用大白话讲大数据HBase,老刘真的很用心(1)

老刘今天复习HBase知识发现很多资料都没有把概念说清楚,有很多专业名词一笔带过没有解释。比如这个框架高性能、高可用,那什么是高性能高可用?怎么实现的高性能高可用?没说!
如果面试官听了你说的,会有什么反应?我的感觉就是你说的东西都是别人的,没有自己的理解。所以老刘才会写用大白话讲大数据这个系列,就是争取把东西讲清楚,讲明白!如果觉得老刘写得不错,给老刘点个赞吧!
01 HBase知识点
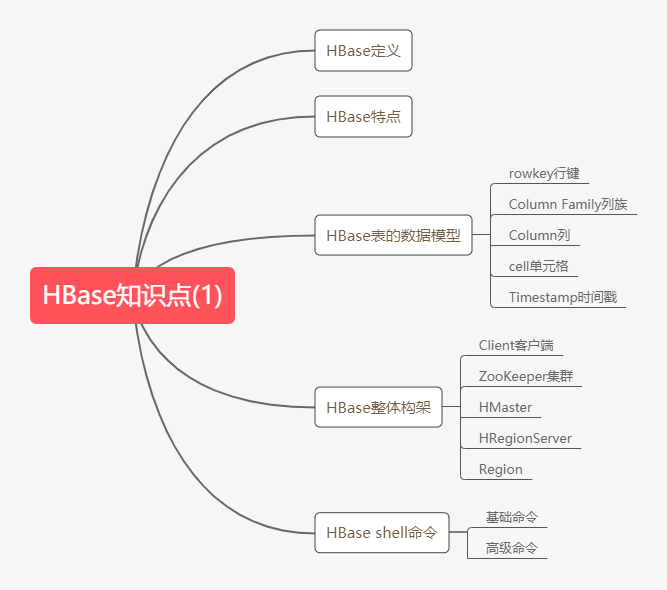
第1点:HBase的定义

官网画红框中直接就说,HBase是一个分布式、可扩展的大数据存储Hadoop数据库。试想下,你是面试官,别人这样回答你,你会不会满意?老刘觉得学的东西要用自己的话讲出来,才是真正的掌握。
在老刘看来,HBase,即Hadoop database,即Hadoop数据库。它的数据通常存储在HDFS上,HDFS为HBase提供了高可靠性的底层存储的支持;利用Hadoop MapReduce来处理HBase中的海量数据,为HBase提供了高性能的计算能力;利用ZooKeeper为HBase提供了稳定的服务。
根据上述所说,就可以总结为HBase是一个建立在HDFS之上,具有高可靠、高性能、可扩展、支持海量数据存储的分布式数据库。
一般是在存储数据比较大的时候,并且对读写性能要求比较高的时候,才会用到HBase数据库。
那你们知道什么是读写性能比较高吗?那就是读的比较快、写的也比较快的时候,才是读写性能比较高!
第2点:HBase的特点
1)极易扩展
HBase底层依赖HDFS,当磁盘空间不足的时候,我们只需要动态增加DataNode节点就可以了。当然也可以通过增加服务器来对集群的存储进行扩容。
2)海量存储
可以存储大批量的数据。在存储海量数据的前提下,能在几十到百毫秒内返回数据。这点和HBase的极易扩展性非常相关。正因为HBase良好的扩展性,才为海量数据的存储提供了便利。
3)列式存储(这里一定要搞清楚列式存储和行式存储的区别)
这里的列式存储其实说的是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须要指定了。
4)稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
5)数据类型单一
它所有的数据都是以字节数组进行存储。
第3点:HBase表的数据模型

先给出一张HBase的设计表,根据这张表进行介绍表的结构。
rowkey行键
1)它是表(table)的主键,table中的记录按照rowkey的字典序进行排序,这里就必须要说说什么是字典序?
有多机构的资料就是一笔带过,一点也不负责,让人非常不爽。老刘就不得不去搜搜字典序排序的相关知识。
通俗地讲,字典序排序大概就是两个作比较的内容从第一个字母开始比较,按照ASCII码表比较大小,小的放在前面,第一个相同就比较下一个,都相同且一个比较完了,则短的排在前面。
常见ASCII码的大小规则:0~9<A~Z<a~z
2)rowkey行键它可以是任意的字符串,其中它的最大长度是 64KB,实际应用中长度一般为 10-100bytes。
Column Family列族
1)HBase表中的每个列,都归属于某个列族。
2)列族是表的schema的一部分(而列不是),即建表时至少指定一个列族。
3)比如我们创建user表,包含info、data两个列族,代码就为create 'user', 'info', 'data'。Column列列肯定是表的某一个列族下的一个列,用列族名:列名表示,比如`info`列族下的`name`列,就表示为`info:name`。
Cell单元格

如上图,我们通过指定rowkey行键、列族、列,就可以确定的一个Cell单元格。在Cell中的数据是没有任何类型的,全部都是以字节数组的形式进行存储的。
Timestamp时间戳
这个说的就是可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号version number。也就是一个Cell可以有多个版本的值的意思。
第4点:HBase架构

从图中可以看出,这是一个非常典型的主从架构。
下面详细说下各个组件:
Client客户端
Client它是操作HBase集群的入口,利用Client,在通过RPC与HMaster进行通信,可以完成表的增、删、改操作。也可以通过RPC与RegionServer通信,完成读写表数据的操作。
一般我们可以利用HBase shell或者Java API进行编程,完成上述表的操作。
ZooKeeper集群
ZooKeeper是什么有什么用,老刘已经在ZooKeeper框架那篇文章中详细讲解了,大家可以去看看。那它在HBase集群中的作用,就非常明显了,① 它实现了HMaster的高可用,多HMaster间进行主备选举。② 保存了HBase的元数据信息meta表。③ 对HMaster和HRegionServer各个节点进行监控。
HMaster
HBase集群也是主从架构,HMaster是主角色,是集群的老大,主要负责管理表和Region。
那它管理表和Region做一些什么呢?
1)管理Client对表的增删改的一些操作;
2)管理Region的操作就会比管理Client多一点。当Region分裂后,负责新Region分配到指定的HRegionServer上;当HRegionServer宕机后,负责其上的region的迁移;以及管理HRegionServer之间的负载均衡。
那大家有没有了解负载均衡,什么是负载均衡?
举个例子,一个网站最开始建立的时候,它的访问量比较小,但当它的流量变得特别大的时候,并发量就变得特别大了,网站就会出现访问延迟的一些现象。这个时候呢,就需要用到负载均衡了。以前这个网站是一个单一服务器,现在就可以配置多个服务器集群,那样就可以把访问流量分发到集群中的不同服务器上,这样就大大减少了单一服务器上的压力,也就是负载均衡想要做的事。
HRegionServer
它是HBase集群中从角色,是集群中的小弟。它主要负责响应客户端的读写数据请求,以及负责管理一系列的Region。
Region
它是HBase集群中分布式存储的最小单元,一个Region对应一个Table表的部分数据。简单理解就是表存储在HBase中,并且都是以Region为单位进行存储。
第5点:HBase shell命令
说一些常用的基础操作命令:
创建user表,包含info、data两个列族
create 'user', 'info', 'data' 使用put命令向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
put 'user', 'rk0001', 'info:name', 'zhangsan' 获取user表中row key为rk0001的所有信息(即所有cell的数据)
get 'user', 'rk0001'
获取user表中row key为rk0001,info列族的所有信息
get 'user', 'rk0001', 'info' 更新数据操作 将user表的f1列族版本数改为5
alter 'user', NAME => 'info', VERSIONS => 5 删除数据以及删除表操作
删除user表row key为rk0001,列标示符为info:name的数据
delete 'user', 'rk0001', 'info:name' 清空表数据
truncate 'user' 删除表
首先需要先让该表为disable状态,使用命令:
disable 'user'
然后使用drop命令删除这个表
drop 'user'
注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled
再说一下HBase的高级操作命令:
显示服务器状态
status 'node01' 显示HBase当前用户
whoami 显示当前所有的表
list 统计指定表的记录数
count 'user' 检查表是否存在,适用于表量特别多的情况
exists 'user' 检查表是否启用或禁用
is_enabled 'user'
is_disabled 'user' 禁用一张表/启用一张表
disable 'user'
enable 'user' 删除一张表,记得在删除表之前必须先禁用
drop
上述都是HBase shell命令的内容,还有用JAVA API进行表操作的内容,但是这部分老刘就不讲解了,有需要的话,可以联系老刘,我会分享给你。
02 HBase总结
今天是HBase知识点的第一部分,老刘尽量用大白话讲这些知识点讲述出来了,如果还有疑问,可以联系公众号:努力的老刘。
最后希望今天讲的内容对大数据感兴趣的同学有帮助,也希望能够得到大家的批评和指点。觉得写得还行的,给老刘点个赞!
用大白话讲大数据HBase,老刘真的很用心(1)的更多相关文章
- 大白话详解大数据HBase核心知识点,老刘真的很用心(2)
前言:老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点 第6点:HRegionServer架构 为 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点(3) 第13点:HBase表的热点问题 什么是热 ...
- 大白话详解大数据hive知识点,老刘真的很用心(3)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(3) 从这篇文章开始决定进行一些改变,老刘在博客上主要分享 ...
- 大白话详解大数据hive知识点,老刘真的很用心(1)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 01 hive知识点(1) 第1点:数据仓库的概念 由于hive它是基于had ...
- 大白话详解大数据hive知识点,老刘真的很用心(2)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(2) 第12点:hive分桶表 hive知识点主要偏实践, ...
- 第五章:大数据 の HBase 进阶
本课主题 HBase 读写数据的流程 HBase 性能优化和最住实践 HBase 管理和集群操作 HBase 备份和复制 引言 前一篇 HBase 基础 (HBase 基础) 简单介绍了NoSQL是什 ...
- 第四章:大数据 の HBase 基础
本课主题 NoSQL 数据库介绍 HBase 基本操作 HBase 集群架构与设计介紹 HBase 与HDFS的关系 HBase 数据拆分和紧缩 引言 介绍什么是 NoSQL,NoSQL 和 RDBM ...
- 大数据hbase分布式安装及其部署。
大数据hbase分布式安装及其部署. 首先要启动Hadoop以及zookeeper,可以参考前面发布的文章. 将hbase的包上传至master节点 这里我使用的是1.3.6的版本,具体的根据自己的版 ...
- 大数据-HBase
HBase HBase(Hadoop Database)基于Google的BigTable论文,依赖HDFS进行存储.适合存储大体量数据.HBase是高可靠性(数据安全).高性能(存取效率).面向列. ...
随机推荐
- maven中执行package, install, deploy的区别
package命令完成了项目编译.单元测试.打包功能,但没有把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库 install命令完成了项目编译.单元测试 ...
- 项目 git 仓库允许服务器访问
我们 deployer 的运行机制是从 git 或者其它你指定的代码库 clone 代码到目标服务器,所以如果你的代码不是公开的仓库,我们通常需要添加 SSH 公钥才可以从代码库 clone 代码,所 ...
- docker compose 用法
目录 docker compose的使用场景 一个基本的demo演示 找一个目录,在其中创建一个python文件app.py 在相同的文件夹下,创建requirements.txt文件 在相同的文件夹 ...
- C#数据结构-线程安全队列
什么是线程安全? 答:线程安全是多线程编程时的计算机程序代码中的一个概念.在拥有共享数据的多条线程并行执行的程序中,线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,不会出现数据污染等意 ...
- 震惊!你还不知道SpringBoot真正的启动引导类
引言 SpringBoot项目中的启动类,一般都是XXApplication,例如「StatsApplication」,「UnionApplication」. 每个项目的启动类名称都不一样.但是它的启 ...
- 浅析I/O模型-select、poll、epoll
I/O流 概念 (1)c++中将数据的输入输出称之为流(stream),在c++中,流被定义为类,成为流类(stream class),其定义的对象为流对象. (2)文件,套接字(socket),管道 ...
- python框架Django中的MTV架构
MTV架构 关注公众号"轻松学编程"了解更多. 通过V对M和T进行连接,用户通过T(界面)对服务器进行访问(发送请求),T把请求传给V(调度),V调用M(数据模型)获取数据,把 ...
- Git命令之diff
工作区(working tree),暂存区(index /stage),本地仓库(repository) git跟不同的参数,比较不同的区间的版本. git diff:是查看working tree与 ...
- windows本地破解用户口令
实验所属系列:操作系统安全 实验对象: 本科/专科信息安全专业 相关课程及专业:信息网络安全概论.计算机网络 实验时数(学分):2学时 实验类别:实践实验类 实验目的 1.了解Windows2000/ ...
- 25类Android常用开源框架
1.图片加载,缓存,处理 框架名称 功能描述 Android Universal Image Loader 一个强大的加载,缓存,展示图片的库,已过时 Picasso 一个强大的图片下载与缓存的库 F ...