后台开发:核心技术与应用实践 -- C++
本书介绍的“后台开发”指的是“服务端的网络程序开发”,从功能上可以具体描述为:服务器收到客户端发来的请求数据,解析请求数据后处理,最后返回结果。
C++编程常用技术
include 一个 .h 文件,就是等于把整个 .h 文件给复制到程序中,include 一个 cpp 文件也是如此。使用include的方式有两种:1. #include<> 2. #include""
#include<>与#include""的区别是:#include<>常用来包含系统提供的头文件,编译器会到保存系统标准头文件的位置查找头文件;而#include""常用于包括程序员自己编号的头文件,用这种格式时,编译器先查找当前目录是否有指定名称的头文件,然后从标准头目录中
进行查找。
包含C语言的头文件是,常引用的是.h文件,而C+++标准为了语言区别开,也为了正确使用命名空间,规定头文件不再使用后缀 .h。
C++允许用同函数名定义多个函数,但这些函数必须参数个数不同或类型不同,这就是函数重载。
函数模板,实际上是建立一个通用函数,其函数类型和形参不具体指定,而用一个虚拟的类型来代表,这个通用函数就是函数模板。凡是函数体相同的函数都可以用这个模板来代替,而不用定义多个函数,实际使用时只需在模板中定义一次就可以了。在调用函数时,系统会根据实参的类型来取代模板中的虚拟类型,从而实现不同函数的功能。
定义函数模板的一般格式是:
template<typename T>
T min(T a,T b,T c){
if(a>b)a=b ;
if(a>c)a=c ;
return a;
}
通常用 strlen() 函数来计算一个字符串的长度,strlen() 函数比较容易混淆的是 sizeof() 函数。
strlen和sizeof的区别如下所述:
- strlen()是函数,在运行时才能计算,参数必须是字符型指针(char *),且必须是以
\0结尾的。当数组名作为参数传入时,实际上数组已经退化为指针了,它的功能是返回字符串的长度。 - sizeof()是运算符,而不是一个函数,在编译时就计算好了,用于计算数据空间的字节数。因此,sizeof 不能用来返回动态分配的内存空间的大小 sizeof 常用于返回类型和静态分配的对象、结构或数组所占的空间,返回值跟对象、结构、数组所存储的内容没有关系。
当参数分别如下时 sizeof 返回的值表示的含义如下所述:
- 数组一一编译时分配的数组空间大小
- 指针一一存储该指针所用的空间大小(int类型大小,32位机器为4 Byte)
- 类型一一该类型所占的空间大小
- 对象一一对象实际占用空间大小
- 函数一一函数的返回类型所占的空间大小,且函数的返回类型不能是 void
C++编译系统在 32 位机器上为整型变量分配4Byte,为单精度浮点型变量分配 4Byte ,为字符型变量分配 1Byte。
数组指针与指针数组
数组指针也称为行指针:假设有定义 int (*p)[n];且()优先级高,首先说明p是一个指针,且指向一个整型的一维数组。这个一维数组的长度是n,也可以说是p的步长,也就是说执行 p+l 时,p要跨过n个整型数据的长度。
int a[3][4];
int (*p)[4];
p=a ;
p++ ;
指针数组不同于数组指针,假设有定义 int *p[n];且[]优先级高,可以理解为先与p结合成为一个数组,再由 int*说明这是一个整型指针数组。它有n个指针类型的数组元素。
int *p[3];
优先级 () > [] > *
函数指针是指向函数的指针变量 所以,函数指针首先是个指针变量,而且这个变量指向一个函数。
函数指针的声明方法:
// 返回值类型 (*指针变量名) ([形参列表]);
int func(int a);
int (*f) (int a);
f=&func;
int b;
(*f) (b); // 函数调用
在声明一个引用变量时,必须同时使之初始化,即声明它代表哪个变量,函数执行期间,不可以将其再作为其他变量的引用。
使用引用传递函数的参数时,在内存中并没有产生实参的副本,而是对实参直接操作。当使用一般变盘传递函数的参数时,当函数发生调用,需要给形参分配存储单元,形参变量是实参变量的副本;如果传递的是对象,还将调用拷贝构造函数。因此,当参数传递的数据较大时,用引用比用 一般变量传递参数的效率更高,所占空间更少。
结构体的声明方法如下所示:
struct 结构名{
数据类型 成员名;
数据类型 成员名;
...
}
共用体,用关键字 union 来定义,它是一种特殊的类,一个共用体里可以定义多种不同的数据类型,这些数据共享一段内存,在不同的时间里保存不同的数据类型和长度的变量,以达到节省空间的目的,但同一时间只能储存其中一个成员变量的值。
共用体的声明方式为:
union 共用体类型名{
数据类型 成员名;
数据类型 成员名;
...
}变量名;
可以使用 union 判断系统是 big endian (大端)还 little endian 小端。
#include<iostream>
using namespace std;
union TEST{
short a ;
char b[sizeof(short)] ;
}
int main(){
TEST test;
test.a=Ox0102; // 不能引用共用体变量 只能引用共用体变量中的成员
if(test.b[0] == 0x01 && test.b[1] == 0x02)
cout << " big endian. " << endl;
else if(test.b[0] == 0x02 && test.b[1] == 0x01)
cout << " small endian." << endl;
else cout << "unkonw" << endl;
}
其中, big endian 是指低地址存放最高有效字节, little endian 是低地址存放最低有效字节。
枚举类型是一种基本数据类型,而不是构造类型,因为它不能再分解为任何其他基本类型。
枚举的声明方式为:
enum 枚举类型名{枚举常量表列};
如同结构和共用体一样,枚举变量也可用不同的方式说明,即先定义后说明,同时定义说明或直接说明
设有变 a,b,c 是枚举类型 weekday,可采用下述任一种方式:
// 1.
enum weekday{ sun , mou , tue , wed , thu , fri , sat };
enum weekday a,b,c;
// end
// 2.
enum weekday{ sun ,mou , tue , wed , thu , fri , sat }a,b,c;
// end
// 3.
enum { sun, mou , tue , wed , thu, fri, sat}a,b,c;
// end
枚举值是常量,不是变量。 不能在程序中用赋值语句再对它赋值。
只能把枚举值赋予枚举变量,不能把元素的数值直接赋予枚举变量
a = sum; // correct
b = mon; // correct
a = 0; // error
b = 1; // error
如果一定要把数值赋予枚举变量,则必须用强制类型转换
a=(enum weekday)2;
a=tue; // 以上二者等价
一般64位机器上各个数据类型所占的存储空间(byte):
| Type | char | short | int | long | float | double | long long |
|---|---|---|---|---|---|---|---|
| Size | 1 | 2 | 4 | 8 | 4 | 8 | 8 |
其中,long 类型在 32 位机器上只占 4Byte ,其他类型在 32 位机器和 64 位机器都是占同样的大小。
union的字节数计算
union 变量共用内存应以最长的为准,同时共用体内变量的默认内存对齐方式以最长的类型对齐。
union A{
int a[5];
double b;
char c;
}
该结构体占用内存为24Byte,因为要以double对齐,double占8byte,4*5=20,对齐之后变为24byte。同样a[5] 改为a[6]依旧占用24byte,但是改为a[7]将占用32byte。
struct的字节数计算
struct B{
char a;
double b;
int c;
};
这是因为 char 的偏移量为0,占用 lByte; double 指的是下一个可用的地址的偏移量为1,不是 sizeof(double )=8的倍数,需要补足 7Byte 才能使偏移量变为8; int 指的是下一个可用的地址的偏移量为 16,是 sizeof(int)=4 的倍数,满足 int 的对齐方式。
故所有成员变量都分配了空间,空间总的大小为 1+7+8+4=20 ,不是结构的节边界数(即结构中占用最大空间的基本类型所占用的字节数 sizeof (double )=8 )的倍数,所以需要填充 4Byte ,以满足结构的大小为 s.izeof( double )=8 的倍数,即 24。
C++提供的预处理功能主要有以下四种:宏定义、文件包含、条件编译和布局控制。
宏定义
#define命令是一个宏定义命令,它用来将一个标识符定义为一个字符串,该标识符被称为宏名,被定义的字符串称为替换文本。该命令有两种格式:一种是简单的宏定义,另一种是带参数的宏定义。
简单的宏定义的声明格式如下所示:#define 宏名 字符串
eg: #define pi 3.14
带参数的宏定义的声明格式如下所示:
#define 宏(参数表列)宏
eg: #define A(x) x*x
#define area(x) x*x
int main (){
int y = area(2+2) ;
cout << y << endl ;
return 0;
}
// output: 8
条件编译
一般情况下,源程序中所有行的语句都参加编译,但是有时程序员希望其中一部分内容只在满足一定条件时才进行编译,也就是对 部分内容指定编译的条件,这就用到了“条件编译”。
条件编译命令最常见的形式为:#ifdef 标识符
程序段
#else
程序段
#endif
// 另一种形式
#if 表达式
程序段
#else
程序段
#endif
面向对象的C++
对象是类类型的一个变量,类则是对象的模板,类是抽象的,不占用存储空间的;而对象是具体的,占用存储空间。
struct和class相似,但是还有一些不同。struct 中的成员访问权限默认是 public,而 class 中则是 private。在C语言中, struct 中不能定义成员函数,而在 C++ 中,增加 class 类型后 ,扩展了 struct 的功能,struct 中也能定义成员函数了。
类中的成员和成员函数具有三种访问权限:private,protected, public,默认为private。private成员只限于类成员访问,protected成员:允许类成员和派生类成员访问,不允许类外的任何成员访问,public成员:允许类成员和类外的任何成员访问。
成员函数可以在类体中定义,也可以在类外定义。
在类外定义样例:
返回类型 类名::函数名(参数列表){
函数体
}
类的静态数据成员来拥有一块单独的存储区,而不管创建了多少个该类的对象,所有这些对象的静态数据成员都共享一块静态存储空间,这就为这些对象提供了一种互相通信的方法。静态数据成员是属于类的,它只在类的范围内有效。因为不管产生了多少对象,类的静态数据成员都有着单一的存储空间,所以存储空间必须定义在一个单一的地方。如果一个静态数据成员被声明而没有被定义,链接器会报告一个错误:“定义必须出现在类的外部而且只能定义一次”。
与数据成员类似,成员函数也可以定义为静态的,在类中声明函数的前面加 static 关键字就成了静态成员函数,如:
class Box{
public:
static int volume();
}
如果要在类外调用公用的静态成员函数,要用类名和域运算符“: ”,如:
Box::volume();
实际上也允许通过对象名调用静态成员函数,如:
a.volume( );
但这并不意味着此函数是属于对象a的,而只是用a的类型而巳。
与静态数据成员不同,静态成员函数的作用不是为了对象之间的沟通,而是为了能处理静态数据成员。
而静态成员函数并不属于某一对象,它与任何对象都无关,因此静态成员函数没有 this 指针。
静态成员函数与非静态成员函数的根本区别是:非静态成员函数有 this 指针,而静态成员函数没有 this 指针,由此决定了静态成员函数不能访问本类中的非静态成员,在 C++ 程序中,静态成员函数主要用来访问静态数据成员,而不访问非静态成员。
对象的存储空间
对于一个空类,里面既没有数据成员,也没有成员函数,该类对象的大小为1Byte。
类的静态数据成员不占对象的内存空间,同时,成员函数包括构造函数和析构函数也是不占空间的。而对于有虚函数的类来说,每个对象都会保存一个指向虚函数表的指针,该指针在64位的机器上占8Byte。
在每一个成员函数中都包含一个特殊的指针,这个指针的名字是固定的,称为 this指针,它是指向本类对象的指针,它的值是当前被调用的成员函数所在的对象的起始地址。
在一般情况下,调用析构函数的次序正好与调用构造函数的次序相反:最先被调用的构造函数,其对应的(同一对象中的)析构函数最后被调用;而最后被调用的构造函数,其对应的析构函数最先被调用。
继承与派生
声明派生类的一般形式为:
class 派生类名 [继承方式] 基类名{
派生类新增加的成员
};
其中的继承方式包括 public (公用的)、 private (私有的)和 protected (受保护的),此项是可选的,如果不写此项,则默认为 private (私有的)。
基类成员在派生类中的访问属性:
- 公用继承(public inheritance):基类的公用成员和保护成员在派生类中保持原有访问属性,其私有成员仍为基类私有
- 私有继承(private inheritance):基类的公用成员和保护成员在派生类中成了私有成员,其私有成员仍为基类私有
- 受保护的继承(protected inheritance):基类的公用成员和保护成员在派生类中成了保护成员,其私有成员仍为基类私有。受保护成员的意思是,不能被外界引用但可以被派生类的成员引用。
综上,可以视为基类访问权限与派生类继承方式的叠加最小访问权限。同时,无论哪一种继承方式,在派生类中是不能访问基类的私有
成员的,私有成员只能被本类的成员函数所访问,毕竟派生类与基类不是同一个类
构造派生类的对象时,必须对基类数据成员、新增数据成员和成员对象的数据成员进行初始化。派生类的构造函数必须要以合适的初值作为参数,隐含调用基类和新增对象成员的构造函数,来初始化它们各自的数据成员,然后再加入新的语句对新增普通数据成员进行初始化。
派生类构造函数必须对这3类成员进行初始化,其执行顺序是这样的:
- 先调用基类构造函数;
- 再调用子对象的构造函数;
- 最后调用派生类的构造函数体
当派生类有多个基类时,处于同一层次的各个基类的构造函数的调用顺序取决于定义派生类时声明的顺序(自左向右),而与在派生类构造函数的成员初始化列表中给出的顺序无关。
在派生时,派生类是不能继承基类的析构函数的,也需要通过派生类的析构函数去调用基类的析构函数。在派生类中可以根据需要定义自己的析构函数,用来对派生类中所增加的成员进行清理工作;基类的清理工作仍然由基类的析构函数负责。在执行派生类的析构函数时,系统会自动调用基类的析构函数和子对象的析构函数,对基类和子对象进行清理。
类的多态
在 C++ 程序设计中,多态性是指具有不同功能的函数可以用同一个函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中,一般是这样表述多态性的:向不同的对象发送同一个消息,不同的对象在接收时会产生不同的行为(即方法);也就是说,每个对象可以用自己的方式去响应共同的消息所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
两个同名函数不在同一个类中,而是分别在:基类和派生类中,属于同名覆盖。若是重载函数,二者的参数个数和参数类型必须至少有一者不同,否则系统无法确定调用哪一个函数。而 虚函数 的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类中的同名函数。
虚函数的声明方式:
virtual 返回类型 函数名();
当把基类某个成员函数声明为虚函数后,就允许在其派生类中对该函数重新定义,赋予它新的功能,且可以通过指向基类的指针指向同一类族中不同类的对象,从而调用其中的同名函数。虚函数实现了同一类族中不同类的对象可以对同一函数调用作出不同的响应的动态多态性。
C++中规定,当某个成员函数被声明为虚函数后,其派生类中的同名函数都自动成为虚函数。
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加=,如下所示:
virtual void funtion()=0;
含有纯虚函数的类称为抽象类,它不能生成对象。
在C++中,,构造函数不能声明为虚函数,这是因为编译器在构造对象时,必须知道确切类型,才能正确地生成对象;其次,在构造函数执行之前,对像并不存在,无法使用指向此对像的指针来调用构造函数。然而,析构函数可以声明为虚函数。C++明确指出,当derived class 对象经由 base class 指针被删除 而该 base class 带着一个non-virtual 析构函数, 导致对象的 derived 成分没被销毁掉,析构函数不是虚函数容易引发内存泄漏。
单例模式 通过类本身来管理其唯一实例,唯一的实例是类的一个普通对象,但设计这个类时,让它只能创建一个实例并提供对此实例的全局访问。使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法来获取该实例。单例模式的作用就是保证在整个应用程序的生命周期中的任何时刻,单例类的实例都只存在一个(当然也可以不存在)。
常用 STL 的使用
对于vector容器来说,可以使用reserve(*)来对容器进行扩容,避免多次自动扩容带来的性能损失,可以使用技巧vector<int>(ivec).swap(ivec)来将容器容量紧缩到合适的大小。其中vector<int> (ivec)表示使用ivec来创建一个临时vector,然后将现有的容器与临时容器进行交换,之后临时容器将会被销毁,因为临时容器的容量是自动设置的合适大小,因此,容量紧缩成功。需要注意的是vector 是按照容器现在容量的一倍进行增长
map 内部自建一棵红黑树(一种非严格意义上的平衡二叉树),这棵树具有对数据自动排序的功能,所以在 map 内部所有的数据都是有序的。
让 map 中的元素按照 key 从大到小排序
map<string, int, greater<string>> mapStudent;
红黑树,一种二叉查找树,但在每个结点上增加一个存储位表示结点的颜色,可以是 Red或Black。通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出两倍,因而是接近平衡。
二叉查找树,也称有序二叉树 (ordered binary tree),或已排序二叉树 (sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值
- 任意节点的左、右子树也分别为二叉查找树
- 没有键值相等的节点
红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找 插入、删除的时间复杂度最坏为 \(O(log n)\)
红黑树的5个性质:
- 每个结点要么是红的要么是黑的
- 根结点是黑的
- 每个叶结点都是黑的(叶子是NIL结点)
- 如果一个结点是红的,那么它的两个儿子都是黑的;
- 对于任意结点而言,其到叶结点树尾端 NIL 指针的每条路径都包含相同数目的黑结点
红黑树示例:
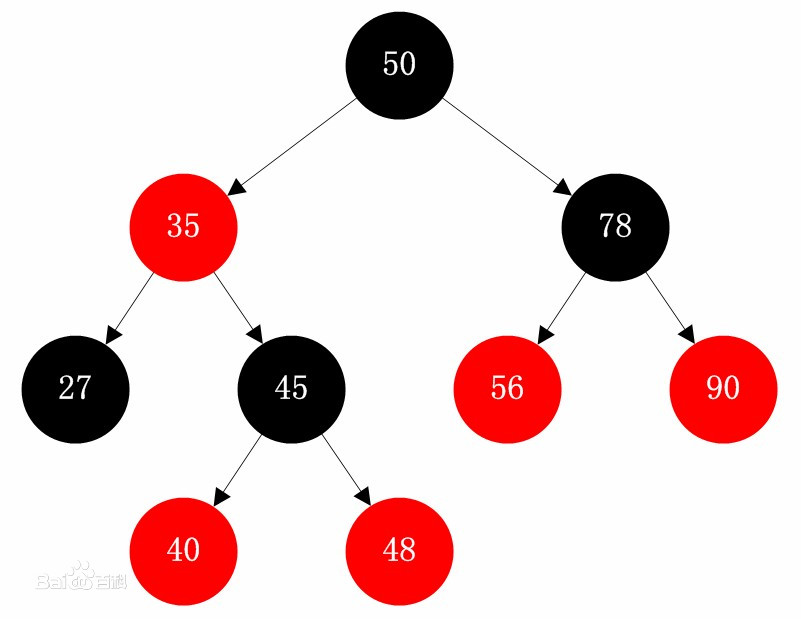
当在对红黑树进行插入和删除等操作时,对树做了修改可能会破坏红黑树的性质,为了继续保持红黑树的性质,可以通过对结点进行重新着色,以及对树进行相关的旋转操作,即通过修改树中某些结点的颜色及指针结构,来达到对红黑树进行插入或删除结点等操作后继续保持它的性质或平衡的目的。
树的旋转分为左旋和右旋,一下给出示例
左旋: (只影响旋转结点和其右子树的结构,把右子树的结点往左子树挪了)

右旋:(只影响旋转结点和其左子树的结构,把左子树的结点往右子树挪了)
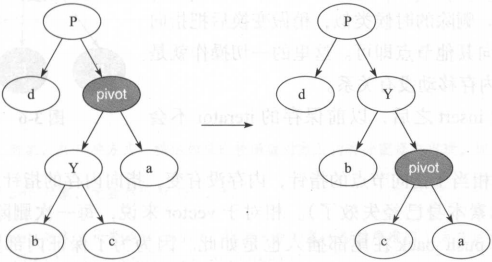
树在经过左旋右旋之后,树的搜索性质保持不变,但树的红黑性质被破坏了,所以红黑树插入和删除数据后,需要利用旋转与颜色重涂来重新恢复树的红黑性质。
set 作为一个关联式容器,是用来存储同一数据类型的数据类型。在 set 中每个元素的值都唯一的,而且系统能根据元素的值自动进行排序。应该注意的是 set 中元素的值不能直接被改变。C++ STL 中标准关联容器 set、mutiset、map、multimap 内部采用的都是红黑树。红黑树的统计性能要好于一般平衡二叉树,所以被 STL 选择作为了关联容器的内部结构。
后台开发:核心技术与应用实践 -- C++的更多相关文章
- 后台开发-核心技术与应用实践--TCP协议
网络模型 为使不同计算机厂家的计算机能够互相通信,国际标准化组织 ISO 1981 年正式推荐了一个网络系统结构一一七层参考模型,也叫作开放系统互连模型. ISO 七层网络模型及其功能展示: 这个七层 ...
- linux后台开发核心技术
3. 常用STL的使用 3.1. string (1)string类的实现(使用strlen.strcpy.strcat.strcmp等,注意判NULL). (2)C++字符串和C字符串的转换:dat ...
- c++后台开发 准备材料
后台开发知识点 面面俱到很难,一个领域钻研的很深也很难.我认识的大神里有把C++语言吃的非常透的,也有实验室就是搞分布式的,拿offer都非常轻松. 博客(C++后台/基础架构) http://www ...
- PHP核心技术与最佳实践——全局浏览
难得买到并喜欢一本好书,‘PHP核心技术与最佳实践’. 几天时间,先看了个大概,总结一下整体是什么样子的,怎么看怎么学. 1.总共14章: 2.第1.2章讲PHP的OOP: 其中第一章侧重于PHP的O ...
- SpringBoot技术栈搭建个人博客【后台开发】
前言:在之前,我们已经完成了项目的基本准备,那么就可以开始后台开发了,突然又想到一个问题,就是准备的时候只是设计了前台的RESTful APIs,但是后台管理我们同样也是需要API的,那么就在这一篇里 ...
- 温习《PHP 核心技术与最佳实践》这本书
再次看这本书,顺手提炼了一下大致目录,以便后续看见目录就知道大概讲的些什么内容 PHP 核心技术与最佳实践 1.面向对象思想的核心概念 1.1 面向对象的『形』与『本』 1.2 魔术方法的应用 1.2 ...
- 【转】C++后台开发应该读的书
转载自http://www.cnblogs.com/balloonwj/articles/9094905.html 作者 左雪菲 根据我的经验来谈一谈,先介绍一下我的情况,坐标上海,后台开发(也带团队 ...
- 面试总结 | Linux后台开发不得不看的知识点(给进军bat的你!)
目录 一 自我介绍 二 面试情况 三 相关知识点汇总 1 c/c++相关 2 计算机网络 3 数据结构相关 4 数据库相关 5 操作系统 6 Linux基础知识及应用编程(后台必备!) 7 大数问题 ...
- 给大一的学弟学妹们培训java web的后台开发讨论班计划
蓝旭工作室5月大一讨论班课程计划 课时 讨论班性质 讨论班名称 主要内容 主讲人 第一讲 先导课 后台开发工具的使用与MySQL数据库基础 后台开发工具的基本使用方法与工程的创建,MySQL数 ...
随机推荐
- Codeforces Round #135 (Div. 2) D. Choosing Capital for Treeland
time limit per test 3 seconds memory limit per test 256 megabytes input standard input output standa ...
- hdu5305 Friends
Problem Description There are n people and m pairs of friends. For every pair of friends, they can c ...
- C# 之 dynamic
C#中的dynamic用于避免编译时类型检查,编译器在运行时获取类型. dynamic无法使用VisualStudio的intelliSense(智能感知),即调用dynamic修饰的对象的方法或字段 ...
- 被收费绘图工具 PUA 了怎么办?来看看这个老实工具吧
本文非常适合 Electron 入门选手,墙裂推荐! 本文作者:HelloGitHub-蔡文心 大家好!这里是 HelloGitHub 推出的<讲解开源项目>系列,今天给大家带来的一款基于 ...
- Seq2Seq原理详解
一.Seq2Seq简介 seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列.Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Dec ...
- windows cmd 查看远程连接端口
查看远程端口号 Cmd tasklist /svc 在输出的内容中查找svchost.exe进程下termservice服务对应的PID,在此查看的PID为:276 然后输入命令:netstat ...
- python 3.7 利用socket文件传输
参考:https://www.cnblogs.com/VseYoung/p/socket_1.html 参考 https://blog.csdn.net/a19990412/article/detai ...
- 解决关闭ssh后网页停止服务的方法,利用nohup
上一篇文章提到宝塔面板无法运行,只能用ssh运行app.py. 关闭ssh时,app.py会被杀死.因为app.py的父进程就是ssh,关掉ssh会造成进程被杀死. 解决方法参考 https://w ...
- bzoj4355 Play with sequence(吉司机线段树)题解
题意: 已知\(n\)个数字,进行以下操作: \(1.\)区间\([L,R]\) 赋值为\(x\) \(2.\)区间\([L,R]\) 赋值为\(max(a[i] + x, 0)\) \(3.\)区间 ...
- 记一次 lampiao渗透(Drupal+脏牛提权)
vulnhub|渗透测试lampiao 题记 最近在打靶机,发现了一个挺有意思的靶机,这里想跟大家分享一下. 环境准备 vulnhub最近出的一台靶机 靶机(https://www.vulnhub.c ...