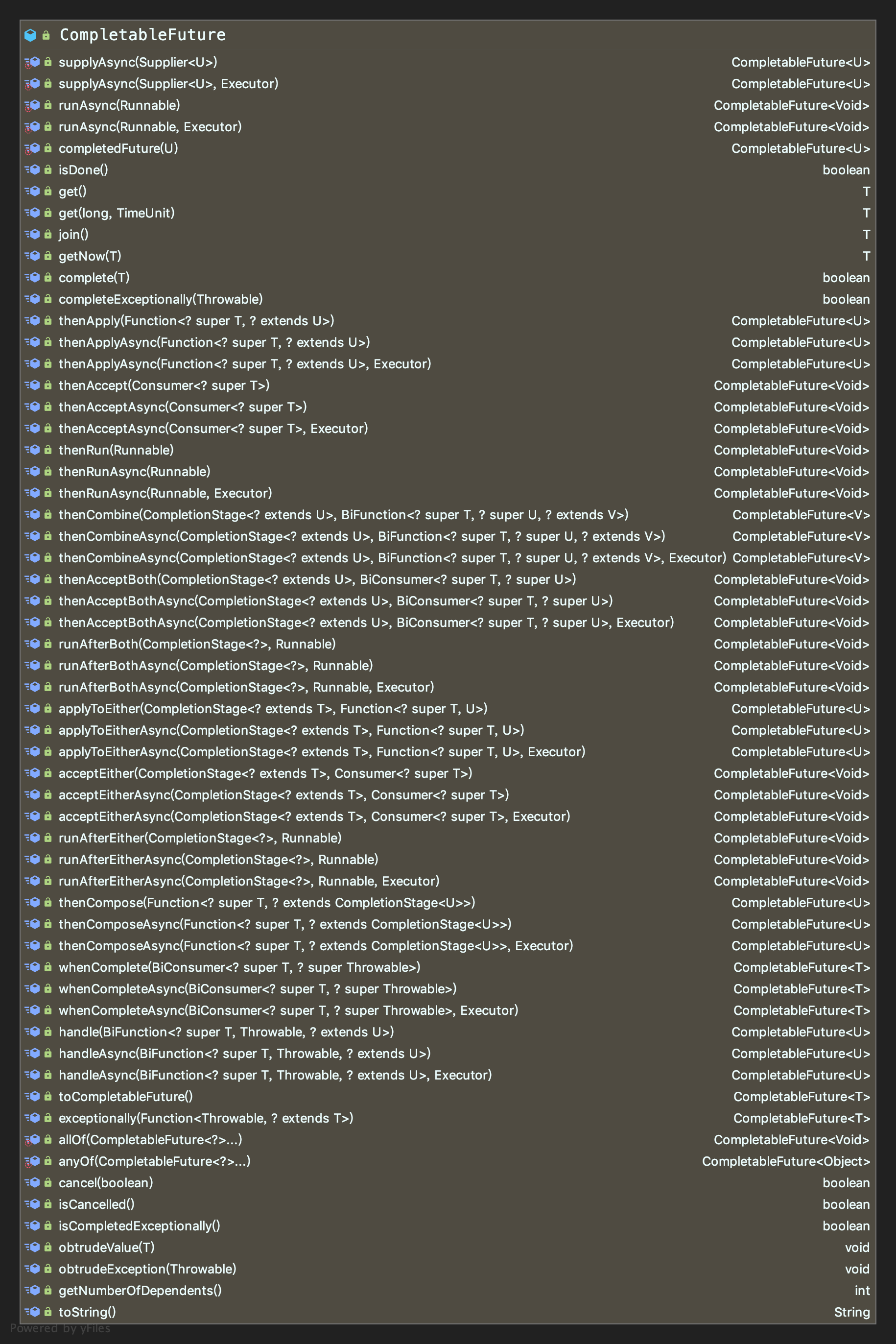
单机批处理多线程执行模型
该模型适用于百万级量级的任务。超过千万数据,可以考虑分组,多机器并行执行。
基本流程:
- 从数据库获取Id列表
- 拆分成n个子Id列表
- 通过子Id列表获取关联数据(注意:都需要提供批量查询接口)
- 映射到需要处理的Model(提交到CompletableFuture)->处理数据->收集成list)(java 8流式处理)
- 收集的list进行join操作
- 收集list
模型
模型原理:Stream+CompletableFuture+lambda
简要解释:
- CompletableFuture是java8提供的一个工具类,主要是用于异步处理流程编排的。
- Stream是java8提供的一个集合流式处理工具类,主要用于数据的流水线处理。
- lambda在java中是基于内部匿名类实现的,可以大幅减少重复代码。
- 总结:在该模型中Stream用于集合流水线处理、CompletableFuture解决异步编排问题(非阻塞)、lambda简化代码。
- 数据流动
List<List<String>> ->
Stream<List<String>> ->
Stream<List<Model>> ->
Stream<CompletableFuture<List<Model>>> ->
Stream<CompletableFuture<List<映射类型>>> ->
List<CompletableFuture<Void>>
案例
ThreadPoolUtil
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
public final class ThreadPoolUtil {
public static ThreadPoolTaskExecutor getDefaultExecutor(Integer poolSize, Integer maxPoolSize, Integer queueCapacity) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setAllowCoreThreadTimeOut(true);
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setCorePoolSize(poolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
ThreadPoolConfig
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
@Configuration
public class ThreadPoolConfig {
/**
* 计算规则:N(thread) = N(cpu) * U(cpu) * (1 + w/c)
* N(thread):线程池大小
* N(cpu):处理器核数
* U(cpu):期望CPU利用率(该值应该介于0和1之间)
* w/c:是等待时间与计算时间的比率,比如说IO操作即为等待时间,计算处理即为计算时间
*/
private static final Integer TASK_POOL_SIZE = 50;
private static final Integer TASK_MAX_POOL_SIZE = 100;
private static final Integer TASK_QUEUE_CAPACITY = 1000;
@Bean("taskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
return ThreadPoolUtil.getDefaultExecutor(TASK_POOL_SIZE, TASK_MAX_POOL_SIZE, TASK_QUEUE_CAPACITY);
}
}
#getFuturesStream
public Stream<CompletableFuture<List<Model>>> getFuturesStream(List<List<String>> idSubLists) {
return idSubLists.stream()
.map(ids ->
CompletableFuture.supplyAsync(() -> modelService.listByIds(ids), taskExecutor)
);
}
#standardisation
public void standardisation() {
List<CompletableFuture<Void>> batchFutures = getFuturesStream(idSubLists)
.map(future -> future.thenApply(this::listByNormalize))
.map(future -> future.thenAccept(modelService::batchUpdateData))
.collect(Collectors.toList());
List<Void> results = batchFutures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
调整线程池的大小
《Java并发编程实战》一书中,Brian Goetz和合著者们为线程池大小的优化提供了不少中肯的建议。这非常重要,如果线程池中线程的数量过多,最终它们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。反之,如果线程的数目过少,正如你的应用所面临的情况,处理器的一些核可能就无法充分利用。Brian Goetz建议,线程池大小与处理器的利用率之比可以使用下面的公式进行估算:
$$N_{threads} = N_{CPU} * U_{CPU} * (1 + \frac{W}{C})$$其中:
- $N_{CPU}$是处理器的核的数目,可以通过
Runtime.getRuntime().availableProcessors()得到- $U_{CPU}$是期望的CPU利用率(该值应该介于0和1之间)
- $\frac{W}{C}$是等待时间与计算时间的比率,比如说IO操作即为等待时间,计算处理即为计算时间
并行——使用流还是CompletableFutures?
对集合进行并行计算有两种方式:要么将其转化为并行流,利用map这样的操作开展工作,要么枚举出集合中的每一个元素,创建新的线程,在CompletableFuture内对其进行操作。后者提供了更多的灵活性,可以调整线程池的大小,而这能帮助确保整体的计算不会因为线程都在等待I/O而发生阻塞。
使用这些API的建议如下:
- 如果进行的是计算密集型的操作,并且没有I/O,那么推荐使用Stream接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
- 反之,如果并行的工作单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture灵活性更好,可以依据等待/计算,或者$\frac{W}{C}$的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生I/O等待,流的延迟特性很难判断到底什么时候触发了等待。
日期和时间API
使用指南:https://www.yuque.com/docs/share/ee5ef8a7-d261-4593-bd08-2a7a7d2c11ca?#(密码:gtag) 《时区工具类使用指南》
项目地址
GitHub:java8-fluent
参考
分享并记录所学所见
怎样用Java 8优雅的开发业务的更多相关文章
- 我们一起来排序——使用Java语言优雅地实现常用排序算法
破阵子·春景 燕子来时新社,梨花落后清明. 池上碧苔三四点,叶底黄鹂一两声.日长飞絮轻. 巧笑同桌伙伴,上学径里逢迎. 疑怪昨宵春梦好,元是今朝Offer拿.笑从双脸生. 排序算法--最基础的算法,互 ...
- 你的Kubernetes Java应用优雅停机了吗?
Java 应用优雅停机 我们首先考虑下,一般在什么场景下数据会丢失呢? 升级服务时 pod重启时 服务器断电时 因为服务器断电属于极端情况,我们暂且不考虑.那就只有 Java 退出时我们要保证数据的完 ...
- 哦,这就是java的优雅停机?(实现及原理)
优雅停机? 这个名词我是服的,如果抛开专业不谈,多好的名词啊! 其实优雅停机,就是在要关闭服务之前,不是立马全部关停,而是做好一些善后操作,比如:关闭线程.释放连接资源等. 再比如,就是不会让调用方的 ...
- java如何优雅的实现时间控制
前言:最近小王同学又遇到了一个需求:线上的业务运行了一段时间,后来随着使用人数增多,出现了一个问题是这样的,一个订单会重复创建几次,导致数据库里出现了很多垃圾数据.在测试同学的不断测试下,发现问题出在 ...
- 编码规范 | Java函数优雅之道(上)
导读 随着软件项目代码的日积月累,系统维护成本变得越来越高,是所有软件团队面临的共同问题.持续地优化代码,提高代码的质量,是提升系统生命力的有效手段之一.软件系统思维有句话“Less coding, ...
- 编码规范 | Java函数优雅之道(下)
上文背景 本文总结了一套与Java函数相关的编码规则,旨在给广大Java程序员一些编码建议,有助于大家编写出更优雅.更高质.更高效的代码. 内部函数参数尽量使用基础类型 案例一:内部函数参数尽量使用基 ...
- Java函数优雅之道
https://www.cnblogs.com/amap_tech/p/11320171.html 导读 随着软件项目代码的日积月累,系统维护成本变得越来越高,是所有软件团队面临的共同问题.持续地优化 ...
- Java 函数优雅之道
导读 随着软件项目代码的日积月累,系统维护成本变得越来越高,是所有软件团队面临的共同问题.持续地优化代码,提高代码的质量,是提升系统生命力的有效手段之一.软件系统思维有句话“Less coding, ...
- Java如何优雅地使用close()?
注:本文出自博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 本文源链接:https://www.cnblogs.com/chloneda/p/java-clo ...
随机推荐
- MindManager 2021 版新增了哪些功能
MindManager Windows 21是一款强大的可视化工具和思维导图软件,在工作应用中有出色的表现.今天就带大家来看下这个新版本增加了哪些功能? 1.新增现代主题信息样式MindManager ...
- guitar pro系列教程(九):Guitar Pro音谱“编辑”讲解
对广大音乐人来说,guitar pro不只是一款看谱软件,更是制谱辅助创作的好搭档 打开guitar pro创作软件的 主界面,你会看到"编辑"的字样,单击一下,会弹出下面的界面, ...
- UIWebView各种加载网页的方式
UIWebView加载网页的方法 最近在使用UIWebView的时候遇到各种不同形式加载网页的方式,总结起来共有三种方式,分别为:使用URL加载,使用HTML源码加载,使用HTML文件加载,各种方法的 ...
- Linun中配置redis密码
这里以linux服务器为例,为redis配置密码. 1.第一种方式 (当前这种linux配置redis密码的方法是一种临时的,如果redis重启之后密码就会失效,) (1)首先进入redis,如果没有 ...
- 牛客练习赛69 火柴排队 题解(dp)
题目链接 题目大意 给你一个长为n(n<=5e3)的数组a.随机使得k个元素增加d.要你求多大的概率使得,这些数组元素的相对大小不发生改变 输出 n 行每行一个整数,第 i 行的整数表示 k=i ...
- 如何让文科生5分钟写上Python
序言 这篇文章是转型后发表的第一篇文章,有必要先聊一下我的写文计划. 串行文章和并行文章 我会按照发文顺序分为串行文章和并行文章.Python 语言本身的内容,我会按照入门.进阶.原理的顺序依次展开. ...
- Arduion学习(一)点亮三色发光二极管
这是我接触Arduion以来第一个小实验 实验准备: 1.查阅相关资料,了解本次实验所用到的引脚.接口的相关知识. 2.准备Arduion板(本次实验所用到的型号为mega2560).三色发光二极管. ...
- dubbo协议之响应头编码器&响应对象编码
前2节分析完了请求头和请求对象的编码,这里看一下响应头和响应对象的编码: 和请求头部一样进来先指定序列化器,没有的话用默认的Hessian2,接下来2个字节的操作和请求头编码类似,第三个字节时去req ...
- Windows生产力工具推荐
相信大部分同学还是Windows用户,作为一个长期Windows/MacOS双系统长期用户,Windows在用的好,工作效率也很高,下面就推荐几款Windows下面的生产力工具. utools 用过M ...
- 【论文解读】【半监督学习】【Google教你水论文】A Simple Semi-Supervised Learning Framework for Object Detection
题记:最近在做LLL(Life Long Learning),接触到了SSL(Semi-Supervised Learning)正好读到了谷歌今年的论文,也是比较有点开创性的,浅显易懂,对比实验丰富, ...