Flink-1-状态化流处理概述
第1章 状态化流处理概述
参考书籍
Stream Processing with Apache Flinkhttps://www.oreilly.com/library/view/stream-processing-with/9781491974285/
《基于Apache Flink的流处理》https://book.douban.com/subject/34912177/
注:本文主要是针对《基于Apache Flink的流处理》的笔记
1-8章笔记下载地址
Apache Flink 是一个分布式流处理引擎,具有直观而富于表现力的API来实现有状态流处理应用程序。
1.1 传统数据处理架构
几十年来,数据和数据处理在企业中无处不在。多年来,数据的收集和使用一直在增长,很多公司都设计和构建了管理这些数据的基础架构。
大多数企业实现的传统架构 区分了两种类型的数据处理
- 事务型处理
- 分析型处理
1.1.1 事务型处理
公司在日常业务活动中使用各种应用程序,如企业资源规划(ERP)系统、客户关系管理(CRM)软件和基于网络的应用程序。这些系统通常设计有独立的数据处理层(应用程序本身)和数据存储层(事务数据库系统),如图1-1所示。

当应用程序需要更新或扩展时,这种应用程序设计可能会导致问题。
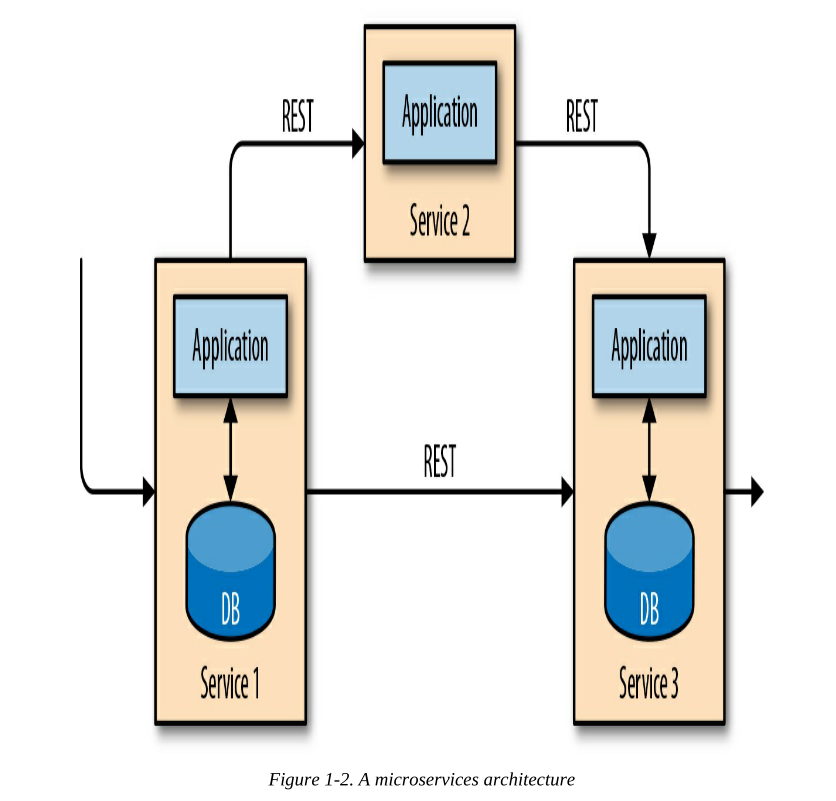
克服应用程序之间紧耦合的最新方法是微服务设计。微服务被设计成小型、独立的应用程序。他们遵循UNIX哲学:做一件事并把它做好。更复杂的应用程序是通过将几个微服务相互连接而构建的,这些微服务只通过标准接口进行通信,如RESTful HTTP连接。因为微服务彼此严格分离,并且只通过定义明确的接口进行通信,所以每个微服务都可以用不同的技术堆栈来实现,包括编程语言、库和数据存储。微服务和所有必需的软件和服务通常被打包并部署在独立的容器中。图1-2描述了一个微服务架构。
1.1.2 分析型处理
存储在公司各种交易数据库系统中的数据可以提供关于公司业务运营的有价值的见解。然而,事务性数据通常分布在几个不相连的数据库系统中,如果可以联合分析,事务性数据更有价值。
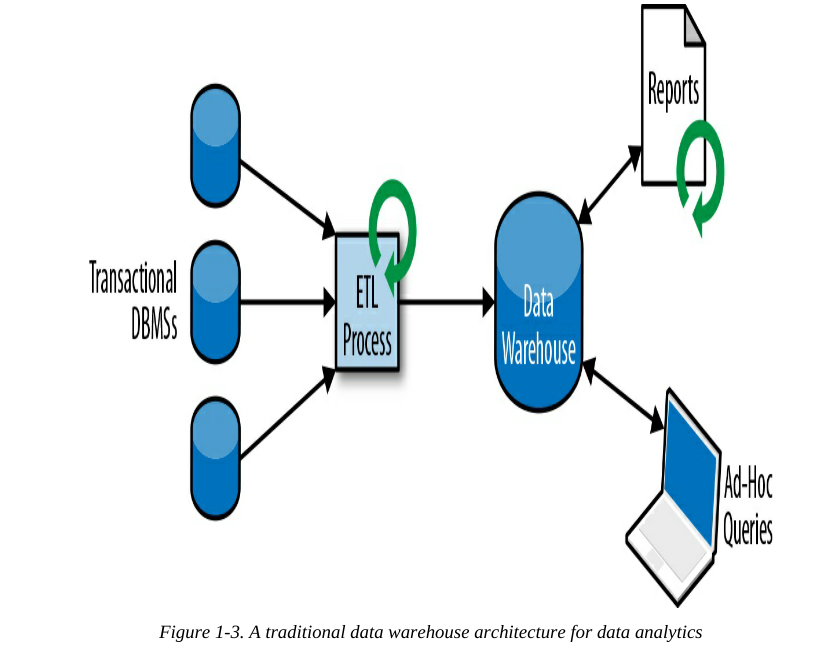
对于分析类查询,数据通常复制到数据仓库中,而不是直接在事务数据库上运行分析查询,数据仓库是用于分析查询工作的专用数据存储。为了填充数据仓库,需要将事务数据库系统管理的数据复制到数据仓库中。将数据复制到数据仓库的过程称为提取-转换-加载(extract–transform–load,ETL)。
ETL过程
- 从事务性数据库中提取数据,
- 将其转换为通用表示形式,可能包括数据验证、数据规范化、编码、去重和表模式转换,
- 最后将其加载到分析性数据库中。
ETL过程可能非常复杂,通常需要技术上复杂的解决方案来满足性能要求。ETL过程需要定期运行,以保持数据仓库中的数据同步。
一旦数据被导入数据仓库,就可以对其进行查询和分析。通常,数据仓库上查询分为两类
- 第一类是定期报告查询
- 第二种类型是即席查询(ad-hoc query)
数据仓库以批处理方式执行这两种查询,如下图1-3所示
如今,Apache Hadoop生态系统是许多企业的信息技术基础架构中不可或缺的一部分。
- 大量数据(如日志文件、社交媒体或网络点击日志)被存储在Hadoop的分布式文件系统(HDFS)、S3或其他大容量数据存储区(如Apache HBase),而不是将所有数据存储在关系型数据库系统,Apache Hbase以较小的成本提供了巨大的存储容量。
- 驻留在这种存储系统中的数据可以通过Hadoop上的SQL引擎进行查询和处理,例如Apache Hive、Apache Drill或Apache Impala。
- 这就是前文描述的传统架构的一种实践
1.2 状态化流处理
任何处理事件流并且不只是简单的只依赖一条事件的应用程序都需要是有状态的,具有存储和访问中间数据的能力。
- 当应用程序接收到事件时,它可以依赖状态来执行任意计算,包括从状态中读取数据或向状态中写入数据。
- 原则上,状态可以在许多不同的存储方案,包括程序变量、本地文件、嵌入式或外部数据库。
Apache Flink将应用程序状态存储在本地内存或本地嵌入式数据库中并且会定期向远程持久化存储来同步
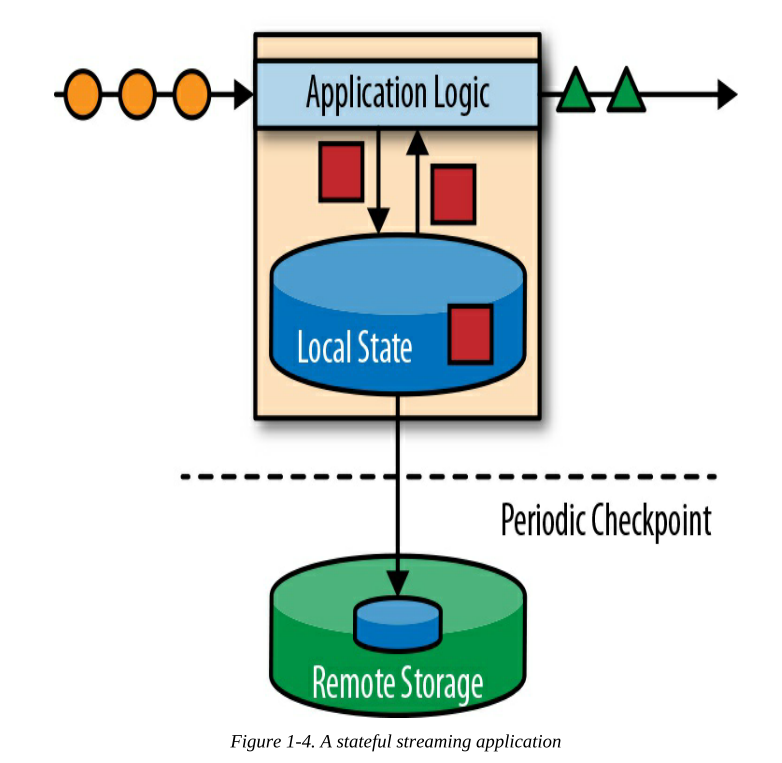
有状态流处理应用程序通常从事件日志中获取它们的输入事件。事件日志负责存储和分发事件流。事件被写入持久的、只能追加的日志,这意味着不能更改写入事件的顺序。写入事件日志的流可以被相同或不同的使用者 多次读取。由于日志的仅支持追加,事件总是以完全相同的顺序发布给所有使用者。有几个很好的开源事件日志系统,Apache Kafka是最受欢迎的。
出于多种原因,将Flink上的有状态流应用程序和事件日志系统来配合使用效果很棒。
- 在这种体系结构中,事件日志用来持久化 输入事件,并可以按确定的顺序重放它们。
- 在出现故障的情况下,Flink通过从以前的检查点恢复状态并重置事件日志上的读取位置来恢复有状态的流应用程序。
如前所述,有状态流处理是一种通用和灵活的设计架构,可以用于许多不同的用例。
在下文中,我们介绍了通常使用状态流处理实现的三类应用程序:
- 事件驱动型应用程序
- 数据管道型应用程序
- 数据分析型应用程序
1.2.1 事件驱动型应用
事件驱动型应用程序是有状态的流应用程序,它们接收事件流并使用特定于应用程序的业务逻辑来处理事件。
事件驱动型应用程序是微服务的演变和发展。它们通过事件日志而不是REST调用进行通信,并将应用程序数据保存为本地状态。图1-5显示了由事件驱动的流应用程序组成的服务架构。
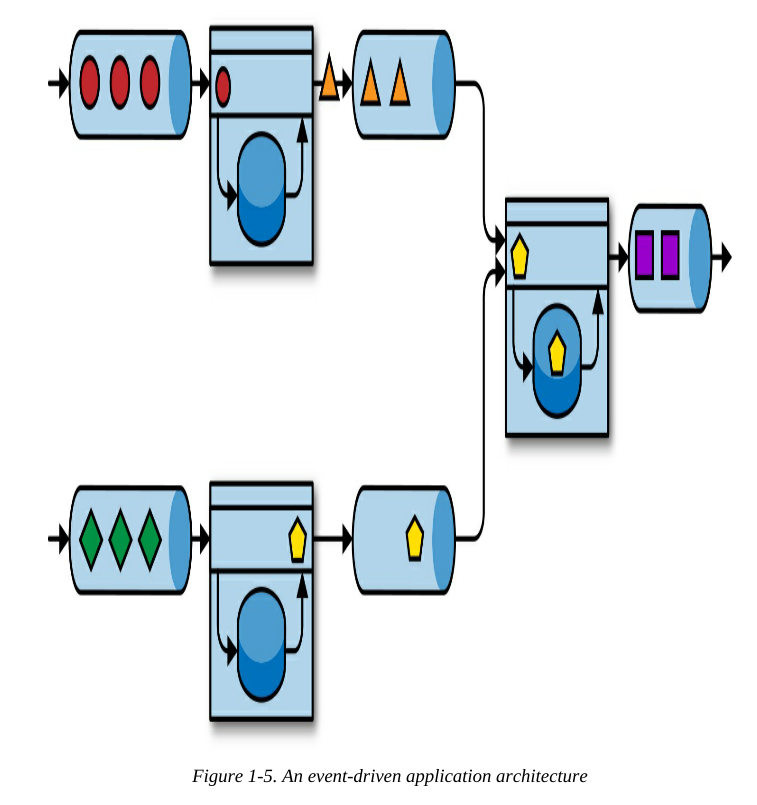
图1-5中的应用程序由事件日志相互连接。
- 一个应用程序将其输出发送到事件日志,另一个应用程序使用另一个应用程序发送的事件(从事件日志上读取)。
- 事件日志分离发送方和接收方,并提供异步、非阻塞的事件传输。
- 每个应用程序都可以是有状态的,并且可以在本地管理自己的状态。
- 应用程序也可以独立部署和扩容。
事件驱动的应用程序对运行它们的流处理引擎有很高要求。并非所有的流处理器都同样适合运行事件驱动的应用程序。应用编程接口的可表达性以及状态处理和事件时间支持的质量决定了可以实现和执行的业务逻辑。Apache Flink是运行这类应用程序的非常好的选择。
1.2.2 数据管道
当今的大公司IT架构包括许多不同种类的数据存储,如关系型数据库系统、事件日志系统、分布式文件系统、内存缓存和搜索索引。为了在各自的应用场景下提供最佳性能表现,所有这些系统都以不同的格式和数据结构存储数据。公司通常将相同的数据存储在多个不同的系统中,以提高数据访问的性能。例如,网上商城提供的商品信息可以存储在事务数据库、网络缓存和搜索索引中。由于这种数据复制,数据存储必须保持同步。
同步不同存储系统中数据的传统方法是定期ETL作业,但是延时性太高了。另一种方法是使用事件日志来分发更新。更新由事件日志写入和分发。日志的使用者(也就是基于Flink的某个应用)将更新同步到需要同步的数据存储中,我们把这类应用称为数据管道。用Flink来实现一个数据管道应用是很方便的,它可以支持对不同种类数据存储的读写,而且可以在短时间处理大量数据。
1.2.3 流式分析
流分析应用程序持续接收事件流,并通过低延迟地合并最新事件来更新结果。通常,流式应用程序将结果存储在支持高效更新的外部数据存储中,如数据库或键值存储。流式分析应用程序的实时更新结果可以在仪表板应用程序中实时地看到,如图1-6所示。
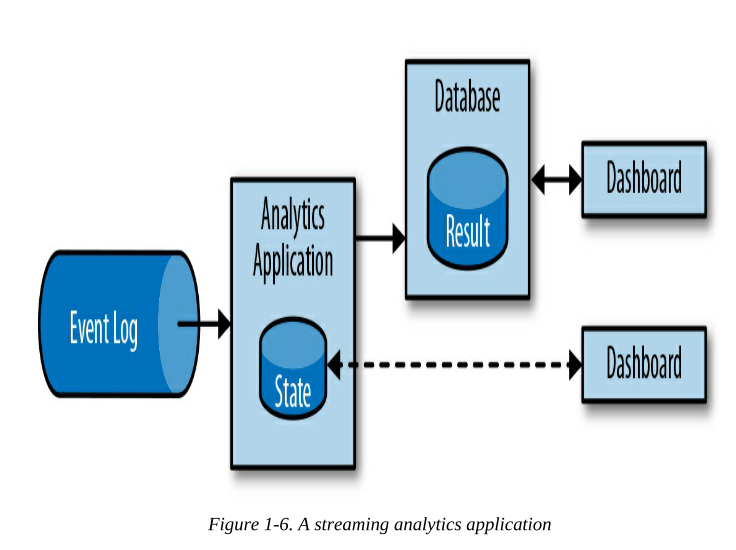
可以运行有状态流应用程序的流处理引擎 负责所有处理步骤,包括事件摄取、包括状态维护在内的连续计算以及更新结果。
值得一提的是,Flink还支持对于数据流的分析型SQL查询
1.3 开源流处理的演变
略
1.4 Flink 快览
Apache Flink是很棒的第三代分布式流处理器。它以高吞吐量和低延迟大规模提供精确的流处理。
以下特性让Flink脱颖而出:
- 同时支持事件时间和处理时间语义。
- 提供精确一次(exactly-once)的状态一致性保证。
- 每秒处理数百万个事件时的毫秒级延迟。Flink应用程序可以扩展到在数千个内核上运行。
- 分层设计的API
- 可以轻松连接到最常用的存储系统,如Kafka、Cassandra、Elasticsearch、JDBC、HDFS、S3等。
- 能够全天运行流式应用程序,宕机时间非常少
- 能够在不会丢失应用程序的状态的前提下,更新作业的应用程序代码或者将作业迁移到不同的Flink集群,。
- 提供详细的指标
- 支持批处理
- 对开发者友好。API极为易用。并且嵌入式执行模式可以将应用连同整个Flink都嵌入到单个JVM进程中,方便在IDE里运行和调试基于Flink的应用
Flink-1-状态化流处理概述的更多相关文章
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- Flink Streaming状态处理(Working with State)
参考来源: https://www.jianshu.com/p/6ed0ef5e2b74 https://blog.csdn.net/Fenggms/article/details/102855159 ...
- 基于Twitter-Snowflake的java改进版,去状态化实现
package jeffery; import java.net.InetAddress; import java.net.UnknownHostException; import java.util ...
- Flink 另外一个分布式流式和批量数据处理的开源平台
Apache Flink是一个分布式流式和批量数据处理的开源平台. Flink的核心是一个流式数据流动引擎,它为数据流上面的分布式计算提供数据分发.通讯.容错.Flink包括几个使用 Flink引擎创 ...
- Structured Streaming + Kafka Integration Guide 结构化流+Kafka集成指南 (Kafka broker version 0.10.0 or higher)
用于Kafka 0.10的结构化流集成从Kafka读取数据并将数据写入到Kafka. 1. Linking 对于使用SBT/Maven项目定义的Scala/Java应用程序,用以下工件artifact ...
- Java知多少(66)输入输出(IO)和流的概述
输入输出(I/O)是指程序与外部设备或其他计算机进行交互的操作.几乎所有的程序都具有输入与输出操作,如从键盘上读取数据,从本地或网络上的文件读取数据或写入数据等.通过输入和输出操作可以从外界接收信息, ...
- java I/O流类概述
java I/O流类概述
- Io流的概述
Io流的概述IO: I输入(Input),O 输出(Output)1.什么是IO流? 数据流,IO是严格的“水流模型” 所以IO流是用来读写数据,或者传输数据. 注意:File只能操作文件对象本身,而 ...
- Flink的状态与容错
本文主要运行到Flink以下内容 检查点机制(CheckPoint) 状态管理器(StateBackend) 状态周期(StateTtlConfig) 关系 首先要将state和checkpoint概 ...
随机推荐
- pwn之栈缓冲区溢出漏洞(入门)
题目ret2text 题目信息确认 使用file命令查看文件类型 root@CTF:/home/# file ret2text ret2text: ELF 32-bit LSB executable, ...
- Spring boot ConditionalOnClass原理解析
Spring boot如何自动加载 对于Springboot的ConditionalOnClass注解一直非常好奇,原因是我们的jar包里面可能没有对应的class,而使用ConditionalOnC ...
- Kubernetes 使用 Ingress 实现灰度发布功能
使用 Ingress 实现灰度发布 一.Canary 规则说明 Ingress-Nginx 是一个K8S ingress工具,支持配置 Ingress Annotations 来实现不同场景下的灰度发 ...
- MySQL全面瓦解4:数据定义-DDL
前言 SQL的语言分类主要包含如下几种: DDL 数据定义语言 create.drop.alter 数据定义语言 create.drop.alter 语句 . DML 数据操纵语言 insert.de ...
- 4G工业路由器的信号强度应该怎么保证呢?
在M2M无线方面,最薄弱的环节是差的间歇性的信号强度.低信号电平导致系统性能差,响应时间慢和可靠性问题.对于系统安装人员和其他4G工业路由器供应商,如何确保最佳的蜂窝信号强度? 检查2G/3G/4G信 ...
- JWT安装配置
1.1 安装JWT pip install djangorestframework-jwt==1.11.0 1.2 syl/settings.py 配置jwt载荷中的有效期设置 import date ...
- Java-GUI基础(二)java.awt
1. 组件与容器 容器就是窗口和面板,而组件为按钮.文本域.标签等(待续),二者的声明.设置很相似, 因此本文只做对于容器的详解.组件与容器的区别在于组件不能做容器,而部分容器可以兼顾组件和容器的特性 ...
- CH2101可达性问题
CH2101可达性问题 拓扑排序应用基础 题意描述 具体见书P95. 给定一个N个点,M条边的有向无环图,问每个点直接或间接可到达的点的数量. 算法分析 书中有详细介绍,这里就不再赘述了. 简而言之就 ...
- XJOI 夏令营501-511测试11 游戏
Alice和Bob两个人正在玩一个游戏,游戏有很多种任务,难度为p的任务(p是正整数),有1/(2^p)的概率完成并得到2^(p-1)分,如果完成不了,得0分.一开始每人都是0分,从Alice开始轮流 ...
- 模板——Splay
$Splay$ #include <bits/stdc++.h> #define inf (int)1e9 using namespace std; const int N=1e5+100 ...