python 文本特征提取 CountVectorizer, TfidfVectorizer
1. TF-IDF概述
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜索引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
(1)TF
TF: Term Frequency, 用于衡量一个词在一个文件中的出现频率。因为每个文档的长度的差别可以很大,因而一个词在某个文档中出现的次数可能远远大于另一个文档,所以词频通常就是一个词出现的次数除以文档的总长度,相当于是做了一次归一化。
TF(t) = (词t在文档中出现的总次数) / (文档的词总数).
(2)IDF
IDF: 逆向文件频率,用于衡量一个词的重要性。计算词频TF的时候,所有的词语都被当做一样重要的,但是某些词,比如”is”, “of”, “that”很可能出现很多很多次,但是可能根本并不重要,因此我们需要减轻在多个文档中都频繁出现的词的权重。
ID(t) = log(总文档数/词t出现的文档数)
TF-IDF:上面两个乘起来,就是TF-IDF TF-IDF = TF * IDF
sklearn.feature_extraction.text.TfidfVectorizer:可以把一大堆文档转换成TF-IDF特征的矩阵。
Convert a collection of raw documents to a matrix of TF-IDF features.
Equivalent to CountVectorizer followed by TfidfTransformer. 举例:
# 初始化TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=tok,stop_words=stop_words)
labels = list() # 特征提取
data = vectorizer.fit_transform(load_data(labels)) # 初始化LogisticRegression模型
log_reg= LogisticRegression(class_weight="balanced") # 训练模型
log_reg.fit(data, numpy.asarray(labels)) # 根据输入预测
log_reg.predict_proba(input)
2.文本特征提取:
将文本数据转化成特征向量的过程,比较常用的文本特征表示法为词袋法
词袋法: 不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征 这些不重复的特征词汇集合为词表 每一个文本都可以在很长的词表上统计出一个很多列的特征向量 如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量
3.TF-IDF的预处理
在scikit-learn中,有两种方法进行TF-IDF的预处理。
第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。
CountVectorizer:只考虑词汇在文本中出现的频率
TfidfVectorizer:除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征
(1)CountVectorizer
CountVectorizer单独求词频
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(type(X))
print(vectorizer.get_feature_names())

print(X.toarray())

X的第一行5个1显示了corpus的第一行数据在排列中的相应位置,数字表示出现的次数。
CountVectorizer和TfidfTransformer搭配计算TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
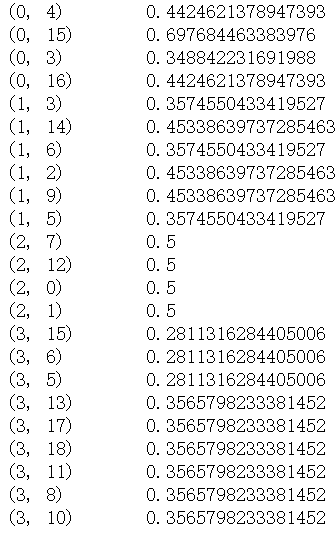
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print (tfidf)

tfidf结果如下:
(2)TfidfVectorizer
第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(corpus)
print(re)
由于第二种方法比较的简洁,因此在实际应用中推荐使用,一步到位完成向量化,TF-IDF与标准化。

4. TF-IDF小结
TF-IDF是非常常用的文本挖掘预处理基本步骤,但是如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后我们已经无法得到哈希后的各特征的IDF的值。使用了TF-IDF并标准化以后,我们就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。当然TF-IDF不光可以用于文本挖掘,在信息检索等很多领域都有使用。因此值得好好的理解这个方法的思想。
参考文献:
python 文本特征提取 CountVectorizer, TfidfVectorizer的更多相关文章
- 机器学习之路:python 文本特征提取 CountVectorizer, TfidfVectorizer
本特征提取: 将文本数据转化成特征向量的过程 比较常用的文本特征表示法为词袋法词袋法: 不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征 这些不重复的特征词汇集合为词表 每一个文本都可以在很长的 ...
- python —— 文本特征提取 CountVectorize
CountVectorize 来自:python学习 文本特征提取(二) CountVectorizer TfidfVectorizer 中文处理 - CSDN博客 https://blog.csdn ...
- 使用sklearn做文本特征提取
提取文本的特征,把文本用特征表示出来,是文本分类的前提,使用sklearn做文本的特征提取,需要导入TfidfVectorizer模块. from sklearn.feature_extraction ...
- 机器学习之路: python nltk 文本特征提取
git: https://github.com/linyi0604/MachineLearning 分别使用词袋法和nltk自然预言处理包提供的文本特征提取 from sklearn.feature_ ...
- sklearn文本特征提取
http://cloga.info/2014/01/19/sklearn_text_feature_extraction/ 文本特征提取 词袋(Bag of Words)表征 文本分析是机器学习算法的 ...
- Feature extraction - sklearn文本特征提取
http://blog.csdn.net/pipisorry/article/details/41957763 文本特征提取 词袋(Bag of Words)表征 文本分析是机器学习算法的主要应用领域 ...
- Python文本数据分析与处理
Python文本数据分析与处理(新闻摘要) 分词 使用jieba分词, 注意lcut只接受字符串 过滤停用词 TF-IDF得到摘要信息或者使用LDA主题模型 TF-IDF有两种 jieba.analy ...
- 算是休息了这么长时间吧!准备学习下python文本处理了,哪位大大有好书推荐的说下!
算是休息了这么长时间吧!准备学习下python文本处理了,哪位大大有好书推荐的说下!
- Python 文本解析器
Python 文本解析器 一.课程介绍 本课程讲解一个使用 Python 来解析纯文本生成一个 HTML 页面的小程序. 二.相关技术 Python:一种面向对象.解释型计算机程序设计语言,用它可以做 ...
随机推荐
- Linux下修改IP、DNS、路由命令行设置
本文最后修改时间:20180313 一.快速修改,重启后设置就没了 ifconfig eth0 192.168.1.22 netmask 255.255.255.0 up route add defa ...
- MD5生成
/// <summary> /// 32位MD5加密 /// </summary> /// <param name="input"></p ...
- 利用RSACryptoServiceProvider进行RSA加密解密
前言: 本文只介绍How to use,对于加密算法的研究不予讨论. 关于私钥的存储,微软给的建议是使用windows自带的秘钥容器,相见文档. 为了直观看到私钥和公钥,本文直接将其存入XML文件中. ...
- SQL SERVER利用BCP命令在命令行下导出数据到csv文件中
bcp "select * from (DBNAME).dbo.qt_trace where User_1 is not null" queryout c:\%date:~6,4% ...
- python TCP socket套接字编程以及注意事项
TCPServer.py #coding:utf-8 import socket #s 等待链接 #c 实时通讯 s = socket.socket(socket.AF_INET,socket.SOC ...
- 在LINUX上部署SOFA
JDK1.6环境变量 vim /etc/profile JAVA_HOME=/usr/local/java/jdk1.6.0_45PATH=$JAVA_HOME/bin:$PATHCLASSPATH= ...
- Linux 内存使用率
文章参考: 1.正确计算linux系统内存使用率 2.Linux系统内存消失与slab使用之谜 例如当前主机内存信息如下: [zhang@test ~]$ cat /proc/meminfo MemT ...
- February 9th, 2018 Week 6th Friday
Every one of us want to ameliorate our own condition. You can only cure retail but you can prevent w ...
- 3.定时器的使用(以通俗易懂的语言解释JavaScript)
1.定时器的作用: 开启定时器:setInterval -->间隔型 setTimeout -->延时型 区别:setInterval会一直执行,应用如微博间隔一段时间不断请求后台数据,看 ...
- 定义 java 基本数据类型
package debug; class Demo { /* * 定义八种基本数据类型,如下 */ public static void main(String[] args) { //define ...